Résilience et récupération d’urgence dans le service Azure Web PubSub
La résilience et la reprise d’activité après sinistre sont des besoins communs des systèmes en ligne. Le service Azure Web PubSub garantit déjà une disponibilité de 99,9 %, mais il s’agit toujours d’un service régional. En cas de panne à l’échelle d’une région, il est essentiel que le service puisse continuer à traiter les messages en temps réel dans une autre région.
Pour la récupération d’urgence régionale, nous vous recommandons les deux approches suivantes :
- Activer la géoréplication (méthode simple). Cette fonctionnalité gère automatiquement le basculement régional. Lorsqu’elle est activée, il n’existe qu’une seule instance Azure SignalR et aucune modification du code n’est introduite. Vérifiez la géoréplication pour plus d’informations.
- Utilisez plusieurs points de terminaison. Vous apprenez à le faire dans ce document
Architecture haute disponibilité pour le service Web PubSub
Il existe deux modèles classiques à l’aide du service Web PubSub :
- Il s’agit d’un modèle de serveur client que les clients envoient des événements au serveur et que le serveur envoie des messages aux clients.
- Un autre modèle est client-client que les clients pub/sous-messages via le service Web PubSub vers d’autres clients.
Les sections ci-dessous décrivent différentes façons pour ces deux modèles d’effectuer une reprise d’activité après sinistre
Architecture haute disponibilité pour le modèle client-serveur
Pour bénéficier d’une résilience interrégion pour le service Web PubSub, vous devez configurer plusieurs instances du service dans différentes régions. Par conséquent, lorsqu’une région est défaillante, les autres peuvent être utilisées comme sauvegarde.
Une configuration typique pour un scénario interrégion consiste à avoir deux paires (ou plus) d’instances de service Web PubSub et de serveurs d’applications.
Dans chaque paire, le serveur d’applications et le service Web PubSub sont situés dans la même région, et le service Web PubSub place le gestionnaire d’événements en amont du serveur d’applications dans la même région.
Pour mieux illustrer l’architecture, nous appelons le service Web PubSub service principal sur le serveur d’applications de la même paire. Dans les autres paires, nous appelons les services Web PubSub les services secondaires sur le serveur d’applications.
Le serveur d’applications peut utilise l’API de contrôle de l’intégrité du service pour détecter si ses services principal et secondaires sont sains ou non. Par exemple, pour un service Web PubSub appelé demo, le point de terminaison https://demo.webpubsub.azure.com/api/health renvoie le code 200 lorsque le service est sain. Le serveur d’applications peut appeler périodiquement les points de terminaison ou il peut les appeler à la demande pour vérifier si les points de terminaison sont sains. En général, les clients WebSocket négocient d’abord avec leur serveur d’applications pour obtenir l’URL de connexion au service Web PubSub, et l’application utilise cette étape de négociation pour faire basculer les clients vers d’autres services secondaires sains. Voici les étapes détaillées :
- Lorsqu’un client négocie avec le serveur d’applications, ce dernier ne DOIT renvoyer que les points de terminaison principaux du service Web PubSub, de sorte que, dans un cas normal, les clients ne se connectent qu’aux points de terminaison principaux.
- Lorsque l’instance principale est hors service, la négociation DOIT renvoyer un point de terminaison secondaire sain afin que le client puisse toujours établir des connexions, et le client se connecte au point de terminaison secondaire.
- Lorsque l’instance principale est établie, negotiate DOIT retourner le point de terminaison principal sain pour que les clients puissent désormais se connecter au point de terminaison principal
- Quand le serveur d’applications diffuse des messages, il DOIT diffuser des messages à tous les points de terminaison sains, aussi bien le principal que les secondaires.
- Le serveur d’applications peut fermer les connexions aux points de terminaison secondaires pour forcer les clients à se reconnecter au point de terminaison principal sain.
Avec cette topologie, un message provenant d’un serveur peut être livré à tous les clients, car tous les serveurs d’applications et toutes les instances du service Web PubSub sont interconnectés.
Nous n’avons pas encore intégré la stratégie dans le kit de développement logiciel (SDK). Pour l’instant, l’application doit implémenter cette stratégie elle-même.
En résumé, voici ce que le côté de l’application doit implémenter :
- Contrôle d’intégrité. L’application peut vérifier si le service est sain à l’aide de l’API de contrôle de l’intégrité du service régulièrement en arrière-plan ou à la demande pour chaque appel negotiate.
- Logique de négociation. L’application retourne un point de terminaison principal sain par défaut. Lorsque le point de terminaison principal est inactif, l’application retourne un point de terminaison secondaire sain.
- Logique de diffusion. Lorsque des messages sont envoyés à plusieurs clients, l’application doit s’assurer qu’elle diffuse des messages vers tous les points de terminaison sains .
Le diagramme ci-dessous illustre cette topologie :
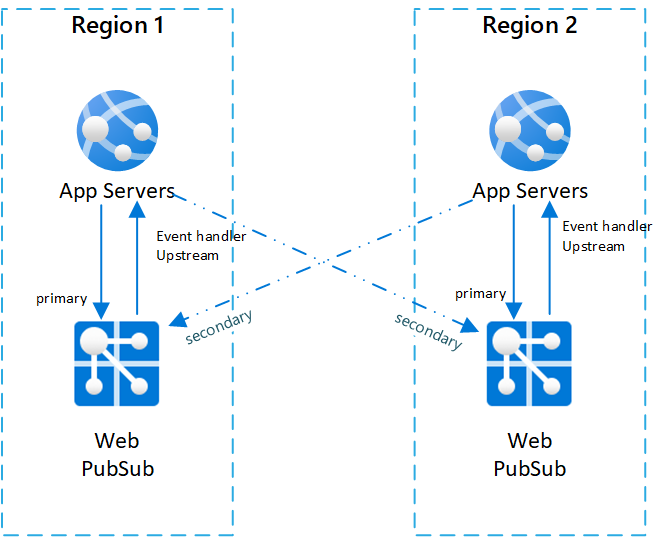
Bonne pratique et séquence de basculement
Vous disposez maintenant de la configuration appropriée de la topologie du système. Chaque fois qu’une instance du service Web PubSub est hors service, le trafic en ligne est acheminé vers d’autres instances. Voici ce qui se passe lorsqu’une instance principale est défaillante (et est restaurée plus tard) :
- L’instance de service principale est hors service : tous les clients connectés à cette instance sont supprimés.
- Les nouveaux clients ou la reconnexion des clients négocient avec le serveur d’applications
- Le serveur d’applications détecte que l’instance du service principal est hors service, et la négociation cesse de renvoyer ce point de terminaison et commence à renvoyer un point de terminaison secondaire sain.
- Les clients se connectent à l’instance secondaire.
- L’instance secondaire prend désormais en charge tout le trafic en ligne. Tous les messages du serveur aux clients peuvent encore être remis, car l’instance secondaire est connectée à tous les serveurs d’applications. Toutefois, les messages d’événement du client au serveur sont envoyés uniquement au serveur d’applications en amont dans la même région.
- Après la récupération de l’instance principale et son retour en ligne, le serveur d’applications détecte que l’instance principale est de nouveau saine. La négociation retourne désormais à nouveau le point de terminaison principal, si bien que les nouveaux clients sont reconnectés à l’instance principale. En revanche, les clients existants ne seront pas supprimés et resteront connectés à l’instance secondaire jusqu’à ce qu’ils se déconnectent eux-mêmes.
Les diagrammes ci-dessous illustrent le basculement :
Fig.1 Avant le basculement 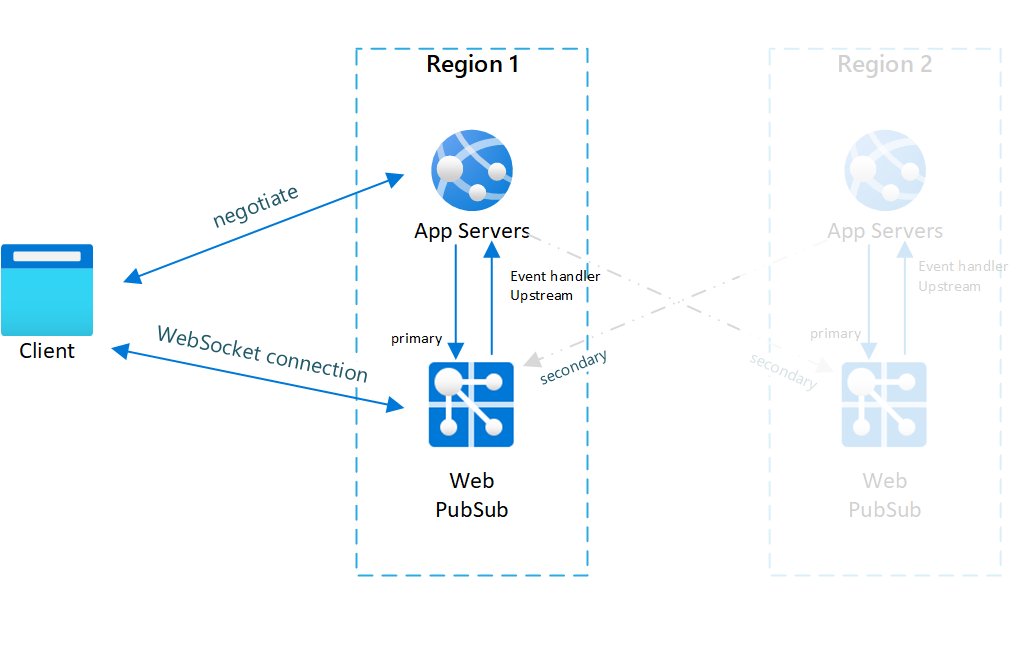
Fig.2 Après le basculement 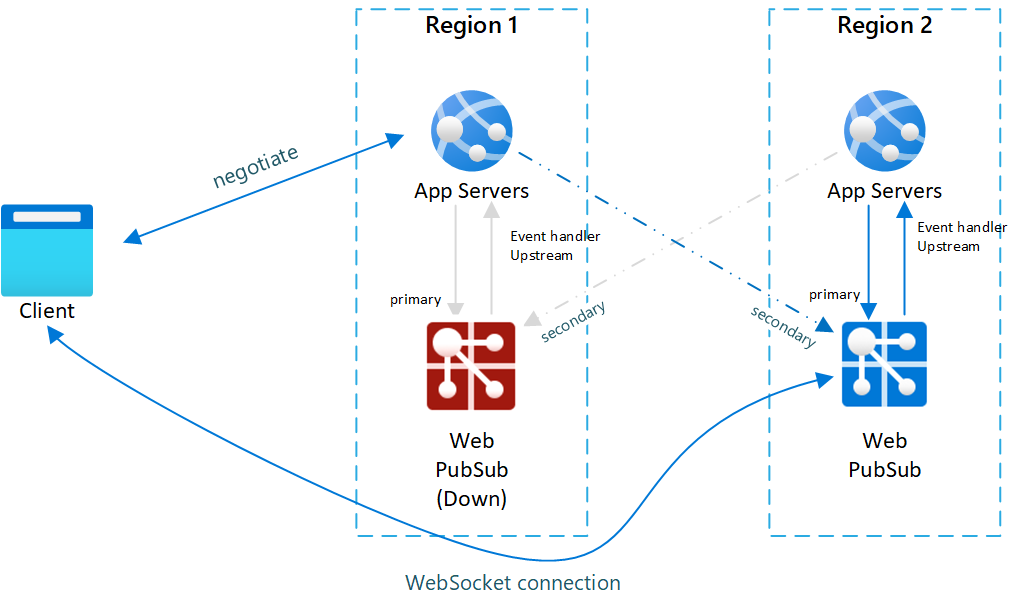
Fig.3 Temps court après la récupération principale 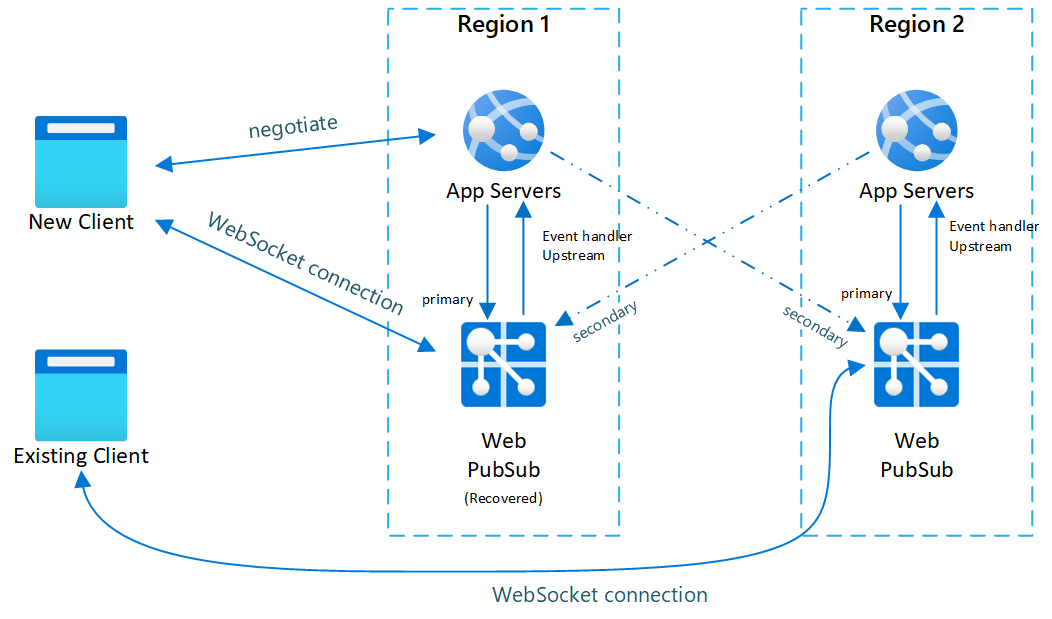
Dans le cadre du fonctionnement normal, seuls le serveur d’applications et le service Web PubSub principaux gèrent le trafic en ligne (en bleu).
Après le basculement, le serveur d’applications et le service Web PubSub secondaires deviennent également actifs. Une fois le service Web PubSub principal de nouveau en ligne, les nouveaux clients se connectent au service Web PubSub principal. Cependant, les clients existants restent connectés à l’instance secondaire, de sorte que les deux instances gèrent le trafic.
Une fois que tous les clients existants se sont déconnectés, votre système revient à la normale (Figure 1).
Il existe deux modèles principaux pour implémenter une architecture inter-région à haute disponibilité :
- Le premier consiste à avoir une paire de serveur d’applications et d’instance de service Web PubSub gérant tout le trafic en ligne et à avoir une autre paire de secours (configuration active/passive, illustrée à la figure 1).
- L’autre consiste à avoir deux paires (ou plus) de serveurs d’applications et d’instances du service Web PubSub, gérant chacune une part du trafic en ligne et servant de paire de secours pour les autres paires (configuration active/active, semblable à la figure 3).
Le service Web PubSub peut prendre en charge ces deux modèles, la principale différence étant la façon dont vous implémentez les serveurs d’applications. Si les serveurs d’applications présentent une configuration active/passive, le service Web PubSub présente également une configuration active/passive (car le serveur d’applications principal renvoie uniquement son instance de service Web PubSub principale). Si les serveurs d’applications présentent une configuration active/active, le service Web PubSub présente également une configuration active/active (car tous les serveurs d’applications renvoient leurs propres instances Web PubSub principales, afin que tous puissent obtenir le trafic).
Notez que, quel que soit le modèle que vous choisissez d’utiliser, vous devez connecter chaque instance du service Web PubSub à un serveur d’applications en tant que rôle principal.
De plus, en raison de la nature de la connexion WebSocket (connexion longue), les clients sont confrontés à des interruptions de connexion en cas d’incident et de basculement. Vous devez gérer de telles situations côté client pour les rendre transparentes pour vos clients finaux. Par exemple, rétablissez une connexion qui a été fermée.
Architecture haute disponibilité pour le modèle client-client
Pour le modèle client-client, il n’est pas encore possible de prendre en charge une récupération d’urgence sans délai à l’aide de plusieurs instances. Si vous avez des exigences de haute disponibilité, envisagez d’utiliser la géoréplication.
Guide pratique pour tester un basculement
Suivez les étapes pour déclencher le basculement :
- Sous l’onglet Mise en réseau de la ressource principale dans le portail, désactivez l’accès au réseau public. Si la ressource a un réseau privé activé, utilisez des règles de contrôle d’accès pour refuser tout le trafic.
- Redémarrez la ressource principale.
Étapes suivantes
Dans cet article, vous avez appris à configurer votre application pour assurer la résilience pour le service Web PubSub.
Utilisez ces ressources pour commencer à créer votre propre application :