Guide pratique pour approcher les opérations de machine learning
Les opérations de Machine Learning consistent en des principes et des meilleures pratiques sur l’organisation et la normalisation du développement, du déploiement et de la maintenance du modèle d’ordinateur de façon évolutive.
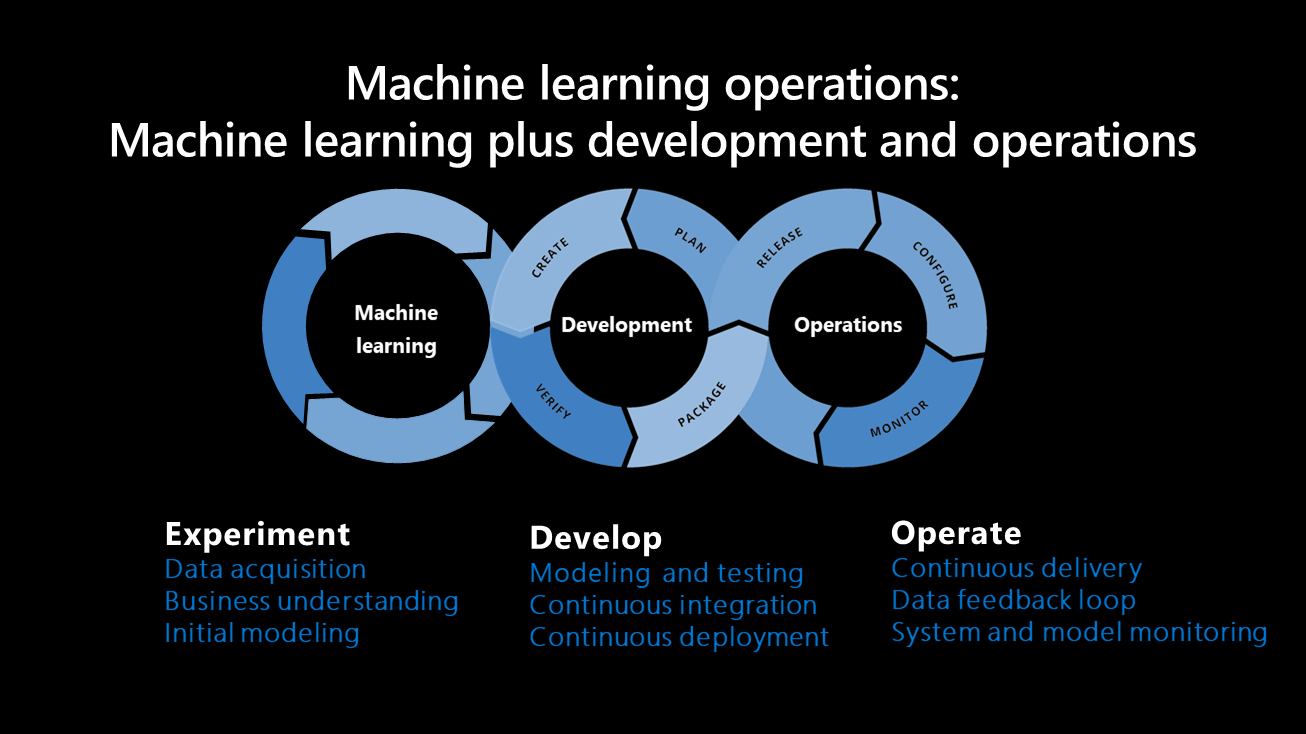
Les principaux composants du développement d’un système de Machine Learning sont présentés ci-dessous :

Sculley, et al. 2015. Hidden technical debt in machine learning systems. Proceedings of the 28th International Conference on Neural Information Processing Systems, Volume 2 (NIPS 2015).
Comparaison des opérations de Machine Learning et des opérations de développement
Tandis que les opérations de développement (DevOps) influencent les opérations de Machine Learning, il existe des différences entre leurs processus. En plus des pratiques DevOps, les opérations de Machine Learning abordent les concepts suivants non couverts dans DevOps :
Contrôle de version des données : Il doit exister un contrôle de version du code et un contrôle de version des jeux de données, car le schéma et les données réelles peuvent changer au fil du temps. Cela permet aux données d’être reproduites, de rendre les données visibles par les autres membres de l’équipe et d’utiliser les cas à auditer.
Suivi du modèle : Les artefacts de modèle sont souvent stockés dans un registre de modèle qui doit identifier les fonctionnalités de stockage, de contrôle de version et de balisage. Ces registres doivent identifier le code source, ses paramètres et les données correspondantes utilisées pour la formation du modèle, qui indiquent tous les emplacements de création d’un modèle.
Piste d’audit numérique : Lorsque vous utilisez du code et des données, toutes les modifications doivent être suivies.
Généralisation : Les modèles sont différents du code en ce qui concerne leur réutilisation, car les modèles doivent être paramétrés en fonction des données d’entrée ou du scénario. Vous devrez peut-être ajuster le modèle pour que les nouvelles données l’utilisent pour un nouveau scénario.
Reformation du modèle : Les performances du modèle peuvent diminuer au fil du temps, et il est important de reformer les modèles pour qu’ils restent utiles.
Approches des opérations de Machine Learning
Les scientifiques des données au sein d’une organisation appliquent un large éventail d’expériences, de maturité, de compétences et d’outils pour expérimenter les opérations de Machine Learning. Étant donné qu’il est important d’encourager le plus grand nombre de participants possible à adopter l’IA, un consensus sur la façon dont toutes les organisations doivent aborder les opérations de Machine Learning n’est pas probable ou souhaitable. À la lumière de cette variété, un point de départ clair pour votre organisation est de comprendre comment sa taille et ses ressources influenceront son approche des opérations de Machine Learning.
La taille et la maturité d’une société indiquent si des équipes de science des données ou des personnes avec des rôles uniques sont propriétaires du cycle de vie du Machine Learning et parcourent chaque phase. Les approches suivantes du cycle de vie sont les plus courantes pour chaque scénario :
Une approche centralisée
Les équipes de science des données vont probablement surveiller le cycle de vie du Machine Learning dans les petites entreprises avec des ressources et des spécialistes limités. Cette équipe applique son expertise technique au nettoyage et à l’agrégation de données, au développement et au déploiement de modèles, ainsi qu’à la surveillance et à la gestion des modèles déployés.
L’un des avantages de cette méthode est qu’elle fait rapidement avancer le modèle vers la production, mais elle augmente les coûts en raison des niveaux de compétence spécifiques qui doivent être maintenus dans l’équipe de science des données. La qualité en pâtit lorsque ces niveaux d’expertise requis ne sont pas présents.
Une approche décentralisée
Les personnes dotées de rôles spécialisés seront probablement responsables du cycle de vie du Machine Learning dans les sociétés ayant des équipes opérationnelles dédiées. Une fois qu’un cas d’usage est approuvé, un ingénieur de Machine Learning est attribué pour évaluer son état actuel et la quantité de travail nécessaire pour l’élever au format qui peut être pris en charge.
Le scientifique des données devra recueillir des informations sur les questions suivantes :
- Qui sera le propriétaire de l’entreprise ?
- Comment le modèle sera-t-il consommé ?
- Quel est le niveau de disponibilité de service nécessaire ?
- Comment le modèle sera-t-il reformé ?
- À quelle fréquence le modèle sera-t-il reformé ?
- Qui va décider des conditions de la promotion du modèle ?
- Quelle est la sensibilité du cas d’usage et le code peut-il être partagé ?
- Comment le modèle et le code seront-ils modifiés à l’avenir ?
- Quelle part de l’expérience actuelle est-elle réutilisable ?
- Existe-t-il des workflows de projet qui peuvent vous aider ?
- Quelle quantité de travail sera nécessaire pour faire passer le modèle en production ?
Ensuite, un ingénieur Machine Learning conçoit le workflow et estime la quantité de travail nécessaire. Une bonne pratique est d’impliquer des scientifiques Données lors de la création du workflow : en effet, vous avez à ce moment-là la possibilité de les former de façon croisée et de les familiariser avec le référentiel final, car il est courant pour ces scientifiques de travailler par la suite sur le cas d’usage.
Comment les opérations de Machine Learning profitent-elles à l’entreprise
Les opérations de Machine Learning connectent les opérations de développement traditionnelles, les opérations de données et la science des données/IA. Le fait de comprendre comment les opérations de Machine Learning peuvent bénéficier à votre entreprise peut vous aider dans votre parcours d’IA.
L’intégration des opérations de Machine Learning dans votre entreprise peut amener les avantages suivants :
La gestion des modèles d’entreprise rationalise et automatise le cycle de vie du développement, de la formation, du déploiement et de la mise en œuvre des modèles. Cela permet aux entreprises d’être agiles et de répondre aux besoins immédiats et aux changements dans l’entreprise de manière reproductible et gérée.
Le contrôle de version des modèles et la réalisation des données permettent à l’entreprise de générer des modèles itérés et à version gérée pour s’adapter aux nuances des données ou au cas d’usage particulier. Cela offre de la flexibilité et de l’agilité pour répondre aux défis et aux changements de l’entreprise.
Lorsque les organisations contrôlent et gèrent leurs modèles, cela leur permet de répondre rapidement aux modifications significatives apportées aux données ou au scénario. Par exemple, un modèle implémenté peut connaître une dérive extrême des données en raison d’un facteur externe ou d’une modification des données sous-jacentes. Cela rendrait les modèles précédents inutilisables et nécessiterait de reformer le modèle actuel dès que possible. Modèles de Machine Learning dont l’exactitude et les performances doivent être suivies. Les parties prenantes sont averties lorsque des modifications ont un impact sur la fiabilité et les performances du modèle, entraînant une reformation et un déploiement rapides.
Les processus d’opérations de Machine Learning appliqués prennent en charge les résultats d’entreprise en autorisant un audit, une conformité, une gouvernance et un contrôle d’accès rapides tout au long du cycle de développement. La visibilité de la génération de modèles, de l’utilisation des données et de la conformité aux réglementations est évidente à mesure que des modifications sont apportées au sein de l’entreprise.
Étapes suivantes
La Microsoft AI Business School est une ressource qui présente l’intelligence artificielle, notamment comment aborder la mise en œuvre de manière holistique, comprendre les dépendances au-delà de la technologie et avoir un impact sur l’activité.
Pour plus d’informations, consultez le processus des opérations du Machine Learning.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour