Meilleures pratiques en lien avec Azure Machine Learning pour la sécurité de l’entreprise
Cet article décrit les bonnes pratiques de sécurité liées à la planification ou à la gestion d’un déploiement sécurisé d’Azure Machine Learning. Ces bonnes pratiques sont tirées de l’expérience de Microsoft et de ses clients avec Azure Machine Learning. Cet article explique la nature et la logique de chaque pratique. Il fournit également des liens vers des guides et des documents de référence.
Architecture de sécurité réseau recommandée (réseau managé)
L'architecture de sécurité recommandée pour les réseaux d'apprentissage automatique est un réseau virtuel géré. Un réseau virtuel managé Azure Machine Learning sécurise l’espace de travail, les ressources Azure associées et toutes les ressources de calcul managées. Il simplifie la configuration et la gestion de la sécurité réseau en préconfigurant les sorties requises et en créant automatiquement des ressources managées au sein du réseau. Vous pouvez utiliser des points de terminaison privés pour autoriser les services Azure à accéder au réseau et éventuellement définir des règles de trafic sortant pour permettre au réseau d’accéder à Internet.
Le réseau virtuel managé a deux modes qu’il peut être configuré pour :
Autoriser le trafic sortant Internet : ce mode autorise la communication sortante avec des ressources situées sur Internet, telles que les référentiels de packages PyPi ou Anaconda publics.

Autoriser uniquement le trafic sortant approuvé : ce mode autorise uniquement la communication sortante minimale requise pour que l’espace de travail fonctionne. Ce mode est recommandé pour les espaces de travail qui doivent être isolés d’Internet. Ou lorsque l’accès sortant n’est autorisé qu’à des ressources spécifiques via des points de terminaison de service, des étiquettes de service ou des noms de domaine complets.

Pour plus d’informations, consultez Isolement de réseau virtuel managé.
Architecture de sécurité réseau recommandée (réseau virtuel Azure)
Si vous ne pouvez pas utiliser de réseau virtuel managé en raison de vos besoins métier, vous pouvez utiliser un réseau virtuel Azure avec les sous-réseaux suivants :
- Entraînement contient les ressources de calcul utilisées pour l’entraînement, comme les instances ou clusters de calcul de Machine Learning.
- Scoring contient les ressources de calcul utilisées pour le scoring, comme Azure Kubernetes Service (AKS).
- Pare-feu contient le pare-feu (comme le service Pare-feu Azure) qui autorise le trafic en provenance et à destination de l’Internet public.
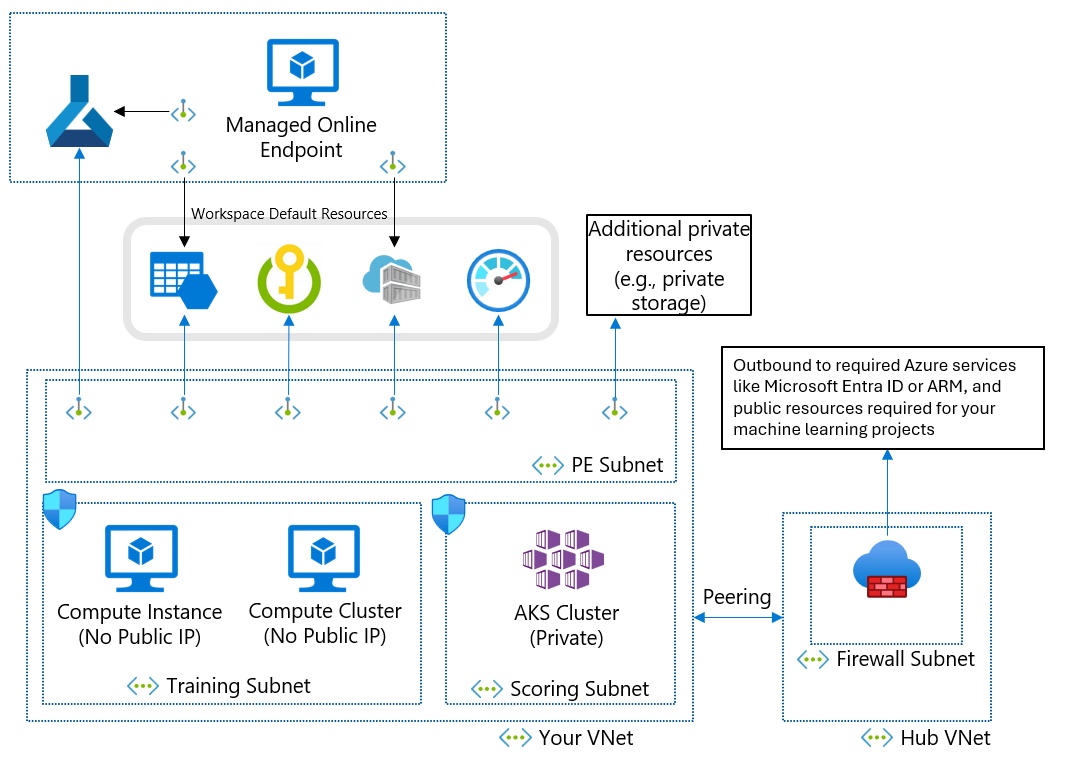
Le réseau virtuel contient également un point de terminaison privé pour votre espace de travail Machine Learning et les services dépendants suivants :
- Compte de Stockage Azure
- Azure Key Vault
- Azure Container Registry
La communication sortante à partir du réseau virtuel doit pouvoir atteindre les services Microsoft suivants :
- Machine Learning
- Microsoft Entra ID
- Azure Container Registry et les registres spécifiques gérés par Microsoft
- Azure Front Door
- Azure Resource Manager
- Stockage Azure
Les clients distants se connectent au réseau virtuel à l’aide d’Azure ExpressRoute ou d’une connexion de réseau privé virtuel (VPN).
Conception de réseau virtuel et de point de terminaison privé
Lors de la conception d’un réseau virtuel Azure, de sous-réseaux et de points de terminaison privés, tenez compte des exigences suivantes :
En général, créez des sous-réseaux distincts pour l’entraînement et le scoring et utilisez le sous-réseau d’entraînement pour tous les points de terminaison privés.
Pour l’adressage IP, chaque instance de calcul nécessite une adresse IP privée. Les clusters de calcul ont besoin d’une adresse IP privée par nœud. Les clusters AKS ont besoin de nombreuses adresses IP privées, comme décrit dans Planifier l’adressage IP pour votre cluster AKS. Au moins un sous-réseau distinct pour AKS permet d’éviter l’épuisement des adresses IP.
Les ressources de calcul dans les sous-réseaux d’apprentissage et de scoring doivent accéder au compte de stockage, au coffre de clés et au registre de conteneurs. Créez des points de terminaison privés pour le compte de stockage, le coffre de clés et le registre de conteneurs.
Le stockage par défaut de l’espace de travail Machine Learning doit avoir deux points de terminaison privés : un pour Stockage Blob Azure et un autre pour Stockage Fichier Azure.
Si vous utilisez Azure Machine Learning Studio, l’espace de travail et les points de terminaison privés de stockage doivent se trouver dans le même réseau virtuel.
Si vous avez plusieurs espaces de travail, utilisez un réseau virtuel pour chaque espace de travail pour créer une limite réseau explicite entre eux.
Utiliser des adresses IP privées
Les adresses IP privées minimisent l’exposition de vos ressources Azure à Internet. Le Machine Learning utilise de nombreuses ressources Azure, et le point de terminaison privé de l’espace de travail Machine Learning est insuffisant pour une adresse IP privée de bout en bout. Le tableau suivant montre les principales ressources utilisées par le machine learning et comment activer l’adresse IP privée pour les ressources. Les instances et les clusters de calcul sont les seules ressources qui n’ont pas la fonctionnalité d’adresse IP privée.
| Ressources | Solution d’adresse IP privée | Documentation |
|---|---|---|
| Espace de travail | Point de terminaison privé | Configurer un point de terminaison privé pour un espace de travail Azure Machine Learning |
| Registre | Point de terminaison privé | Isolement réseau avec les registres Azure Machine Learning |
| Ressources associées | ||
| Stockage | Point de terminaison privé | Sécuriser des comptes de stockage Azure avec des points de terminaison de service |
| Key Vault | Point de terminaison privé | Sécuriser un coffre de clés Azure Key Vault |
| Container Registry | Point de terminaison privé | Activer Azure Container Registry |
| Ressources d’entraînement | ||
| Instance de calcul | Adresse IP privée (aucune adresse IP publique) | Sécuriser les environnements d’apprentissage |
| Cluster de calcul | Adresse IP privée (aucune adresse IP publique) | Sécuriser les environnements d’apprentissage |
| Ressources d’hébergement | ||
| Point de terminaison en ligne managé | Point de terminaison privé | Isolement réseau avec des points de terminaison en ligne managés |
| Point de terminaison en ligne (Kubernetes) | Point de terminaison privé | Sécuriser les points de terminaison en ligne Azure Kubernetes Service |
| Points de terminaison batch | Adresse IP privée (héritée du cluster de calcul) | Isolement réseau dans les points de terminaison par lots |
Contrôler le trafic entrant et sortant du réseau virtuel
Utilisez un pare-feu ou un groupe de sécurité réseau (NSG) Azure pour contrôler le trafic entrant et sortant du réseau virtuel. Pour plus d’informations sur les exigences en matière de trafic entrant et sortant, consultez Configurer le trafic réseau entrant et sortant. Pour plus d’informations sur les flux de trafic entre les composants, consultez Flux de trafic réseau dans un espace de travail sécurisé.
Garantir l’accès à votre espace de travail
Pour que votre point de terminaison privé puisse accéder à votre espace de travail Machine Learning, effectuez les étapes suivantes :
Vérifiez que vous avez accès à votre réseau virtuel en utilisant une connexion VPN, ExpressRoute ou une machine virtuelle jumpbox avec accès à Azure Bastion. L’utilisateur public ne peut pas accéder à l’espace de travail Machine Learning avec le point de terminaison privé parce que celui-ci n’est accessible qu’à partir de votre réseau virtuel. Pour plus d’informations, consultez Sécuriser votre espace de travail avec des réseaux virtuels.
Vérifiez que vous pouvez résoudre les noms de domaine complets (FQDN) de l’espace de travail avec votre adresse IP privée. Si vous utilisez votre propre serveur DNS (Domain Name System) ou une infrastructure DNS centralisée, vous devez configurer un redirecteur DNS. Pour plus d’informations, consultez Utilisation de votre espace de travail avec un serveur DNS personnalisé.
Gestion des accès à l’espace de travail
Lors de la définition des contrôles de gestion des identités et des accès pour le Machine Learning, vous pouvez séparer les contrôles qui définissent l’accès aux ressources Azure de ceux qui gèrent l’accès aux ressources de données. Selon votre cas d’utilisation, déterminez s’il convient d’utiliser une gestion des identités et des accès en libre-service, centrée sur les données ou centrée sur les projets.
Modèle libre-service
Dans un modèle libre-service, les scientifiques des données peuvent créer et gérer des espaces de travail. Ce modèle est mieux adapté aux situations de preuve de concept nécessitant une flexibilité pour essayer différentes configurations. L’inconvénient est que les scientifiques des données doivent disposer de l’expertise nécessaire pour provisionner des ressources Azure. Cette approche est moins appropriée quand un contrôle strict, une utilisation des ressources, des traces d’audit et l’accès aux données sont requis.
Définissez des stratégies Azure afin de mettre en place des protections pour le provisionnement et l’utilisation des ressources, par exemple des tailles de cluster et des types de machines virtuelles autorisés.
Créez un groupe de ressources pour conserver les espaces de travail et accorder aux scientifiques des données un rôle Contributeur dans le groupe de ressources.
Les scientifiques des données peuvent ensuite créer des espaces de travail et associer des ressources du groupe de ressources en libre-service.
Pour accéder au stockage de données, créez des identités managées affectées par l’utilisateur et accordez les rôles d’accès en lecture aux identités sur le stockage.
Lorsque les scientifiques des données créent des ressources de calcul, ils peuvent affecter les identités managées aux instances de calcul pour avoir accès aux données.
Pour connaître les bonnes pratiques, consultez Authentification pour l’analytique à l’échelle du cloud .
Modèle centré sur les données
Dans un modèle centré sur les données, l’espace de travail appartient à un seul scientifique des données qui peut travailler sur plusieurs projets. L’avantage de cette approche est que le chercheur de données peut réutiliser du code ou des pipelines d’apprentissage dans différents projets. Tant que l’espace de travail est limité à un seul utilisateur, il est possible de rapprocher l’accès aux données de cet utilisateur lors de l’audit des journaux de stockage.
L’inconvénient est que l’accès aux données n’est pas compartimenté ou restreint par projet, et tout utilisateur ajouté à l’espace de travail peut accéder aux mêmes ressources.
Créez l’espace de travail.
Créez des ressources de calcul en activant les identités managées affectées par le système.
Quand un scientifique des données a besoin d’accéder aux données d’un projet spécifique, accordez à l’identité managée de calcul l’accès en lecture aux données.
Accordez à l’identité managée de calcul l’accès à d’autres ressources requises, telles qu’un registre de conteneurs avec des images Docker personnalisées pour l’entraînement.
Accordez également le rôle d’accès en lecture de l’identité managée de l’espace de travail sur les données pour activer l’aperçu des données.
Accordez au scientifique des données l’accès à l’espace de travail.
Le scientifique des données peut désormais créer des magasins de données pour accéder aux données requises pour les projets et envoyer des exécutions d’entraînement qui utilisent les données.
Vous pouvez également créer un groupe de sécurité Microsoft Entra et lui accorder un accès en lecture aux données, puis ajouter des identités managées au groupe de sécurité. Cette approche réduit le nombre d’attributions de rôle directes sur les ressources, ce qui permet d’éviter d’atteindre la limite d’abonnement applicable aux attributions de rôles.
Modèle centré sur le projet
Un modèle centré sur le projet crée un espace de travail Machine Learning pour un projet spécifique, et de nombreux scientifiques des données collaborent au sein du même espace de travail. L’accès aux données étant limité à un projet donné, l’approche convient bien aux données sensibles. Il est également facile d’ajouter des scientifiques des données au projet ou de les supprimer.
L’inconvénient de cette approche est qu’elle peut compliquer le partage de ressources entre projets. Il est également difficile de rapprocher l’accès aux données d’utilisateurs spécifiques pendant les audits.
Créer l’espace de travail
Identifiez les instances de stockage de données requises pour le projet, créez une identité managée affectée par l’utilisateur et accordez-lui l’accès en lecture au stockage.
Vous pouvez également accorder à l’identité managée de l’espace de travail l’accès au stockage de données pour autoriser l’aperçu des données. Vous pouvez omettre cet accès pour les données sensibles qui ne doivent pas figurer dans un aperçu.
Créez des magasins de données sans informations d’identification pour les ressources de stockage.
Créez des ressources de calcul dans l’espace de travail, puis affectez l’identité managée aux ressources de calcul.
Accordez à l’identité managée de calcul l’accès à d’autres ressources requises, telles qu’un registre de conteneurs avec des images Docker personnalisées pour l’entraînement.
Accordez aux scientifiques des données travaillant sur le projet un rôle sur l’espace de travail.
En utilisant le contrôle d’accès en fonction du rôle (RBAC) Azure, vous pouvez empêcher les scientifiques de données de créer des magasins de données ou des ressources de calcul avec des identités managées différentes. Cette pratique empêche l’accès aux données qui ne sont pas spécifiques au projet.
Si vous le souhaitez, pour simplifier la gestion de l’appartenance au projet, vous pouvez créer un groupe de sécurité Microsoft Entra pour des membres du projet et accorder à ce groupe l’accès à l’espace de travail.
Azure Data Lake Storage avec passage des informations d’identification
Vous pouvez utiliser l’identité de l’utilisateur Microsoft Entra pour un accès au stockage interactif à partir de Machine Learning Studio. En activant l’espace de noms hiérarchique dans Data Lake Storage, vous pouvez améliorer l’organisation des ressources de données pour le stockage et la collaboration. L’espace de noms hiérarchique Data Lake Storage vous permet de compartimenter l’accès aux données en accordant à différents utilisateurs un accès basé sur une liste de contrôle d’accès (ACL) à différents dossiers et fichiers. Par exemple, vous pouvez accorder l’accès à des données confidentielles uniquement à un sous-ensemble d’utilisateurs.
Rôles RBAC et personnalisés
Azure RBAC vous aide à gérer qui a accès aux ressources Machine Learning et à configurer qui peut effectuer des opérations. Par exemple, vous pouvez autoriser uniquement des utilisateurs spécifiques à gérer les ressources de calcul en leur attribuant le rôle Administrateur d’espace de travail.
L’étendue d’accès peut varier d’un environnement à l’autre. Dans un environnement de production, vous pouvez limiter la capacité des utilisateurs à mettre à jour les points de terminaison d’inférence. Au lieu de cela, vous pouvez accorder cette autorisation à un principal de service autorisé.
Machine Learning a plusieurs rôles par défaut : Propriétaire, Contributeur, Lecteur et Scientifique des données. Vous pouvez également créer vos propres rôles, par exemple pour créer des autorisations qui reflètent la structure de votre organisation. Pour plus d’informations, consultez Gérer l’accès à un espace de travail Azure Machine Learning.
Au fil du temps, la composition de votre équipe peut changer. Si vous créez un groupe Microsoft Entra pour chaque rôle et espace de travail d’équipe, vous pouvez attribuer un rôle RBAC Azure au groupe Microsoft Entra, et gérer séparément l’accès aux ressources et les groupes d’utilisateurs.
Les principaux d’utilisateur et de service peuvent faire partie du même groupe Microsoft Entra. Par exemple, quand vous créez une identité managée affectée par l’utilisateur et qu’Azure Data Factory l’utilise pour déclencher un pipeline Machine Learning, vous pouvez ajouter l’identité managée à un groupe Microsoft Entra Exécuteur de pipelines ML.
Gestion centralisée des images Docker
Azure Machine Learning fournit des images Docker curées que vous pouvez utiliser pour l’entraînement et le déploiement. Toutefois, vos exigences de conformité d’entreprise peuvent imposer l’utilisation d’images à partir d’un référentiel privé géré par votre entreprise. Machine Learning propose deux façons d’utiliser un dépôt central :
Utiliser les images d’un référentiel central en tant qu’images de base. La gestion de l’environnement Machine Learning installe les packages et crée un environnement Python dans lequel s’exécute le code d’entraînement ou d’inférence. Avec cette approche, vous pouvez mettre à jour facilement les dépendances de package sans modifier l’image de base.
Utilisez les images telles quelles, sans recourir à la gestion de l’environnement Machine Learning. Cette approche vous donne un degré de contrôle plus élevé, mais vous oblige également à construire soigneusement l’environnement Python dans le cadre de l’image. Vous devez répondre à toutes les dépendances nécessaires pour exécuter le code, et toutes les nouvelles dépendances nécessitent la reconstruction de l’image.
Pour plus d’informations, consultez Gérer les environnements.
Chiffrement des données
Les données au repos de Machine Learning ont deux sources de données :
Votre stockage contient toutes vos données, notamment les données d’entraînement et de modèle entraînées, à l’exception des métadonnées. Vous êtes responsable du chiffrement du stockage.
Azure Cosmos DB contient vos métadonnées, y compris les informations d’historique des exécutions comme le nom de l’expérience et la date et heure de sa soumission. Dans la plupart des espaces de travail, Azure Cosmos DB se trouve dans l’abonnement Microsoft et est chiffré par une clé gérée par Microsoft.
Si vous souhaitez chiffrer vos métadonnées à l’aide de votre propre clé, vous pouvez utiliser un espace de travail de clé géré par le client. L’inconvénient est que vous devez avoir Azure Cosmos DB dans votre abonnement et en payer le coût. Pour plus d’informations, consultez Chiffrement de données avec Azure Machine Learning.
Pour plus d’informations sur la façon dont Azure Machine Learning chiffre les données en transit, consultez Chiffrement en transit.
Surveillance
Quand vous déployez des ressources Machine Learning, configurez des contrôles de journalisation et d’audit pour l’observabilité. Les motivations en matière d’observation des données peuvent varier en fonction des personnes qui les consultent. Il s’agit entre autres des scénarios suivants :
Des professionnels du Machine Learning ou des équipes en charge des opérations cherchant à superviser l’intégrité du pipeline Machine Learning. Ces observateurs doivent comprendre les problèmes liés à l’exécution planifiée ou aux problèmes liés à la qualité des données ou aux performances d’entraînement attendues. Vous pouvez créer des tableaux de bord Azure qui Supervise les données Azure Machine Learning ou Crée des flux de travail pilotés par des événements.
Des gestionnaires de capacité, des professionnels du Machine Learning ou des équipes en charge des opérations pouvant être intéressés par la création d’un tableau de bord pour observer l’utilisation des calculs et des quotas. Pour gérer un déploiement avec plusieurs espaces de travail Azure Machine Learning, songez à créer un tableau de bord central pour comprendre l’utilisation des quotas. Les quotas étant gérés au niveau de l’abonnement, il est important d’avoir une vue d’ensemble de l’environnement à des fins d’optimisation.
Des équipes informatiques et en charge des opérations souhaitant mettre en place une journalisation des diagnostics pour auditer l’accès aux ressources et les événements de modification dans l’espace de travail.
Songez à créer des tableaux de bord permettant de superviser l’intégrité globale de l’infrastructure du Machine Learning et des ressources dépendantes, notamment le stockage. Par exemple, la combinaison de métriques stockage Azure avec des données d’exécution de pipeline peut vous aider à optimiser l’infrastructure pour de meilleures performances ou à découvrir les causes racines du problème.
Azure collecte et stocke automatiquement les métriques de la plateforme et les journaux d’activité. Vous pouvez acheminer les données vers d’autres emplacements au moyen d’un paramètre de diagnostic. Configurez la journalisation des diagnostics sur un espace de travail Log Analytics centralisé pour l’observabilité dans plusieurs instances d’espace de travail. Utilisez Azure Policy pour configurer automatiquement la journalisation des nouveaux espaces de travail Machine Learning dans cet espace de travail Log Analytics central.
Azure Policy
Vous pouvez appliquer et auditer l’utilisation des fonctionnalités de sécurité sur les espaces de travail par le biais d’Azure Policy. Voici nos recommandations :
- Appliquez un chiffrement avec une clé gérée par le client.
- Appliquez Azure Private Link et des point de terminaison privés.
- Appliquez des zones DNS privées.
- Désactivez l’authentification non-Azure AD, par exemple SSH (Secure Shell).
Pour plus d’informations, consultez Définitions de stratégie intégrées pour Azure Machine Learning.
Vous pouvez également utiliser des définitions de stratégie personnalisées pour régir la sécurité de l’espace de travail de manière flexible.
Clusters et instances de calcul
Les considérations et recommandations suivantes s’appliquent aux clusters et instances de calcul Machine Learning.
Chiffrement de disque
Le disque du système d’exploitation pour une instance de calcul ou un nœud de cluster de calcul est stocké dans Stockage Azure et chiffré avec des clés gérées par Microsoft. Chaque nœud dispose également d’un disque temporaire local. Le disque temporaire est également chiffré avec des clés gérées par Microsoft si l’espace de travail a été créé avec le paramètre hbi_workspace = True. Pour plus d’informations, consultez Chiffrement de données avec Azure Machine Learning.
Identité managée
Les clusters de calcul prennent en charge l’utilisation d’identités managées pour s’authentifier auprès des ressources Azure. L’utilisation d’une identité managée pour le cluster permet l’authentification auprès des ressources sans exposer d’informations d’identification dans votre code. Pour plus d’informations, consultez Créer un cluster de calcul Azure Machine Learning.
Script de configuration
Vous pouvez utiliser un script d’installation pour automatiser la personnalisation et la configuration des instances de calcul lors de la création. En tant qu’administrateur, vous pouvez écrire un script de personnalisation à utiliser lors de la création de toutes les instances de calcul dans un espace de travail. Vous pouvez utiliser Azure Policy pour appliquer l’utilisation du script d’installation pour créer chaque instance de calcul. Pour plus d’informations, consultez Créer et gérer une instance de calcul Azure Machine Learning.
Créer au nom de
Si vous ne souhaitez pas que les scientifiques des données provisionnent des ressources de calcul, vous pouvez créer des instances de calcul en leur nom, puis les leur attribuer. Pour plus d’informations, consultez Créer et gérer une instance de calcul Azure Machine Learning.
Espace de travail doté d’un point de terminaison privé
Utilisez des instances de calcul avec un espace de travail doté d’un point de terminaison privé. L’instance de calcul rejette tout accès public émanant de l’extérieur du réseau virtuel. Cette configuration empêche également le filtrage des paquets.
Prise en charge d’Azure Policy
Lorsque vous utilisez un réseau virtuel Azure, vous pouvez utiliser Azure Policy pour vous assurer que chaque cluster de calcul ou instance est créé dans un réseau virtuel et spécifiez le réseau virtuel et le sous-réseau par défaut. La stratégie n’est pas nécessaire lors de l’utilisation d’un réseau virtuel géré, car les ressources de calcul sont automatiquement créées dans le réseau virtuel géré.
Vous pouvez également utiliser une stratégie pour désactiver l’authentification non-Azure AD, par exemple SSH.
Étapes suivantes
Apprenez-en davantage sur les configurations de sécurité du Machine Learning :
- Sécurité et gouvernance d’entreprise
- Sécuriser les ressources d’espace de travail à l’aide de réseaux virtuels
Commencez un déploiement basé sur un modèle Machine Learning :
- Modèles de démarrage rapide Azure (
microsoft.com) - Zone d’atterrissage des données de l’IA et de l’analytique à l’échelle de l’entreprise
Lisez d’autres articles sur les considérations architecturales en matière de déploiement du Machine Learning :
Découvrez comment les contraintes liées à la structure d’équipe, à l’environnement ou aux contraintes régionales affectent la configuration de l’espace de travail.
Découvrez comment gérer les coûts de calcul et le budget entre plusieurs équipes et utilisateurs.
Découvrez DevOps pour le Machine Learning (MLOps), une pratique combinant des personnes, des processus et des technologies pour fournir des solutions de Machine Learning robustes, fiables et automatisées.