Qu’est-ce qu’une voix neuronale personnalisée ?
La voix neuronale personnalisée (CNV) est une fonctionnalité de synthèse vocale qui vous permet de créer une voix de synthèse personnalisée, unique en son genre, pour vos applications. Avec la voix neuronale personnalisée, vous pouvez créer une voix très naturelle pour votre marque ou vos personnages, en fournissant des échantillons vocaux comme données d’apprentissage.
Important
L’accès à la voix neuronale personnalisée est limité en fonction de critères d’éligibilité et d’utilisation. Demandez l’accès à l’aide du formulaire d’admission.
Accédez à la Voix neuronale personnalisée (CNV) Lite est possible pour tout le monde sous forme de version de démonstration afin d’évaluer la CNV, avant d’investir dans des enregistrements professionnels pour créer une voix de meilleure qualité.
Par défaut, la synthèse vocale peut être utilisée avec des voix neuronales prédéfinies pour chaque langue prise en charge. Les voix neuronales prédéfinies fonctionnent bien dans la plupart des scénarios de synthèse vocale si vous n’avez pas besoin d’une voix unique.
La voix neuronale personnalisée est basée sur la technologie de synthèse vocale neuronale et sur le modèle universel multilingue, multilocuteur. Vous pouvez créer des voix de synthèse riches en styles d’élocution, ou des voix adaptables multilingues. Réaliste et naturelle, la voix neuronale personnalisée peut représenter des marques, personnifier des machines et permettre aux utilisateurs d’interagir sur le ton de la conversation avec les applications. Consultez les langues prises en charge pour une voix neuronale personnalisée.
Comment fonctionne-t-il ?
Pour créer une voix neuronale personnalisée, utilisez Speech Studio pour charger le fichier audio enregistré et les scripts correspondants, effectuer l’apprentissage du modèle et déployer la voix sur un point de terminaison personnalisé.
Conseil
Essayez CNV Lite sous forme de version de démonstration afin d’évaluer la voix neuronale personnalisée avant d’investir dans des enregistrements professionnels pour créer une voix de meilleure qualité.
La création d’une voix neuronale personnalisée performante nécessite un contrôle qualité minutieux à chaque étape, depuis la conception de la voix et la préparation des données, jusqu’au déploiement du modèle vocal sur votre système.
Avant de commencer à utiliser Speech Studio, voici quelques points à prendre en compte :
- Concevez un personnage de la voix qui représente votre marque à l’aide d’un bref document définissant ce personnage. Ce document des éléments comme les caractéristiques de la voix et son caractère inhérent. Cela permet de guider le processus de création d’un modèle vocal neuronal personnalisé, notamment la définition des scripts, la sélection de l’artiste vocal, l’entraînement et le réglage de la voix.
- Sélectionnez le script d’enregistrement pour représenter les scénarios utilisateur de votre voix. Par exemple, vous pouvez utiliser les expressions issues des conversations de bot comme script d’enregistrement si vous créez un bot de service client. Incluez différents types de phrases dans vos scripts, notamment des affirmations, des questions et des exclamations.
Voici une vue d’ensemble des étapes de création d’une voix neuronale personnalisée dans Speech Studio :
- Créez un projet qui contiendra vos données, vos modèles vocaux, vos tests et vos points de terminaison. Chaque projet est spécifique à un pays/une région et une langue. Si vous voulez créer plusieurs voix, nous vous recommandons de créer un projet pour chaque voix.
- Configurer les artistes vocaux. Pour pouvoir entraîner une voix neuronale, vous devez d’abord envoyer un enregistrement de la déclaration de consentement de l’artiste vocal. La déclaration de l’artiste vocal est un enregistrement de l’artiste vocal qui lit une déclaration indiquant qu’il consent à ce que ses données vocales soient utilisées pour entraîner un modèle vocal personnalisé Custom Voice.
- Préparez les données d’entraînement au format approprié. Il est conseillé de capturer les enregistrements audio dans un studio d’enregistrement de qualité professionnelle pour obtenir un rapport signal/bruit élevé. La qualité du modèle vocal dépend fortement de vos données d’entraînement. Il est nécessaire de faire attention à l’homogénéité du volume, au débit de parole, à la tonalité et à la cohérence dans la manière de s’exprimer.
- Entraînez votre modèle vocal. Sélectionnez au moins 300 énoncés pour créer une voix neuronale personnalisée. Une série de vérifications de la qualité des données s’effectue automatiquement quand vous les chargez. Pour générer des modèles vocaux de haute qualité, vous devez corriger toutes les erreurs et soumettre à nouveau les données.
- Testez votre voix. Préparez des scripts de test pour votre modèle vocal qui couvrent les différents cas d’usage de vos applications. Il est judicieux d’utiliser des scripts au sein et en dehors du jeu de données d’entraînement afin que vous puissiez tester la qualité plus largement pour différents contenus.
- Déployez et utilisez votre modèle vocal dans vos applications.
Vous pouvez régler, ajuster et utiliser votre voix personnalisée, de la même manière que vous utilisiez une voix neuronale prédéfinie. Effectuez de la synthèse vocale en temps réel, ou générez du contenu audio hors connexion avec entrée de texte. Vous utilisez l’API REST, le Kit de développement logiciel (SDK) Speech ou Speech Studio.
Conseil
Vous pouvez également utiliser le SDK Speech et l’API REST de voix personnalisée pour effectuer l’apprentissage d’une voix neuronale personnalisée.
Consultez les exemples de code dans le référentiel du kit de développement logiciel (SDK) Speech sur GitHub pour découvrir comment utiliser une voix neuronale personnalisée dans votre application.
Le style et les caractéristiques du modèle vocal entraîné dépendent du style et de la qualité des enregistrements du talent vocal utilisé pour l’entraînement. Néanmoins, vous pouvez effectuer plusieurs ajustements à l’aide de SSML (Speech Synthesis Markup Language) quand vous effectuez les appels d’API à votre modèle vocal pour générer une voix de synthèse. SSML correspond au langage de balisage utilisé pour communiquer avec le service de synthèse vocale afin de convertir du texte en audio. Les ajustements que vous pouvez effectuer incluent la modification de la tonalité de la voix, le débit, l’intonation et la correction de la prononciation. Si le modèle vocal est généré avec plusieurs styles, vous pouvez également utiliser SSML pour passer de l’un à l’autre.
Séquence de composants
La voix neuronale personnalisée se compose de trois composants principaux : l’analyseur de texte, le modèle acoustique neuronal et le vocodeur neuronal. Pour générer une voix de synthèse naturelle à partir d’un texte, ce dernier est d’abord entré dans l’analyseur de texte, qui fournit une sortie sous la forme d’une séquence de phonèmes. Un phonème est une unité sonore de base qui distingue un mot d’un autre dans une langue particulière. Une séquence de phonèmes définit les prononciations des mots fournis dans le texte.
Ensuite, la séquence de phonèmes entre dans le modèle acoustique neuronal pour prédire les caractéristiques acoustiques qui définissent les signaux de parole. Les fonctionnalités acoustiques incluent le timbre, le type de diction, la vitesse d’élocution, les intonations et les modèles d’accent tonique. Enfin, le vocodeur neuronal convertit les caractéristiques acoustiques en ondes audibles afin de générer une voix de synthèse.
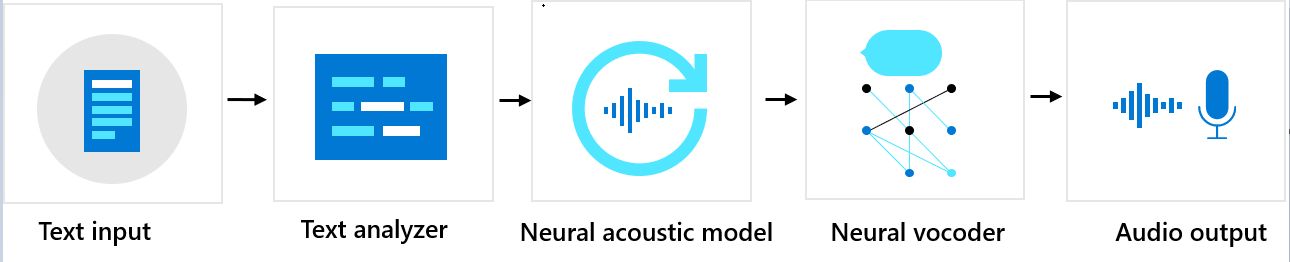
Les modèles vocaux de synthèse vocale neuronale sont entraînés à l’aide de réseaux neuronaux profonds basés sur des échantillons d’enregistrement de voix humaines. Pour plus d’informations, consultez ce billet de blog Microsoft. Pour en savoir plus sur la façon dont un vocodeur neuronal est entraîné, consultez ce billet de blog Microsoft.
Migrer vers la fonctionnalité Voix neuronale personnalisée
Si vous utilisez l’ancienne version de la voix neuronale (dont la mise hors service est prévue en février 2024), consultez Comment migrer vers la voix neuronale personnalisée.
IA responsable
Un système d’IA englobe non seulement la technologie, mais aussi ses utilisateurs, les personnes concernées et l’environnement dans lequel il est déployé. Lisez les notes de transparence pour en savoir plus sur l’utilisation et le déploiement d’une IA responsable dans vos systèmes.
- Note de transparence et cas d'usage pour la voix neuronale personnalisée
- Caractéristiques et limitations de l’utilisation de la voix neuronale personnalisée
- Accès limité à la voix neuronale personnalisée
- Instructions pour le déploiement responsable de la technologie des voix de synthèse
- Divulgation d'un talent vocal
- Guide de conception de la divulgation
- Modèles de conception de divulgation
- Code de conduite pour les intégrations de synthèse vocale
- Données, confidentialité et sécurité pour la voix neuronale personnalisée