Lire l’audio dans l’appel
L’action de lecture fournie dans le SDK Azure Communication Services Call Automation vous permet de diffuser des prompts audio auprès des participants de l’appel. Cette action est accessible par le biais de l’implémentation côté serveur de votre application. Vous pouvez lire du contenu audio pour appeler des participants via l’une des deux méthodes suivantes :
- Donner l’accès Azure Communication Services aux fichiers audio préenregistrés au format WAV, auxquels Azure Communication Services peut accéder avec prise en charge de l’authentification
- Texte standard qui peut être converti en sortie vocale par le biais de l’intégration à Azure AI services.
Vous pouvez utiliser l’intégration récemment annoncée entre Azure Communication Services et Azure AI services pour lire des réponses personnalisées à l’aide de la synthèse vocale Azure. Vous pouvez utiliser des voix neuronales prédéfinies de type humain prêtes à l’emploi, ou créer des voix neuronales personnalisées propres à votre produit ou à votre marque. Pour plus d’informations sur les voix, langues et paramètres régionaux pris en charge, consultez Prise en charge des langues et des voix pour le service Speech.
Remarque
Azure Communication Services prend actuellement en charge deux formats de fichiers, les fichiers MP3 avec ID3V2TAG et les fichiers WAV sous forme de contenu audio mono-canal PCM 16 bits enregistré à 16 KHz. Vous pouvez créer vos propres fichiers audio à l’aide de la Synthèse vocale avec l’outil de création de contenu audio.
Voix de synthèse vocale neuronales prédéfinies
Microsoft utilise des réseaux neuronaux profonds pour dépasser les limites de la synthèse vocale traditionnelle en ce qui concerne les accents toniques et les intonations dans le langage parlé. La prédiction prosodique et la synthèse vocale se produisent simultanément pour donner un résultat plus fluide et plus naturel. Vous pouvez utiliser ces voix neuronales pour rendre les interactions avec vos chatbots et assistants vocaux plus naturelles et plus agréables. Vous pouvez choisir parmi plus de 100 voix prédéfinies. En savoir plus sur les voix de synthèse vocale Azure.
Cas d’utilisation courants
L’action de lecture peut être utilisée de nombreuses façons par les développeurs dans leurs applications. En voici quelques exemples.
Annonces
Votre application lit une sorte d’annonce lorsqu’un participant rejoint ou quitte l’appel pour avertir les autres utilisateurs.
Clients en libre-service
Dans les scénarios avec réponse vocale interactive et assistants virtuels, vous pouvez utiliser votre application ou vos bots pour diffuser des invites audio auprès des appelants. Cette invite peut se présenter sous la forme d’un menu qui guide l’appelant dans son interaction.
Musique d’attente
L’action de lecture peut également être utilisée dans le but de jouer de la musique pour les appelants. Elle peut être configurée en boucle afin de continuer à diffuser la musique jusqu’à ce qu’un agent soit disponible pour aider l’appelant.
Messages de conformité
Dans le cadre des exigences de conformité de différents secteurs, les fournisseurs sont censés diffuser des messages juridiques ou de conformité aux appelants, par exemple « Cet appel est enregistré pour en évaluer la qualité ».
Exemple d’architecture pour la lecture audio dans un appel en utilisant la synthèse vocale
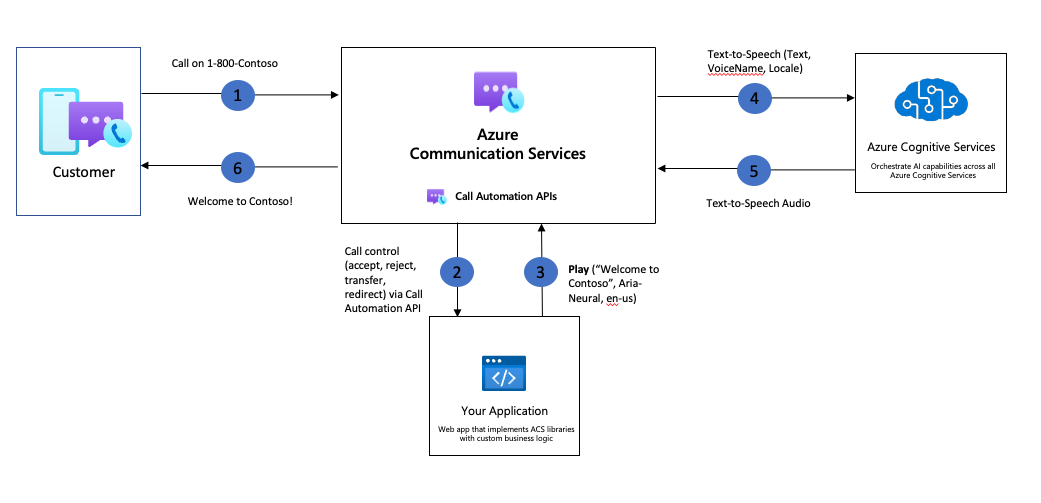
Exemple d’architecture pour la lecture audio dans un appel
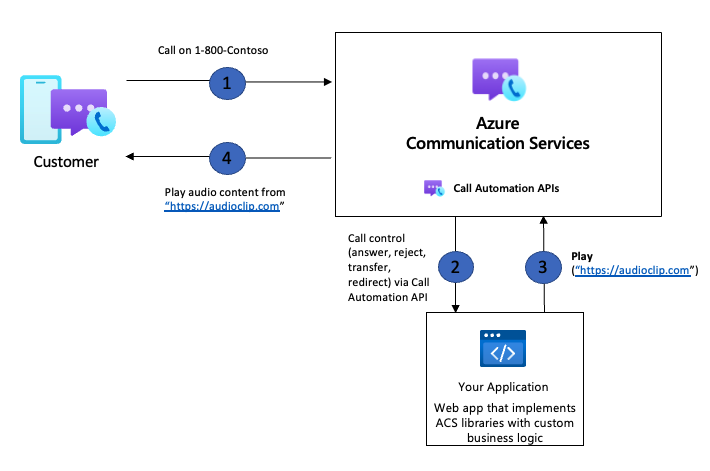
Limitations connues
- Les invites textuelles de synthèse vocale prennent en charge un maximum de 400 caractères. Si votre invite dépasse cette limite, nous vous conseillons d’utiliser SSML pour les actions de jeu basées sur la synthèse vocale.
- Si vous dépassez votre quota de service Speech, vous pouvez demander une augmentation de ce quota en suivant les étapes décrites ici.
Étapes suivantes
- Consultez notre guide pratique pour découvrir comment lire des invites vocales personnalisées pour les utilisateurs.
- Découvrez l’utilisation et les journaux opérationnels publiés par l’automatisation des appels.
- Découvrez la collecte des entrées client.