Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les applications conteneurisées peuvent s’exécuter sur de longues périodes, ce qui provoque des états rompus qui nécessitent parfois une réparation (redémarrage du conteneur). Azure Container Instances prend en charge les sondes probe liveness afin que vous puissiez configurer vos conteneurs dans votre groupe de conteneurs pour les redémarrer si des fonctionnalités critiques ne fonctionnent pas. La sonde probe liveness se comporte comme une sonde probe liveness Kubernetes.
Cet article explique comment déployer un groupe de conteneurs avec probe liveness, illustrant le redémarrage automatique d’un conteneur non intègre simulé.
Azure Container Instances prend également en charge les sondes probe readiness, que vous pouvez configurer pour vous assurer que le trafic atteint un conteneur uniquement quand ce dernier est prêt.
Déploiement YAML
Créez un fichier liveness-probe.yaml avec l’extrait de code suivant. Ce fichier définit un groupe composé d’un conteneur NGNIX qui finit par devenir non sain.
apiVersion: 2019-12-01
location: eastus
name: livenesstest
properties:
containers:
- name: mycontainer
properties:
image: mcr.microsoft.com/oss/nginx/nginx:1.15.5-alpine
command:
- "/bin/sh"
- "-c"
- "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
ports: []
resources:
requests:
cpu: 1.0
memoryInGB: 1.5
livenessProbe:
exec:
command:
- "cat"
- "/tmp/healthy"
periodSeconds: 5
osType: Linux
restartPolicy: Always
tags: null
type: Microsoft.ContainerInstance/containerGroups
Exécutez la commande suivante pour déployer ce groupe de conteneurs avec la configuration YAML précédente :
az container create --resource-group myResourceGroup --name livenesstest -f liveness-probe.yaml
Démarrer, commande
Le déploiement comprend une propriété command définissant une commande de démarrage qui s’exécute lors du premier démarrage du conteneur. Cette propriété accepte un tableau de chaînes. Cette commande simule le conteneur présentant un état non sain.
Il commence par démarrer une session bash et crée un fichier appelé healthy dans le répertoire /tmp. Il se met ensuite en veille pendant 30 secondes avant de supprimer le fichier, puis se remet en veille pendant 10 minutes :
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
Commande d’activité
Ce déploiement définit une livenessProbe prenant en charge une commande d’activité exec qui joue le rôle de vérification de l’activité. Si cette commande se termine sur une valeur différente de zéro, le conteneur est arrêté et redémarré, avec un message signalant que le fichier healthy est introuvable. Si cette commande se termine correctement avec le code de sortie 0, aucune action n'est entreprise.
La propriété periodSeconds signifie que la commande d’activité doit s’exécuter toutes les 5 secondes.
Vérifier la sortie d’activité
Pendant les 30 premières secondes, le fichier healthy créé par la commande de démarrage existe. Lorsque la commande d’activité vérifie l’existence du fichier healthy, le code d’état retourne 0, ce qui signale une réussite et dès lors, aucun redémarrage n'intervient.
Après 30 secondes, la commande cat /tmp/healthy commence à échouer, ce qui provoque l’apparition d’événements non sains et l’arrêt d’événements.
Vous pouvez voir ces événements dans le portail Azure et dans Azure CLI.
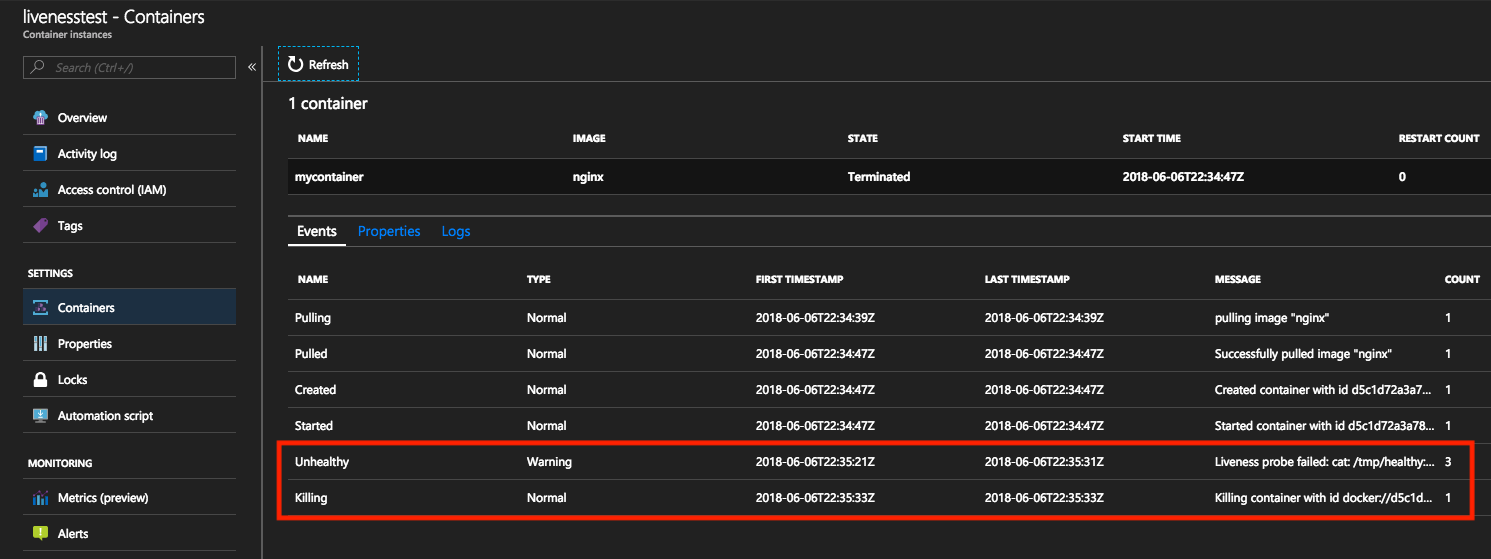
Si l’on consulte les événements sur le Portail Azure, les événements de type Unhealthy sont déclenchés à l’échec d’une commande d’activité. L’événement suivant est de type Killing, ce qui signifie la suppression d’un conteneur, permettant ainsi le lancement d’un redémarrage. Le nombre de redémarrages du conteneur s’incrémente à chaque occurrence de cet événement.
Les redémarrages sont effectués sur place afin de préserver les ressources comme les adresses IP publiques et les contenus propres aux nœuds.

Si la sonde probe liveness échoue constamment et déclenche trop de redémarrages, votre conteneur accuse un retard exponentiel.
Probe liveness et stratégies de redémarrage
Les stratégies de redémarrage annulent et remplacent le comportement de redémarrage déclenché par les sondes probe liveness. Par exemple, si vous définissez restartPolicy = Never et une sonde probe liveness, le groupe de conteneurs ne redémarre pas en raison de l’échec de la vérification de l’activité. Il respecte en revanche sa stratégie de redémarrage, soit Never.
Étapes suivantes
Les scénarios basés sur des tâches peuvent nécessiter qu’une sonde probe liveness autorise les redémarrages automatiques si une fonction prérequise ne fonctionne pas correctement. Pour plus d’informations sur l’exécution des conteneurs basés sur des tâches, consultez Exécuter des tâches en conteneur dans Azure Container Instances.