Ingérer dans Azure Cosmos DB for Apache Cassandra des données d’Apache Kafka à l’aide de Kafka Connect
S’APPLIQUE À : ![]() Cassandra
Cassandra
Les applications Cassandra existantes peuvent facilement fonctionner avec Azure Cosmos DB for Apache Cassandra en raison de la compatibilité de son pilote CQLv4. Vous tirez parti de cette capacité pour intégrer des plateformes de diffusion en continu, telles qu’Apache Kafka, et importer des données dans Azure Cosmos DB.
Les données qui se trouvent dans Apache Kafka (rubriques) sont utiles uniquement lorsqu’elles sont consommées par d’autres applications ou ingérées dans d’autres systèmes. Il est possible de créer une solution à l’aide des API Kafka Producer/Consumerà l’aide du langage et du Kit de développement logiciel (SDK) client de votre choix. Kafka Connect offre une solution alternative. Il s’agit d’une plateforme qui permet de transmettre en continu des données entre Apache Kafka et d’autres systèmes de manière évolutive et fiable. Étant donné que Kafka Connect prend en charge les connecteurs standard, dont Cassandra, vous n’avez pas besoin d’écrire de code personnalisé pour intégrer Kafka à Azure Cosmos DB for Apache Cassandra.
Dans cet article, nous utiliserons le connecteur open source DataStax Apache Kafka, qui fonctionne en complément de l’infrastructure Kafka Connect pour ingérer les enregistrements d’une rubrique Kafka dans les lignes d’une ou plusieurs tables Cassandra. L’exemple fournit une configuration réutilisable à l’aide de Docker Compose. C’est très pratique, car elle vous permet de démarrer tous les composants requis localement à l’aide d’une seule commande. Ces composants incluent Kafka, Zookeeper, le rôle de travail Kafka Connect et l’exemple d’une application de génération de données.
Voici une liste des composants et de leurs définitions de service. Vous pouvez vous référer au fichier docker-compose complet dans le référentiel GitHub.
- Kafka et Zookeeper utilisent des images debezium.
- Pour s’exécuter en tant que conteneur Docker, le connecteur DataStax Apache Kafka est intégré à une image Docker existante : debezium/connect-base. Cette image comprend une installation de Kafka et de ses bibliothèques Kafka Connect, ce qui rend l’ajout de connecteurs personnalisés très pratique. Vous pouvez vous référer au Dockerfile.
- Le service
data-generatoramorce des données générées de façon aléatoire (JSON) dans la rubrique Kafkaweather-data. Vous pouvez vous référer au code et auDockerfiledans le référentiel GitHub.
Prérequis
Créer un espace de clés et des tables et démarrer le pipeline d’intégration
À l’aide du portail Azure, créez l’espace de clés Cassandra et les tables nécessaires à l’application de démonstration.
Notes
Utilisez les mêmes noms d’espace de clés et de tables que ci-dessous.
CREATE KEYSPACE weather WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 1};
CREATE TABLE weather.data_by_state (station_id text, temp int, state text, ts timestamp, PRIMARY KEY (state, ts)) WITH CLUSTERING ORDER BY (ts DESC) AND cosmosdb_cell_level_timestamp=true AND cosmosdb_cell_level_timestamp_tombstones=true AND cosmosdb_cell_level_timetolive=true;
CREATE TABLE weather.data_by_station (station_id text, temp int, state text, ts timestamp, PRIMARY KEY (station_id, ts)) WITH CLUSTERING ORDER BY (ts DESC) AND cosmosdb_cell_level_timestamp=true AND cosmosdb_cell_level_timestamp_tombstones=true AND cosmosdb_cell_level_timetolive=true;
Clonez le référentiel GitHub :
git clone https://github.com/Azure-Samples/cosmosdb-cassandra-kafka
cd cosmosdb-cassandra-kafka
Démarrez tous les services :
docker-compose --project-name kafka-cosmos-cassandra up --build
Notes
Le téléchargement et le démarrage des conteneurs peuvent prendre un certain temps : il s’agit simplement d’un processus ponctuel.
Pour vérifier si tous les conteneurs ont démarré :
docker-compose -p kafka-cosmos-cassandra ps
L’application de génération de données commencera à pomper les données dans la rubrique weather-data dans Kafka. Vous pouvez également effectuer une rapide vérification de la validité pour confirmer. Apercevez le conteneur Docker qui exécute le rôle de travail Kafka Connect :
docker exec -it kafka-cosmos-cassandra_cassandra-connector_1 bash
Une fois que arrivé dans l’interpréteur de commandes du conteneur, démarrez simplement le processus habituel de consommation de la console Kafka. Vous devriez voir arriver les données météorologiques (au format JSON).
cd ../bin
./kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic weather-data
Configuration du connecteur Cassandra Sink
Copiez le contenu JSON ci-dessous dans un fichier (vous pouvez le nommer cassandra-sink-config.json). Vous devez le mettre à jour conformément à votre configuration, et le reste de cette section vous fournira des conseils à ce sujet.
{
"name": "kafka-cosmosdb-sink",
"config": {
"connector.class": "com.datastax.oss.kafka.sink.CassandraSinkConnector",
"tasks.max": "1",
"topics": "weather-data",
"contactPoints": "<cosmos db account name>.cassandra.cosmos.azure.com",
"port": 10350,
"loadBalancing.localDc": "<cosmos db region e.g. Southeast Asia>",
"auth.username": "<enter username for cosmosdb account>",
"auth.password": "<enter password for cosmosdb account>",
"ssl.hostnameValidation": true,
"ssl.provider": "JDK",
"ssl.keystore.path": "/etc/alternatives/jre/lib/security/cacerts/",
"ssl.keystore.password": "changeit",
"datastax-java-driver.advanced.connection.init-query-timeout": 5000,
"maxConcurrentRequests": 500,
"maxNumberOfRecordsInBatch": 32,
"queryExecutionTimeout": 30,
"connectionPoolLocalSize": 4,
"topic.weather-data.weather.data_by_state.mapping": "station_id=value.stationid, temp=value.temp, state=value.state, ts=value.created",
"topic.weather-data.weather.data_by_station.mapping": "station_id=value.stationid, temp=value.temp, state=value.state, ts=value.created",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"offset.flush.interval.ms": 10000
}
}
Voici un résumé des attributs :
Connectivité de base
contactPoints: entrez le point de contact pour Cassandra Azure Cosmos DBloadBalancing.localDc: entrez la région du compte Azure Cosmos DB, par exemple : Asie Sud-Estauth.username: entrez le nom d’utilisateurauth.password: entrez le mot de passeport: entrez la valeur du port (il s’agit de10350, pas de9042. Laisser tel quel)
Configuration SSL
Azure Cosmos DB assure une connectivité sécurisée par SSL et le connecteur Kafka Connect prend également en charge le protocole SSL.
ssl.keystore.path: chemin d’accès au magasin de clés JDK dans le conteneur :/etc/alternatives/jre/lib/security/cacerts/ssl.keystore.password: mot de passe du magasin de clés JDK (par défaut)ssl.hostnameValidation: nous désactivons la validation du nom d’hôte du nœudssl.provider:JDKest utilisé comme fournisseur SSL
Paramètres génériques
key.converter: nous utilisons le convertisseur de chaîneorg.apache.kafka.connect.storage.StringConvertervalue.converter: étant donné que les données des rubriques Kafka sont au format JSON, nous utilisonsorg.apache.kafka.connect.json.JsonConvertervalue.converter.schemas.enable: comme notre charge utile JSON n’a pas de schéma qui lui est associé (pour les besoins de l’application de démonstration), nous devons indiquer à Kafka Connect de ne pas rechercher de schéma en définissant cet attribut surfalse. Dans le cas contraire, cela entraînera des échecs.
Installation du connecteur
Installez le connecteur à l’aide du point de terminaison REST Kafka Connect :
curl -X POST -H "Content-Type: application/json" --data @cassandra-sink-config.json http://localhost:8083/connectors
Pour vérifier l’état :
curl http://localhost:8080/connectors/kafka-cosmosdb-sink/status
Si tout se passe bien, le connecteur doit commencer à faire son effet. Il doit s’authentifier auprès d’Azure Cosmos DB et commencer à ingérer des données de la rubrique Kafka (weather-data) dans les tables Cassandra (weather.data_by_state et weather.data_by_station).
Vous pouvez désormais interroger les données des tables. Accédez au portail Azure, puis affichez l’interpréteur de commandes CQL hébergé pour votre compte Azure Cosmos DB.
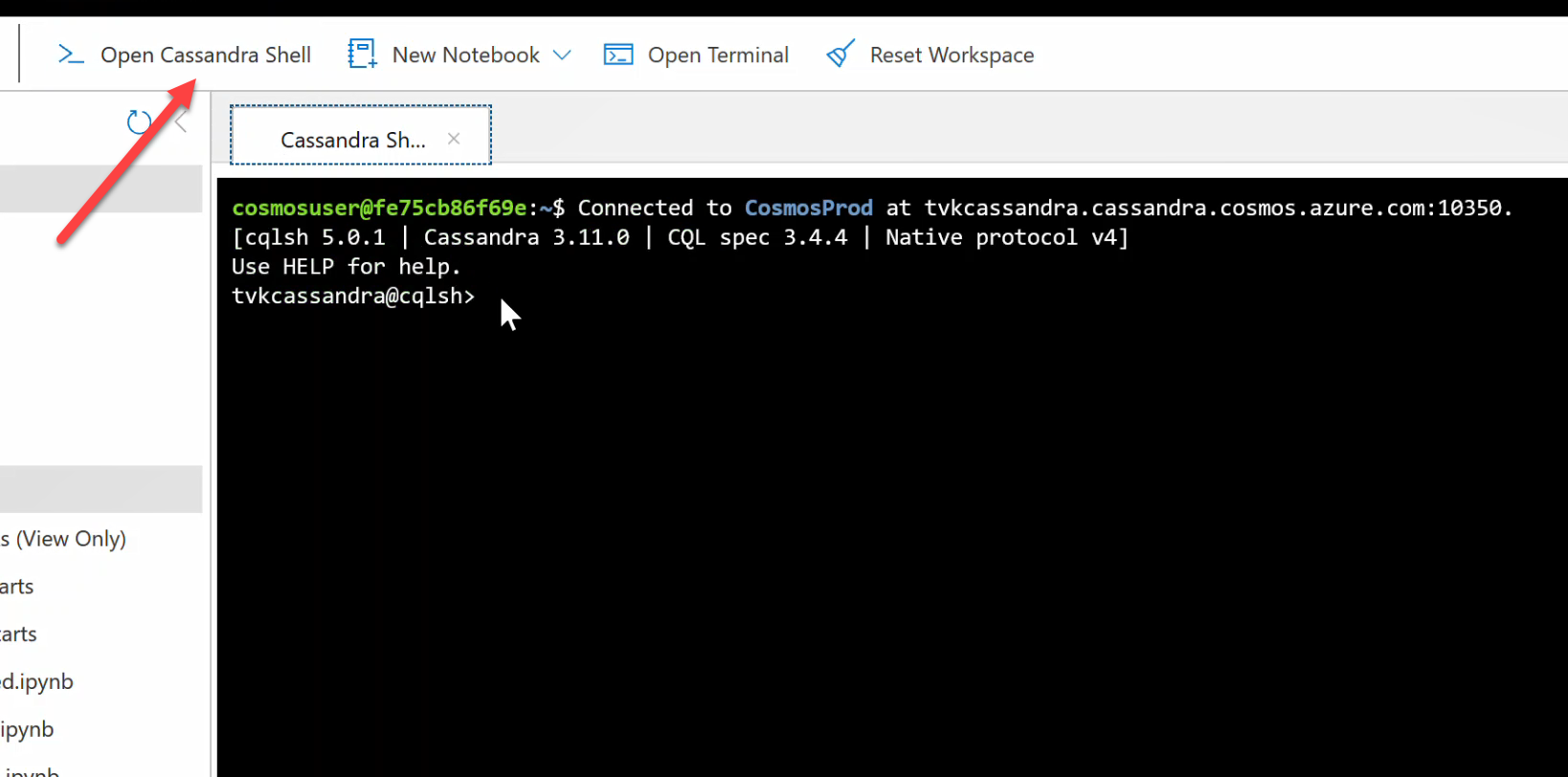
Interroger des données à partir d’Azure Cosmos DB
Vérifiez les tables data_by_state et data_by_station. Voici quelques exemples de requêtes pour vous aider à démarrer :
select * from weather.data_by_state where state = 'state-1';
select * from weather.data_by_state where state IN ('state-1', 'state-2');
select * from weather.data_by_state where state = 'state-3' and ts > toTimeStamp('2020-11-26');
select * from weather.data_by_station where station_id = 'station-1';
select * from weather.data_by_station where station_id IN ('station-1', 'station-2');
select * from weather.data_by_station where station_id IN ('station-2', 'station-3') and ts > toTimeStamp('2020-11-26');
Nettoyer les ressources
Quand vous en avez terminé avec votre application et votre compte Azure Cosmos DB, vous pouvez supprimer les ressources Azure que vous avez créées afin d’éviter des frais supplémentaires. Pour supprimer les ressources :
Depuis la barre de recherche du portail Azure, recherchez et sélectionnez Groupes de ressources.
Dans la liste, sélectionnez le groupe de ressources créé pour ce guide de démarrage rapide.
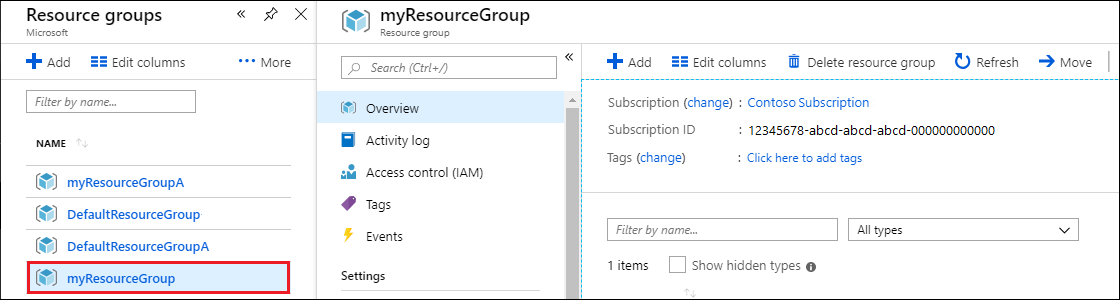
Dans la page Vue d’ensemble du groupe de ressources, sélectionnez Supprimer un groupe de ressources.
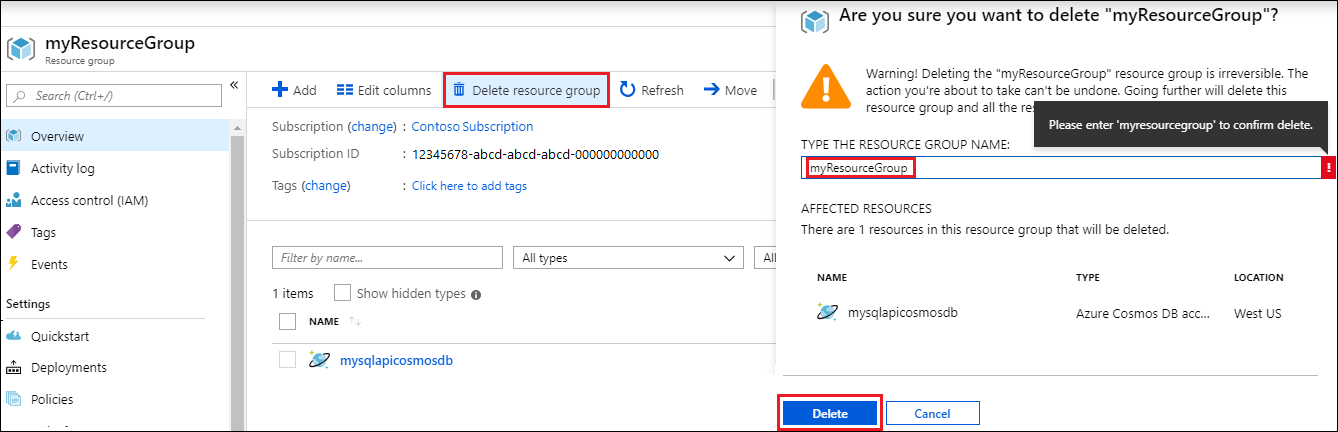
Dans la fenêtre suivante, entrez le nom du groupe de ressources à supprimer, puis sélectionnez Supprimer.