Migrer des données de Cassandra vers un compte Azure Cosmos DB for Apache Cassandra en utilisant Azure Databricks
S’APPLIQUE À : ![]() Cassandra
Cassandra
L’API pour Cassandra dans Azure Cosmos DB est devenue un excellent choix pour les charges de travail d’entreprise exécutées sur Apache Cassandra pour plusieurs raisons :
Pas de frais généraux de gestion et de surveillance : L’API élimine les frais généraux de gestion et de surveillance des paramètres dans les fichiers du système d’exploitation, les fichiers JVM et les fichiers YAML, ainsi que dans leurs interactions.
Des économies significatives : Vous pouvez réaliser des économies grâce à Azure Cosmos DB, notamment sur les machines virtuelles, la bande passante et les licences applicables. Vous n’avez pas à gérer les coûts liés aux centres de données, aux serveurs, au stockage SSD, à la mise en réseau et à la consommation électrique.
Possibilité d’utiliser le code et les outils existants : Azure Cosmos DB fournit une compatibilité au niveau du protocole filaire avec les Kits de développement logiciel (SDK) et les outils Cassandra existants. Cette compatibilité garantit la possibilité d’utiliser votre base de code avec Azure Cosmos DB for Apache Cassandra sans changements majeurs.
Il existe de nombreuses façons de migrer des charges de travail de base de données d’une plateforme vers une autre. Azure Databricks est une offre PaaS (platform as a service) pour Apache Spark permettant d’effectuer des migrations hors connexion à grande échelle. Cet article décrit les étapes à suivre pour migrer les données des espaces de clés et des tables Apache Cassandra vers Azure Cosmos DB for Apache Cassandra en utilisant Azure Databricks.
Prérequis
Approvisionner un compte Azure Cosmos DB for Apache Cassandra.
Passez en revue les principes fondamentaux de la connexion à Azure Cosmos DB for Apache Cassandra.
Passez en revue les fonctionnalités prises en charge dans Azure Cosmos DB for Apache Cassandra pour garantir la compatibilité.
Assurez-vous que vous avez déjà créé un espace de clés et des tables vides dans votre compte Azure Cosmos DB for Apache Cassandra cible.
Provisionner un cluster Azure Databricks
Vous pouvez suivre les instructions pour approvisionner un cluster Azure Databricks. Nous vous recommandons de sélectionner le runtime Databricks version 7.5, qui prend en charge Spark 3.0.
Ajout de dépendances
Vous devez ajouter la bibliothèque du connecteur Apache Spark Cassandra à votre cluster pour vous connecter aux points de terminaison Cassandra natifs et Azure Cosmos DB. Dans votre cluster, sélectionnez Bibliothèques>Installer nouveau>Maven, puis ajoutez com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 dans les coordonnées Maven.
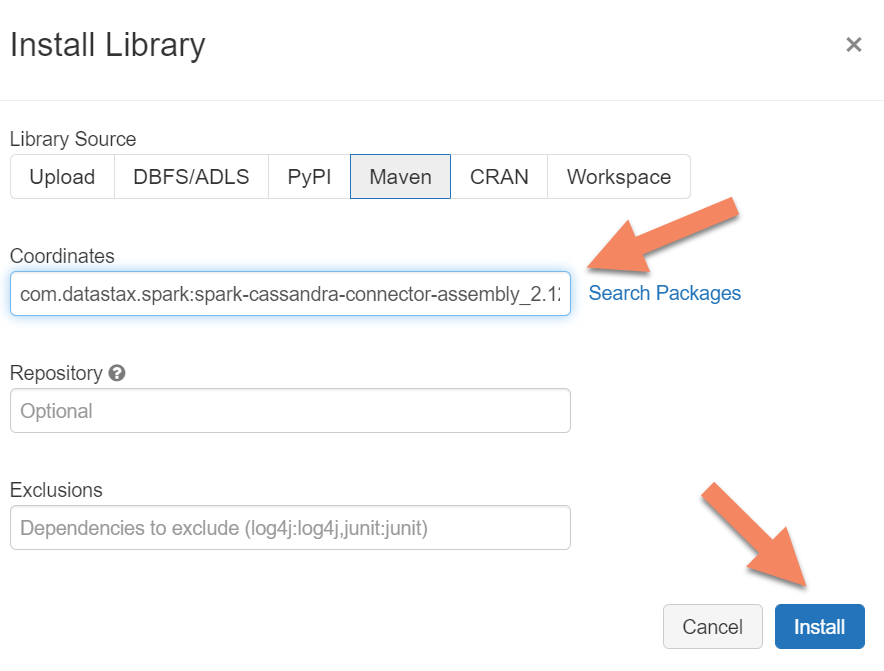
Sélectionnez Installer, puis redémarrez le cluster une fois l’installation terminée.
Notes
Veillez à redémarrer le cluster Databricks après l’installation de la bibliothèque du connecteur Cassandra.
Avertissement
Les exemples présentés dans cet article ont été testés avec Spark version 12:3.0.0 et le connecteur Spark Cassandra correspondant com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0. Les versions ultérieures de Spark et/ou du connecteur Cassandra peuvent ne pas fonctionner comme prévu.
Créer un notebook Scala pour la migration
Créez un notebook Scala dans Databricks. Remplacez vos configurations Cassandra source et cible par les informations d’identification correspondantes, ainsi que les espaces de clés et les tables sources et cibles. Exécutez ensuite le code suivant :
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val nativeCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val cosmosCassandra = Map(
"spark.cassandra.connection.host" -> "<USERNAME>.cassandra.cosmos.azure.com",
"spark.cassandra.connection.port" -> "10350",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
//"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1", // Spark 3.x
"spark.cassandra.connection.connections_per_executor_max"-> "1", // Spark 2.x
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from native Cassandra
val DFfromNativeCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(nativeCassandra)
.load
//Write to CosmosCassandra
DFfromNativeCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(cosmosCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Notes
Les valeurs spark.cassandra.output.batch.size.rows et spark.cassandra.output.concurrent.writes ainsi que le nombre de Workers dans votre cluster Spark sont des configurations importantes à régler afin d’éviter la limitation du débit. La limitation du débit se produit lorsque les demandes adressées à Azure Cosmos DB dépassent le débit approvisionné ou les unités de requête (RU). Vous devrez peut-être ajuster ces paramètres en fonction du nombre d’Exécuteurs dans le cluster Spark, voire de la taille (et par conséquent du coût en RU) de chaque enregistrement écrit dans les tables cibles.
Dépanner
Limitation du débit (erreur 429)
Il se peut que le code d’erreur 429 ou le texte d’erreur « Le taux de demandes est élevé » s’affiche même si vous avez réduit les paramètres à leur valeur minimale. Les scénarios suivants peuvent entraîner une limitation du débit :
Le débit alloué à la table est inférieur à 6 000 unités de requête . Même avec les paramètres minimaux, Spark peut écrire à un débit d’environ 6 000 unités de requête ou plus. Si vous avez approvisionné une table dans un espace de clés avec un débit partagé, il est possible que cette table ait moins de 6 000 RU disponibles au moment de l’exécution.
Assurez-vous que la table vers laquelle vous effectuez la migration dispose d’au moins 6 000 RU disponibles au moment de l’exécution de la migration. Si nécessaire, allouez des unités de requête dédiées à cette table.
Asymétrie excessive des données avec un volume important de données. Si vous avez une grande quantité de données à migrer vers une table donnée, mais que les données présentent un asymétrie importante (c’est-à-dire qu’un grand nombre d’enregistrements sont écrits pour la même valeur de clé de partition), vous pouvez quand même subir une limitation de débit, même si vous avez approvisionné plusieurs unités de requête dans votre table. Les unités de requête sont réparties de manière égale entre les partitions physiques, et une forte asymétrie des données peut provoquer un goulot d’étranglement des requêtes adressées à une seule partition.
Dans ce scénario, réduisez au minimum les paramètres de débit dans Spark et forcez la migration à s’exécuter lentement. Ce scénario peut être plus courant lorsque vous migrez des tables de référence ou de contrôle, où l’accès est moins fréquent et où l’asymétrie peut être importante. Toutefois, si une asymétrie significative est présente dans un autre type de table, vous pouvez passer en revue votre modèle de données pour éviter les problèmes de partition chaude pour votre charge de travail pendant les opérations à l’état stable.