Partitionnement dans Azure Cosmos DB for Apache Cassandra
S’APPLIQUE À : ![]() Cassandra
Cassandra
Cet article décrit le fonctionnement du partitionnement dans Azure Cosmos DB for Apache Cassandra.
L'API pour Cassandra utilise le partitionnement pour procéder à la mise à l'échelle des différentes tables d'un espace de clés afin de répondre aux besoins de performances de votre application. Les partitions sont formées en fonction de la valeur d'une clé de partition associée à chaque enregistrement d'une table. Tous les enregistrements d'une partition possèdent la même valeur de clé de partition. Azure Cosmos DB gère de manière transparente et automatique le positionnement des partitions sur les ressources physiques afin de répondre efficacement aux besoins de scalabilité et de performances de la table. À mesure que le débit et le stockage requis par une application augmentent, Azure Cosmos DB déplace et équilibre les données sur un plus grand nombre de machines physiques.
Du point de vue du développeur, le comportement de partitionnement d’Azure Cosmos DB for Apache Cassandra est quasiment identique à celui d’Apache Cassandra natif. Il existe toutefois quelques différences.
Différences entre Apache Cassandra et Azure Cosmos DB
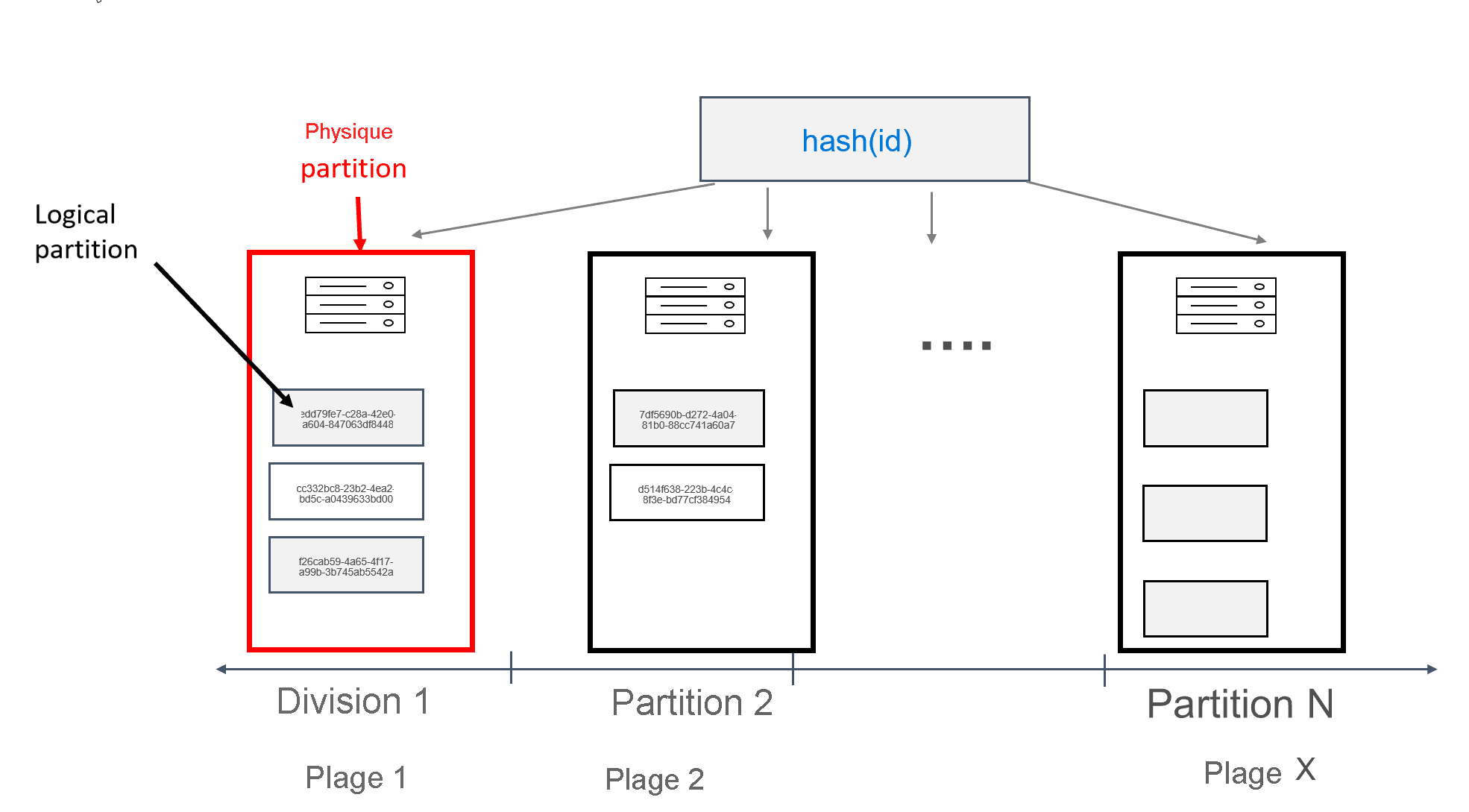
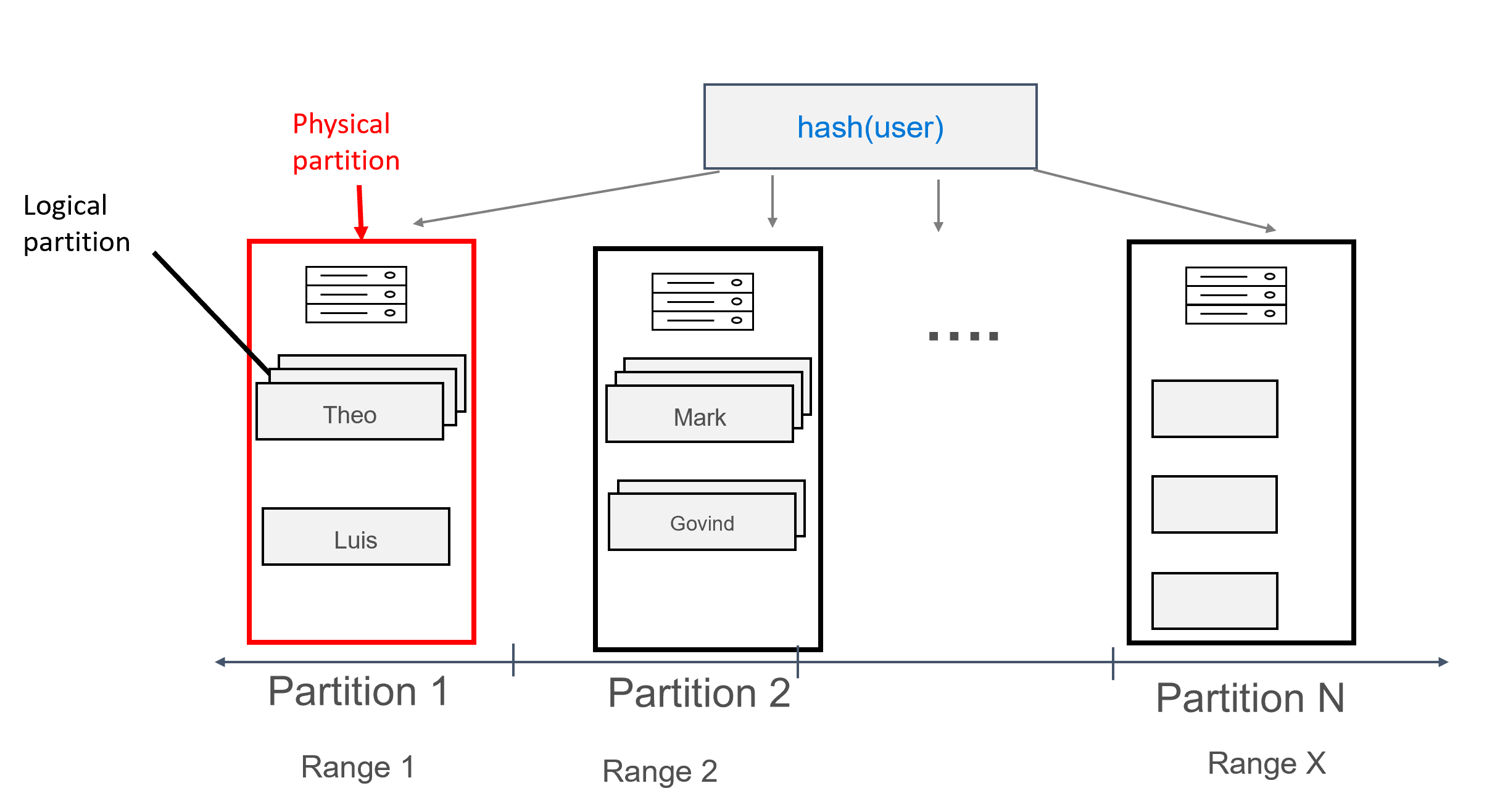
Dans Azure Cosmos DB, chaque machine sur laquelle des partitions sont stockées est elle-même appelée partition physique. La partition physique est semblable à une machine virtuelle puisqu'il s'agit d'une unité Compute dédiée ou d'un ensemble de ressources physiques. Dans Azure Cosmos DB, chaque partition stockée sur cette unité Compute est appelée partition logique. Si vous connaissez déjà Apache Cassandra, les partitions logiques sont comparables aux partitions standard de Cassandra.
Apache Cassandra recommande de limiter à 100 Mo la taille des données qui peuvent être stockées dans une partition. L'API pour Cassandra pour Azure Cosmos DB prend en charge jusqu’à 20 Go par partition logique, et jusqu’à 30 Go de données par partition physique. Dans Azure Cosmos DB, contrairement à Apache Cassandra, la capacité de calcul disponible dans la partition physique est exprimée à l'aide d'une métrique appelée unité de requête (RU), qui vous permet d'aborder votre charge de travail en termes de requêtes (lectures ou écritures) par seconde, plutôt qu'en termes de cœurs, de mémoire ou d'IOPS. Une fois que vous avez identifié le coût de chaque requête, la planification des capacités est plus simple. Chaque partition physique peut disposer d'un maximum de 10 000 RU de calcul. Pour en savoir plus sur les options de scalabilité, lisez l'article consacré à la mise à l'échelle élastique dans l'API pour Cassandra.
Dans Azure Cosmos DB, chaque partition physique se compose d'un ensemble de réplicas, également appelés jeux de réplicas, avec au moins 4 réplicas par partition. Cela contraste avec Apache Cassandra, où la définition d'un facteur de réplication de 1 est possible. Toutefois, cela aboutit à une faible disponibilité si le seul nœud qui contient les données tombe en panne. Dans l'API pour Cassandra, le facteur de réplication est toujours de 4 (quorum de 3). Azure Cosmos DB gère automatiquement les jeux de réplicas, alors que dans Apache Cassandra ceux-ci doivent être gérés à l'aide de divers outils.
Apache Cassandra présente un concept de jetons, qui correspondent à des hachages de clés de partition. Les jetons sont basés sur un hachage murmur3 de 64 octets, avec des valeurs allant de -2^63 à -2^63 - 1. Cette plage est communément appelée « Token Ring » dans Apache Cassandra. Le « Token Ring » est réparti en plages de jetons, et ces plages sont elles-mêmes réparties entre les nœuds présents dans un cluster Apache Cassandra natif. L’implémentation du partitionnement pour Azure Cosmos DB est similaire, si ce n’est qu’elle utilise un algorithme de hachage différent et a un plus grand « Token Ring » interne. Toutefois, en externe, nous exposons la même plage de jetons qu’Apache Cassandra, à savoir de -2^63 à -2^63 - 1.
Clé primaire
Une primary key doit être définie pour toutes les tables de l'API pour Cassandra. La syntaxe d'une clé primaire est la suivante :
column_name cql_type_definition PRIMARY KEY
Supposons que nous voulions créer une table d'utilisateurs qui stocke les messages de différents utilisateurs :
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
Dans cette conception, nous avons défini le champ id comme clé primaire. La clé primaire sert à identifier l'enregistrement dans la table, et elle est également utilisée comme clé de partition dans Azure Cosmos DB. Si la clé primaire est définie comme décrit précédemment, il n'y aura qu'un seul enregistrement dans chaque partition. Cela se traduira par une répartition parfaitement horizontale et évolutive lors de l'écriture de données dans la base de données, ce qui est idéal pour les cas d'usage de recherche de valeurs-clés. L'application doit fournir la clé primaire lors de la lecture des données de la table, afin d'optimiser les performances de lecture.
Clé primaire composée
Apache Cassandra présente également un concept de compound keys. Une primary key composée comprend plusieurs colonnes, la première pour la partition key et les autres colonnes pour les clustering keys. La syntaxe d'une compound primary key est la suivante :
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
Supposons que nous voulions modifier la conception ci-dessus et permettre une récupération efficace des messages d'un utilisateur donné :
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
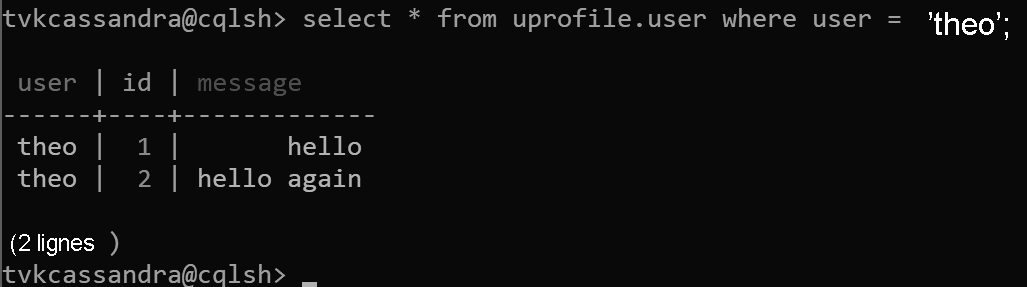
Dans cette conception, nous définissons maintenant user comme clé de partition et id comme clé de clustering. Vous pouvez définir autant de clés de clustering que vous le souhaitez, mais chaque valeur (ou combinaison de valeurs) de la clé de clustering doit être unique afin que plusieurs enregistrements soient ajoutés à la même partition, par exemple :
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
Lorsque les données sont renvoyées, elles sont triées en fonction de la clé de clustering, comme prévu dans Apache Cassandra :
Avertissement
Lorsque vous interrogez les données d’une table constituée d’une clé primaire composée, si vous voulez filtrer sur la clé de partition et tous les autres champs non indexés à part la clé de clustering, veillez à ajouter explicitement un index secondaire au niveau de la clé de partition :
CREATE INDEX ON uprofile.user (user);
Azure Cosmos DB for Apache Cassandra n’applique pas les index aux clés de partition par défaut et l’index dans ce scénario peut améliorer considérablement les performances des requêtes. Pour plus d’informations, consultez notre article sur l'indexation secondaire .
Avec des données ainsi modélisées, plusieurs enregistrements, regroupés par utilisateur, peuvent être attribués à chaque partition. Nous pouvons donc émettre une requête qui est efficacement acheminée par la partition key (dans ce cas, user) pour obtenir tous les messages d'un utilisateur donné.
Clé de partition composite
Le fonctionnement des clés de partition composites est globalement identique à celui des clés composées, sauf que vous pouvez spécifier plusieurs colonnes comme clé de partition composite. La syntaxe des clés de partition composite est la suivante :
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
Par exemple, ci-dessous, la combinaison unique de firstname et lastname forme la clé de partition, et id correspond à la clé de clustering :
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );
Étapes suivantes
- En savoir plus sur le partitionnement et la mise à l’échelle horizontale dans Azure Cosmos DB.
- Apprenez-en davantage sur le débit approvisionné dans Azure Cosmos DB.
- Renseignez-vous sur la distribution globale dans Azure Cosmos DB.