Distribution de données mondiale avec Azure Cosmos DB - Sous le capot
S’APPLIQUE À : ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
Cosmos DB étant un service fondamental dans Azure, il est déployé dans toutes les régions Azure du monde entier, dont les clouds publics, souverains, du ministère de la Défense et du secteur public.
À un niveau élevé, les données des conteneurs Azure Cosmos DB sont partitionnées horizontalement en plusieurs réplicas, qui répliquent les écritures, dans chaque région. Les jeux de réplicas s’engagent de manière durée à l’aide d’un vote pour la majorité.
Chaque région contient toutes les partitions de données d’un conteneur Azure Cosmos DB, et peut servir des écritures quand les écritures multirégions sont activées. Si votre compte Azure Cosmos DB est distribué entre N régions Azure, il y aura au moins N x 4 copies de toutes vos données.
À l’intérieur d’un centre de données, nous déployons et gérons Azure Cosmos DB sur des tampons massifs de machines, chacune avec un stockage local dédié. À l’intérieur d’un centre de données, Cosmos DB est déployé dans de nombreux clusters, chacun pouvant exécuter plusieurs générations de matériel. Les machines au sein d’un cluster sont généralement réparties sur 10 à 20 domaines d’erreur pour assurer la haute disponibilité au sein d’une région. L’image suivante montre la topologie du système de distribution mondiale Azure Cosmos DB :
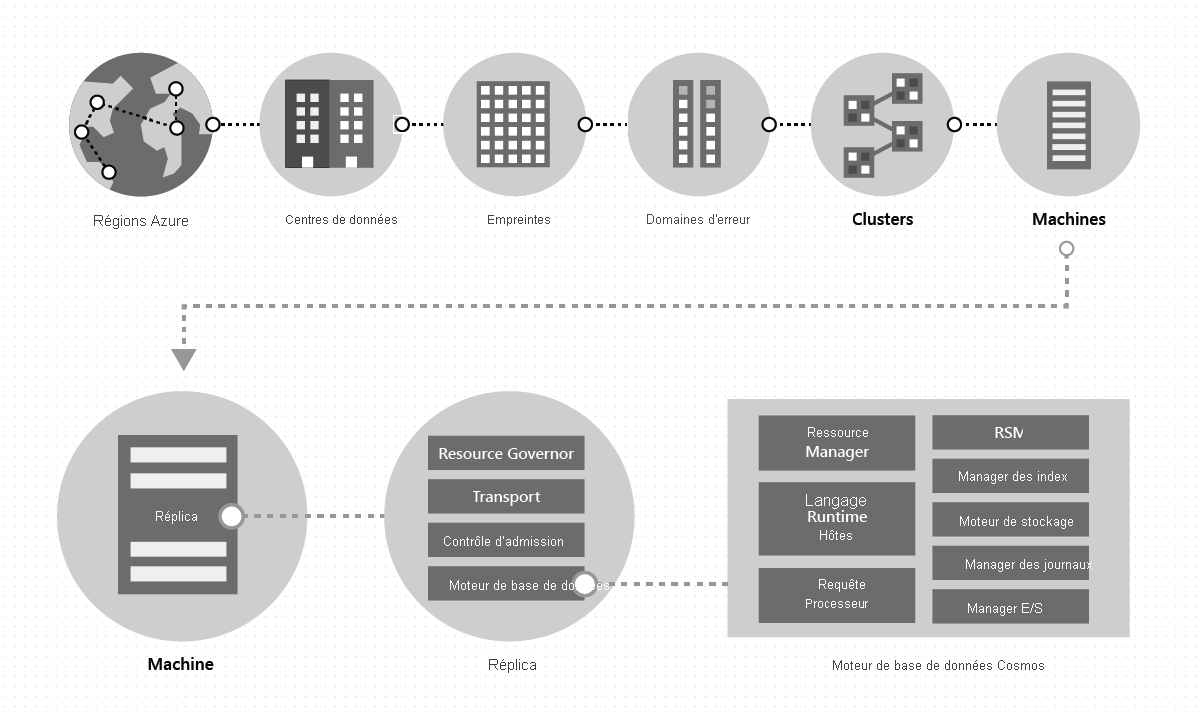
La distribution globale dans Azure Cosmos DB est une solution clé en main : à tout moment, en quelques clics ou par programmation à l’aide d’un appel d’API, vous pouvez ajouter ou supprimer les régions géographiques associées à votre base de données Azure Cosmos DB. Une base de données Azure Cosmos DB, à son tour, se compose d’un ensemble de conteneurs Azure Cosmos DB. Dans Azure Cosmos DB, les conteneurs font office d’unités logiques de distribution et d’extensibilité. Les collections, tables et graphiques que vous créez sont (en interne) tout simplement des conteneurs Azure Cosmos DB. Les conteneurs sont totalement indépendants du schéma et fournissent une étendue pour les requêtes. Les données d’un conteneur Azure Cosmos DB sont automatiquement indexées lors de l’ingestion. L’indexation automatique permet aux utilisateurs d’interroger les données sans les tracas associés à la gestion du schéma ou de l’index, en particulier dans une configuration globalement distribuée.
Dans une région spécifique, les données d’un conteneur sont distribuées à l’aide d’une clé de partition que vous fournissez, et gérées de manière transparente par les partitions physiques sous-jacentes (distribution locale).
Chaque partition physique est également répliquée entre les régions géographiques (distribution mondiale).
Quand une application utilisant Azure Cosmos DB met à l’échelle le débit de façon élastique sur un conteneur Azure Cosmos DB ou consomme davantage de stockage, Azure Cosmos DB gère de manière transparente les opérations de gestion des partitions (fractionnement, clonage, suppression) dans toutes les régions. Indépendamment de l’échelle, de la distribution ou des défaillances, Azure Cosmos DB continue à fournir une illustration système unique des données à l’intérieur des conteneurs globalement distribués dans un nombre quelconque de régions.
Comme le montre l’illustration suivante, les données d’un conteneur sont distribuées en deux dimensions - dans une ou plusieurs régions, à l’échelle mondiale :
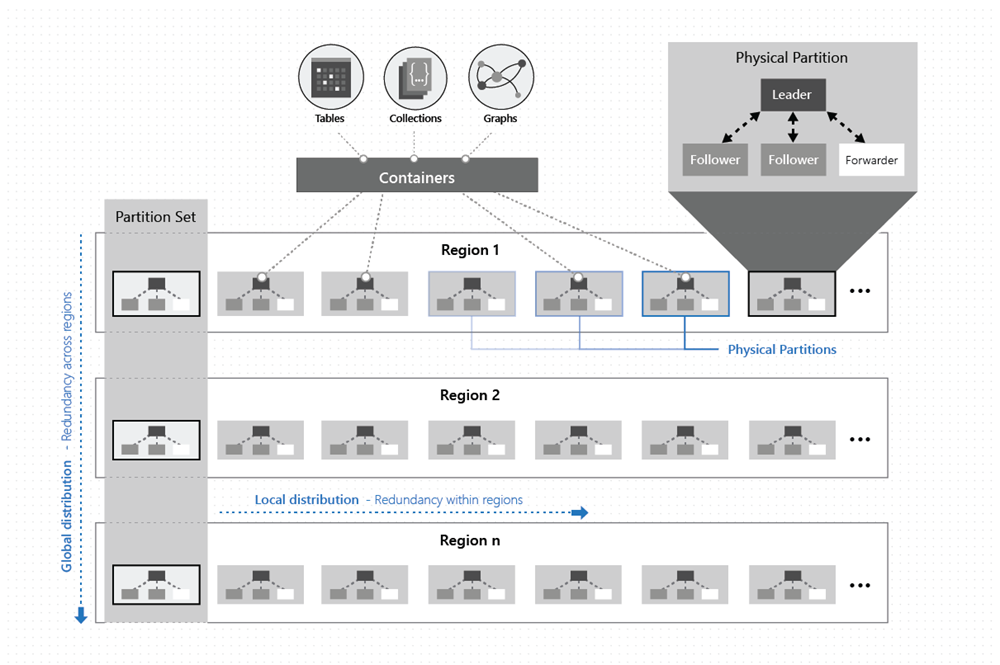
Une partition physique est implémentée par un groupe de réplicas appelé jeu de réplicas. Chaque machine héberge des centaines de réplicas correspondant à diverses partitions physiques au sein d’un ensemble fixe de processus, comme le montre l’illustration ci-dessus. Les réplicas correspondant aux partitions physiques sont distribués de façon dynamique, et leur charge est équilibrée sur les machines au sein d’un cluster, et sur les centres de données au sein d’une région.
Un réplica n’appartient qu’à un seul client Azure Cosmos DB. Chaque réplica héberge une instance du moteur de base de données d’Azure Cosmos DB, qui gère les ressources ainsi que les index associés. Le moteur de base de données d’Azure Cosmos DB opère sur un système type basé sur ARS. Le moteur ignore le concept de schéma et brouille la frontière entre la structure et les valeurs d’instance des enregistrements. Azure Cosmos DB parvient à une indépendance complète du schéma en indexant automatiquement et efficacement tout ce qui est ingéré, ce qui permet aux utilisateurs d’interroger leurs données globalement distribuées sans devoir se préoccuper du schéma ou de la gestion d’index.
Le moteur de base de données d’Azure Cosmos DB consiste en composants incluant l’implémentation de primitives de coordination, les runtimes de langage, le processeur de requêtes ainsi que les sous-systèmes de stockage et d’indexation responsables du stockage transactionnel et de l’indexation des données. Pour assurer la durabilité et la haute disponibilité, le moteur de base de données conserve ses données et son index sur des disques SSD, et les réplique sur les instances de moteur de base de données à l’intérieur des jeux de réplicas. Les locataires plus importants correspondent à une échelle plus élevée de débit et de stockage, et disposent de réplicas de plus grande capacité ou en plus grand nombre, voire des deux. Chaque composant du système étant entièrement asynchrone, jamais un thread ne bloque, et chaque thread effectue un travail de courte durée n’induisant pas de basculements de thread superflus. Une limitation du débit et une contre-pression sont appliquées à la pile entière, du contrôle d’admission à tous les chemins d’E/S. Le moteur de base de données Azure Cosmos DB est conçu pour exploiter un accès concurrentiel de granularité fine et fournir un débit élevé tout en opérant avec une quantité réduite de ressources système.
La distribution globale d’Azure Cosmos DB repose sur deux abstractions clés, les jeux de réplicas et les groupes de partitions. Un jeu de réplicas est un bloc modulaire utilisé pour la coordination, et un groupe de partitions est une superposition dynamique de partitions physiques distribuées géographiquement. Pour comprendre le fonctionnement de la distribution globale, nous devons comprendre ces deux abstractions clés.
Jeux de réplicas
Une partition physique est matérialisée sous la forme d’un groupe de réplicas auto-géré et dont la charge est équilibrée de façon dynamique, réparti sur plusieurs domaines d’erreur, appelé jeu de réplicas. Celui-ci implémente collectivement le protocole de machine à état répliqué pour rendre les données de la partition physique hautement disponibles, durables et cohérentes. L’appartenance au jeu de réplicas N est dynamique. Elle fluctue entre NMin et NMax en fonction des échecs, des opérations d’administration et du délai de régénération/récupération des réplicas ayant échoué. En fonction des changements d’appartenance, le protocole de réplication reconfigure également la taille des quorums de lecture et d’écriture. Pour distribuer uniformément le débit affecté à une partition physique donnée, nous appliquons deux idées :
Tout d’abord, le coût de traitement des demandes d’écriture sur le leader est plus élevé que celui de l’application des mises à jour sur l’abonné. En conséquence, davantage de ressources système son budgétées pour le leader en comparaison des abonnés.
Deuxièmement, autant que possible, le quorum de lecture pour un niveau de cohérence donné est composé exclusivement des réplicas d’abonnés. Nous évitons de contacter le leader pour servir les lectures, sauf si cela est indispensable. Nous appliquons diverses idées issues des recherches menées sur la relation entre la charge et la capacité dans les systèmes basés sur un quorum pour les cinq modèles de cohérence pris en charge par Azure Cosmos DB.
Groupes de partitions
Un groupe de partitions physiques, une de chacune des régions configurées avec la base de données Azure Cosmos DB, est composé pour gérer le même ensemble de clés répliqué dans toutes les régions configurées. Cette primitive de coordination supérieure est appelée groupe de partitions. Il s’agit d’une superposition dynamique distribuée géographiquement de partitions physiques gérant un ensemble de clés donné. Si une partition physique (un jeu de réplicas) est circonscrite à l’intérieur d’un cluster, un groupe de partitions peut couvrir plusieurs clusters, centres de données et régions géographiques, comme le montre l’illustration ci-dessous :
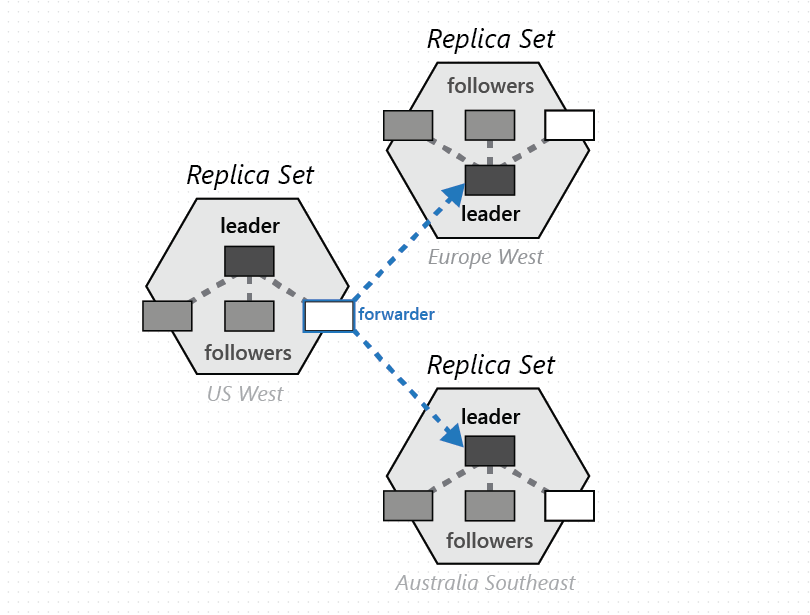
Vous pouvez considérer un jeu de partitions comme un « super jeu de réplicas » dispersé géographiquement, composé de plusieurs jeux de réplicas possédant le même ensemble de clés. De façon similaire à un jeu de réplicas, l’appartenance à un groupe de partitions est dynamique. Elle varie en fonction des opérations de gestion de partition physique implicites pour ajouter/supprimer des partitions dans un groupe de partitions donné (par exemple, quand vous effectuez un scale-out du débit sur un conteneur, ajoutez/supprimez une région pour votre base de données Azure Cosmos DB ou en cas d’échec). Étant donné que chaque partition (d’un groupe de partitions) gère l’appartenance au groupe de partitions à l’intérieur de son propre jeu de réplicas, l’appartenance est entièrement décentralisée et hautement disponible. Lors de la reconfiguration d’un groupe de partitions, la topologie de la superposition entre les partitions physiques est également établie. La topologie est sélectionnée de façon dynamique en fonction du niveau de cohérence, de la distance géographique et de la bande passante réseau disponible entre les partitions physiques source et cible.
Le service vous permet de configurer vos bases de données Azure Cosmos DB avec une ou plusieurs régions d’écriture. Selon le choix opéré, des groupes de partitions sont configurés pour accepter les écritures dans une région précise ou dans toutes les régions. Le système utilise un protocole consensuel imbriqué à deux niveaux. Un niveau opère à l’intérieur des réplicas d’un jeu de réplicas d’une partition physique acceptant les écritures, et l’autre opère au niveau d’un groupe de partitions pour fournir des garanties d’ordre complètes pour toutes les écritures validées à l’intérieur du groupe de partitions. Ce consensus imbriqué à plusieurs niveaux est vital pour l’implémentation de nos contrats SLA rigoureux en matière de haute disponibilité, ainsi que pour l’implémentation des modèles de cohérence qu’Azure Cosmos DB offre à ses clients.
Résolution de conflits
Notre conception de la propagation des mises à jour, de la résolution des conflits et du suivi de la causalité s’inspire de travaux antérieurs menés sur les algorithmes épidémiques et le système Bayou. Si les noyaux des idées ont survécu et offrent un cadre de référence commode pour communiquer la conception de système d’Azure Cosmos DB, ils ont également subi une transformation importante au fur et à mesure de leur application au système Azure Cosmos DB. Cela était nécessaire car les systèmes précédents n’étaient conçus ni avec la gouvernance des ressources, ni avec l’échelle à laquelle Azure Cosmos DB doit opérer, ni pour offrir les capacités (par exemple, la cohérence en fonction de l’obsolescence limitée) et les contrats SLA rigoureux et complets qu’Azure Cosmos DB offre à ses clients.
Rappelons qu’un groupe de partitions est distribué dans plusieurs régions et suit le protocole de réplication (écritures multirégions) d’Azure Cosmos DB pour répliquer les données sur les partitions physiques constituant un groupe de partitions donné. Chaque partition physique (d’un groupe de partitions) accepte des écritures et sert des lectures, généralement aux clients locaux dans cette région. Les écritures acceptées par une partition physique à l’intérieur d’une région sont validées durablement et rendues hautement disponibles à l’intérieur de la partition physique avant d’être confirmées au client. Il s’agit d’écritures provisoires propagées à d’autres partitions physiques à l’intérieur du groupe de partitions à l’aide d’un canal anti-entropie. Les clients peuvent demander des écritures provisoires ou validées en transmettant un en-tête de requête. La propagation anti-entropie (y compris la fréquence de propagation) est dynamique, basée sur la topologie du groupe de partitions, la proximité régionale des partitions physiques et le niveau de cohérence configuré. À l’intérieur d’un groupe de partitions, Azure Cosmos DB suit un schéma de validation principal avec une partition arbitre sélectionnée de manière dynamique. La sélection de l’arbitre est dynamique et fait partie intégrante de la reconfiguration du jeu de partitions en fonction de la topologie de la superposition. Les écritures validées (dont les mises à plusieurs lignes/par lots) sont garanties ordonnées.
Nous employons des horloges vectorielles codées (contenant un identificateur de région et des horloges logiques correspondant à chaque niveau de consensus respectivement du jeu de réplicas et du groupe de partitions) pour le suivi de la causalité et les vecteurs de version afin de détecter et résoudre les conflits de mises à jour. La topologie et l’algorithme de sélection de pair sont conçus pour assurer un stockage fixe minimal et une surcharge réseau minimale des vecteurs de version. L’algorithme garantit la propriété de convergence stricte.
Pour les bases de données Azure Cosmos DB configurées avec plusieurs régions d’écriture, le système offre des stratégies flexibles de résolution automatique des conflits parmi lesquelles les développeurs peuvent choisir, notamment :
- Stratégie Dernière écriture prioritaire (LWW) qui, par défaut, utilise une propriété timestamp définie par le système (basée sur le protocole d’horloge de synchronisation de l’heure). Azure Cosmos DB vous permet également de spécifier toute autre propriété numérique personnalisée à utiliser pour la résolution des conflits.
- Stratégie (personnalisée) de résolution des conflits définie par l’application (exprimée via des procédures de fusion), conçue pour la réconciliation sémantique définie par l’application des conflits. Ces procédures sont appelées lors de la détection de conflits d’écriture-écriture sous les auspices d’une transaction de base de données côté serveur. Le système fournit exactement une garantie pour l’exécution d’une procédure de fusion dans le cadre du protocole d’engagement. Plusieurs échantillons de résolution des conflits sont à votre disposition.
Modèles de cohérence
Que vous configuriez votre base de données Azure Cosmos DB avec une ou plusieurs régions d’écriture, vous pouvez choisir parmi les cinq modèles de cohérence bien définis. Avec plusieurs régions d’écriture, voici quelques aspects remarquables des niveaux de cohérence :
La cohérence en fonction de l’obsolescence limitée garantit que toutes les lectures auront lieu dans les k préfixes ou T secondes suivant la dernière écriture dans toute région. De plus, les lectures avec cohérence en fonction de l’obsolescence limitée sont garanties unitones et assorties de garanties de préfixe cohérent. Le protocole anti-entropie opère avec une limite de débit, et garantit que les préfixes ne s’accumulent pas et que la contre-pression sur les écritures ne doive pas être appliquée. La cohérence de session garantit une lecture et une écriture unitones, la lecture de votre propre écriture, que l’écriture suive la lecture, ainsi qu’un préfixe cohérent, dans le monde entier. Pour les bases de données configurées avec une cohérence forte, les avantages (faible latence d’écriture, haute disponibilité d’écriture) de plusieurs régions d’écriture ne s’appliquent pas, en raison de la réplication synchrone entre les régions.
Les sémantiques des cinq modèles de cohérence dans Azure Cosmos DB sont exposées ici et décrites mathématiquement ici à l’aide d’une spécification TLA+ de haut niveau.
Étapes suivantes
Découvrez ensuite comment configurer la distribution mondiale à l’aide les articles suivants :
- Ajouter/supprimer des régions à partir de votre compte de base de données
- Guide pratique pour créer une stratégie personnalisée de résolution des conflits
- Vous tentez d’effectuer une planification de la capacité pour une migration vers Azure Cosmos DB ? Vous pouvez utiliser les informations sur votre cluster de bases de données existant pour la planification de la capacité.
- Si vous ne connaissez que le nombre de vCores et de serveurs présents dans votre cluster de bases de données existant, lisez Estimation des unités de requête à l’aide de vCores ou de processeurs virtuels
- Si vous connaissez les taux de requêtes typiques de votre charge de travail de base de données actuelle, lisez la section concernant l’estimation des unités de requête à l’aide du planificateur de capacité Azure Cosmos DB