Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Azure Cosmos DB peut stocker plusieurs téraoctets de données. Vous pouvez procéder à une migration de données à grande échelle pour transférer votre charge de travail de production vers Azure Cosmos DB. Cet article décrit les défis liés au transfert de données à grande échelle vers Azure Cosmos DB et vous présente l'outil qui permet de relever ces défis pour migrer les données vers Azure Cosmos DB. Dans cette étude de cas, le client a utilisé l'API Azure Cosmos DB pour NoSQL.
Avant de migrer l'intégralité de la charge de travail vers Azure Cosmos DB, vous pouvez migrer un sous-ensemble de données pour valider certains aspects tels que le choix de la clé de partition, les performances des requêtes et la modélisation des données. Une fois la preuve de concept validée, vous pouvez transférer l'intégralité de la charge de travail vers Azure Cosmos DB.
Outils de migration de données
Les stratégies de migration Azure Cosmos DB varient en fonction du choix de l'API et de la taille des données. Pour migrer des jeux de données plus petits – pour valider la modélisation des données, les performances des requêtes, le choix de clé de partition, etc. – vous pouvez utiliser le connecteur Azure Cosmos DB d’Azure Data Factory. Si vous avez l'habitude de Spark, vous pouvez également choisir d'utiliser le connecteur Spark Azure Cosmos DB pour migrer les données.
Défis liés aux migrations à grande échelle
Les outils existants pour procéder à la migration des données vers Azure Cosmos DB présentent certaines limites qui deviennent particulièrement évidentes à grande échelle :
Fonctionnalités de scale-out limitées : pour migrer des téraoctets de données vers Azure Cosmos DB le plus rapidement possible, et utiliser efficacement l'intégralité du débit alloué, les clients de migration doivent avoir la possibilité d’effectuer un scale-out indéfiniment.
Absence de suivi de l'avancement et de pointage de contrôle : lors de la migration de jeux de données volumineux, il est important de suivre l'avancement de la migration et d'avoir recours au pointage de contrôle. Sinon, toute erreur qui se produit pendant la migration arrête la migration, et vous devez démarrer le processus à partir de zéro. Il serait improductif de relancer l'intégralité du processus de migration alors que 99 % de celui-ci a déjà été effectué.
Absence de file d’attente de lettres mortes : dans les grands jeux de données, certaines parties des données sources posent parfois des problèmes. En outre, des problèmes temporaires de client ou de réseau peuvent être rencontrés. L’un de ces cas ne doit pas entraîner l’échec de la migration entière. Même si la plupart des outils de migration ont des fonctionnalités de nouvelle tentative robustes qui protègent contre les problèmes intermittents, il n’est pas toujours suffisant. Par exemple, si moins de 0,01% des documents de données sources sont supérieurs à 2 Mo de taille, l’écriture du document échoue dans Azure Cosmos DB. Dans l’idéal, il est utile que l’outil de migration conserve ces documents « échoués » dans une autre file d’attente de lettres mortes, qui peut être traitée après la migration.
La plupart de ces limites sont en cours de correction pour les outils tels qu'Azure Data Factory et les services Azure Data Migration.
Outil personnalisé avec bibliothèque de fonctionnalités pour exécution en masse
Les défis décrits dans la section précédente peuvent être résolus à l’aide d’un outil personnalisé qui peut être facilement mis à l’échelle sur plusieurs instances et résilient aux défaillances temporaires. En outre, l'outil personnalisé peut suspendre et reprendre la migration à différents points de contrôle. Azure Cosmos DB fournit déjà la bibliothèque d'Exécuteurs en bloc qui intègre certaines de ces fonctionnalités. Par exemple, la bibliothèque d'Exécuteurs en bloc dispose déjà de la fonctionnalité permettant de gérer les erreurs temporaires et peut effectuer un scale-out des threads d'un nœud individuel pour utiliser environ 500 K de RU par nœud. La bibliothèque d'exécuteurs en bloc partitionne également le jeu de données source en micro-lots qui sont exploités indépendamment sous la forme de pointage de contrôle.
L'outil personnalisé utilise la bibliothèque "Bulk Executor" et, par ailleurs, il prend en charge la montée en charge sur plusieurs clients tout en permettant le suivi des erreurs pendant le processus d'ingestion. Pour utiliser cet outil, les données sources doivent être partitionnées en fichiers distincts dans Azure Data Lake Storage (ADLS) afin que différents agents de migration puissent récupérer chaque fichier et les ingérer dans Azure Cosmos DB. L'outil personnalisé utilise une collection distincte, qui stocke les métadonnées relatives à l'avancement de la migration de chaque fichier source dans ADLS et assure le suivi des erreurs associées.
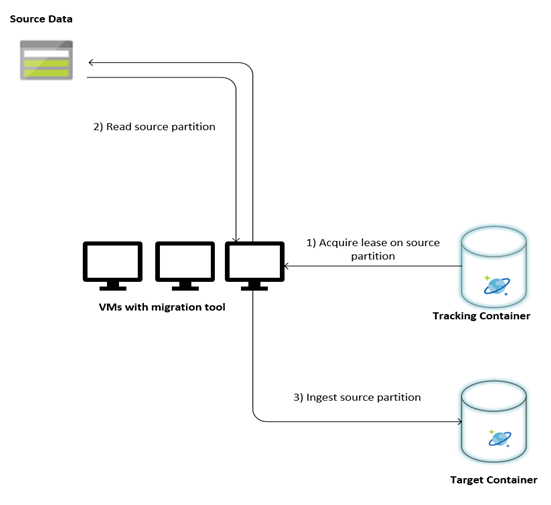
L'illustration suivante décrit le processus de migration à l'aide de cet outil personnalisé. L'outil s'exécute sur un ensemble de machines virtuelles, et chaque machine virtuelle interroge la collection de suivi d'Azure Cosmos DB pour acquérir un bail sur l'une des partitions de données source. Au terme de cette opération, la partition de données source est lue par l'outil et ingérée dans Azure Cosmos DB à l'aide de la bibliothèque d'Exécuteurs en bloc. La collection de suivi est ensuite mise à jour pour enregistrer l'avancement de l'ingestion des données et les éventuelles erreurs rencontrées. Après le traitement d'une partition de données, l'outil tente de rechercher la partition source disponible suivante. Il poursuit le traitement de la partition source suivante jusqu'à ce que toutes les données soient migrées. Le code source de l’outil est disponible dans le dépôt Azure Cosmos DB pour l'ingestion en bloc.
La collection de suivi contient des documents, comme illustré dans l’exemple suivant. Vous verrez un de ces documents pour chaque partition dans les données sources. Chaque document contient les métadonnées de la partition de données source, comme son emplacement, son état de migration et les erreurs (le cas échéant) :
{
"owner": "25812@bulkimporttest07",
"jsonStoreEntityImportResponse": {
"numberOfDocumentsReceived": 446688,
"isError": false,
"totalRequestUnitsConsumed": 3950252.2800000003,
"errorInfo": [],
"totalTimeTakenInSeconds": 188,
"numberOfDocumentsImported": 446688
},
"storeType": "AZURE_BLOB",
"name": "sourceDataPartition",
"location": "sourceDataPartitionLocation",
"id": "sourceDataPartitionId",
"isInProgress": false,
"operation": "unpartitioned-writes",
"createDate": {
"seconds": 1561667225,
"nanos": 146000000
},
"completeDate": {
"seconds": 1561667515,
"nanos": 180000000
},
"isComplete": true
}
Conditions préalables à la migration des données
Avant d'entamer la migration des données, quelques conditions préalables doivent être prises en compte :
Estimez la taille des données :
La taille des données sources peut être légèrement différente de celle des données contenues dans Azure Cosmos DB. Quelques échantillons de documents de la source peuvent être insérés pour vérifier la taille de leurs données dans Azure Cosmos DB. En fonction de la taille des documents d'échantillon, il est possible d'estimer la taille totale des données dans Azure Cosmos DB après migration.
Par exemple, si la taille de chaque document est d'environ 1 Ko après la migration vers Azure Cosmos DB et que le jeu de données source contient environ 60 milliards de documents, la taille estimée des données contenues dans Azure Cosmos DB avoisine les 60 To.
Pré-créez des conteneurs avec un nombre suffisant de RUs :
Bien qu’Azure Cosmos DB effectue un scale-out automatiquement du stockage, il n’est pas recommandé de commencer à partir de la plus petite taille de conteneur. Les petits conteneurs ont un débit plus faible, ce qui ralentira la migration. Au lieu de cela, il est utile de créer les conteneurs avec la taille finale des données (comme estimé à l’étape précédente) et de s’assurer que la charge de travail de migration consomme entièrement le débit provisionné.
À l’étape précédente, étant donné que la taille des données était estimée à environ 60 To, un conteneur d’au moins 2,4 millions de RUs est nécessaire pour héberger l’ensemble du jeu de données.
Estimez la vitesse de migration :
En supposant que la charge de travail de migration puisse consommer la totalité du débit approvisionné, le débit approvisionné fournit une estimation de la vitesse de migration. Pour poursuivre l’exemple précédent, cinq unités de requête sont requises pour écrire un document de 1 Ko via l'API d'un compte Azure Cosmos DB pour NoSQL. 2,4 millions de RU permettraient un transfert de 480 000 documents par seconde (ou 480 Mo/s). Cela signifie que la migration complète de 60 To prend 125 000 secondes ou environ 34 heures.
Si vous souhaitez que la migration soit achevée dans la journée, vous devez augmenter le débit alloué en passant à 5 millions de RU.
Désactivez l'indexation :
Étant donné que la migration doit être effectuée dès que possible, il est conseillé de réduire le temps et les RUs (unités de requête) consacrés à la création d’index pour chacun des documents ingérés. Azure Cosmos DB indexe automatiquement toutes les propriétés, il est utile de réduire l’indexation en quelques termes sélectionnés ou de la désactiver complètement pour le cours de la migration. Vous pouvez désactiver la stratégie d’indexation du conteneur en modifiant l’indexingMode à none comme indiqué ici :
{
"indexingMode": "none"
}
Au terme de la migration, vous pourrez procéder à une mise à jour de l'indexation.
Processus de migration
Une fois les conditions préalables remplies, vous pouvez migrer les données en procédant comme suit :
Commencez par importer les données de la source vers le Stockage Blob Azure. Pour augmenter la vitesse de migration, il est utile de paralléliser les partitions sources distinctes. Avant d'entamer la migration, le jeu de données source doit être partitionné en fichiers d'environ 200 Mo.
La bibliothèque d'exécuteurs en bloc peut monter en puissance pour utiliser 500 000 RU sur une même machine virtuelle cliente. Puisque le débit disponible est de 5 millions de RU, 10 machines virtuelles Ubuntu 16.04 (Standard_D32_v3) doivent être approvisionnées dans la région de votre base de données Azure Cosmos DB. Vous devez préparer ces machines virtuelles avec l'outil de migration et son fichier de paramètres.
Exécutez l'étape relative à la file d'attente sur l'une des machines virtuelles clientes. Cette étape crée la collection de suivi, qui analyse le conteneur ADLS et crée un document de suivi de progression pour chacun des fichiers de partition du jeu de données source.
Exécutez ensuite l'étape d'importation sur toutes les machines virtuelles clientes. Chacun des clients peut s'approprier une partition source et ingérer ses données dans Azure Cosmos DB. Une fois qu’il est terminé et que son état est mis à jour dans la collection de suivi, les clients peuvent ensuite interroger la prochaine partition source disponible dans la collection de suivi.
Ce processus se poursuit jusqu'à ce que toutes les partitions sources aient été ingérées. Une fois que toutes les partitions sources ont été traitées, l'outil doit être réexécuté en mode correction d'erreurs sur la même collection de suivi. Cette étape est nécessaire pour identifier les partitions sources qui doivent être traitées à nouveau en raison d’erreurs.
Certaines de ces erreurs peuvent être dues à des documents incorrects dans les données sources. Vous devez les identifier et les corriger. Ensuite, vous devez réexécuter l'étape d'importation sur les partitions défaillantes pour les réingérer.
Au terme de la migration, vous pouvez vérifier que le nombre de documents contenus dans Azure Cosmos DB et dans la base de données source est le même. Dans cet exemple, la taille totale des données contenues dans Azure Cosmos DB était de 65 téraoctets. Après la migration, l'indexation peut être activée de manière sélective, et les RUs peuvent être réduites au niveau requis par les opérations du workload.
Étapes suivantes
- Pour en savoir plus, essayez les exemples d'applications utilisant la bibliothèque d'Exécuteurs en bloc en .NET et Java.
- La bibliothèque d'Exécuteurs en bloc est intégrée au connecteur Spark Azure Cosmos DB. Pour plus d'informations, consultez Connecteur Spark Azure Cosmos DB.
- Contactez l’équipe de produit Azure Cosmos DB en ouvrant un ticket de support sous le type de problème « Avis général » et le sous-type de problème « Migrations volumineuses (To+) » pour obtenir de l’aide supplémentaire sur les migrations à grande échelle.
- Vous tentez d’effectuer une planification de la capacité pour une migration vers Azure Cosmos DB ? Vous pouvez utiliser les informations sur votre cluster de bases de données existant pour la planification de la capacité.
- Si vous ne connaissez que le nombre de vCore et de serveurs présents dans votre cluster de bases de données existant, lisez Estimation des unités de requête à l’aide de vCore ou de processeurs virtuels.
- Si vous connaissez les taux de requêtes typiques de votre charge de travail de base de données actuelle, lisez la section concernant l’estimation des unités de requête à l’aide du planificateur de capacité Azure Cosmos DB