Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’APPLIQUE À : ![]() NoSQL
NoSQL
Cet article s’appuie sur plusieurs concepts Azure Cosmos DB tels que la modélisation des données, le partitionnement et le débit provisionné pour illustrer comment aborder un exercice concret de conception de données.
Si vous travaillez habituellement avec des bases de données relationnelles, vous avez probablement développé des habitudes et des intuitions sur la façon de concevoir un modèle de données. En raison des contraintes spécifiques, mais également des atouts uniques d’Azure Cosmos DB, la plupart de ces bonnes pratiques ne se traduisent pas correctement et peuvent vous faire dériver vers des solutions non optimales. L’objectif de cet article est de vous guider tout au long du processus de modélisation d’un cas d’utilisation concret sur Azure Cosmos DB, de la modélisation des éléments à la colocalisation d’entités et au partitionnement de conteneur.
Téléchargez ou affichez un code source généré par la communauté qui illustre les concepts de cet article.
Important
Un contributeur de la communauté a participé à cet exemple de code et l’équipe Azure Cosmos DB ne prend pas en charge sa maintenance.
Le scénario
Pour cet exercice, nous allons prendre en compte le domaine d’une plateforme de création de blogs dans laquelle des utilisateurs peuvent créer des publications. Les utilisateurs peuvent également ajouter des mentions j’aime et des commentaires à ces publications.
Conseil
Nous avons mis en italique certains mots pour identifier les types de « choses » que notre modèle devra manipuler.
Ajout d’exigences supplémentaires à notre spécification :
- Une première page affiche un flux de publications récemment créées,
- Nous pouvons extraire toutes les publications d’un utilisateur, tous les commentaires d’une publication et toutes les mentions j’aime d’une publication,
- Les publications sont retournées avec le nom d’utilisateur de leur auteur et un décompte des commentaires et des mentions j’aime associés,
- Les commentaires et mentions j’aime sont également retournés avec le nom d’utilisateur des utilisateurs qui les ont créés,
- Lorsqu’elles sont affichées sous forme de listes, les publications doivent uniquement présenter un résumé tronqué de leur contenu.
Identifier les modèles d’accès principaux
Pour commencer, nous donnons une structure à notre spécification initiale en identifiant les modèles d’accès de notre solution. Lors de la conception d’un modèle de données pour Azure Cosmos DB, il est important de comprendre quelles demandes notre modèle doit traiter pour veiller à ce que le modèle traite efficacement ces requêtes.
Pour simplifier le suivi du processus global, nous catégorisons ces différentes requêtes en tant que commandes ou requêtes, en empruntant le vocabulaire de CQRS. Dans le CQRS, les commandes sont des demandes d'écriture (c'est-à-dire des intentions de mettre à jour le système) et les requêtes sont des demandes de lecture seule.
Voici la liste des requêtes exposées par notre plateforme :
- [C1] Créer/modifier un utilisateur
- [Q1] Récupérer un utilisateur
- [C2] Créer/modifier une publication
- [Q2] Récupérer une publication
- [Q3] Lister les publications d’un utilisateur sous forme abrégée
- [C3] Créer un commentaire
- [Q4] Lister les commentaires d’une publication
- [C4] Ajouter une mention « j’aime » à une publication
- [Q5] Lister les mentions « j’aime » d’une publication
- [Q6] Lister les x publications les plus récentes créées sous forme abrégée (flux)
À ce stade, nous n’avons pas pensé aux détails contenus par chaque entité (utilisateur, publication, etc.). Cette étape est généralement l’une des premières à être traitée lors de la conception d’un magasin relationnel. Nous commençons en premier par cette étape parce que nous devons déterminer comment ces entités se traduisent en termes de tables, de colonnes, de clés étrangères, etc. Cette opération est moins préoccupante avec une base de données de documents qui n’applique aucun schéma en écriture.
La principale raison pour laquelle il est important d’identifier nos modèles d’accès dès le début tient au fait que cette liste de requêtes sera notre suite de tests. Chaque fois que nous effectueront une itération sur notre modèle de données, nous examinerons chaque requête et vérifierons ses performances et son extensibilité. Nous calculons les unités de requête (RU) consommées dans chaque modèle et les optimisons. Tous ces modèles utilisent la stratégie d’indexation par défaut, et vous pouvez les remplacer en indexant des propriétés spécifiques, ce qui peut améliorer la consommation et la latence des RU.
V1 : Première version
Nous commençons avec deux conteneurs : users et posts.
Conteneur d’utilisateurs
Ce conteneur stocke uniquement des éléments utilisateur :
{
"id": "<user-id>",
"username": "<username>"
}
Nous partitionnons ce conteneur par id, ce qui signifie que chaque partition logique figurant dans ce conteneur contient un seul élément.
Conteneur de publications
Ce conteneur héberge des entités telles que des publications, commentaires et mentions « J’aime » :
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"title": "<post-title>",
"content": "<post-content>",
"creationDate": "<post-creation-date>"
}
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"creationDate": "<like-creation-date>"
}
Nous partitionnons ce conteneur par postId, ce qui signifie que chaque partition logique dans ce conteneur contient une seule publication, ainsi que tous les commentaires et toutes les mentions « J’aime » relatifs à cette publication.
Notez que nous avons introduit une propriété type dans les éléments stockés de ce conteneur pour faire la distinction entre les trois types d’entités hébergées par ce conteneur.
En outre, nous avons choisi de référencer les données associées au lieu de les incorporer (consultez cette section pour plus d’informations sur ces concepts), car :
- aucune limite supérieure ne s’applique au nombre de publications qu’un utilisateur peut créer,
- les publications peuvent être d’une longueur arbitraire,
- aucune limite supérieure ne s’applique au nombre de commentaires et de mentions « j’aime » qu’une publication peut avoir,
- nous voulons être en mesure d’ajouter un commentaire ou une mention « j’aime » à une publication sans avoir à mettre à jour la publication proprement dite.
Comment fonctionne notre modèle ?
Il est maintenant temps d’évaluer les performances et l’extensibilité de notre première version. Pour chacune des demandes identifiées précédemment, nous mesurons la latence et le nombre d’unités de requête que le modèle consomme. Cette mesure est effectuée sur un jeu de données factice contenant 100 000 utilisateurs avec entre 5 et 50 publications par utilisateur et jusqu'à 25 commentaires et 100 mentions « j’aime » par publication.
[C1] Créer/modifier un utilisateur
Cette demande est simple à implémenter car il suffit de créer ou de mettre à jour un élément dans le conteneur users. Les requêtes sont correctement réparties sur toutes les partitions grâce à la clé de partition id.
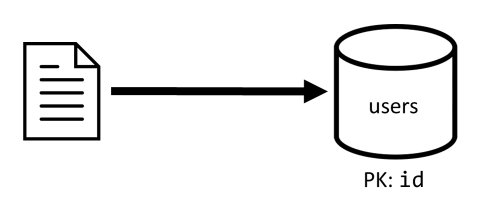
| Latence | Frais en RU (unités de requête) | Performances |
|---|---|---|
7 ms |
5.71 RU |
✅ |
[Q1] Récupérer un utilisateur
La récupération d’un utilisateur s’effectue en lisant l’élément correspondant à partir du conteneur users.
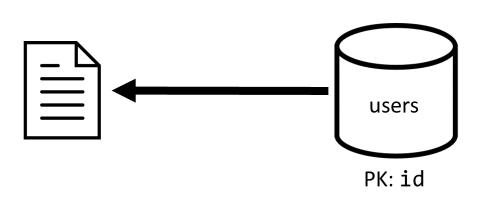
| Latence | Frais en RU (unités de requête) | Performances |
|---|---|---|
2 ms |
1 RU |
✅ |
[C2] Créer/modifier une publication
Similaire à [C1] , il suffit d’écrire dans le conteneur posts.
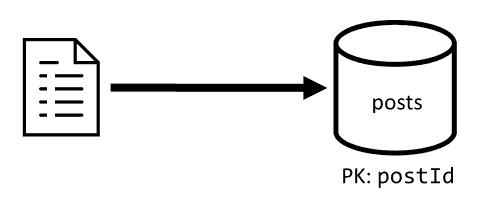
| Latence | Frais en RU (unités de requête) | Performances |
|---|---|---|
9 ms |
8.76 RU |
✅ |
[Q2] Récupérer une publication
Nous commençons par extraire le document correspondant à partir du conteneur posts. Mais ce n’est pas tout. Conformément à notre spécification, nous devons également agréger le nom d’utilisateur de l’auteur de la publication, le nombre de commentaires et le nombre de mentions « J’aime » pour la publication. Les agrégations répertoriées nécessitent l’établissement de 3 requêtes SQL supplémentaires.
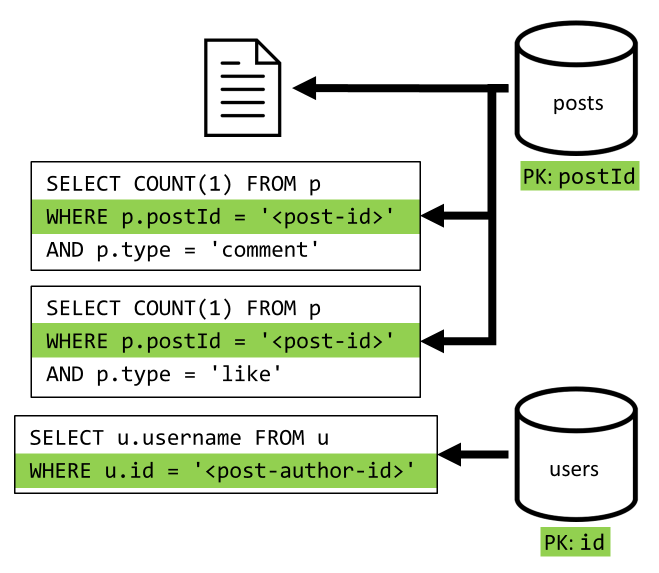
Chaque requête supplémentaire effectue un filtrage sur la clé de partition de son conteneur respectif, ce qui est exactement ce que nous voulons pour optimiser les performances et l’extensibilité. Mais nous devons finalement effectuer quatre opérations pour retourner une publication unique, donc nous améliorerons cela dans une prochaine itération.
| Latence | Frais en RU (unités de requête) | Performances |
|---|---|---|
9 ms |
19.54 RU |
⚠ |
[Q3] Lister les publications d’un utilisateur sous forme abrégée
Tout d’abord, nous devons récupérer les publications souhaitées à l’aide d’une requête SQL qui extrait les publications correspondant à cet utilisateur particulier. Mais nous devons également établir d’autres requêtes pour agréger le nom d’utilisateur de l’auteur et les nombres de commentaires et de mentions « J’aime ».
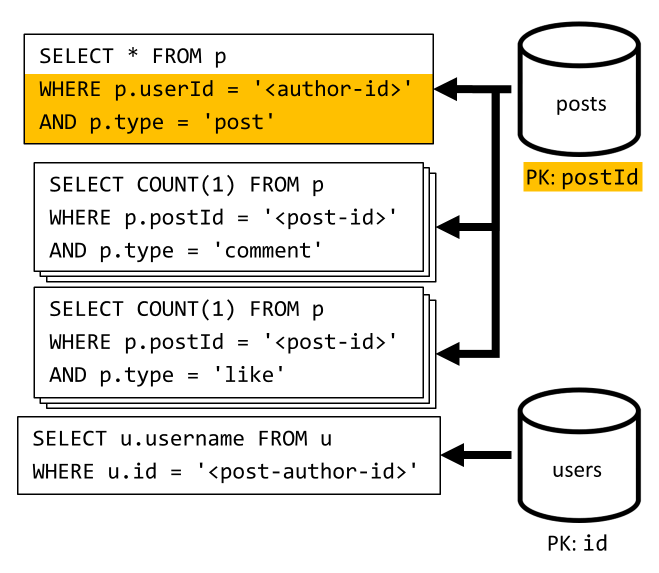
Cette implémentation présente de nombreux inconvénients :
- les requêtes d’agrégation des nombres de commentaires et de mentions « j’aime » doivent être émises pour chaque publication retournée par la première requête,
- la requête principale n’effectue pas de filtrage sur la clé de partition du conteneur
posts, ce qui conduit à une distribution ramifiée et à une analyse de partition sur le conteneur.
| Latence | Frais en RU (unités de requête) | Performances |
|---|---|---|
130 ms |
619.41 RU |
⚠ |
[C3] Créer un commentaire
Un commentaire est créé en écrivant l’élément correspondant dans le conteneur posts.
| Latence | Frais en RU (unités de requête) | Performances |
|---|---|---|
7 ms |
8.57 RU |
✅ |
[Q4] Lister les commentaires d’une publication
Nous commençons avec une requête qui extrait tous les commentaires pour cette publication et une fois encore, nous devons également agréger les noms d’utilisateur séparément pour chaque commentaire.
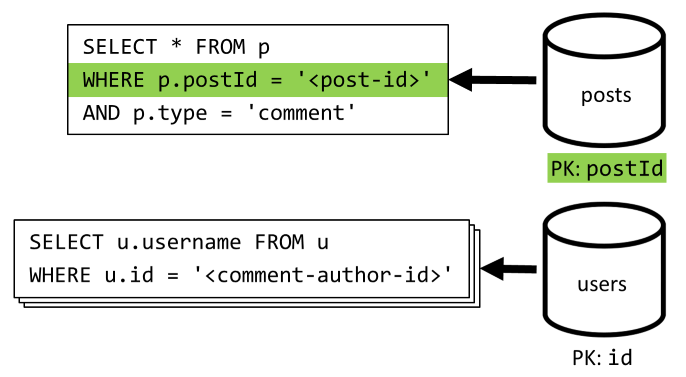
La requête principale filtre les données sur la clé de partition du conteneur, mais l’agrégation séparée des noms d’utilisateur pénalise les performances globales. Nous améliorerons ceci par la suite.
| Latence | Frais en RU (unités de requête) | Performances |
|---|---|---|
23 ms |
27.72 RU |
⚠ |
[C4] Ajouter une mention « j’aime » à une publication
Tout comme pour [C3] , nous créons l’élément correspondant dans le conteneur posts.
| Latence | Frais en RU (unités de requête) | Performances |
|---|---|---|
6 ms |
7.05 RU |
✅ |
[Q5] Lister les mentions « j’aime » d’une publication
Tout comme pour [Q4] , nous interrogeons les mentions « j’aime » de la publication, puis agrégeons leurs noms d’utilisateur.
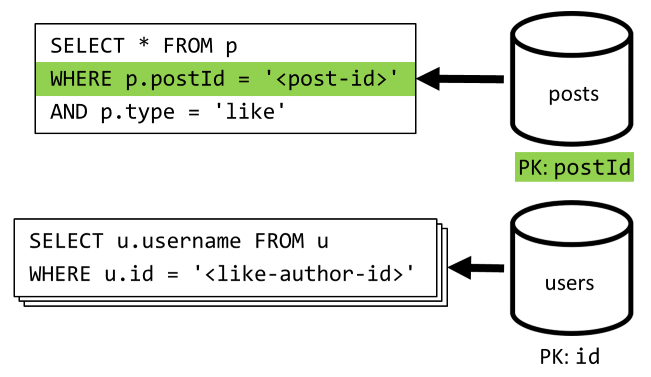
| Latence | Frais en RU (unités de requête) | Performances |
|---|---|---|
59 ms |
58.92 RU |
⚠ |
[Q6] Lister les x publications les plus récentes créées sous forme abrégée (flux)
Nous extrayons les publications les plus récentes en interrogeant le conteneur posts trié dans l’ordre décroissant de la date de création, puis agrégeons les noms d’utilisateur et les nombres de commentaires et de mentions « j’aime » pour chaque publication.
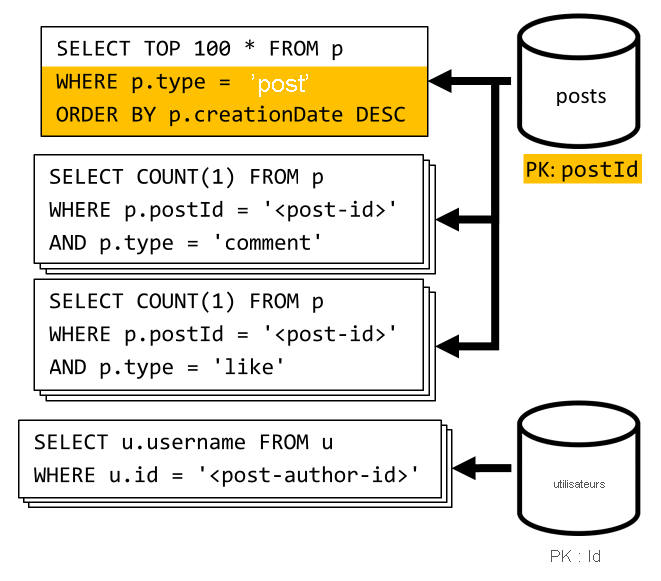
Une fois encore, notre requête initiale n’effectue pas de filtrage sur la clé de partition du conteneur posts, ce qui déclenche une distribution ramifiée coûteuse. La situation est encore pire ici, car nous ciblons un jeu de résultats plus grand et trions les résultats avec une clause ORDER BY, ce qui rend le processus plus onéreux en termes d’unités de requête.
| Latence | Frais en RU (unités de requête) | Performances |
|---|---|---|
306 ms |
2063.54 RU |
⚠ |
Réflexion sur les performances de V1
L’examen des problèmes de performances auxquels nous avons été confrontés dans la section précédente permet d’identifier deux classes principales de problèmes :
- certaines demandes nécessitent l’exécution de plusieurs requêtes afin de collecter toutes les données à retourner,
- certaines requêtes ne filtrent pas les données sur la clé de partition des conteneurs qu’elles ciblent, ce qui conduit à une distribution ramifiée qui nuit à l’extensibilité.
Nous allons résoudre chacun de ces problèmes, en commençant par le premier.
V2 : Introduction d’une dénormalisation pour optimiser les requêtes de lecture
La raison pour laquelle nous devons établir d’autres requêtes dans certains cas tient au fait que les résultats de la requête initiale ne contiennent pas toutes les données que nous devons retourner. La dénormalisation des données résout ce genre de problème dans notre jeu données lors de l’utilisation d’un magasin de données non relationnel tel qu’Azure Cosmos DB.
Dans notre exemple, nous allons modifier les éléments de publication pour ajouter le nom d’utilisateur de l’auteur de la publication, le nombre de commentaires et le nombre de mentions « j’aime » :
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Nous allons également modifier chaque élément de commentaire et de mention « j’aime » pour ajouter le nom d’utilisateur de l’utilisateur qui l’a créé :
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
Dénormalisation des nombres de commentaires et de mentions « j’aime »
Notre objectif est que, chaque fois que nous ajoutons un commentaire ou une mention « j’aime », nous incrémentions également commentCount ou likeCount dans la publication correspondante. Comme postId partitionne notre conteneur posts, le nouvel élément (commentaire ou mention « J’aime ») et la publication correspondante figurent dans la même partition logique. Par conséquent, nous pouvons utiliser une procédure stockée pour effectuer cette opération.
Lorsque vous créez un commentaire ([C3]), au lieu d’ajouter simplement un nouvel élément dans le conteneur posts, nous appelons la procédure stockée suivante sur ce conteneur :
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
Cette procédure stockée accepte l’ID de la publication et le corps du nouveau commentaire en tant que paramètres, puis :
- récupère la publication
- incrémente
commentCount - remplace la publication
- ajoute le nouveau commentaire
Comme les procédures stockées sont exécutées en tant que transactions atomiques, la valeur de commentCount et le nombre réel de commentaires restent toujours synchronisés.
Bien entendu, nous appelons une procédure stockée similaire lors de l’ajout de nouvelles mentions « j’aime » pour incrémenter likeCount.
Dénormalisation des noms d’utilisateur
Les noms d’utilisateur requièrent une approche différente, car les utilisateurs figurent non seulement dans des partitions différentes, mais aussi dans un autre conteneur. Lorsque nous devons dénormaliser des données dans des partitions et des conteneurs, nous pouvons utiliser le flux de modification du conteneur source.
Dans notre exemple, nous utilisons le flux de modification du conteneur users pour réagir chaque fois que les utilisateurs mettent à jour leurs noms d’utilisateur. Lorsque cela se produit, nous propageons la modification en appelant une autre procédure stockée sur le conteneur posts :
function updateUsernames(userId, username) {
var collection = getContext().getCollection();
collection.queryDocuments(
collection.getSelfLink(),
`SELECT * FROM p WHERE p.userId = '${userId}'`,
function (err, results) {
if (err) throw err;
for (var i in results) {
var doc = results[i];
doc.userUsername = username;
collection.upsertDocument(
collection.getSelfLink(),
doc);
}
});
}
Cette procédure stockée accepte l’ID et le nouveau nom d’utilisateur de l’utilisateur en tant que paramètres, puis :
- extrait tous les éléments correspondant à
userId(éventuellement des publications, des commentaires ou des mentions « j’aime ») - pour chacun de ces éléments
- remplace
userUsername - remplace l’élément
- remplace
Important
Cette opération est coûteuse, car elle requiert l’exécution de cette procédure stockée sur chaque partition du conteneur posts. Nous supposons que la plupart des utilisateurs choisissent un nom d’utilisateur approprié lors de leur inscription et qu’ils n’en changeront jamais, de sorte que cette mise à jour s’exécutera très rarement.
Quels sont les gains de performances de V2 ?
Parlons de quelques-uns des gains den performances de V2.
[Q2] Récupérer une publication
Maintenant que notre dénormalisation est en place, il nous suffit d’extraire un seul élément pour traiter cette demande.
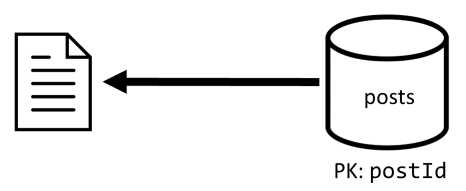
| Latence | Frais en RU (unités de requête) | Performances |
|---|---|---|
2 ms |
1 RU |
✅ |
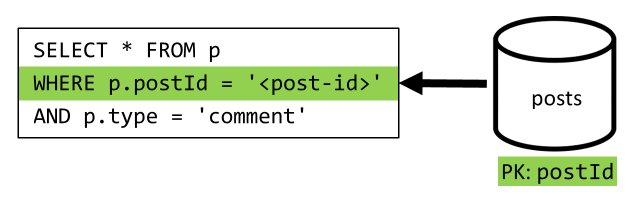
[Q4] Lister les commentaires d’une publication
Ici encore, nous pouvons faire l’économie des demandes supplémentaires qui extrayaient les noms d’utilisateur et obtenir au final une seule requête qui filtre les données sur la clé de partition.
| Latence | Frais en RU (unités de requête) | Performances |
|---|---|---|
4 ms |
7.72 RU |
✅ |
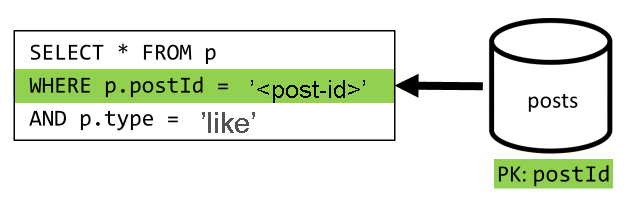
[Q5] Lister les mentions « j’aime » d’une publication
La situation est exactement la même lors de l’énumération des mentions « j’aime ».
| Latence | Frais en RU (unités de requête) | Performances |
|---|---|---|
4 ms |
8.92 RU |
✅ |
V3 : S’assurer que toutes les demandes sont évolutives
Il reste encore deux requêtes que nous n’avons pas complètement optimisées lors de l’affichage de l’amélioration globale de nos performances. Ces requêtes sont [Q3] et [Q6]. Ce sont les demandes impliquant des requêtes qui ne filtrent pas sur la clé de partition des conteneurs ciblés.
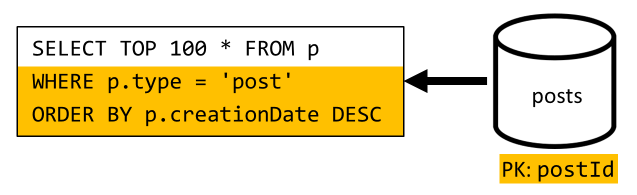
[Q3] Lister les publications d’un utilisateur sous forme abrégée
Cette demande bénéficie déjà des améliorations introduites dans V2, ce qui permet d’épargner d’autres requêtes.

Mais la requête restante ne filtre toujours pas les données sur la clé de partition du conteneur posts.
La façon d’interpréter cette situation est simple :
- Cette demande doit effectuer un filtrage sur
userId, car nous voulons extraire toutes les publications d’un utilisateur particulier. - Elle n’est pas efficace parce qu’elle est exécutée sur le conteneur
posts, queuserIdne partitionne pas. - De toute évidence, nous pouvons résoudre notre problème de performances en exécutant cette requête sur un conteneur qui partitionné avec
userId. - Il s’avère que nous possédons déjà un conteneur de ce type : le conteneur
users.
Nous allons donc introduire un deuxième niveau de dénormalisation en dupliquant toutes les publications dans le conteneur users. En procédant ainsi, nous obtenons effectivement une copie de nos publications, désormais partitionnées selon une dimension différente qui améliore considérablement l’efficacité de leur récupération par leur userId.
Le conteneur users contient maintenant deux types d’éléments :
{
"id": "<user-id>",
"type": "user",
"userId": "<user-id>",
"username": "<username>"
}
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Dans cet exemple :
- Nous avons introduit un champ
typedans l’élément de l’utilisateur afin de distinguer les utilisateurs et les publications, - Nous avons également ajouté un champ
userIddans l’élément de l’utilisateur, qui est redondant avec le champidmais qui est requis, car le conteneurusersest maintenant partitionné avecuserId(et non plus avecid)
Pour réaliser cette dénormalisation, nous utilisons une fois encore le flux de modification. Cette fois-ci, nous réagissons sur le flux de modification du conteneur posts pour distribuer toute publication nouvelle ou mise à jour vers le conteneur users. Et comme la fourniture d’une liste des publications ne nécessite pas de retourner leur contenu complet, nous pouvons les tronquer dans ce processus.
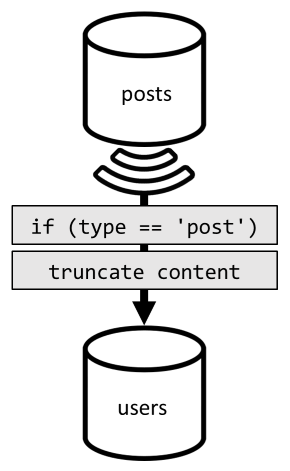
Maintenant, nous pouvons router notre requête vers le conteneur users et filtrer les données sur la clé de partition du conteneur.

| Latence | Frais en RU (unités de requête) | Performances |
|---|---|---|
4 ms |
6.46 RU |
✅ |
[Q6] Lister les x publications les plus récentes créées sous forme abrégée (flux)
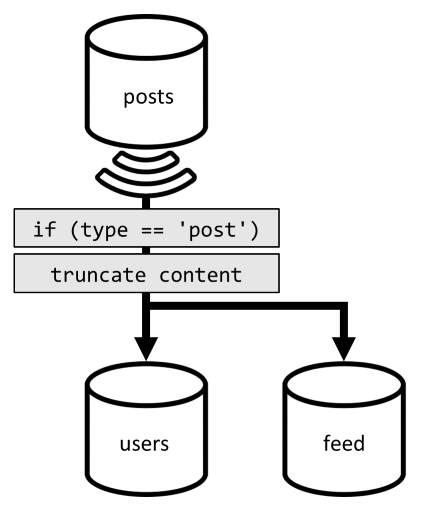
Nous devons faire face à une situation similaire ici : même après avoir fait l’économie d’autres requêtes rendues inutiles par la dénormalisation introduite dans V2, la requête restante ne filtre pas sur la clé de partition du conteneur :
En suivant la même approche, l’optimisation des performances et de l’extensibilité de cette demande exige que cette dernière s’applique à une seule partition. Il est concevable d’atteindre une seule partition, car nous n’avons qu’à retourner un nombre limité d’éléments. Pour remplir la page d’accueil de notre plateforme de création de blogs, il nous suffit d’obtenir les 100 publications les plus récentes, sans avoir à paginer le jeu de données complet.
Ainsi, pour optimiser cette dernière demande, nous allons introduire un troisième conteneur dans notre conception, entièrement dédié au traitement de cette demande. Nous allons dénormaliser nos publications dans ce nouveau conteneur feed :
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Le champ type partitionne ce conteneur, qui est toujours post dans nos éléments. Cela garantit que tous les éléments figurant dans ce conteneur seront placés dans la même partition.
Pour réaliser cette dénormalisation, il nous suffit de raccorder le pipeline de flux de modification que nous avons précédemment introduit pour distribuer les publications vers ce nouveau conteneur. Il est important de garder à l’esprit qu’il faut s’assurer de ne stocker que les 100 publications les plus récentes. Sinon, le contenu du conteneur peut croître au-delà de la taille maximale d’une partition. Cette limitation peut être implémentée en appelant un post-déclencheur chaque fois qu’un document est ajouté dans le conteneur :
Voici le corps du post-déclencheur qui tronque la collection :
function truncateFeed() {
const maxDocs = 100;
var context = getContext();
var collection = context.getCollection();
collection.queryDocuments(
collection.getSelfLink(),
"SELECT VALUE COUNT(1) FROM f",
function (err, results) {
if (err) throw err;
processCountResults(results);
});
function processCountResults(results) {
// + 1 because the query didn't count the newly inserted doc
if ((results[0] + 1) > maxDocs) {
var docsToRemove = results[0] + 1 - maxDocs;
collection.queryDocuments(
collection.getSelfLink(),
`SELECT TOP ${docsToRemove} * FROM f ORDER BY f.creationDate`,
function (err, results) {
if (err) throw err;
processDocsToRemove(results, 0);
});
}
}
function processDocsToRemove(results, index) {
var doc = results[index];
if (doc) {
collection.deleteDocument(
doc._self,
function (err) {
if (err) throw err;
processDocsToRemove(results, index + 1);
});
}
}
}
L’étape finale consiste à rediriger la requête vers le nouveau conteneur feed :
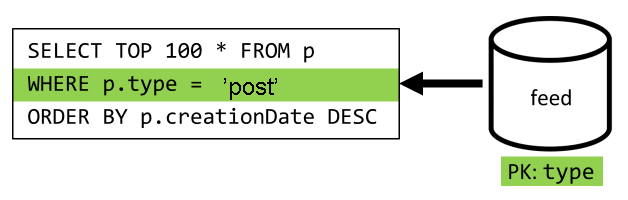
| Latence | Frais en RU (unités de requête) | Performances |
|---|---|---|
9 ms |
16.97 RU |
✅ |
Conclusion
Penchons-nous sur les améliorations globales des performances et de la scalabilité que nous avons introduites au fil des versions de notre conception.
| V1 | V2 | V3 | |
|---|---|---|---|
| [C1] | 7 ms / 5.71 RU |
7 ms / 5.71 RU |
7 ms / 5.71 RU |
| [Q1] | 2 ms / 1 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [C2] | 9 ms / 8.76 RU |
9 ms / 8.76 RU |
9 ms / 8.76 RU |
| [Q2] | 9 ms / 19.54 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [Q3] | 130 ms / 619.41 RU |
28 ms / 201.54 RU |
4 ms / 6.46 RU |
| [C3] | 7 ms / 8.57 RU |
7 ms / 15.27 RU |
7 ms / 15.27 RU |
| [Q4] | 23 ms / 27.72 RU |
4 ms / 7.72 RU |
4 ms / 7.72 RU |
| [C4] | 6 ms / 7.05 RU |
7 ms / 14.67 RU |
7 ms / 14.67 RU |
| [Q5] | 59 ms / 58.92 RU |
4 ms / 8.92 RU |
4 ms / 8.92 RU |
| [Q6] | 306 ms / 2063.54 RU |
83 ms / 532.33 RU |
9 ms / 16.97 RU |
Nous avons optimisé un scénario nécessitant beaucoup de lectures
Vous avez sans doute remarqué que nous avons concentré nos efforts sur l’amélioration des performances des requêtes de lecture (requêtes) au détriment des requêtes d’écriture (commandes). Dans de nombreux cas, les opérations d’écriture déclenchent désormais une dénormalisation ultérieure via les flux de modification, ce qui les rend plus coûteuses en termes de calculs et plus longues à matérialiser.
Nous justifions cette focalisation sur les performances de lecture par le fait qu’une plateforme de création de blogs (comme la plupart des applications sociales) est lourde en lecture. Une charge de travail lourde en lecture indique que le nombre de requêtes en lecture qu’elle doit traiter correspond généralement à des commandes d’une taille plus élevée que le nombre de requêtes en écriture. Il est donc logique d’augmenter le coût d’exécution des demandes d’écriture pour réduire celui des demandes de lecture et les rendre plus performantes.
Si nous examinons l’optimisation la plus extrême que nous avons réalisée, [Q6] est passée de plus de 2000 RU à seulement 17 RU. Nous avons obtenu cela en dénormalisant les publications pour un coût d’environ 10 unités de requête par élément. Comme nous traiterions beaucoup plus de demandes de flux que de création ou de mises à jour de publications, le coût de cette dénormalisation est négligeable au vu de l’économie globale réalisée.
La dénormalisation peut être appliquée de façon incrémentielle
Les améliorations d’extensibilité que nous avons explorées dans cet article impliquent la dénormalisation et la duplication des données sur l’ensemble du jeu de données. Il convient de noter que ces optimisations ne sont pas tenues d’être mises en place le premier jour. Les requêtes qui effectuent un filtrage sur des clés de partition présentent de meilleures performances à grande échelle, mais des requêtes entre partitions peuvent être acceptables si elles sont appelées rarement ou sur un jeu de données limité. Si vous créez simplement un prototype ou si vous lancez un produit à l’aide d’une base utilisateur de petite taille et contrôlée, vous pouvez vraisemblablement passer plus tard à ces améliorations. Les performances de votre modèle constituent l’élément important à surveiller ensuite afin de pouvoir décider si et quand il est temps de les prendre en compte.
Le flux de modification que nous utilisons pour distribuer des mises à jour aux autres conteneurs stocke toutes ces mises à jour de manière permanente. Cette persistance permet de demander toutes les mises à jour depuis la création du conteneur et d’amorcer des affichages dénormalisés comme une opération ponctuelle de mise à jour, même si votre système a déjà beaucoup de données.
Étapes suivantes
Après cette introduction à la modélisation et au partitionnement de données pratiques, vous pouvez consulter les articles suivants pour passer en revue les concepts que nous avons abordés :
- Utiliser des bases de données, des conteneurs et des éléments
- Partitioning in Azure Cosmos DB (Partitionnement dans Azure Cosmos DB)
- Flux de modification dans Azure Cosmos DB