Diagnostiquer et résoudre des problèmes liés aux exceptions Taux de requêtes Azure Cosmos DB trop élevé (429)
S’APPLIQUE À : ![]() NoSQL
NoSQL
Cet article contient des causes et des solutions connues pour différentes erreurs de code d’état 429 pour l’API pour NoSQL. Si vous utilisez l’API pour MongoDB, consultez l’article Résoudre des problèmes courants dans l’API pour MongoDB pour connaître la procédure de débogage du code d’état 16500.
Une exception « Taux de requêtes trop élevé », également connue sous le code d’erreur 429, indique que vos requêtes sur Azure Cosmos DB sont limitées.
Lorsque vous utilisez le débit approvisionné, vous définissez le débit, mesuré en unités de requête par seconde (RU/s), qui est requis pour votre charge de travail. Les opérations de base de données sur le service, telles que les lectures, les écritures et les requêtes, consomment un certain nombre d’unités de requête (RU). En savoir plus sur les unités de requête.
Dans une seconde donnée, si les opérations consomment plus que les unités de requête approvisionnées, Azure Cosmos DB renverra une exception 429. Chaque seconde, le nombre d’unités de requête disponibles est réinitialisé.
Avant de prendre une mesure pour modifier le RU/s, il est important de comprendre la cause racine de la limitation du débit et de résoudre le problème sous-jacent.
Conseil
Les instructions de cet article s’appliquent aux bases de données et aux conteneurs utilisant le débit approvisionné, à la fois la mise à l’échelle automatique et le débit manuel.
Différents messages d’erreur correspondent aux différents types d’exceptions 429 :
- Le taux de requêtes est élevé. Un plus grand nombre d’unités de requête peut être nécessaire, donc aucune modification n’a été apportée.
- La requête n’a pas abouti en raison d’un taux élevé de requêtes de métadonnées.
- La requête n’a pas abouti en raison d’une erreur de service temporaire.
Le taux de demandes est élevé
Il s’agit du scénario le plus courant. Il se produit lorsque les unités de requête consommées par les opérations sur les données dépassent le nombre de RU/s approvisionné. Si vous utilisez le débit manuel, cela se produit lorsque vous avez consommé plus de RU/s que le débit manuel approvisionné. Si vous utilisez la mise à l’échelle automatique, cela se produit lorsque vous avez consommé plus que le nombre maximal de RU/s approvisionnées. Par exemple, si vous avez une ressource approvisionnée avec un débit manuel de 400 RU/s, vous obtenez une erreur 429 lorsque vous consommez plus de 400 unités de requête en une seule seconde. Si vous disposez d’une ressource approvisionnée avec une mise à l’échelle automatique de 4000 RU/s (mises à l’échelle entre 400 RU/s et 4000 RU/s), vous obtenez des réponses 429 quand vous consommez plus de 429 unités de requête en une seule seconde.
Conseil
Toutes les opérations sont facturées selon le nombre de ressources qu’elles consomment. Ces frais sont calculés en unités de requête. Ces frais comprennent les requêtes non achevées correctement en raison d’erreurs d’application telles que 400, 412, 449, etc. Lorsque vous examinez la limitation ou l’utilisation, il est judicieux d’examiner si un modèle a changé dans votre utilisation, ce qui peut entraîner une augmentation de ces opérations. Recherchez plus précisément les balises 412 ou 449 (conflit réel).
Pour plus d’informations sur le débit provisionné, voir Débit provisionné dans Azure Cosmos DB.
Étape 1 : Vérifier les métriques pour déterminer le pourcentage de requêtes avec une erreur 429
Le fait de voir des messages d’erreur 429 ne signifie pas nécessairement qu’il y a un problème avec votre base de données ou votre conteneur. Un pourcentage faible de réponses 429 est normal, que vous utilisiez le débit manuel ou celui de mise à l’échelle automatique, et c’est un signe que vous optimisez les RU/s que vous avez approvisionnés.
Comment examiner
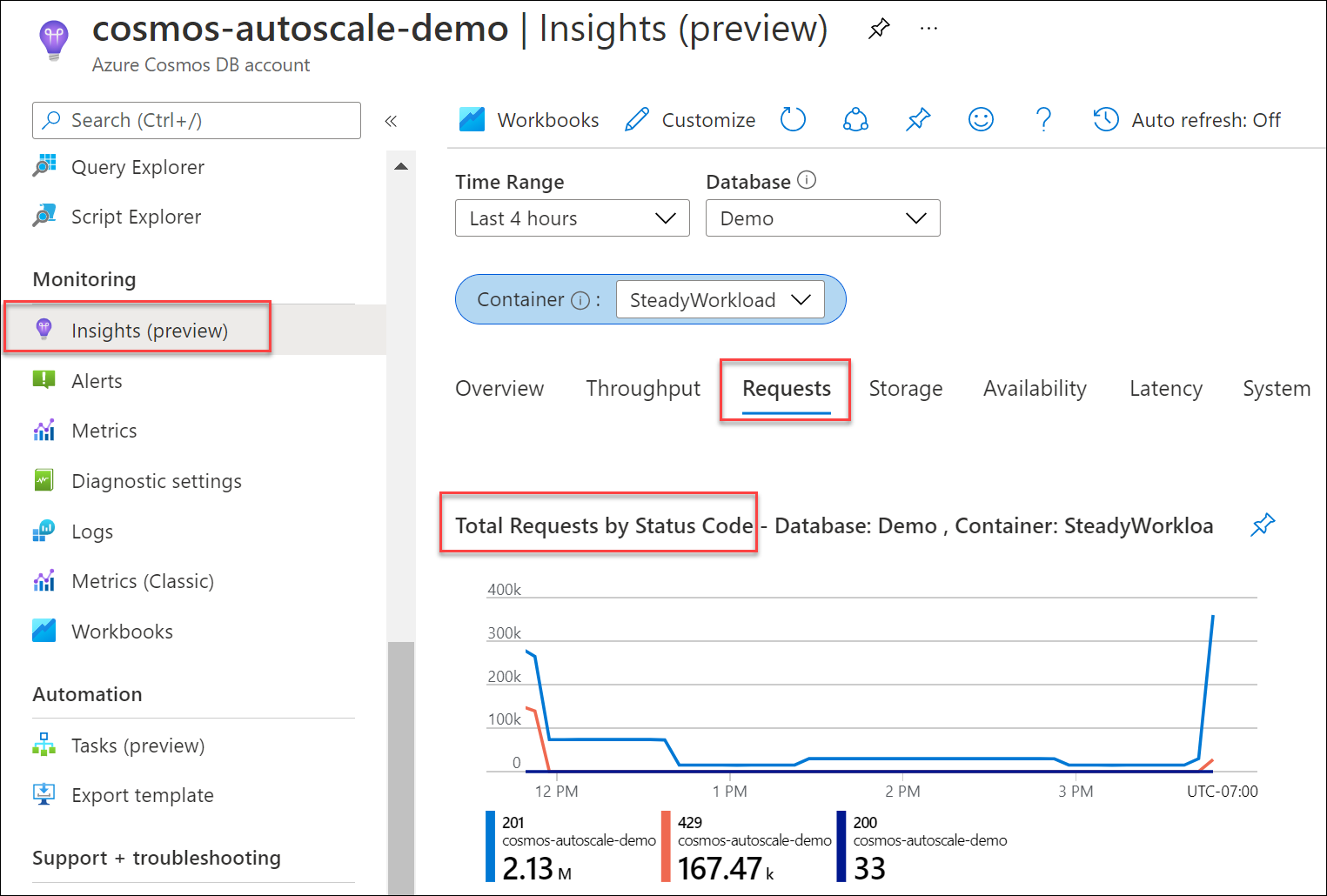
Déterminez le pourcentage de requêtes adressées à votre base de données ou à votre conteneur qui ont donné lieu à des réponses 429, par rapport au nombre total de requêtes réussies. Dans votre compte Azure Cosmos DB, accédez à Insights>Requêtes>Nombre total des requêtes par code d’état. Filtrez sur une base de données et un conteneur spécifiques.
Par défaut, les Kits de développement logiciel (SDK) du client Azure Cosmos DB et les outils d’importation de données, tels qu’Azure Data Factory et la bibliothèque d’exécuteur en bloc, réessayent automatiquement les requêtes en cas d’erreur 429. Ils réessaient généralement jusqu’à neuf fois. Par conséquent, bien que vous puissiez voir des réponses 429 dans les métriques, ces erreurs peuvent ne pas avoir été renvoyées à votre application.
Solution recommandée
En général, pour une charge de travail de production, si vous constatez entre 1 % et 5 % de requêtes avec des réponses 429 et que la latence de bout en bout est acceptable, il s’agit d’un signe sain que les RU/s sont pleinement utilisées. Aucune action n'est requise. Dans le cas contraire, passez aux étapes suivantes de la résolution des problèmes.
Important
Cette plage de 1 à 5 % suppose une distribution uniforme des partitions de votre compte. Si vos partitions ne sont pas distribuées uniformément, votre partition dysfonctionnelle peut retourner une grande quantité d’erreurs 429, tandis que le taux global peut être faible.
Si vous utilisez la mise à l’échelle automatique, il est possible de voir des réponses 429 sur votre base de données ou votre conteneur, même si les RU/s n’ont pas été mises à l’échelle au nombre maximal de RU/s. Consultez la section Taux de requêtes élevé avec la mise à l’échelle automatique pour plus d’informations.
L’une des questions récurrentes est « Pourquoi vois-je des réponses 429 dans les métriques Azure Monitor, mais aucune dans mon propre contrôle d’application ? » Si les métriques Azure Monitor indiquent que vous avez des réponses 429, mais que vous n’en avez vu aucune dans votre propre application, cela s’explique par le fait que, par défaut, les kits de développement logiciel (SDK) de clients Azure Cosmos DB automatically retried internally on the 429 responses et la requête ont réussi lors des nouvelles tentatives suivantes. Par conséquent, le code d’état 429 n’est pas renvoyé à l’application. Dans ces cas-ci, le taux global de réponses 429 est généralement minimal et peut être ignoré sans risque, en supposant que ce taux global est compris entre 1 et 5 % et que la latence de bout en bout est acceptable pour votre application.
Étape 2 : déterminer s’il existe une partition active
Une partition chaude se présente quand une ou plusieurs clés de partition logique consomment une quantité disproportionnée du nombre total de RU/s en raison d’un volume de requêtes plus élevé. Cela peut être dû à une conception de clé de partition qui ne distribue pas les requêtes de manière égale. Ainsi, de nombreuses demandes sont redirigées vers un petit sous-ensemble de partitions logiques (et donc physiques) devenues « hot ». Étant donné que toutes les données d’une partition logique résident sur une partition physique et que le nombre total de RU/s est réparti de façon égale entre les partitions physiques, une partition « hot » peut entraîner des réponses 429 et une utilisation inefficace du débit.
Voici quelques exemples de stratégies de partitionnement qui mènent à des partitions chaudes :
- Vous disposez d’un conteneur qui stocke des données d’appareil IoT pour une charge de travail gourmande en écriture qui est partitionnée par
date. Toutes les données d’une même date se trouveront sur la même partition logique et physique. Comme toutes les données écrites chaque jour ont la même date, cela se traduirait par une partition chaude tous les jours.- Au lieu de cela, pour ce scénario, une clé de partition comme
id(un GUID ou un ID d’appareil) ou une clé de partition synthétique qui associeidetdatedonnerait une cardinalité plus élevée de valeurs et une meilleure distribution du volume de requêtes.
- Au lieu de cela, pour ce scénario, une clé de partition comme
- Vous avez un scénario multilocataire avec un conteneur partitionné par
tenantId. Si un locataire est beaucoup plus actif que les autres, il en résulte une partition active. Par exemple, si le plus grand locataire a 100 000 utilisateurs, mais que la plupart des locataires ont moins de 10 utilisateurs, vous aurez une partition chaude lorsqu’ils seront partitionnés par letenantID.- Pour le scénario précédent, envisagez d’avoir un conteneur dédié pour le plus grand locataire, partitionné par une propriété plus granulaire telle que
UserId.
- Pour le scénario précédent, envisagez d’avoir un conteneur dédié pour le plus grand locataire, partitionné par une propriété plus granulaire telle que
Comment identifier la partition chaude
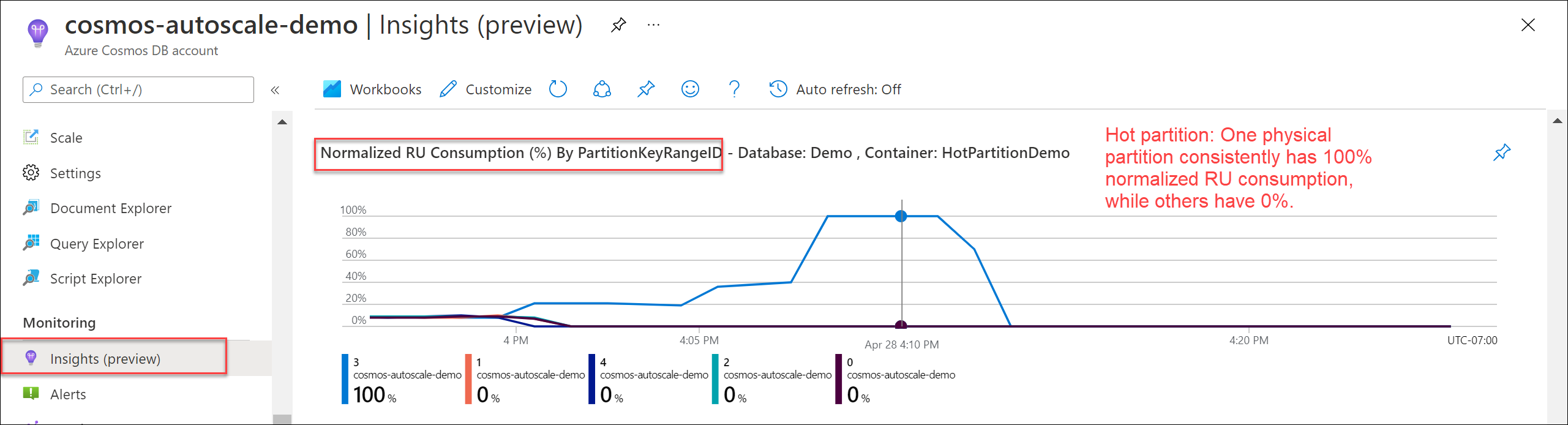
Pour vérifier s’il existe une partition active, accédez à Insights>Débit>Consommation RU normalisée (%) par PartitionKeyRangeID. Filtrez sur une base de données et un conteneur spécifiques.
Chaque PartitionKeyRangeId correspond à une partition physique. Si un PartitionKeyRangeId présente une consommation de RU normalisée plus élevée que les autres (par exemple, l’une d’entre elles est toujours à 100 %, alors que les autres sont à 30 % ou moins), cela peut être le signe d’une partition active. En savoir plus sur la métrique de consommation normalisée de RU.
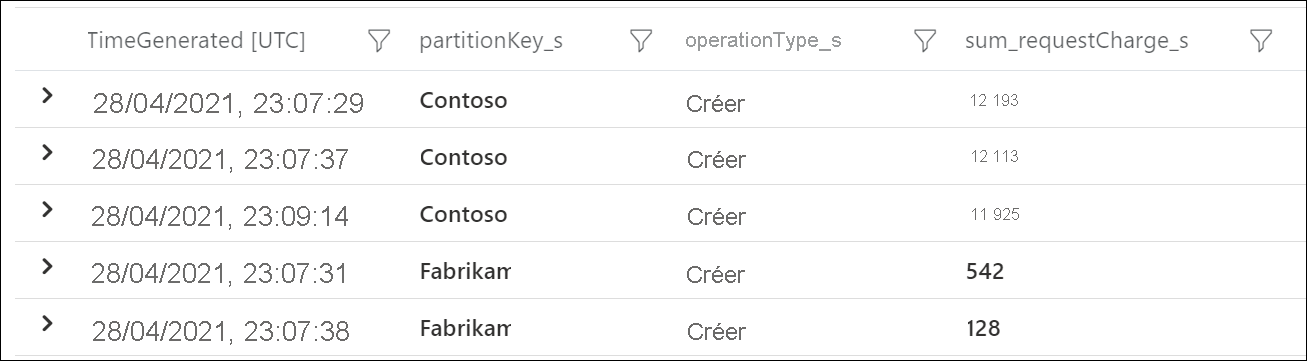
Pour déterminer quelles clés de partition logique consomment le plus de RU/s, utilisez les journaux de diagnostic Azure. Cet exemple de requête additionne le nombre total d’unités de requête consommées par seconde sur chaque clé de partition logique.
Important
L’activation des journaux de diagnostic entraîne des frais distincts pour le service Log Analytics, qui est facturé en fonction du volume de données ingérées. Nous vous recommandons d’activer les journaux de diagnostic pendant une période limitée à des fins de débogage et de les désactiver lorsque vous n’en avez plus besoin. Pour plus d’informations, consultez la page des tarifs.
CDBPartitionKeyRUConsumption
| where TimeGenerated >= ago(24hour)
| where CollectionName == "CollectionName"
| where isnotempty(PartitionKey)
// Sum total request units consumed by logical partition key for each second
| summarize sum(RequestCharge) by PartitionKey, OperationName, bin(TimeGenerated, 1s)
| order by sum_RequestCharge desc
Cet exemple de sortie montre qu’au cours d’une minute donnée, la clé de partition logique ayant pour valeur « Contoso » a consommé environ 12 000 RU/s, tandis que la clé de partition logique ayant pour valeur « Fabrikam » a consommé moins de 600 RU/s. Si ce modèle était cohérent pendant la période où la limitation de débit s’est produite, cela indiquerait une partition chaude.
Conseil
Dans toute charge de travail, il y aura une variation naturelle du volume des requêtes entre les partitions logiques. Vous devez déterminer si la partition chaude est causée par une asymétrie fondamentale due au choix de la clé de partition (ce qui peut nécessiter de changer la clé) ou par un pic temporaire dû à la variation naturelle des modèles de charge de travail.
Solution recommandée
Consultez l’aide relative au choix d’une clé de partition correcte.
Si le pourcentage de requêtes à débit limité est élevé et qu’il n’y a pas de partition active :
- Vous pouvez augmenter les RU/s sur la base de données ou le conteneur à l’aide des Kits de développement logiciel (SDK) clients, du portail Azure, de PowerShell, de l’interface CLI ou du modèle ARM. Suivez les meilleures pratiques en matière de mise à l’échelle du débit approvisionné (RU/s) pour déterminer les unités de requête à définir.
Si le pourcentage de requêtes à débit limité est élevé et qu’il existe une partition active sous-jacente :
- À long terme, pour optimiser les coûts et les performances, envisagez de modifier la clé de partition. La clé de partition ne pouvant pas être mise à jour sur place, cela nécessite de migrer les données vers un nouveau conteneur avec une clé de partition différente. Azure Cosmos DB prend en charge un outil de migration des données en direct à cet effet.
- À court terme, vous pouvez augmenter temporairement les RU/s globales de la ressource pour permettre un débit plus important vers la partition chaude. Cette stratégie n’est pas recommandée à long terme, car elle entraîne un sur-approvisionnement des RU/s et un coût plus élevé.
- À court terme, vous pouvez utiliser la fonctionnalité de redistribution du débit entre les partitions (préversion) pour affecter davantage de RU/s à la partition physique qui est chaude. Cette pratique est recommandée uniquement quand la partition physique chaude est prévisible et cohérente.
Conseil
Lorsque vous augmentez le débit, l’opération de scale-up se termine instantanément ou nécessite jusqu’à cinq à six heures, en fonction du nombre de RU/s pour lesquelles vous souhaitez effectuer un scale-up. Pour connaître le nombre maximal de RU/s que vous pouvez définir sans déclencher l’opération de scale-up asynchrone (qui nécessite qu’Azure Cosmos DB approvisionne davantage de partitions physiques), multipliez le nombre de PartitionKeyRangeIds distincts par 10 000 RU/s. Par exemple, si vous avez 30 000 RU/s approvisionnées et 5 partitions physiques (6000 RU/s allouées par partition physique), vous pouvez passer à 50 000 RU/s (10 000 RU/s par partition physique) dans une opération de scale-up instantané. Une augmentation supérieure à 50 000 RU/s nécessite une opération de scale-up asynchrone. Plus d’informations sur les meilleures pratiques pour la mise à l’échelle du débit approvisionné (RU/s).
Étape 3 : Déterminer les requêtes qui renvoient des réponses 429
Comment examiner des requêtes avec des réponses 429
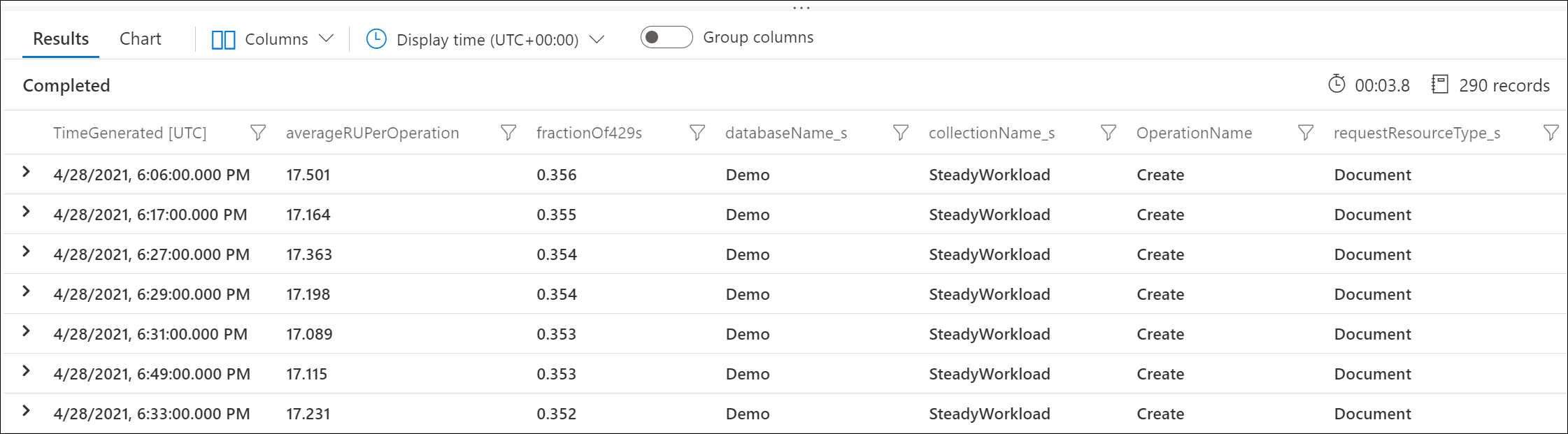
Utilisez les journaux de diagnostic Azure pour identifier les requêtes qui renvoient des réponses 429 et le nombre de RU/s qu’elles ont consommées. Cet exemple de requête agrège les données au niveau de la minute.
Important
L’activation des journaux de diagnostic entraîne des frais distincts pour le service Log Analytics, qui est facturé en fonction du volume de données ingérées. Nous vous recommandons d’activer les journaux de diagnostic pendant une période limitée à des fins de débogage et de les désactiver lorsque vous n’en avez plus besoin. Pour plus d’informations, consultez la page des tarifs.
CDBDataPlaneRequests
| where TimeGenerated >= ago(24h)
| summarize throttledOperations = dcountif(ActivityId, StatusCode == 429), totalOperations = dcount(ActivityId), totalConsumedRUPerMinute = sum(RequestCharge) by DatabaseName, CollectionName, OperationName, RequestResourceType, bin(TimeGenerated, 1min)
| extend averageRUPerOperation = 1.0 * totalConsumedRUPerMinute / totalOperations
| extend fractionOf429s = 1.0 * throttledOperations / totalOperations
| order by fractionOf429s desc
Par exemple, cet exemple de sortie montre que, chaque minute, 30 % des requêtes Create Document ont vu leur débit limité, chaque demande consommant en moyenne 17 RU.
Solution recommandée
Utiliser le Capacity Planner d’Azure Cosmos DB
Vous pouvez utiliser Capacity Planner d’Azure Cosmos DB pour savoir quel est le meilleur débit approvisionné en fonction de votre charge de travail (volume, type d’opérations et taille des documents). Vous pouvez continuer de personnaliser les calculs en fournissant des exemples de données pour obtenir une estimation plus précise.
Réponses 429 sur les requêtes Create, Replace ou Upsert document
- Par défaut, dans l’API pour NoSQL, toutes les propriétés sont indexées. Ajustez la stratégie d’indexation pour indexer uniquement les propriétés nécessaires. Cela réduit le nombre d’unités de requête requises par opération de création de document, ce qui réduit la probabilité de voir des réponses 429 ou vous permet d’effectuer un plus grand nombre d’opérations par seconde pour la même quantité de RU/s approvisionnée.
Réponses 429 sur les requêtes Query document
- Suivez l’aide pour résoudre les problèmes liés aux requêtes dont les frais de RU sont élevés.
Réponses 429 sur les procédures stockées d’exécution
- Les procédures stockées sont destinées aux opérations qui nécessitent des transactions d’écriture sur une valeur de clé de partition. Il n’est pas recommandé d’utiliser les procédures stockées pour un grand nombre d’opérations de lecture ou de requête. Pour des performances optimales, ces opérations de lecture ou d’interrogation doivent être effectuées côté client, à l’aide des Kits de développement logiciel (SDK) Azure Cosmos DB.
Le taux de requêtes est élevé avec la mise à l’échelle automatique
Tous les conseils de cet article s’appliquent à la fois au débit manuel et au débit de mise à l’échelle automatique.
Lors de l’utilisation de la mise à l’échelle automatique, une question récurrente est « Est-il toujours possible de rencontrer des réponses 429 avec la mise à l’échelle automatique ? »
Oui. Il existe deux scénarios principaux dans lesquels cela peut se produire.
Scénario 1 : lorsque le nombre total de RU/s consommées dépasse le nombre maximal de RU/s de la base de données ou du conteneur, le service limite les requêtes en conséquence. Ceci est analogue au dépassement du débit global approvisionné d’une base de données ou d’un conteneur.
Scénario 2 : s’il existe une partition active, c’est-à-dire une valeur de clé de partition logique qui présente un nombre de requêtes beaucoup plus élevé que d’autres valeurs de clé de partition, il est possible que la partition physique sous-jacente dépasse son budget de RU/s. En guise de bonne pratique, pour éviter les partitions à chaud, choisissez une clé de partition appropriée qui entraîne une répartition égale du stockage et du débit. Cela est similaire au moment où l’on retrouve une partition active lors de l’utilisation d’un débit manuel.
Par exemple, si vous sélectionnez l’option de débit maximal de 20 000 RU/s et que vous avez 200 Go de stockage avec quatre partitions physiques, chaque partition physique peut être mise à l’échelle automatiquement jusqu’à 5 000 RU/s. S’il existe une partition active sur une clé de partition logique spécifique, vous verrez des réponses 429 quand la partition physique sous-jacente dans laquelle elle se trouve dépasse 429 RU/s, c’est-à-dire 5000 % de l’utilisation normalisée.
Suivez les instructions de l’Étape 1, de l'Étape 2 et de l’Étape 3 pour déboguer ces scénarios.
Une autre question récurrente est :Pourquoi la consommation normalisée de RU est-elle de 100 %, mais que la mise à l’échelle automatique n’atteint pas le nombre maximal de RU/s ?
Cela se produit généralement pour les charges de travail qui ont des pics d’utilisation temporaires ou intermittents. Lorsque vous utilisez la mise à l’échelle automatique, Azure Cosmos DB ne met à l’échelle le débit maximal de RU/s que lorsque la consommation de RU normalisée est de 100 % pendant une période prolongée et continue dans un intervalle de 5 secondes. Cela permet de s’assurer que la logique de mise à l’échelle est économique pour l’utilisateur, car elle garantit que les pics simples et momentanés ne conduisent pas à une mise à l’échelle inutile ou à un coût plus élevé. Lors des pics momentanés, le système est généralement mis à l’échelle jusqu’à une valeur supérieure à la valeur précédente de RU/s, mais inférieure au nombre maximal de RU/s. Plus d’informations sur la procédure d’interprétation de mesure de consommation normalisée des RU avec la mise à l’échelle automatique.
Limitation du débit des requêtes de métadonnées
Une limitation du débit des métadonnées peut se produire lorsque vous effectuez un volume élevé d’opérations de métadonnées sur des bases de données et/ou des conteneurs. Les opérations sur les métadonnées comprennent :
- Créer, lire, mettre à jour ou supprimer un conteneur ou une base de données
- Répertorier les bases de données ou conteneurs dans un compte Azure Cosmos DB
- Interroger des offres pour voir le débit approvisionné actuel
Il existe une limite de RU réservées au système pour ces opérations. L’augmentation du nombre de RU/s approvisionnées sur la base de données ou le conteneur n’a aucun impact et n’est donc pas recommandée. Consultez Limites de service du plan de contrôle.
Comment examiner
Accédez à Insights>Système>Requêtes de métadonnées par code d’état. Filtrez sur une base de données et un conteneur spécifiques, le cas échéant.

Solution recommandée
Si votre application doit effectuer des opérations de métadonnées, envisagez d’implémenter une stratégie de backoff pour envoyer ces requêtes à un débit inférieur.
Utilisez des instances de client Azure Cosmos DB statiques. Quand DocumentClient ou CosmosClient est initialisé, le Kit de développement logiciel (SDK) Azure Cosmos DB extrait des métadonnées sur le compte, y compris des informations sur le niveau de cohérence, les bases de données, les conteneurs, les partitions et les offres. Cette initialisation peut consommer un grand nombre d’unités de requête et devrait rarement être effectuée. Utilisez une seule instance DocumentClient et utilisez-la pour la durée de vie de votre application.
Mettez en cache les noms des bases de données et des conteneurs. Récupérez les noms de vos bases de données et de vos conteneurs à partir de la configuration ou mettez-les en cache au démarrage. Les appels comme ReadDatabaseAsync/ReadDocumentCollectionAsync ou CreateDatabaseQuery/CreateDocumentCollectionQuery entraînent des appels de métadonnées au service, qui consomment la limite de RU réservées au système. Ces opérations ne doivent pas être effectuées fréquemment.
Limitation du débit en raison d’une erreur de service temporaire
Cette erreur 429 est renvoyée lorsque la requête rencontre une erreur de service temporaire. L’augmentation du nombre de RU/s sur la base de données ou le conteneur n’a aucun impact et n’est donc pas recommandée.
Solution recommandée
Relancez la requête. Si l’erreur persiste pendant plusieurs minutes, créez un ticket de support à partir du portail Azure.
Étapes suivantes
- Surveiller la consommation normalisée de RU/s de votre base de données ou de votre conteneur.
- Diagnostiquer et résoudre des problèmes lors de l’utilisation du kit de développement logiciel (SDK) .NET Azure Cosmos DB.
- Découvrez les recommandations relatives aux performances pour .NET V3 et .NET V2.
- Diagnostiquer et résoudre des problèmes lors de l'utilisation du SDK Java v4 Azure Cosmos DB.
- Découvrez les recommandations relatives aux performances pour le SDK Java v4.