Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier les répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer de répertoire.
Important
Azure Cosmos DB pour PostgreSQL n’est plus pris en charge pour les nouveaux projets. N’utilisez pas ce service pour les nouveaux projets. Utilisez plutôt l’un des deux services suivants :
Utilisez Azure Cosmos DB pour NoSQL pour une solution de base de données distribuée conçue pour des scénarios à grande échelle avec un contrat de niveau de service de disponibilité (SLA) de 99,999%, une mise à l’échelle automatique instantanée et un basculement automatique entre plusieurs régions.
Utilisez la fonctionnalité Elastic Clusters d'Azure Database pour PostgreSQL pour un PostgreSQL partagé utilisant l'extension open source Citus.
Azure Data Factory est un service d’ETL et d’intégration de données basé sur le cloud. Il vous permet de créer des workflows basés sur les données pour déplacer et transformer des données à grande échelle.
Avec Azure Data Factory, vous pouvez créer et planifier des flux de travail pilotés par les données (appelés pipelines) qui peuvent ingérer des données provenant de magasins de données disparates. Les pipelines peuvent être exécutés localement, dans Azure ou sur d’autres fournisseurs de cloud pour l'analyse et la création de rapports.
Data Factory dispose d’un récepteur de données pour Azure Cosmos DB for PostgreSQL. Le récepteur de données vous permet d’importer vos données (fichiers relationnels, NoSQL, lac de données) dans des tables Azure Cosmos DB for PostgreSQL pour le stockage, le traitement et la création de rapports.
Important
Data Factory ne prend pas en charge les points de terminaison privés pour Azure Cosmos DB for PostgreSQL à ce stade.
Data Factory pour l’ingestion en temps réel
Voici les principales raisons de choisir Azure Data Factory pour l’ingestion de données dans Azure Cosmos DB for PostgreSQL :
- Facile à utiliser : offre un environnement visuel sans code pour orchestrer et automatiser le déplacement des données.
- Puissant : utilise toute la capacité de la bande passante réseau sous-jacente, pour un débit maximal de 5 Gio/s.
- Connecteurs intégrés : intégrez toutes vos sources de données grâce à plus de 90 connecteurs intégrés.
- Économique : prend en charge un service cloud serverless complètement managé avec paiement à l'utilisation et qui évolue à la demande.
Étapes pour utiliser Data Factory
Dans cet article, vous créez un pipeline de données à l’aide de l’interface utilisateur (IU) d’Azure Data Factory. Le pipeline de cette fabrique de données copie les données d’un stockage Blob Azure vers une base de données. Pour obtenir la liste des magasins de données pris en charge en tant que sources et récepteurs, consultez le tableau Magasins de données pris en charge.
Dans Data Factory, vous pouvez utiliser l’activité Copy pour copier des données entre des magasins de données situés localement et dans le cloud vers Azure Cosmos DB for PostgreSQL. Si vous débutez avec Data Factory, voici un guide rapide pour vous aider à démarrer :
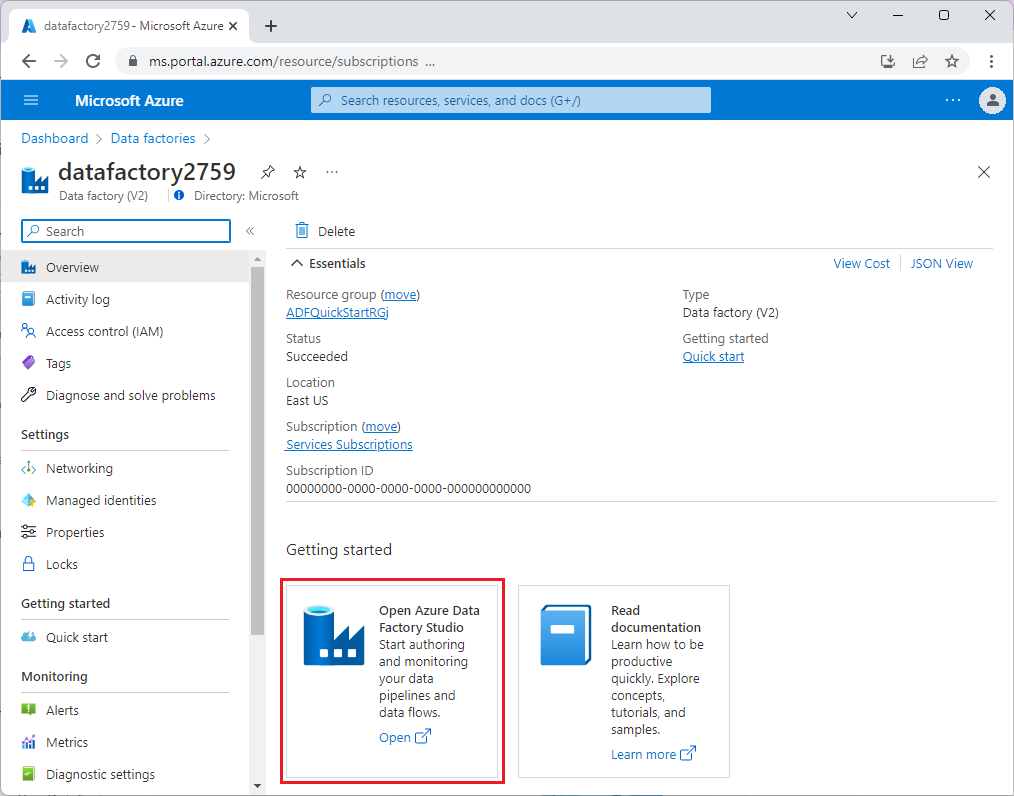
Une fois Data Factory approvisionné, accédez à votre fabrique de données et lancez Azure Data Factory Studio. La page d’accueil Data Factory devrait s’afficher comme dans l’image suivante :
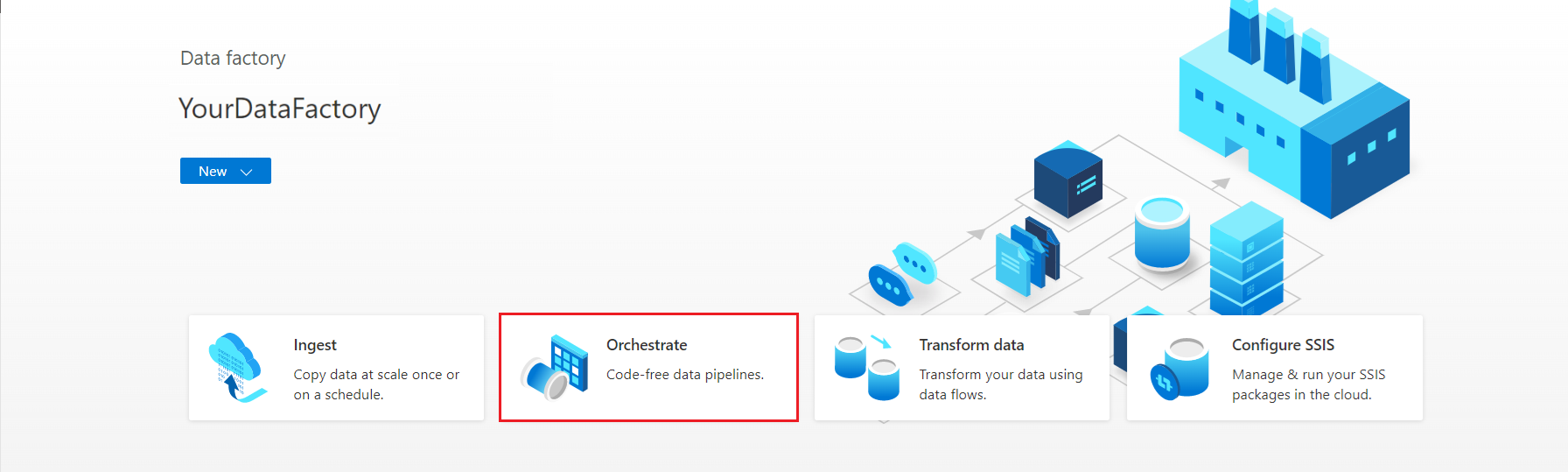
Dans la page d’accueil d’Azure Data Factory Studio, sélectionnez Orchestrer.
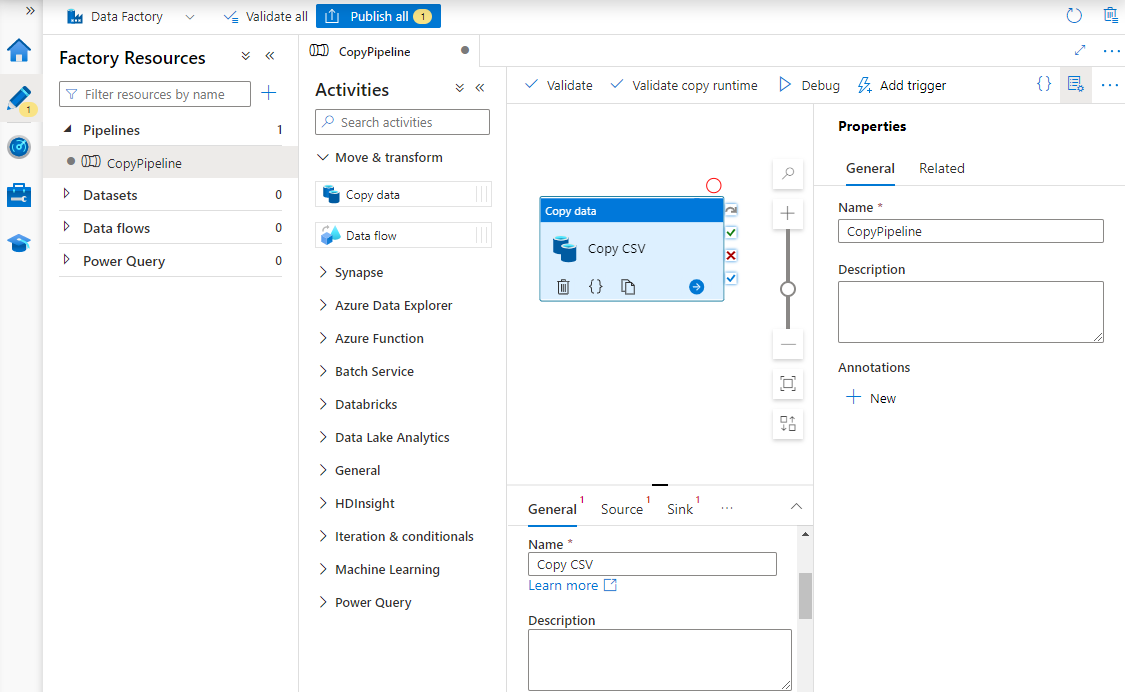
Sous Propriétés, entrez un nom pour le pipeline.
Dans la boîte à outils Activités, développez la catégorie Déplacer et transformer, puis faites glisser l’activité Copier les données vers l’aire du concepteur de pipeline. En bas du volet concepteur, sous l’onglet Général, entrez un nom pour l’activité de copie.
Configurez Source.
Dans la page Activités, sélectionnez l’onglet Source. Sélectionnez Nouveau pour créer un jeu de données source.
Dans la boîte de dialogue Nouveau jeu de données, sélectionnez Stockage Blob Azure, puis Continuer.
Choisissez le type de format de vos données, puis sélectionnez Continuer.
Dans la page Définir les propriétés, sous Service lié, sélectionnez Nouveau.
Dans la page Nouveau service lié, sélectionnez un nom pour le service lié, puis sélectionnez votre compte de stockage dans la liste Nom du compte de stockage.
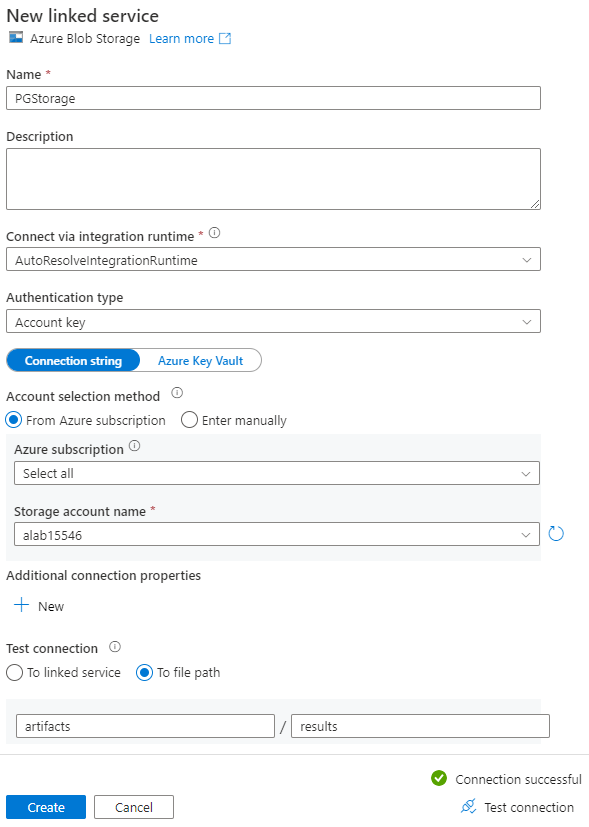
Sous Tester la connexion, sélectionnez Au chemin d'accès du fichier, entrez le conteneur et le répertoire auxquels se connecter, puis sélectionnez Tester la connexion.
Sélectionnez Créer pour enregistrer la configuration.
Dans l’écran Définir les propriétés, sélectionnez OK.
Configurez Sink.
Dans la page Activités, sélectionnez l’onglet Récepteur. Sélectionnez Nouveau pour créer un jeu de données de récepteur.
Dans la boîte de dialogue Nouveau jeu de données, sélectionnez Azure DB pour PostgreSQL, puis Continuer.
Dans la page Définir les propriétés, sous Service lié, sélectionnez Nouveau.
Dans la page Nouveau service lié, entrez un nom pour le service lié, puis sélectionnez Entrée manuellement dans la Méthode de sélection du compte.
Entrez le nom du coordinateur de votre cluster dans le champ Nom de domaine complet. Vous pouvez copier le nom du coordinateur à partir de la page de présentation de votre cluster Azure Cosmos DB for PostgreSQL.
Laissez le port par défaut 5432 dans le champ Port pour une connexion directe au coordinateur ou remplacez-le par le port 6432 pour vous connecter au port PgBouncer géré.
Entrez le nom de la base de données sur votre cluster et fournissez les informations d’identification pour vous y connecter.
Sélectionnez SSL dans la liste déroulante Méthode de chiffrement.
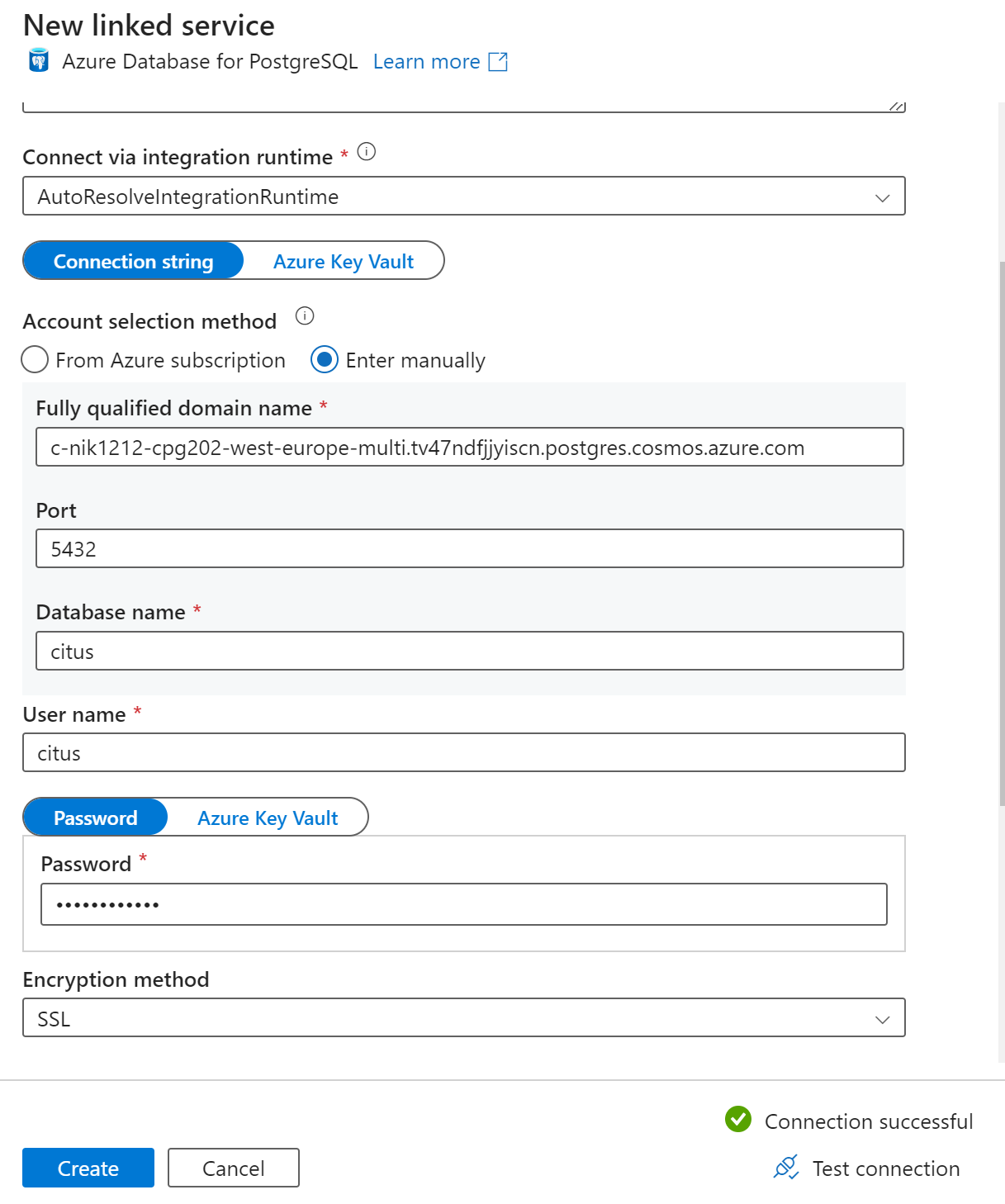
Sélectionnez Tester la connexion en bas du panneau pour valider la configuration du récepteur.
Sélectionnez Créer pour enregistrer la configuration.
Dans l’écran Définir les propriétés, sélectionnez OK.
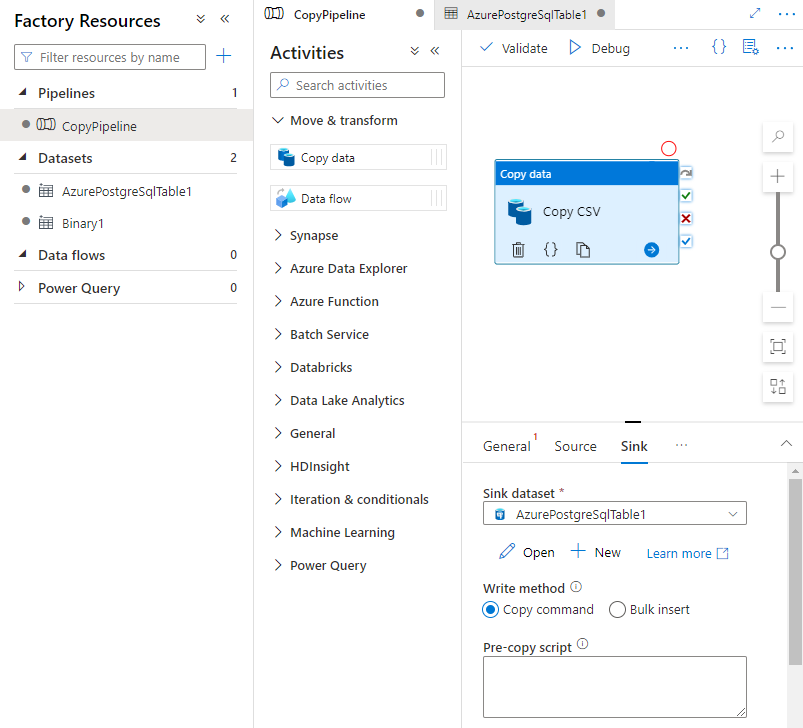
Dans l’onglet Récepteur de la page Activités, sélectionnez Ouvrir en regard du menu déroulant Jeu de données de récepteur, puis sélectionnez le nom de la table sur le cluster de destination où vous souhaitez ingérer les données.
Sous Méthode d’écriture, sélectionnez Copier la commande.
Sur la barre d’outils située au-dessus du canevas, sélectionnez Valider pour valider les paramètres du pipeline. Corrigez toute erreur, revérifiez et assurez-vous que le pipeline est bien validé.
Sélectionnez Déboguer sur la barre d’outils pour exécuter le pipeline.
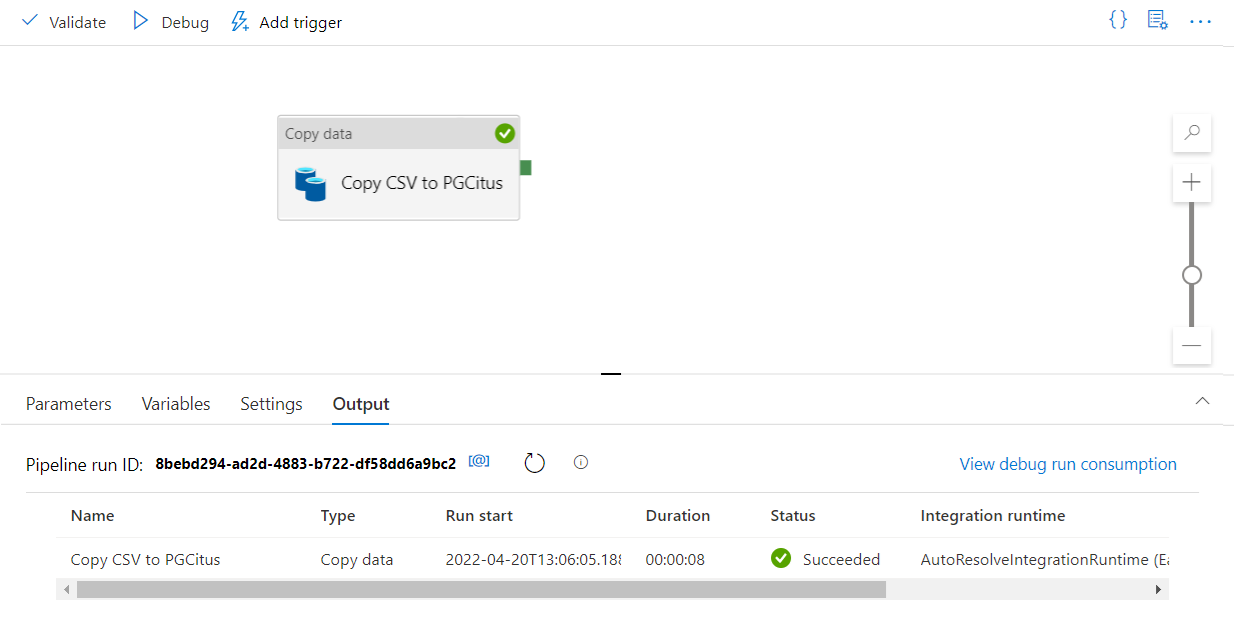
Une fois que le pipeline peut s’exécuter correctement, sélectionnez Publier tout dans la barre d’outils supérieure. Cette action a pour effet de publier les entités (jeux de données et pipelines) que vous avez créées dans Data Factory.
Appeler une procédure stockée dans Data Factory
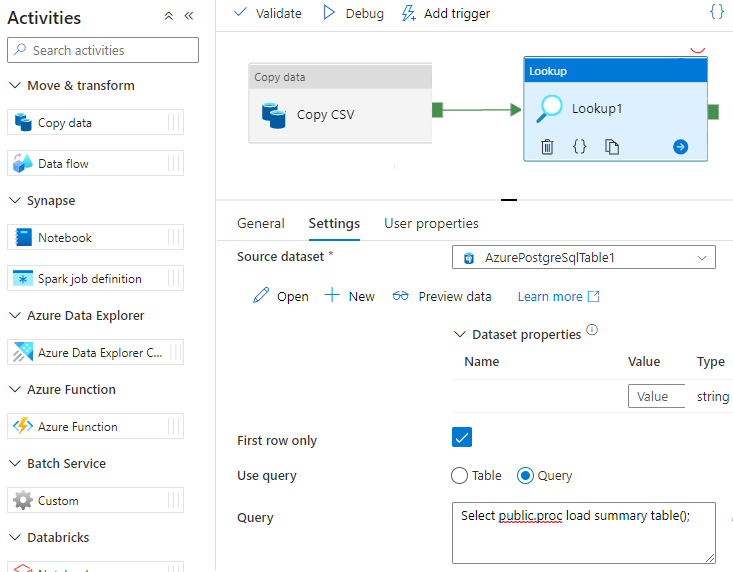
Dans certains scénarios, vous pouvez être amené à appeler une fonction/procédure stockée pour envoyer des données agrégées d’une table de mise en lots vers une table de synthèse. Data Factory ne propose pas d’activité de procédure stockée pour Azure Cosmos DB for PostgreSQL, mais comme solution de contournement, vous pouvez utiliser l’activité de recherche avec une requête pour appeler une procédure stockée, comme indiqué ci-dessous :
Étapes suivantes
- Découvrez comment créer un tableau de bord en temps réel avec Azure Cosmos DB for PostgreSQL.
- Découvrez comment déplacer votre charge de travail vers Azure Cosmos DB for PostgreSQL.