Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier les répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer de répertoire.
Important
Azure Cosmos DB pour PostgreSQL n’est plus pris en charge pour les nouveaux projets. N’utilisez pas ce service pour les nouveaux projets. Utilisez plutôt l’un des deux services suivants :
Utilisez Azure Cosmos DB pour NoSQL pour une solution de base de données distribuée conçue pour des scénarios à grande échelle avec un contrat de niveau de service de disponibilité (SLA) de 99,999%, une mise à l’échelle automatique instantanée et un basculement automatique entre plusieurs régions.
Utilisez la fonctionnalité Elastic Clusters d'Azure Database pour PostgreSQL pour un PostgreSQL partagé utilisant l'extension open source Citus.
Avant d’examiner la procédure de création d’une nouvelle application, il est utile de donner une vue d’ensemble rapide des termes et concepts impliqués.
Vue d’ensemble de l’architecture
Azure Cosmos DB for PostgreSQL vous donne la possibilité de distribuer des tables et/ou des schémas sur plusieurs machines au sein d’un cluster et de les interroger de manière transparente comme avec du PostgreSQL simple :
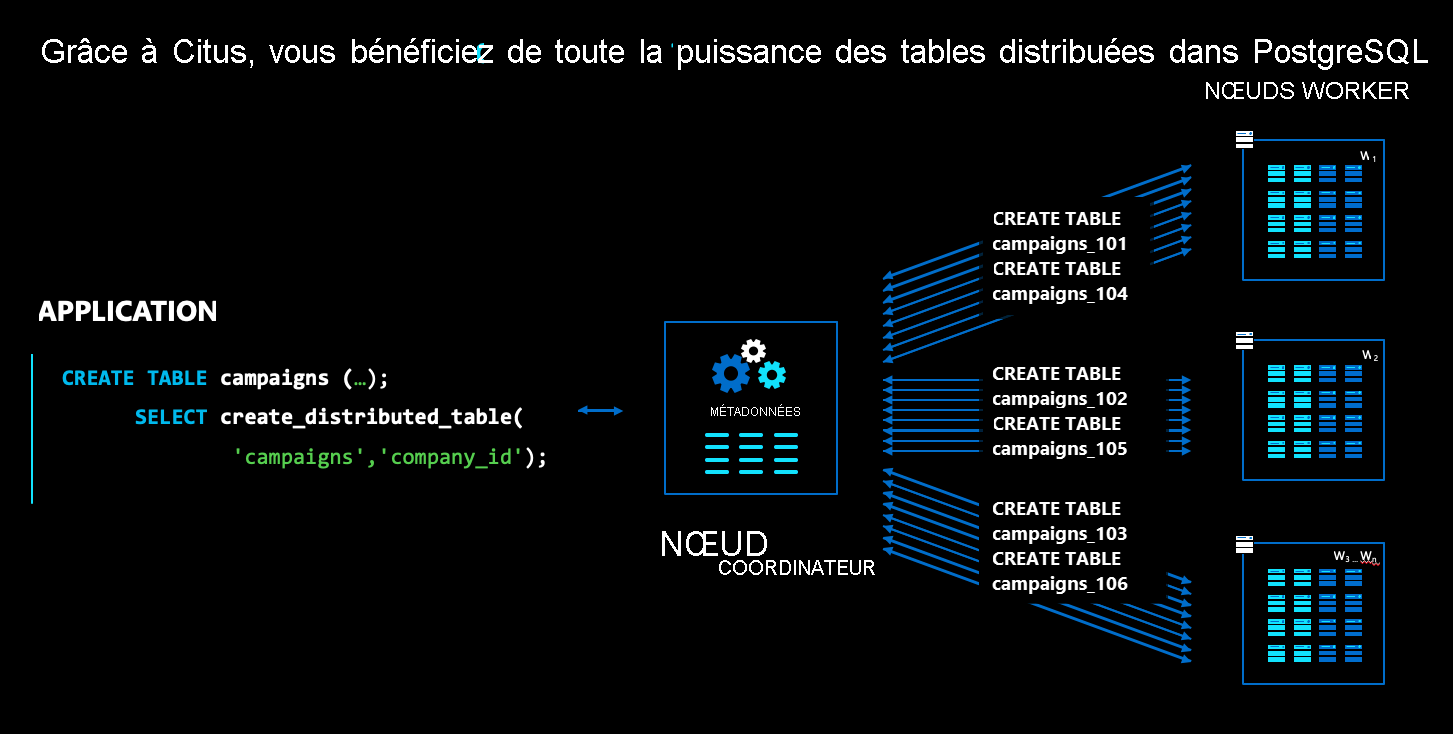
Dans l’architecture Azure Cosmos DB pour PostgreSQL, il existe plusieurs types de nœuds :
- Le nœud coordinateur stocke les métadonnées des tables distribuées. Il est responsable de la planification distribuée.
- Les nœuds Worker, quant à eux, stockent les données et métadonnées proprement dites, et effectuent les calculs.
- Le coordinateur et les Workers sont des bases de données PostgreSQL simples, sur lesquelles est chargée l’extension
citus.
Pour distribuer une table PostgreSQL normale, comme campaigns dans le diagramme ci-dessus, exécutez une commande nommée create_distributed_table(). Azure Cosmos DB for PostgreSQL crée alors en toute transparence des partitions pour la table sur les différents nœuds Worker. Dans le diagramme, les partitions sont représentées sous forme de boîte bleues.
Pour distribuer un schéma PostgreSQL normal, vous exécutez la commande citus_schema_distribute(). Une fois que vous avez exécuté cette commande, Azure Cosmos DB for PostgreSQL transforme de manière transparente les tables dans ces schémas en tables colocalisées à partition unique qui peuvent être déplacées en tant qu’unité entre les nœuds du cluster.
Remarque
Sur un cluster sans nœuds Worker, les partitions de tables distribuées se trouvent sur le nœud coordinateur.
Les partitions consistent en des tables PostgreSQL simples (mais portant un nom spécial) qui contiennent des sections de données. Dans notre exemple, étant donné que nous avons distribué campaigns par company_id, les partitions contiennent des campagnes, et les campagnes de différentes entreprises sont affectées à différentes partitions.
Colonne de distribution (également appelée clé de partition)
create_distributed_table() est la fonction magique fournie par Azure Cosmos DB for PostgreSQL pour distribuer des tables et utiliser des ressources sur plusieurs machines.
SELECT create_distributed_table(
'table_name',
'distribution_column');
Le deuxième argument ci-dessus sélectionne une colonne de la table comme colonne de distribution. Il peut s’agir de n’importe quelle colonne d’un type PostgreSQL natif (les plus courants étant entier et texte). La valeur de la colonne de distribution détermine quelles lignes vont dans quelles partitions. C’est pourquoi cette colonne est également appelée clé de partition.
Azure Cosmos DB for PostgreSQL détermine comment exécuter des requêtes en fonction de leur utilisation de la clé de partition :
| La requête implique | Elle s’exécute… |
|---|---|
| Une seule clé de partition | Sur le nœud Worker qui contient sa partition |
| Plusieurs clés de partition | En parallèle sur plusieurs nœuds |
Le choix de la clé de partition détermine les performances et la scalabilité des applications.
- Une distribution de données inégale selon les clés de partition (également appelée asymétrie des données) n’est pas optimale pour les performances. Par exemple, ne choisissez pas de colonne pour laquelle une seule valeur représente 50 % des données.
- Les clés de partition présentant une cardinalité faible peuvent nuire à la scalabilité. Vous ne pouvez utiliser que le même nombre de fragments qu'il y a de valeurs de clés distinctes. Choisissez une clé dont la cardinalité est de l’ordre de quelques centaines ou milliers.
- La jointure de deux tables volumineuses associées à différentes clés de partition peut être lente. Choisissez une clé de partition commune aux grandes tables. Pour plus d’informations, consultez Colocalisation.
Colocation
Un autre concept étroitement lié à la clé de partition est la colocalisation. Les tables partitionnées par les mêmes valeurs de colonne de distribution sont colocalisées : les partitions de tables colocalisées sont stockées ensemble sur les mêmes Workers.
Voici deux tables partitionnées par la même clé, site_id. Elles sont colocalisées.
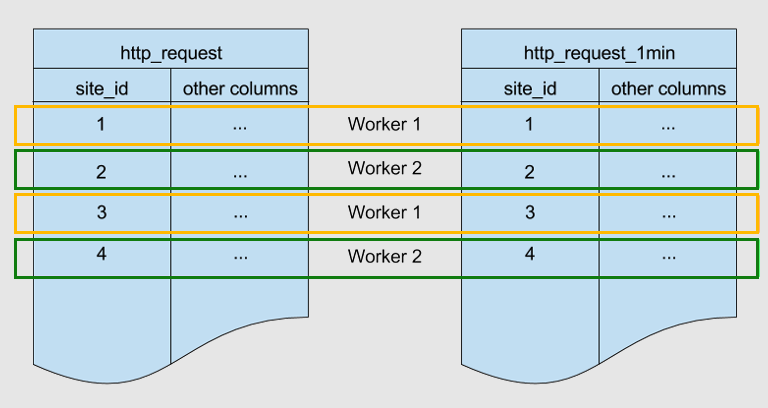
Azure Cosmos DB for PostgreSQL garantit que les lignes dont la valeur site_id est identique dans les deux tables sont stockées sur le même nœud Worker. Comme vous pouvez le constater, pour les deux tables, les lignes contenant site_id=1 sont stockées sur le Worker 1. Il en va de même pour les autres identifiants de site.
La colocalisation permet d’optimiser les jointures entre ces tables. Si vous joignez les deux tables sur site_id, Azure Cosmos DB for PostgreSQL peut effectuer la jointure localement sur les nœuds Worker sans mélanger les données entre les nœuds.
Les tables d’un schéma distribué sont toujours regroupées ensemble.