Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier les répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer de répertoire.
Important
Azure Cosmos DB pour PostgreSQL n’est plus pris en charge pour les nouveaux projets. N’utilisez pas ce service pour les nouveaux projets. Utilisez plutôt l’un des deux services suivants :
Utilisez Azure Cosmos DB pour NoSQL pour une solution de base de données distribuée conçue pour des scénarios à grande échelle avec un contrat de niveau de service de disponibilité (SLA) de 99,999%, une mise à l’échelle automatique instantanée et un basculement automatique entre plusieurs régions.
Utilisez la fonctionnalité Elastic Clusters d'Azure Database pour PostgreSQL pour un PostgreSQL partagé utilisant l'extension open source Citus.
Dans ce tutoriel, vous allez utiliser Azure Cosmos DB pour PostgreSQL pour découvrir comment :
- Créer un cluster
- Utiliser l’utilitaire psql pour créer un schéma
- Partitionner des tables entre des nœuds
- Ingérer des exemples de données
- Interroger les données de locataire
- Partager des données entre les locataires
- Personnaliser le schéma par locataire
Prérequis
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Créer un cluster
Connectez-vous au portail Azure et procédez comme suit pour créer un cluster Azure Cosmos DB pour PostgreSQL :
Accédez à Créer un cluster Azure Cosmos DB pour PostgreSQL dans le portail Azure.
Sur le formulaire Créer un cluster Azure Cosmos DB pour PostgreSQL :
Renseignez l’onglet Informations de base.
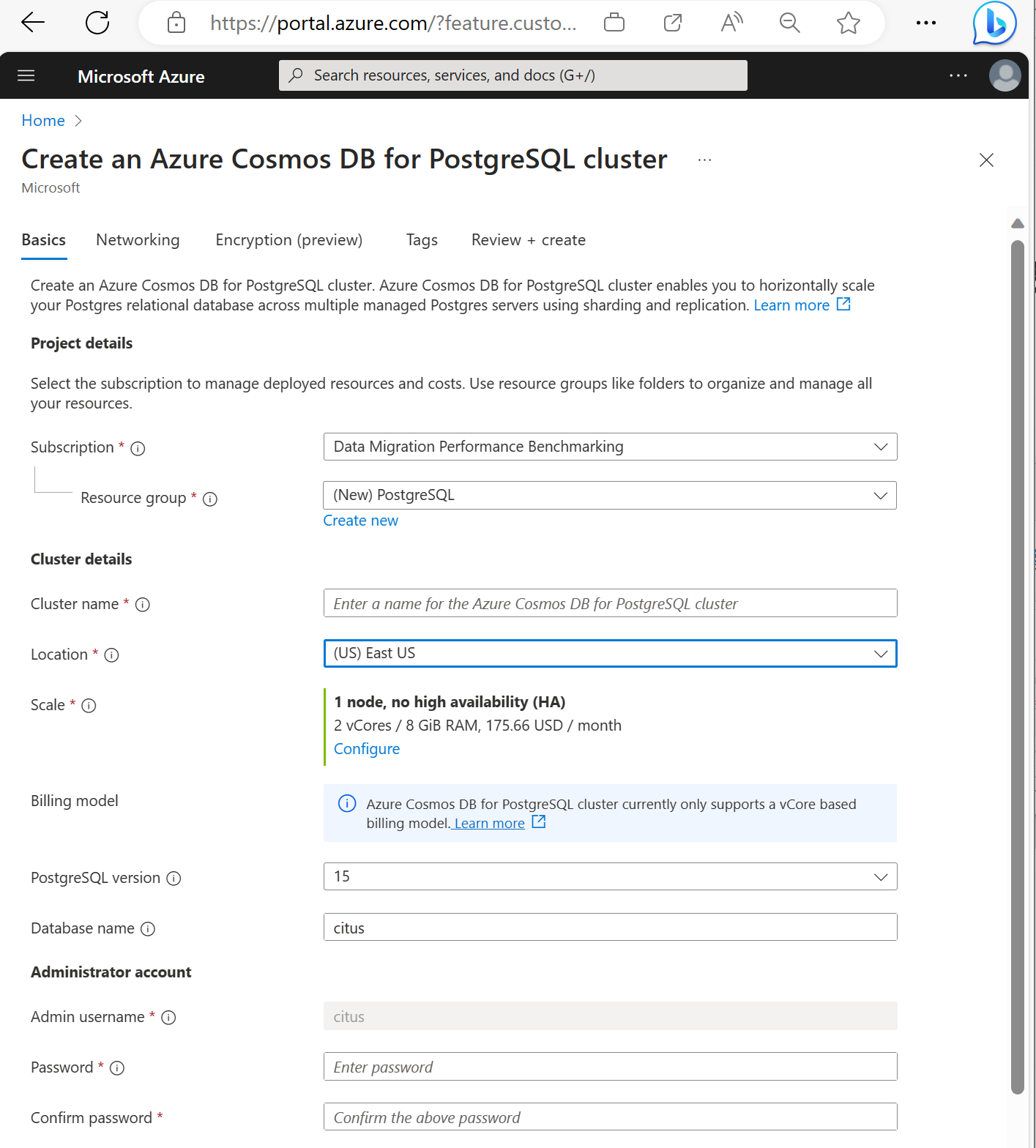
La plupart des options sont explicites, mais n’oubliez pas que :
- Le nom du cluster détermine le nom DNS que vos applications utilisent pour se connecter, au format
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Vous pouvez choisir une version principale de PostgreSQL, telle que la 15. Azure Cosmos DB for PostgreSQL prend toujours en charge la dernière version de Citus pour la principale version de Postgres sélectionnée.
- Le nom d’utilisateur de l’administrateur doit être
citus. - Vous pouvez laisser le nom de la base de données à sa valeur par défaut « citus » ou définir votre unique nom de base de données. Vous ne pouvez pas renommer une base de données après l’approvisionnement du cluster.
- Le nom du cluster détermine le nom DNS que vos applications utilisent pour se connecter, au format
Sélectionnez Suivant : Mise en réseau en bas de l’écran.
Sur l’écran Mise en réseau, sélectionnez Autoriser l’accès public à partir des ressources et services Azure dans Azure sur ce cluster.
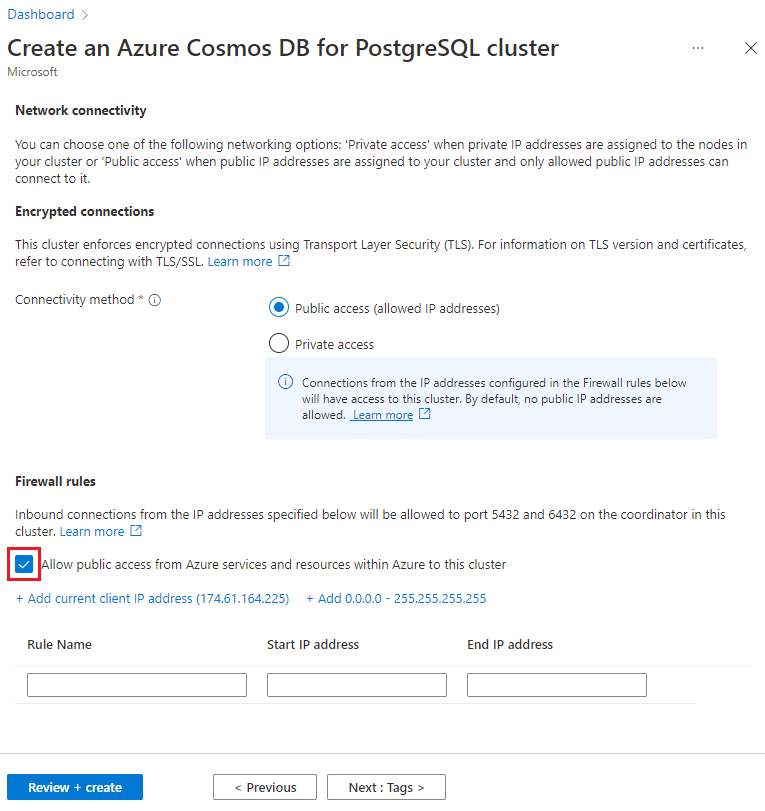
Sélectionnez Vérifier + créer puis, une fois la validation réussie, sélectionnez Créer pour créer le cluster.
Le provisionnement prend quelques minutes. La page redirige vers la supervision du déploiement. Quand l’état passe de Le déploiement est en cours à Votre déploiement est terminé, sélectionnez Accéder à la ressource.
Utiliser l’utilitaire psql pour créer un schéma
Une fois connecté à Azure Cosmos DB pour PostgreSQL à l’aide de psql, vous pouvez effectuer quelques tâches de base. Ce tutoriel vous explique comment créer une application web qui autorise les annonceurs à effectuer le suivi de leurs campagnes.
Plusieurs entreprises peuvent utiliser l’application. Nous allons donc créer une table pour stocker les entreprises et une autre pour leurs campagnes. Dans la console psql, exécutez les commandes suivantes :
CREATE TABLE companies (
id bigserial PRIMARY KEY,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE campaigns (
id bigserial,
company_id bigint REFERENCES companies (id),
name text NOT NULL,
cost_model text NOT NULL,
state text NOT NULL,
monthly_budget bigint,
blocked_site_urls text[],
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id)
);
Chaque campagne paiera pour afficher des publicités. Ajoutez également une table pour les publicités, en exécutant le code suivant dans psql après le code ci-dessus :
CREATE TABLE ads (
id bigserial,
company_id bigint,
campaign_id bigint,
name text NOT NULL,
image_url text,
target_url text,
impressions_count bigint DEFAULT 0,
clicks_count bigint DEFAULT 0,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, campaign_id)
REFERENCES campaigns (company_id, id)
);
Enfin, nous effectuerons le suivi des statistiques relatives aux clics et aux impressions pour chaque publicité :
CREATE TABLE clicks (
id bigserial,
company_id bigint,
ad_id bigint,
clicked_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_click_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
CREATE TABLE impressions (
id bigserial,
company_id bigint,
ad_id bigint,
seen_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_impression_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
Vous pouvez localiser les tables nouvellement créées dans la liste des tables dans psql en exécutant :
\dt
Les applications multilocataires peuvent imposer l’unicité seulement par client. C’est pourquoi toutes les clés primaires et étrangères incluent l’ID de l’entreprise.
Partitionner des tables entre des nœuds
Un déploiement de Azure Cosmos DB pour PostgreSQL stocke les lignes de la table sur différents nœuds en fonction de la valeur d’une colonne désignée par l’utilisateur. Cette « colonne de distribution » désigne quel locataire possède quelles lignes.
Nous allons définir la colonne de distribution en tant que company_id, l’identificateur du locataire. Dans psql, exécutez les fonctions suivantes :
SELECT create_distributed_table('companies', 'id');
SELECT create_distributed_table('campaigns', 'company_id');
SELECT create_distributed_table('ads', 'company_id');
SELECT create_distributed_table('clicks', 'company_id');
SELECT create_distributed_table('impressions', 'company_id');
Important
La distribution de tables ou l’utilisation du partitionnement basé sur un schéma est nécessaire pour tirer parti des fonctionnalités de performances d’Azure Cosmos DB for PostgreSQL. Si vous ne distribuez pas de tables ou de schémas, les nœuds Worker ne peuvent s’empêcher d’exécuter des requêtes impliquant leurs tables.
Ingérer des exemples de données
En dehors de psql à présent, dans la ligne de commande normale, téléchargez des exemples de jeux de données :
for dataset in companies campaigns ads clicks impressions geo_ips; do
curl -O https://examples.citusdata.com/mt_ref_arch/${dataset}.csv
done
De nouveau dans psql, effectuez le chargement en masse des données. Veillez à exécuter psql dans le répertoire où vous avez téléchargé les fichiers de données.
SET client_encoding TO 'UTF8';
\copy companies from 'companies.csv' with csv
\copy campaigns from 'campaigns.csv' with csv
\copy ads from 'ads.csv' with csv
\copy clicks from 'clicks.csv' with csv
\copy impressions from 'impressions.csv' with csv
Ces données sont désormais réparties entre les nœuds worker.
Interroger les données de locataire
Lorsque l’application demande des données pour un locataire individuel, la base de données peut exécuter la requête sur un nœud worker unique. Les requêtes de locataire unique filtrent par un ID de locataire unique. Par exemple, la requête suivante filtre company_id = 5 pour les publicités et les impressions. Essayez de l’exécuter dans psql pour voir les résultats.
SELECT a.campaign_id,
RANK() OVER (
PARTITION BY a.campaign_id
ORDER BY a.campaign_id, count(*) desc
), count(*) as n_impressions, a.id
FROM ads as a
JOIN impressions as i
ON i.company_id = a.company_id
AND i.ad_id = a.id
WHERE a.company_id = 5
GROUP BY a.campaign_id, a.id
ORDER BY a.campaign_id, n_impressions desc;
Partager des données entre les locataires
Jusqu’à présent, toutes les tables ont été distribuées par company_id. Mais certaines données « n’appartiennent » par nature à aucun locataire en particulier et peuvent être partagées. Par exemple, toutes les entreprises figurant dans l’exemple de plateforme de publicité peuvent souhaiter obtenir des informations géographiques sur leur public ciblé en fonction des adresses IP.
Créez une table pour stocker les informations géographiques partagées. Exécutez les commandes suivantes dans psql :
CREATE TABLE geo_ips (
addrs cidr NOT NULL PRIMARY KEY,
latlon point NOT NULL
CHECK (-90 <= latlon[0] AND latlon[0] <= 90 AND
-180 <= latlon[1] AND latlon[1] <= 180)
);
CREATE INDEX ON geo_ips USING gist (addrs inet_ops);
Définissez ensuite geo_ips comme « table de référence » pour stocker une copie de la table sur chaque nœud worker.
SELECT create_reference_table('geo_ips');
Chargez-la avec des exemples de données. Pensez à exécuter cette commande dans psql à partir du répertoire où vous avez téléchargé le jeu de données.
\copy geo_ips from 'geo_ips.csv' with csv
La jointure de la table de clics avec geo_ips est efficace sur tous les nœuds. Voici une jointure fournissant les emplacements de toutes les personnes qui ont cliqué sur la publicité 290. Essayez d’exécuter cette requête dans psql.
SELECT c.id, clicked_at, latlon
FROM geo_ips, clicks c
WHERE addrs >> c.user_ip
AND c.company_id = 5
AND c.ad_id = 290;
Personnaliser le schéma par locataire
Chaque locataire peut avoir besoin de stocker des informations spéciales dont les autres utilisateurs n’ont pas besoin. Toutefois, tous les locataires partagent une infrastructure commune avec un schéma de base de données identique. Où peuvent aller les données supplémentaires ?
Une astuce consiste à utiliser un type de colonne de durée indéterminée comme le type JSONB de PostgreSQL. Notre schéma a un champ JSONB dans clicks appelé user_data.
Une entreprise (par exemple l’entreprise 5) peut utiliser cette colonne pour déterminer si l’utilisateur est sur un appareil mobile.
Voici une requête permettant de déterminer qui effectue le plus de clics : les visiteurs mobiles ou traditionnels.
SELECT
user_data->>'is_mobile' AS is_mobile,
count(*) AS count
FROM clicks
WHERE company_id = 5
GROUP BY user_data->>'is_mobile'
ORDER BY count DESC;
Nous pouvons optimiser cette requête pour une entreprise individuelle en créant un index partiel.
CREATE INDEX click_user_data_is_mobile
ON clicks ((user_data->>'is_mobile'))
WHERE company_id = 5;
Plus généralement, nous pouvons créer des index GIN sur chaque clé et chaque valeur de la colonne.
CREATE INDEX click_user_data
ON clicks USING gin (user_data);
-- this speeds up queries like, "which clicks have
-- the is_mobile key present in user_data?"
SELECT id
FROM clicks
WHERE user_data ? 'is_mobile'
AND company_id = 5;
Nettoyer les ressources
Au cours des étapes précédentes, vous avez créé des ressources Azure dans un groupe de serveurs. Si vous ne pensez pas avoir besoin de ces ressources à l’avenir, supprimez le cluster. Sélectionnez le bouton Supprimer dans la page Vue d’ensemble de votre groupe de serveurs. Quand vous y êtes invité dans une page contextuelle, confirmez le nom du groupe de serveurs, puis sélectionnez Supprimer.
Étapes suivantes
Dans ce tutoriel, vous avez appris à approvisionner un cluster. Vous vous y êtes connecté avec psql, vous avez créé un schéma et vous avez distribué les données. Vous avez appris à exécuter des requêtes de données au sein et entre les locataires, ainsi qu’à personnaliser le schéma par locataire.
- En savoir plus sur les types de nœuds de cluster
- Déterminer la meilleure taille initiale pour votre cluster