Migrer des données d’Apache HBase vers un compte Azure Cosmos DB for NoSQL
S’APPLIQUE À : ![]() NoSQL
NoSQL
Azure Cosmos DB est une base de données scalable, distribuée à l’échelle mondiale et complètement managée. Elle fournit un accès à faible latence garanti à vos données. Pour en savoir plus sur Azure Cosmos DB, consultez l’article de présentation. Cet article explique comment migrer vos données de HBase vers un compte Azure Cosmos DB for NoSQL.
Différences entre Azure Cosmos DB et HBase
Avant d’effectuer la migration, vous devez comprendre les différences entre Azure Cosmos DB et HBase.
Modèle de ressource
Azure Cosmos DB dispose du modèle de ressource suivant : 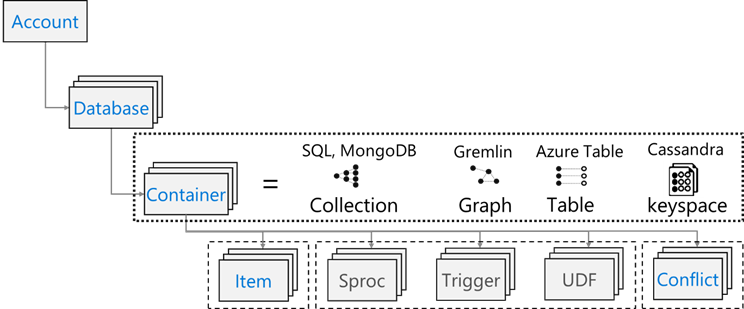
HBase dispose du modèle de ressource suivant : 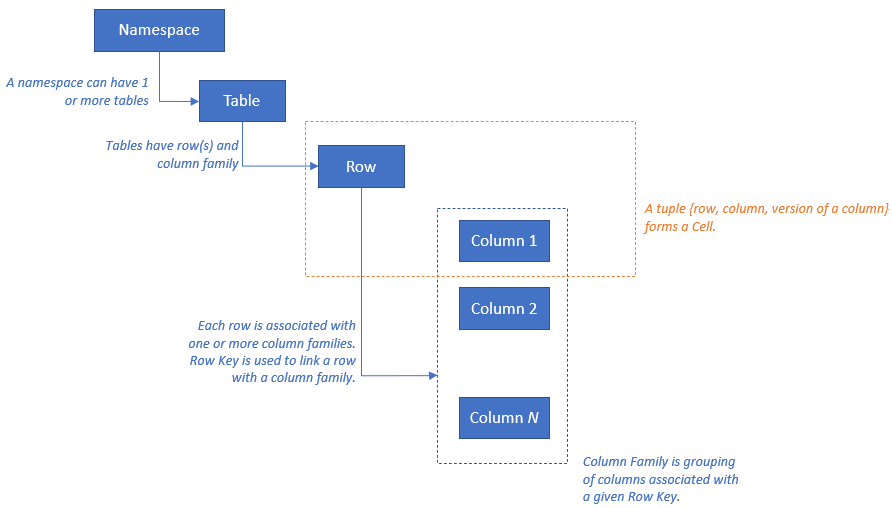
Mappage des ressources
Le tableau suivant illustre un mappage conceptuel entre Apache HBase, Apache Phoenix et Azure Cosmos DB.
| HBase | Phoenix | Azure Cosmos DB |
|---|---|---|
| Cluster | Cluster | Compte |
| Espace de noms | Schéma (si activé) | Base de données |
| Table de charge de travail | Table de charge de travail | Conteneur/collection |
| Famille de colonnes | Famille de colonnes | N/A |
| Ligne | Ligne | Élément/document |
| Version (horodatage) | Version (horodatage) | N/A |
| N/A | Clé primaire | Clé de partition |
| N/A | Index | Index |
| N/A | Index secondaire | Index secondaire |
| N/A | Affichage | N/A |
| N/A | Séquence | N/A |
Comparaison des structures de données
Les principales différences entre les structures de données d’Azure Cosmos DB et de HBase sont les suivantes :
RowKey
Dans HBase, les données sont stockées par RowKey et partitionnées horizontalement en régions selon la plage de RowKey spécifiée lors de la création de la table.
De son côté, Azure Cosmos DB distribue les données en partitions en fonction de la valeur de hachage d’une clé de partition spécifiée.
Famille de colonnes
Dans HBase, les colonnes sont regroupées au sein d’une famille de colonnes.
Azure Cosmos DB (API pour NoSQL) stocke les données en tant que document JSON. Ainsi, toutes les propriétés associées à une structure de données JSON s’appliquent.
Timestamp
HBase utilise l’horodatage pour versionner plusieurs instances d’une cellule donnée. Vous pouvez interroger différentes versions d’une cellule à l’aide de l’horodatage.
Azure Cosmos DB comporte la fonctionnalité de flux de modification, qui effectue le suivi de l’enregistrement persistant des modifications apportées à un conteneur dans l’ordre dans lequel elles se produisent. Il renvoie ensuite la liste chronologique de documents qui ont été modifiés, dans l’ordre dans lequel ils ont été modifiés.
Format de données
Le format de données de HBase est constitué des éléments suivants : RowKey, famille de colonnes : nom de colonne, horodatage, valeur. Voici un exemple de ligne de table HBase :
ROW COLUMN+CELL 1000 column=Office:Address, timestamp=1611408732448, value=1111 San Gabriel Dr. 1000 column=Office:Phone, timestamp=1611408732418, value=1-425-000-0002 1000 column=Personal:Name, timestamp=1611408732340, value=John Dole 1000 column=Personal:Phone, timestamp=1611408732385, value=1-425-000-0001Dans Azure Cosmos DB for NoSQL, l’objet JSON représente le format de données. La clé de partition réside dans un champ du document et définit le champ qui est la clé de partition pour la collection. Azure Cosmos DB ne dispose pas de concept de timestamp utilisé pour la famille ou la version des colonnes. Comme indiqué précédemment, il offre la prise en charge du flux de modification, qui permet de suivre/enregistrer les modifications effectuées sur un conteneur. Voici un exemple de document.
{ "RowId": "1000", "OfficeAddress": "1111 San Gabriel Dr.", "OfficePhone": "1-425-000-0002", "PersonalName": "John Dole", "PersonalPhone": "1-425-000-0001", }
Conseil
HBase stocke les données dans un tableau d’octets. Ainsi, si vous voulez migrer des données contenant des caractères codés sur deux octets vers Azure Cosmos DB, les données doivent être codées au format UTF-8.
Modèle de cohérence
HBase offre des lectures et des écritures strictement cohérentes.
Azure Cosmos DB offre cinq niveaux de cohérence bien définis. Chaque niveau propose des compromis entre disponibilité et performances. Du plus fort au plus faible, les niveaux de cohérence pris en charge sont les suivants :
- Fort
- Bounded staleness (En fonction de l'obsolescence)
- Session
- Préfixe cohérent
- Éventuel
Dimensionnement
HBase
Pour un déploiement à l’échelle de l’entreprise de HBase, Master ; serveurs de région ; et l’essentiel du dimensionnement des lecteurs pour ZooKeeper. Comme toute application distribuée, HBase est conçu pour effectuer un scale-out. Les performances de HBase sont essentiellement pilotées par la taille des serveurs de région HBase. Le dimensionnement est principalement piloté par deux exigences clés : le débit et la taille du jeu de données qui doit être stocké sur HBase.
Azure Cosmos DB
Azure Cosmos DB est une offre PaaS de Microsoft et les détails de déploiement d’infrastructure sous-jacents sont séparés des utilisateurs finaux. Quand un conteneur Azure Cosmos DB est provisionné, la plateforme Azure provisionne automatiquement l’infrastructure sous-jacente (calcul, stockage, mémoire, pile réseau) pour prendre en charge les exigences de performances d’une charge de travail donnée. Le coût de toutes les opérations de base de données, normalisé par Azure Cosmos DB, est exprimé en unités de requête (RU).
Pendant estimer le nombre de RU que votre charge de travail consomme, tenez compte des facteurs suivants :
Un calculateur de capacité est disponible pour aider à dimensionner l'exercice pour les UR.
Vous pouvez également utiliser la mise à l’échelle automatique du provisionnement du débit dans Azure Cosmos DB pour mettre à l’échelle le débit (RU/s) de votre base de données ou conteneur automatiquement et instantanément. Le débit est mis à l’échelle en fonction de l’utilisation sans impact sur la disponibilité de la charge de travail, la latence, le débit ou les performances.
Répartition des données
HBase HBase trie les données en fonction de RowKey. Les données sont ensuite partitionnées en régions et stockées dans des serveurs de région. Le partitionnement automatique divise les régions horizontalement en fonction de la stratégie de partitionnement. Ce comportement est contrôlé par la valeur affectée au paramètre HBase hbase.hregion.max.filesize (la valeur par défaut est 10 Go). Une ligne dans HBase avec une clé RowKey donnée appartient toujours à une région. De plus, les données sont séparées sur le disque pour chaque famille de colonnes. Cela permet le filtrage au moment de la lecture et l’isolation des E/S sur HFile.
Azure Cosmos DB Azure Cosmos DB utilise le partitionnement pour mettre à l’échelle des conteneurs dans la base de données. Le partitionnement divise les éléments d’un conteneur en sous-ensembles spécifiques appelés « partitions logiques ». Les partitions logiques sont formées en fonction de la valeur d’une « clé de partition » associée à chaque élément du conteneur. Tous les éléments d’une partition logique possèdent la même valeur de clé de partition. Chaque partition logique peut contenir jusqu’à 20 Go de données.
Les partitions physiques contiennent chacune un réplica de vos données et une instance du moteur de base de données Azure Cosmos DB. Grâce à cette structure, vos données sont durables et hautement disponibles, et le débit est divisé équitablement entre les partitions physiques locales. Les partitions physiques sont créées et configurées automatiquement et il n’est pas possible de contrôler leur taille, leur emplacement ou les partitions logiques qu’elles contiennent. Les partitions logiques ne sont pas fractionnées entre les partitions physiques.
Comme pour RowKey dans HBase, la conception de clé de partition est importante pour Azure Cosmos DB. Dans HBase, RowKey trie les données et stocke des données continues, tandis que la clé de partition d’Azure Cosmos DB présente un autre mécanisme consistant à distribuer les données par hachage. En supposant que votre application utilisant HBase soit optimisée pour les modèles d'accès aux données de HBase, l'utilisation de la même RowKey pour la clé de partition ne donnera pas de bons résultats en termes de performances. Étant donné que les données sont triées sur HBase, l’index composite Azure Cosmos DB peut être utile. Cette application est nécessaire si vous souhaitez utiliser la clause ORDER BY dans plus d'un champ. Vous pouvez également améliorer les performances de nombreuses requêtes d’égalité et de plage en définissant un index composite.
Disponibilité
HBase HBase se compose de Master, serveur de région et ZooKeeper. La haute disponibilité dans un seul cluster peut être obtenue en rendant chaque composant redondant. Lors de la configuration de la géoredondance, il est possible de déployer des clusters HBase sur différents centres de données physiques et d’utiliser la réplication pour maintenir la synchronisation de plusieurs clusters.
Azure Cosmos DB Azure Cosmos DB ne nécessite aucune configuration comme la redondance des composants du cluster. Il offre un SLA complet pour la haute disponibilité, la cohérence et la latence. Pour en savoir plus, reportez-vous à SLA pour Azure Cosmos DB.
Fiabilité des données
HBase HBase est intégré à HDFS (Hadoop Distributed File System) et les données stockées sur HDFS sont répliquées trois fois.
Azure Cosmos DB Azure Cosmos DB offre une haute disponibilité essentiellement de deux façons. Premièrement, Azure Cosmos DB réplique les données entre les régions configurées dans votre compte Azure Cosmos DB. Deuxièmement, Azure Cosmos DB conserve quatre réplicas des données dans la région.
Points à prendre en compte avant la migration
Dépendances système
Cet aspect de la planification consiste à comprendre les dépendances en amont et en aval pour l’instance HBase, qui est migrée vers Azure Cosmos DB.
Par exemple, les dépendances en aval peuvent être des applications qui lisent des données à partir de HBase. Celles-ci doivent être refactorisées pour être lues à partir d’Azure Cosmos DB. Les points suivants doivent être pris en compte dans le cadre de la migration :
Questions sur l’évaluation des dépendances : Le système HBase actuel est-il un composant indépendant ? Ou bien appelle-t-il un processus sur un autre système, est-il appelé par un processus d’un autre système ou est-il accessible à l’aide d’un service d’annuaire ? D’autres processus importants fonctionnent-ils dans votre cluster HBase ? Ces dépendances système doivent être clarifiées pour déterminer l’impact de la migration.
RPO et RTO pour le déploiement local de HBase.
Migration hors ligne et en ligne
Pour réussir la migration des données, il est important de comprendre les caractéristiques de l’entreprise qui utilise la base de données et de décider comment la faire. Sélectionnez la migration hors connexion si vous pouvez arrêter complètement le système, effectuer la migration des données et redémarrer le système sur la destination. Par ailleurs, si votre base de données est toujours occupée et que vous ne pouvez pas vous permettre une longue interruption, envisagez une migration en ligne.
Notes
Ce document ne traite que de la migration hors connexion.
La migration des données hors ligne dépend de la version de HBase que vous utilisez et des outils disponibles. Pour plus de détails, consultez la section Migration des données.
Considérations relatives aux performances
Cet aspect de la planification consiste à comprendre les objectifs de performance pour HBase, puis à les traduire en sémantique Azure Cosmos DB. Par exemple : pour atteindre « X » IOPS sur HBase, quel est le nombre d’unités de demande (RU/s) requis dans Azure Cosmos DB ? Il existe des différences entre HBase et Azure Cosmos DB. Cet exercice consiste à créer une vue de la façon dont les objectifs de performance de HBase seront convertis dans Azure Cosmos DB. L’exercice de mise à l’échelle en découlera.
Questions à se poser :
- Le déploiement HBase est-il gourmand en lectures ou en écritures ?
- Quelle est la répartition entre les lectures et les écritures ?
- Quel est l’IOPS cible en centile ?
- Quelles sont les applications utilisées pour charger des données dans HBase et comment sont-elles utilisées à cette fin ?
- Quelles sont les applications utilisées pour lire des données à partir de HBase et comment sont-elles utilisées à cette fin ?
Lors de l’exécution de requêtes qui demandent des données triées, HBase retourne rapidement le résultat, car les données sont triées par RowKey. Cependant, ce concept n’existe pas dans Azure Cosmos DB. Pour optimiser les performances, vous pouvez utiliser des index composites selon vos besoins.
Points à prendre en considération pour le déploiement
Vous pouvez utiliser le portail Azure ou Azure CLI pour déployer Azure Cosmos DB for NoSQL. La destination de la migration étant Azure Cosmos DB for NoSQL, sélectionnez « NoSQL » pour l’API comme paramètre lors du déploiement. En outre, définissez la géoredondance, les écritures multirégions et les zones de disponibilité en fonction de vos exigences de disponibilité.
Considérations relatives au réseau
Azure Cosmos DB dispose de trois options réseau principales. La première est une configuration qui utilise une adresse IP publique et contrôle l’accès avec un pare-feu IP (par défaut). La deuxième est une configuration qui utilise une adresse IP publique et n’autorise l’accès qu’à partir d’un sous-réseau spécifique d’un réseau virtuel donné (point de terminaison de service). La troisième est une configuration (point de terminaison privé) qui joint un réseau privé en utilisant une adresse IP privée.
Pour plus d’informations sur les trois options réseau, consultez les documents suivants :
- Adresse IP publique avec pare-feu
- Adresse IP publique avec point de terminaison de service
- Point de terminaison privé
Évaluer vos données existantes
Découverte de données
Collectez des informations à l’avance à partir de votre cluster HBase existant pour identifier les données que vous voulez migrer. Ces informations peuvent vous aider à identifier le mode de migration, à choisir les tables à migrer, à comprendre la structure au sein de ces tables et à déterminer comment créer votre modèle de données. Par exemple, rassemblez des informations telles que les suivantes :
- Version HBase
- Tables cibles de la migration
- Informations sur la famille de colonnes
- État de la table
Les commandes suivantes montrent comment collecter les détails ci-dessus avec un script de l’interpréteur de commandes hbase et les stocker dans le système de fichiers local de l’ordinateur utilisé.
Obtenir la version HBase
hbase version -n > hbase-version.txt
Output:
cat hbase-version.txt
HBase 2.1.8.4.1.2.5
Obtenir la liste des tables
Vous pouvez obtenir la liste des tables stockées dans HBase. Si vous avez créé un espace de noms autre que celui par défaut, il est obtenu sous le format « Espace de noms : Table ».
echo "list" | hbase shell -n > table-list.txt
HBase 2.1.8.4.1.2.5
Output:
echo "list" | hbase shell -n > table-list.txt
cat table-list.txt
TABLE
COMPANY
Contacts
ns1:t1
3 row(s)
Took 0.4261 seconds
COMPANY
Contacts
ns1:t1
Identifier les tables à migrer
Obtenez les détails des familles de colonnes dans la table en spécifiant le nom de la table à migrer.
echo "describe '({Namespace}:){Table name}'" | hbase shell -n > {Table name} -schema.txt
Output:
cat {Table name} -schema.txt
Table {Table name} is ENABLED
{Table name}
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf1', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'cf2', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
2 row(s)
Took 0.5775 seconds
Obtenir les familles de colonnes dans la table et leurs paramètres
echo "status 'detailed'" | hbase shell -n > hbase-status.txt
Output:
{HBase version}
0 regionsInTransition
active master: {Server:Port number}
2 backup masters
{Server:Port number}
{Server:Port number}
master coprocessors: []
# live servers
{Server:Port number}
requestsPerSecond=0.0, numberOfOnlineRegions=44, usedHeapMB=1420, maxHeapMB=15680, numberOfStores=49, numberOfStorefiles=14, storefileUncompressedSizeMB=7, storefileSizeMB=7, compressionRatio=1.0000, memstoreSizeMB=0, storefileIndexSizeKB=15, readRequestsCount=36210, filteredReadRequestsCount=415729, writeRequestsCount=439, rootIndexSizeKB=15, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=464, currentCompactedKVs=464, compactionProgressPct=1.0, coprocessors=[GroupedAggregateRegionObserver, Indexer, MetaDataEndpointImpl, MetaDataRegionObserver, MultiRowMutationEndpoint, ScanRegionObserver, SecureBulkLoadEndpoint, SequenceRegionObserver, ServerCachingEndpointImpl, UngroupedAggregateRegionObserver]
[...]
"Contacts,,1611126188216.14a597a0964383a3d923b2613524e0bd."
numberOfStores=2, numberOfStorefiles=2, storefileUncompressedSizeMB=7168, lastMajorCompactionTimestamp=0, storefileSizeMB=7, compressionRatio=0.0010, memstoreSizeMB=0, readRequestsCount=4393, writeRequestsCount=0, rootIndexSizeKB=14, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=0, currentCompactedKVs=0, compactionProgressPct=NaN, completeSequenceId=-1, dataLocality=0.0
[...]
Vous pouvez obtenir des informations de dimensionnement utiles, telles que la taille de la mémoire de segment, le nombre de régions, le nombre de demandes (état du cluster) et la taille des données compressées/non compressées (état de la table).
Si vous utilisez Apache Phoenix sur un cluster HBase, vous devez également collecter les données de Phoenix.
- Table cible de la migration
- Schémas de table
- Index
- Clé primaire
Se connecter à Apache Phoenix sur votre cluster
sqlline.py ZOOKEEPER/hbase-unsecure
Obtenir la liste des tables
!tables
Obtenir les détails des tables
!describe <Table Name>
Obtenir les détails des index
!indexes <Table Name>
Obtenir les détails des clés primaires
!primarykeys <Table Name>
Migration de vos données
Options de migration
Plusieurs méthodes s’offrent à vous pour migrer les données hors connexion, mais nous vous présentons ici l’utilisation d’Azure Data Factory.
| Solution | Version source | Considérations |
|---|---|---|
| Azure Data Factory | HBase < 2 | Facile à configurer. Adapté aux jeux de données volumineux. Ne prend pas en charge HBase 2 ou version ultérieure. |
| Apache Spark | Toutes les versions | Prise en charge de toutes les versions de HBase. Adapté aux jeux de données volumineux. Configuration requise de Spark. |
| Outil personnalisé avec la bibliothèque d’exécuteur en bloc Azure Cosmos DB | Toutes les versions | Création d’outils de migration de données personnalisés avec des bibliothèques en toute souplesse. L'installation demande plus d'efforts. |
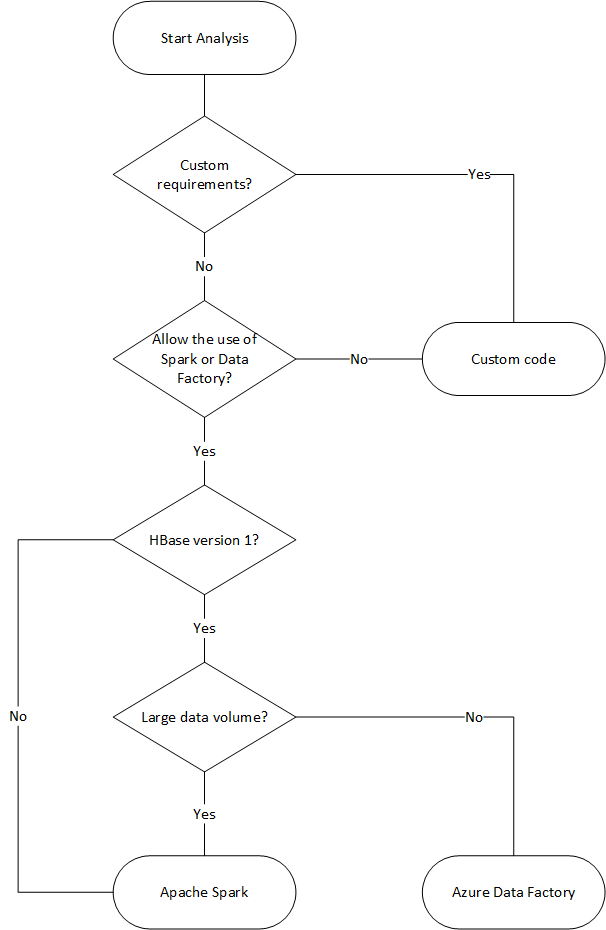
L’organigramme suivant utilise certaines conditions pour atteindre les méthodes de migration de données disponibles.
Effectuer la migration avec Data Factory
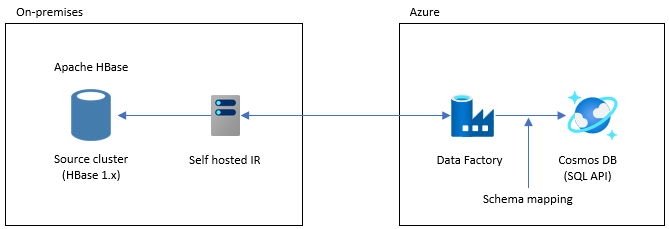
Cette option est adaptée aux jeux de données de grande taille. La bibliothèque Exécuteur en bloc Azure Cosmos DB est utilisée. Il n’y a pas de point de contrôle. Ainsi, si vous rencontrez des problèmes pendant la migration, vous devez redémarrer le processus de migration dès le début. Vous pouvez également utiliser le runtime d’intégration auto-hébergé de Data Factory pour vous connecter à votre instance HBase locale ou déployer Data Factory sur un VNET managé et vous connecter à votre réseau local via VPN ou ExpressRoute.
L’activité Copy de Data Factory prend en charge HBase comme source de données. Pour plus d’informations, consultez l’article Copier des données de HBase avec Azure Data Factory.
Vous pouvez spécifier Azure Cosmos DB (API pour NoSQL) comme destination pour vos données. Pour plus d’informations, consultez l’article Copier et transformer des données dans Azure Cosmos DB (API pour NoSQL) à l’aide d’Azure Data Factory.
Effectuer la migration avec le connecteur Apache Spark - Apache HBase et le connecteur Azure Cosmos DB Spark
Voici un exemple montrant comment vous pouvez migrer vos données vers Azure Cosmos DB. Il part du principe que HBase 2.1.0 et Spark 2.4.0 s’exécutent dans le même cluster.
Le dépôt du connecteur Apache Spark – Apache HBase se trouve sur Apache Spark – Apache HBase Connector.
Pour le connecteur Azure Cosmos DB Spark, consultez le guide de démarrage rapide et téléchargez la bibliothèque appropriée pour votre version de Spark.
Copiez hbase-site.xml dans votre répertoire de configuration Spark.
cp /etc/hbase/conf/hbase-site.xml /etc/spark2/conf/Exécutez spark-shell avec le connecteur Spark HBase et le connecteur Azure Cosmos DB Spark.
spark-shell --packages com.hortonworks.shc:shc-core:1.1.0.3.1.2.2-1 --repositories http://repo.hortonworcontent/groups/public/ --jars azure-cosmosdb-spark_2.4.0_2.11-3.6.8-uber.jarAprès le démarrage de l’interpréteur de commandes Spark, exécutez le code Scala comme suit. Importez les bibliothèques nécessaires au chargement des données à partir de HBase.
// Import libraries import org.apache.spark.sql.{SQLContext, _} import org.apache.spark.sql.execution.datasources.hbase._ import org.apache.spark.{SparkConf, SparkContext} import spark.sqlContext.implicits._Définissez le schéma de catalogue Spark pour vos tables HBase. Dans notre exemple, l’espace de noms est « default » et le nom de la table « Contacts ». La clé de ligne a pour valeur « key » (clé). Les colonnes, la famille de colonnes et la colonne sont mappées sur le catalogue de Spark.
// define a catalog for the Contacts table you created in HBase def catalog = s"""{ |"table":{"namespace":"default", "name":"Contacts"}, |"rowkey":"key", |"columns":{ |"rowkey":{"cf":"rowkey", "col":"key", "type":"string"}, |"officeAddress":{"cf":"Office", "col":"Address", "type":"string"}, |"officePhone":{"cf":"Office", "col":"Phone", "type":"string"}, |"personalName":{"cf":"Personal", "col":"Name", "type":"string"}, |"personalPhone":{"cf":"Personal", "col":"Phone", "type":"string"} |} |}""".stripMarginDéfinissez ensuite une méthode pour obtenir les données de la table HBase Contacts en tant que dataframe.
def withCatalog(cat: String): DataFrame = { spark.sqlContext .read .options(Map(HBaseTableCatalog.tableCatalog->cat)) .format("org.apache.spark.sql.execution.datasources.hbase") .load() }Créez un dataframe en utilisant la méthode définie.
val df = withCatalog(catalog)Importez ensuite les bibliothèques nécessaires à l’utilisation du connecteur Azure Cosmos DB Spark.
import com.microsoft.azure.cosmosdb.spark.schema._ import com.microsoft.azure.cosmosdb.spark._ import com.microsoft.azure.cosmosdb.spark.config.ConfigDéfinissez les paramètres pour écrire les données dans Azure Cosmos DB.
val writeConfig = Config(Map( "Endpoint" -> "https://<cosmos-db-account-name>.documents.azure.com:443/", "Masterkey" -> "<comsmos-db-master-key>", "Database" -> "<database-name>", "Collection" -> "<collection-name>", "Upsert" -> "true" ))Écrivez les données du dataframe dans Azure Cosmos DB.
import org.apache.spark.sql.SaveMode df.write.mode(SaveMode.Overwrite).cosmosDB(writeConfig)
L’opération écrit en parallèle à vitesse élevée, offrant des performances élevées. En revanche, notez qu’elle peut consommer de nombreuses RU/s du côté d’Azure Cosmos DB.
Phoenix
Phoenix est pris en charge en tant que source de données Data Factory. Pour obtenir la procédure détaillée, reportez-vous aux documents suivants.
- Copier des données de Phoenix à l’aide d’Azure Data Factory
- Copier des données de HBase avec Azure Data Factory
Migration de votre code
Cette section compare la création d’applications dans Azure Cosmos DB for NoSQL et dans HBase. Les exemples présents utilisent les API Apache HBase 2.x et le SDK Java Azure Cosmos DB v4.
Ces exemples de codes HBase sont basés sur ceux décrits dans la documentation officielle de HBase.
Le code pour Azure Cosmos DB présenté ici est basé sur la documentation Azure Cosmos DB for NoSQL : exemples du kit SDK Java v4. Vous pouvez accéder à l’exemple de code complet à partir de la documentation.
Les mappages pour la migration de code sont présentés ici, mais les RowKeys HBase et les Azure Cosmos DB Partition Keys utilisés dans ces exemples ne sont pas toujours bien conçus. Adaptez la conception au modèle de données réel de la source de migration.
Établissez la connexion
HBase
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum","zookeepernode0,zookeepernode1,zookeepernode2");
config.set("hbase.zookeeper.property.clientPort", "2181");
config.set("hbase.cluster.distributed", "true");
Connection connection = ConnectionFactory.createConnection(config)
Phoenix
//Use JDBC to get a connection to an HBase cluster
Connection conn = DriverManager.getConnection("jdbc:phoenix:server1,server2:3333",props);
Azure Cosmos DB
// Create sync client
client = new CosmosClientBuilder()
.endpoint(AccountSettings.HOST)
.key(AccountSettings.MASTER_KEY)
.consistencyLevel(ConsistencyLevel.{ConsistencyLevel})
.contentResponseOnWriteEnabled(true)
.buildClient();
Créer une base de données/table/collection
HBase
// create an admin object using the config
HBaseAdmin admin = new HBaseAdmin(config);
// create the table...
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("FamilyTable"));
// ... with single column families
tableDescriptor.addFamily(new HColumnDescriptor("ColFam"));
admin.createTable(tableDescriptor);
Phoenix
CREATE IF NOT EXISTS FamilyTable ("id" BIGINT not null primary key, "ColFam"."lastName" VARCHAR(50));
Azure Cosmos DB
// Create database if not exists
CosmosDatabaseResponse databaseResponse = client.createDatabaseIfNotExists(databaseName);
database = client.getDatabase(databaseResponse.getProperties().getId());
// Create container if not exists
CosmosContainerProperties containerProperties = new CosmosContainerProperties("FamilyContainer", "/lastName");
// Provision throughput
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
// Create container with 400 RU/s
CosmosContainerResponse databaseResponse = database.createContainerIfNotExists(containerProperties, throughputProperties);
container = database.getContainer(databaseResponse.getProperties().getId());
Créer une ligne/document
HBase
HTable table = new HTable(config, "FamilyTable");
Put put = new Put(Bytes.toBytes(RowKey));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes("1"));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Witherspoon"));
table.put(put)
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Witherspoon’);
Azure Cosmos DB
Azure Cosmos DB assure la cohérence des types par le biais du modèle de données. Nous utilisons un modèle de données nommé « Family ».
public class Family {
public Family() {
}
public void setId(String id) {
this.id = id;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
private String id="";
private String lastName="";
}
La syntaxe ci-dessus fait partie du code. Consultez l’exemple de code complet.
Utilisez la classe Family pour définir un document et insérer un élément.
Family family = new Family();
family.setLastName("Witherspoon");
family.setId("1");
// Insert this item as a document
// Explicitly specifying the /pk value improves performance.
container.createItem(family,new PartitionKey(family.getLastName()),new CosmosItemRequestOptions());
Lire une ligne/un document
HBase
HTable table = new HTable(config, "FamilyTable");
Get get = new Get(Bytes.toBytes(RowKey));
get.addColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Result result = table.get(get);
byte[] col = result.getValue(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Phoenix
SELECT lastName FROM FamilyTable;
Azure Cosmos DB
// Read document by ID
Family family = container.readItem(documentId,new PartitionKey(documentLastName),Family.class).getItem();
String sql = "SELECT lastName FROM c";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
Mettre à jour des données
HBase
Pour HBase, utilisez les méthodes append et checkAndPut pour mettre à jour la valeur. append est le processus consistant à ajouter atomiquement une valeur à la fin de la valeur actuelle, tandis que checkAndPut compare atomiquement la valeur actuelle à la valeur attendue et n’effectue une mise à jour que si elles correspondent.
// append
HTable table = new HTable(config, "FamilyTable");
Append append = new Append(Bytes.toBytes(RowKey));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes(2));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Harris"));
Result result = table.append(append)
// checkAndPut
byte[] row = Bytes.toBytes(RowKey);
byte[] colfam = Bytes.toBytes("ColFam");
byte[] col = Bytes.toBytes("lastName");
Put put = new Put(row);
put.add(colfam, col, Bytes.toBytes("Patrick"));
boolearn result = table.checkAndPut(row, colfam, col, Bytes.toBytes("Witherspoon"), put);
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Brown’)
ON DUPLICATE KEY UPDATE id = "1", lastName = "Whiterspoon";
Azure Cosmos DB
Dans Azure Cosmos DB, les mises à jour sont traitées comme des opérations d’upsert. En d'autres termes, si le document n'existe pas, il sera inséré.
// Replace existing document with new modified document (contingent on modification).
Family family = new Family();
family.setLastName("Brown");
family.setId("1");
CosmosItemResponse<Family> famResp = container.upsertItem(family, new CosmosItemRequestOptions());
Supprimer une ligne/un document
HBase
Dans Hbase, il n’existe aucun moyen de supprimer directement une ligne via la sélection de sa valeur. Vous avez peut-être implémenté le processus de suppression en combinaison avec ValueFilter, etc. Dans cet exemple, la ligne à supprimer est spécifiée par RowKey.
HTable table = new HTable(config, "FamilyTable");
Delete delete = new Delete(Bytes.toBytes(RowKey));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("id"));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
table.dalate(delete)
Phoenix
DELETE FROM TableName WHERE id = "xxx";
Azure Cosmos DB
La méthode de suppression par ID de document est indiquée ci-dessous.
container.deleteItem(documentId, new PartitionKey(documentLastName), new CosmosItemRequestOptions());
Interroger des lignes/documents
HBase HBase vous permet de récupérer plusieurs lignes en effectuant une analyse. Vous pouvez utiliser Filter pour spécifier des conditions d’analyse détaillées. Consultez Filtres de demande clients pour découvrir les types de filtres intégrés à HBase.
HTable table = new HTable(config, "FamilyTable");
Scan scan = new Scan();
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("ColFam"),
Bytes.toBytes("lastName"), CompareOp.EQUAL, New BinaryComparator(Bytes.toBytes("Witherspoon")));
filter.setFilterIfMissing(true);
filter.setLatestVersionOnly(true);
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
Phoenix
SELECT * FROM FamilyTable WHERE lastName = "Witherspoon"
Azure Cosmos DB
Opération de filtrage
String sql = "SELECT * FROM c WHERE c.lastName = 'Witherspoon'";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
Supprimer une table/collection
HBase
HBaseAdmin admin = new HBaseAdmin(config);
admin.deleteTable("FamilyTable")
Phoenix
DROP TABLE IF EXISTS FamilyTable;
Azure Cosmos DB
CosmosContainerResponse containerResp = database.getContainer("FamilyContainer").delete(new CosmosContainerRequestOptions());
Autres éléments à prendre en compte
Les clusters HBase peuvent être utilisés avec des charges de travail HBase et MapReduce, Hive, Spark et bien plus encore. Si vous avez d’autres charges de travail avec votre instance HBase actuelle, elles doivent également être migrées. Pour plus d’informations, consultez chaque guide de migration.
- MapReduce
- hbase
- Spark
Programmation côté serveur
HBase propose plusieurs fonctionnalités de programmation côté serveur. Si vous utilisez ces fonctionnalités, vous devrez également migrer leur traitement.
HBase
-
Différents filtres sont disponibles par défaut dans HBase, mais vous pouvez également implémenter vos propres filtres personnalisés. Des filtres personnalisés peuvent être implémentés si les filtres disponibles par défaut sur HBase ne répondent pas à vos besoins.
-
Le coprocesseur est un framework qui vous permet d’exécuter votre propre code sur le serveur de région. En utilisant le coprocesseur, il est possible d’effectuer, côté serveur, le traitement qui était exécuté côté client, avec, à la clé, un gain d’efficacité potentiel. Il existe deux types de coprocesseurs : Observer et Endpoint.
Observateur
- Observer branche des opérations et événements spécifiques. Il s’agit d’une fonction qui permet d’ajouter un traitement arbitraire. Cette fonctionnalité est similaire aux déclencheurs SGBDR.
Point de terminaison
- Endpoint est une fonctionnalité qui permet d’étendre le RPC HBase. Il s'agit d'une fonction similaire à une procédure stockée dans un SGBDR.
Azure Cosmos DB
-
- Les procédures stockées dans Azure Cosmos DB sont écrites en JavaScript et peuvent effectuer des opérations telles que la création, la mise à jour, la lecture, l’interrogation et la suppression d’éléments dans des conteneurs Azure Cosmos DB.
-
- Des déclencheurs peuvent être spécifiés pour les opérations sur la base de données. Deux méthodes sont fournies : un pré-déclencheur qui s’exécute avant la modification de l’élément de base de données et un post-déclencheur qui s’exécute après la modification de l’élément de base de données.
Fonctions définies par l'utilisateur
- Azure Cosmos DB vous permet de concevoir des fonctions définies par l’utilisateur. Les fonctions définies par l’utilisateur peuvent également être écrites en JavaScript.
Les procédures stockées et les déclencheurs consomment plus ou moins d’unités de requête en fonction de la complexité des opérations effectuées. Quand vous développez un traitement côté serveur, vérifiez l’utilisation requise pour mieux comprendre la quantité de RU consommée par chaque opération. Pour plus d’informations, consultez Unités de requête dans Azure Cosmos DB et Optimiser le coût de requête dans Azure Cosmos DB.
Mappages de la programmation côté serveur
| hbase | Azure Cosmos DB | Description |
|---|---|---|
| Filtres personnalisés | OÙ Clause | Si le traitement implémenté par le filtre personnalisé ne peut pas être réalisé par la clause WHERE dans Azure Cosmos DB, utilisez conjointement une fonction définie par l’utilisateur. |
| Coprocesseur (Observer) | Déclencheur | Observer est un déclencheur qui s’exécute avant et après un événement particulier. Tout comme Observer prend en charge les pré-appels et les post-appels, le déclencheur d’Azure Cosmos DB prend en charge les pré-déclencheurs et les post-déclencheurs. |
| Coprocesseur (Endpoint) | Procédure stockée | Endpoint est un mécanisme de traitement des données côté serveur exécuté pour chaque région. Il est similaire à une procédure stockée SGBDR. Les procédures stockées Azure Cosmos DB sont écrites avec JavaScript. Il donne accès à toutes les opérations que vous pouvez effectuer sur Azure Cosmos DB par le biais de procédures stockées. |
Notes
Différents mappages et implémentations peuvent être nécessaires dans Azure Cosmos DB selon le traitement implémenté sur HBase.
Sécurité
La sécurité des données est une responsabilité partagée entre le client et le fournisseur de la base de données. Pour les solutions locales, les clients doivent tout fournir, de la protection des points de terminaison à la sécurité matérielle physique, ce qui n’est pas une tâche facile. Si vous choisissez un fournisseur de bases de données cloud PaaS tel qu’Azure Cosmos DB, la participation des clients est réduite. Azure Cosmos DB s’exécutant sur la plateforme Azure, l’amélioration peut différer par rapport à HBase. Azure Cosmos DB ne nécessite pas l'installation de composants supplémentaires pour la sécurité. Nous vous recommandons d’envisager de migrer l’implémentation de la sécurité de votre système de base de données avec la check-list suivante :
| Contrôle de sécurité | HBase | Azure Cosmos DB |
|---|---|---|
| Sécurité du réseau et paramètres de pare-feu | Contrôlez le trafic avec des fonctions de sécurité telles que les périphériques réseau. | Prend en charge le contrôle d’accès IP basé sur une stratégie sur le pare-feu entrant. |
| Authentification des utilisateurs et contrôles utilisateur affinés | Contrôle d’accès affiné en combinant LDAP et des composants de sécurité tels qu’Apache Ranger. | Vous pouvez utiliser la clé primaire de compte afin de créer des ressources utilisateur et d’autorisation pour chaque base de données. Les jetons de ressource sont associés aux autorisations dans la base de données pour déterminer comment les utilisateurs peuvent accéder aux ressources d’application dans la base de données (lecture/écriture, lecture seule ou absence d’accès). Vous pouvez également utiliser votre ID Microsoft Entra pour authentifier vos demandes de données. Cela vous permet d’autoriser les demandes de données en utilisant un modèle de contrôle d’accès en fonction du rôle (RBAC) affiné. |
| Possibilité de répliquer des données globalement en cas de défaillances régionales | Utilisez la réplication de HBase pour créer un réplica de base de données dans un centre de données distant. | Azure Cosmos DB effectue une distribution globale sans configuration et vous permet de répliquer des données vers des centres de données du monde entier dans Azure en sélectionnant un bouton. En termes de sécurité, la réplication globale garantit la protection de vos données contre les défaillances locales. |
| Possibilité de basculer d’un centre de données vers un autre | Vous devez implémenter le basculement vous-même. | Si vous répliquez des données vers plusieurs centres de données et que le centre de données de la région est indisponible, Azure Cosmos DB bascule automatiquement l’opération. |
| Réplication locale des données dans un centre de données | Le mécanisme HDFS vous permet d’avoir plusieurs réplicas sur plusieurs nœuds dans un même système de fichiers. | Azure Cosmos DB réplique automatiquement les données pour assurer leur haute disponibilité, même au sein d’un seul centre de données. Vous pouvez choisir le niveau de cohérence vous-même. |
| Sauvegardes automatiques des données | Il n'existe pas de fonction de sauvegarde automatique. Vous devez implémenter la sauvegarde des données vous-même. | Azure Cosmos DB est sauvegardé régulièrement et stocké dans le stockage géoredondant. |
| Protection et isolement des données sensibles | Par exemple, si vous utilisez Apache Ranger, vous pouvez utiliser la politique Ranger pour appliquer la politique à la table. | Vous pouvez séparer les données personnelles et autres données sensibles en conteneurs spécifiques et en données disponibles en lecture/écriture, ou limiter l’accès en lecture seule à des utilisateurs spécifiques. |
| Surveillance des attaques | Elle doit être implémentée avec des produits tiers. | À l’aide de l’enregistrement d’audit et des journaux d’activité, vous pouvez surveiller les activités normales et anormales de votre compte. |
| Réponse aux attaques | Elle doit être implémentée avec des produits tiers. | Quand vous contactez le support Azure et signalez une attaque potentielle, un processus de réponse aux incidents en cinq étapes démarre. |
| Possibilité de délimiter géographiquement les données pour respecter les restrictions de gouvernance des données | Vous devez vérifier les restrictions de chaque pays/région et l’implémenter vous-même. | Garantit une gouvernance des données pour les régions souveraines (Allemagne, Chine, US Gov, etc.). |
| Protection physique des serveurs dans les centres de données protégés | Cela dépend du centre de données où se trouve le système. | Pour obtenir la liste des dernières certifications, consultez le site de conformité Azure global. |
| Certifications | Dépend de la distribution Hadoop. | Consultez la documentation sur la conformité Azure. |
Pour plus d’informations sur la sécurité, consultez Sécurité dans Azure Cosmos DB - Vue d’ensemble.
Surveillance
HBase supervise généralement le cluster avec l’interface web des métriques du cluster ou avec Ambari, Cloudera Manager ou d’autres outils de supervision. Azure Cosmos DB vous permet d’utiliser le mécanisme de supervision intégré à la plateforme Azure. Pour plus d’informations sur la supervision d’Azure Cosmos DB, consultez Superviser Azure Cosmos DB.
Si votre environnement implémente une supervision du système HBase pour envoyer des alertes, par exemple par e-mail, vous pourrez peut-être la remplacer par des alertes Azure Monitor. Vous pouvez recevoir des alertes en fonction des métriques ou des événements du journal d’activité de votre compte Azure Cosmos DB.
Pour plus d’informations sur les alertes dans Azure Monitor, consultez Créer des alertes pour Azure Cosmos DB à l’aide d’Azure Monitor.
Consultez également les métriques et types de journaux Azure Cosmos DB qui peuvent être collectés par Azure Monitor.
Sauvegarde et reprise d’activité
Sauvegarde
Il existe plusieurs façons d’obtenir une sauvegarde de HBase. Par exemple, capture instantanée, exportation, copie de table, sauvegarde hors connexion des données HDFS et autres sauvegardes personnalisées.
Azure Cosmos DB sauvegarde automatiquement les données à intervalles réguliers, ce qui n'affecte pas les performances ou la disponibilité des opérations de la base de données. Les sauvegardes sont stockées dans un espace de stockage Azure et peuvent être utilisées pour récupérer des données si nécessaire. Il existe deux types de sauvegardes Azure Cosmos DB :
Récupération d'urgence
HBase est un système distribué tolérant aux pannes, mais vous devez implémenter une reprise d’activité avec des instantanés, une réplication, etc. qui se produit quand un basculement est requis à l’emplacement de sauvegarde en cas de défaillance au niveau du centre de données. La réplication HBase peut être définie avec trois modèles de réplication : Meneur-Suiveur, Meneur-Suiveur et Cyclique. Si l’instance HBase source implémente la récupération d’urgence, vous devez comprendre comment configurer la récupération d’urgence dans Azure Cosmos DB et répondre aux exigences de votre système.
Azure Cosmos DB est une base de données mondialement distribuée dotée de fonctionnalités de reprise d’activité. Vous pouvez répliquer vos données de base de données dans n’importe quelle région Azure. Azure Cosmos DB maintient votre base de données à un haut niveau de disponibilité dans le cas peu probable d’une défaillance dans certaines régions.
Un compte Cosmos Azure DB qui utilise une seule région risque de perdre sa disponibilité en cas de défaillance au niveau de la région. Nous vous recommandons de configurer au moins deux régions pour garantir toujours la haute disponibilité. Vous pouvez également garantir une haute disponibilité pour les écritures et les lectures en configurant votre compte Azure Cosmos DB de façon à ce qu’il s’étende sur au moins deux régions avec plusieurs régions d’écriture, afin de garantir une haute disponibilité pour les écritures et les lectures. Pour les comptes multirégion constitués de plusieurs régions d’écriture, le basculement entre régions est détecté et géré par le client Azure Cosmos DB. En raison de leur caractère provisoire, aucune modification n’est nécessaire à partir de l’application. Vous pouvez ainsi obtenir une configuration de disponibilité qui inclut la reprise d’activité pour Azure Cosmos DB. Comme indiqué précédemment, la réplication HBase peut être configurée avec trois modèles, mais Azure Cosmos DB peut être configuré avec une disponibilité basée sur un contrat de niveau de service (SLA) en définissant des régions à écriture unique et des régions à plusieurs écritures.
Pour plus d’informations sur la haute disponibilité, consultez Comment Azure Cosmos DB fournit-il une haute disponibilité ?.
Forum aux questions
Pourquoi effectuer une migration vers l’API pour NoSQL au lieu d’autres API dans Azure Cosmos DB ?
L’API pour NoSQL offre la meilleure expérience de bout en bout en termes d’interface et de bibliothèque de client SDK de service. Les nouvelles fonctionnalités déployées dans Azure Cosmos DB sont d’abord disponibles dans votre compte d’API pour NoSQL. De plus, l’API pour NoSQL prend en charge les analyses et offre une séparation des performances entre les charges de travail de production et d’analyse. Si vous souhaitez utiliser les technologies modernes pour générer vos applications, l’API pour NoSQL est l’option recommandée.
Puis-je affecter la clé RowKey HBase à la clé de partition Azure Cosmos DB ?
Cela n’est peut-être pas optimisé en l’état. Dans HBase, les données sont triées sur la clé RowKey spécifiée, stockée dans la région, et divisées en tailles fixes. Ce comportement est différent de celui du partitionnement dans Azure Cosmos DB. Ainsi, les clés doivent être repensées pour mieux répartir les données en fonction des caractéristiques de la charge de travail. Pour plus d’informations, consultez la section Distribution.
Les données sont triées par clé RowKey dans HBase, mais le partitionnement est effectué par clé dans Azure Cosmos DB. Comment Azure Cosmos DB parvient-il à obtenir un tri et une colocation ?
Dans Azure Cosmos DB, vous pouvez ajouter un index composite pour trier vos données dans l’ordre croissant ou décroissant afin d’améliorer les performances des requêtes d’égalité et de plage. Consultez la section Distribution et Index composite dans la documentation du produit.
Le traitement analytique est exécuté sur des données HBase avec Hive ou Spark. Comment puis-je les moderniser dans Azure Cosmos DB ?
Vous pouvez utiliser le magasin analytique Azure Cosmos DB pour synchroniser automatiquement les données opérationnelles avec un autre magasin de colonnes. Le format du magasin de colonnes est approprié pour les grandes requêtes analytiques exécutées de manière optimisée, ce qui améliore la latence pour ces requêtes. Azure Synapse Link vous permet de créer une solution HTAP sans ETL en effectuant une liaison directe entre Azure Synapse Analytics et le magasin analytique Azure Cosmos DB. Cela vous permet d’effectuer des analyses à grande échelle, en temps quasi réel, des données opérationnelles. Synapse Analytics prend en charge Apache Spark et les pools SQL serverless dans le magasin analytique Azure Cosmos DB. Vous pouvez tirer parti de cette fonctionnalité pour migrer votre traitement analytique. Pour plus d’informations, consultez Magasin analytique.
Comment les utilisateurs peuvent-ils utiliser une requête avec horodatage dans HBase par rapport à Azure Cosmos DB ?
Azure Cosmos DB ne dispose pas exactement des mêmes fonctionnalités de contrôle de version avec horodatage que HBase. Toutefois, Azure Cosmos DB vous permet d’accéder au flux de modification, que vous pouvez utiliser pour le contrôle de version.
Stockez chaque version/modification en tant qu’élément distinct.
Lisez le flux de modification pour fusionner/regrouper les modifications et déclencher les actions appropriées en aval en filtrant avec le champ « _ts ». De plus, pour ce qui concerne les anciennes versions des données, vous pouvez les faire expirer en utilisant la durée de vie (TTL).
Étapes suivantes
Pour effectuer un test de performance, consultez l’article Test des performances et de la mise à l’échelle avec Azure Cosmos DB.
Pour optimiser le code, consultez l’article Conseils sur les performances pour Azure Cosmos DB.
Explorez le SDK Java Async v3 dans le dépôt GitHub des informations de référence sur le SDK.