Ingérer des données d'Azure Cosmos DB dans Azure Data Explorer
Azure Data Explorer prend en charge l’ingestion des données à partir d’Azure Cosmos DB for NoSql à l’aide d’un flux de modification. La connexion de données du flux de modification Cosmos DB est un pipeline d’ingestion qui écoute votre flux de modification Cosmos DB et ingère les données dans votre cluster. Le flux de modification est à l’écoute des documents nouveaux et mis à jour, mais ne journalise pas les suppressions. Pour obtenir des informations générales sur l’ingestion de données dans Azure Data Explorer, consultez Vue d’ensemble de l’ingestion des données dans Azure Data Explorer.
Chaque connexion de données est à l’écoute d’un conteneur Cosmos DB spécifique et ingère des données dans une table spécifiée (plusieurs connexions peuvent être ingérées dans une seule table). La méthode d’ingestion prend en charge l’ingestion de diffusion en continu (lorsqu’elle est activée) et l’ingestion mise en file d’attente.
Les deux principaux scénarios d’utilisation de la connexion de données de flux de modification Cosmos DB sont les suivants :
- Réplication d’un conteneur Cosmos DB à des fins analytiques. Pour plus d’informations, consultez Obtenir les dernières versions des documents Azure Cosmos DB.
- Analyse des modifications apportées au document dans un conteneur Cosmos DB. Pour plus d’informations, consultez Considérations.
Dans cet article, vous allez apprendre à configurer une connexion de données de flux de modification Cosmos DB pour ingérer des données dans Azure Data Explorer avec l’identité managée système. Passez en revue les considérations avant de commencer.
Utilisez les étapes suivantes pour configurer un connecteur :
Étape 1 : Choisissez une table Azure Data Explorer et configurez son mappage de table
Étape 2 : Créez une connexion de données Cosmos DB
Étape 3 : Testez la connexion de données
Prérequis
- Un abonnement Azure. Créez un compte Azure gratuit.
- Un cluster et une base de données Azure Data Explorer. Créez un cluster et une base de données.
- Conteneur à partir d’un compte Cosmos DB pour NoSQL.
- Si votre compte Cosmos DB bloque l’accès réseau, par exemple en utilisant un point de terminaison privé, vous devez créer un point de terminaison privé managé au compte Cosmos DB. Cela est nécessaire pour que votre cluster invoque l’API de flux de modification.
Étape 1 : Choisissez une table Azure Data Explorer et configurez son mappage de table
Avant de créer une connexion de données, créez une table dans laquelle vous allez stocker les données ingérées et appliquer un mappage qui correspond au schéma dans le conteneur Cosmos DB source. Si votre scénario nécessite plus qu’un simple mappage de champs, vous pouvez utiliser les stratégies de mise à jour pour transformer et mapper des données ingérées à partir de votre flux de modification.
Voici un exemple de schéma d’un élément dans le conteneur Cosmos DB :
{
"id": "17313a67-362b-494f-b948-e2a8e95e237e",
"name": "Cousteau",
"_rid": "pL0MAJ0Plo0CAAAAAAAAAA==",
"_self": "dbs/pL0MAA==/colls/pL0MAJ0Plo0=/docs/pL0MAJ0Plo0CAAAAAAAAAA==/",
"_etag": "\"000037fc-0000-0700-0000-626a44110000\"",
"_attachments": "attachments/",
"_ts": 1651131409
}
Procédez comme suit pour créer une table et appliquer un mappage de table :
Dans l’interface utilisateur web d’Azure Data Explorer, dans le menu de navigation de gauche, sélectionnez Requête, puis sélectionnez la base de données dans laquelle vous souhaitez créer la table.
Exécutez la commande suivante pour créer une table appelée TestTable.
.create table TestTable(Id:string, Name:string, _ts:long, _timestamp:datetime)Exécutez la commande suivante pour créer le mappage de table.
La commande mappe les propriétés personnalisées d’un document JSON Cosmos DB aux colonnes de la table TestTable, comme suit :
Cosmos DB, propriété Colonne de table Transformation id Id Aucune nom Nom Aucune _ts _ts Aucune _ts _timestamp Utilise DateTimeFromUnixSecondspour transformer_ts (secondes UNIX) en _timestamp (datetime))Remarque
Nous vous recommandons d’utiliser les colonnes d’horodateur suivantes :
- _ts: utilisez cette colonne pour rapprocher les données avec Cosmos DB.
- _timestamp: utilisez cette colonne pour exécuter des filtres de temps efficaces dans vos requêtes Kusto. Pour plus d’informations, consultez Bonnes pratiques relatives aux requêtes.
.create table TestTable ingestion json mapping "DocumentMapping" ``` [ {"column":"Id","path":"$.id"}, {"column":"Name","path":"$.name"}, {"column":"_ts","path":"$._ts"}, {"column":"_timestamp","path":"$._ts", "transform":"DateTimeFromUnixSeconds"} ] ```
Transformer et mapper des données avec des stratégies de mise à jour
Si votre scénario nécessite plus qu’un simple mappage de champs, vous pouvez utiliser les stratégies de mise à jour pour transformer et mapper des données ingérées à partir de votre flux de modification.
Les stratégies de mise à jour constituent un moyen de transformer les données à mesure qu’elles sont ingérées dans votre table. Elles sont écrites dans le langage de requête Kusto et sont exécutés sur le pipeline d’ingestion. Elles peuvent être utilisées pour transformer des données à partir d’une ingestion de flux de modification Cosmos DB, comme dans les scénarios suivants :
- Vos documents contiennent des tableaux qui seraient plus faciles à interroger s’ils sont transformés en plusieurs lignes à l’aide de l’opérateur
mv-expand. - Il convient de filtrer les documents. Par exemple, vous pouvez filtrer les documents par type à l’aide de l’opérateur
where. - Vous avez une logique complexe qui ne peut pas être représentée dans un mappage de table.
Pour plus d’informations sur la création et la gestion des stratégies de mise à jour, consultez Vue d’ensemble de la stratégie de mise à jour.
Étape 2 : Créez une connexion de données Cosmos DB
Vous pouvez utiliser les méthodes suivantes pour créer le connecteur de données :
Dans le portail Azure, accédez à la page vue d’ensemble de votre cluster, puis sélectionnez l’onglet Prise en main.
Dans la vignette Ingestion de données , sélectionnez Créer une connexion de données>Cosmos DB.
Dans le volet Cosmos DB Créer une connexion de données, renseignez le formulaire avec les informations contenues dans le tableau :
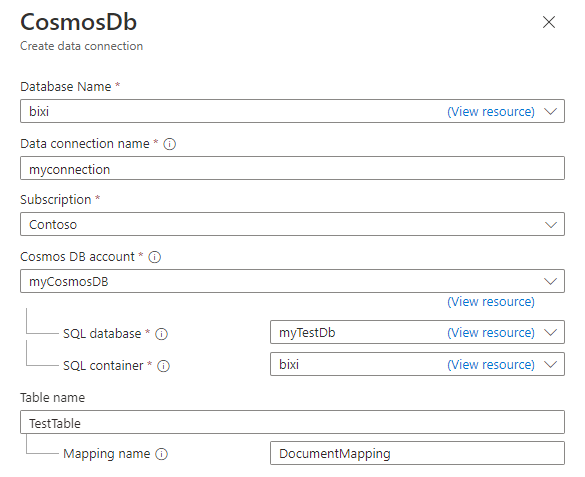
Champ Description Nom de la base de données Choisissez la base de données Azure Data Explorer dans laquelle vous souhaitez ingérer des données. Nom de la connexion de données Spécifiez un nom pour la connexion de données. Abonnement Sélectionnez l’abonnement qui contient votre compte NoSQL Cosmos DB. Compte Cosmos DB Choisissez le compte Cosmos DB à partir duquel vous souhaitez ingérer des données. Base de données SQL Choisissez la base données Cosmos DB à partir duquel vous souhaitez ingérer des données. Conteneur SQL Choisissez le conteneur Cosmos DB à partir duquel vous souhaitez ingérer des données. Nom de la table Spécifiez le nom de la table Azure Data Explorer vers laquelle vous souhaitez ingérer des données. Nom du mappage En option, si vous le souhaitez, spécifiez le nom de mappage à utiliser pour la connexion de données. En option, dans la section Paramètres avancés, effectuez les étapes suivantes :
Spécifiez la Date de début de la récupération d’événement. Il s’agit de l’heure à partir de laquelle le connecteur commencera à ingérer des données. Si vous ne spécifiez pas d’heure, le connecteur commence à ingérer des données à partir du moment où vous créez la connexion de données. Le format de date recommandé est la norme UTC ISO 8601, spécifiée comme suit :
yyyy-MM-ddTHH:mm:ss.fffffffZ.Sélectionnez Affecté par l’utilisateur, puis sélectionnez l’identité. Par défaut, l’identité managée Affecté par le système est utilisée par la connexion. Si nécessaire, vous pouvez utiliser une identité affectée par l’utilisateur.
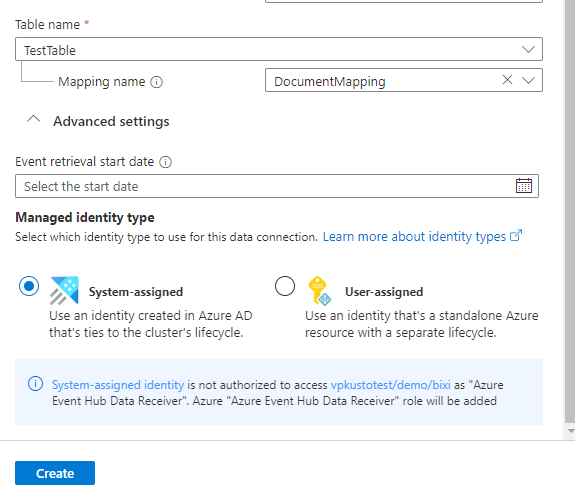
Sélectionnez Créer pour créer la connexion de données.
Étape 3 : Testez la connexion de données
Dans le conteneur Cosmos DB, insérez le document suivant :
{ "name":"Cousteau" }Dans l’interface utilisateur web d’Azure Data Explorer, exécutez la requête suivante :
TestTableLe jeu de résultats doit ressembler à l’image suivante :

Remarque
Azure Data Explorer a une stratégie d’agrégation (traitement par lots) pour l’ingestion de données en file d’attente conçue pour optimiser le processus d’ingestion. La stratégie de traitement par lot par défaut est configurée pour sceller un lot une fois que l’une des conditions suivantes est remplie pour le lot : délai maximal de 5 minutes, taille totale de un Go ou 1000 objets blob. Il existe donc un risque de latence. Pour plus d’informations, consultez la stratégie de traitement par lot. Pour réduire la latence, configurez votre table pour prendre en charge la diffusion en continu. Consultez la stratégie de diffusion en continu.
À propos de l’installation
Les considérations suivantes s’appliquent au flux de modification Cosmos DB :
Le flux de modification n’expose pas les événements de suppression.
Le flux de modification Cosmos DB inclut uniquement les documents nouveaux et mis à jour. Si vous avez besoin de connaître les documents supprimés, vous pouvez configurer votre flux à l’aide d’un marqueur réversible pour marquer un document Cosmos DB comme supprimé. Une propriété est ajoutée aux événements de mise à jour qui indiquent si un document a été supprimé. Vous pouvez ensuite utiliser l’opérateur
wheredans vos requêtes pour les filtrer.Par exemple, si vous mappez la propriété supprimée à une colonne de table appelée IsDeleted, vous pouvez filtrer les documents supprimés avec la requête suivante :
TestTable | where not(IsDeleted)Le flux de modification expose uniquement la dernière mise à jour d’un document.
Pour comprendre la conséquence de la deuxième considération, examinez le scénario suivant :
Un conteneur Cosmos DB contient des documents A et B. Les modifications apportées à une propriété appelée foo sont affichées dans le tableau suivant :
ID document Propriété foo Événement Horodateur de document (_ts) A Rouge Création 10 G Bleu Création 20 A Orange Update 30 A Pink Update 40 G Violet Update 50 A Carmine Update 50 G NeonBlue Update 70 L’API de flux de modification est interrogée par le connecteur de données à intervalles réguliers, généralement toutes les quelques secondes. Chaque interrogation contient des modifications qui se sont produites dans le conteneur entre les appels, mais uniquement la dernière version de la modification par document.
Pour illustrer le problème, envisagez une séquence d’appels d’API avec des horodateurs 15, 35, 55et 75 comme indiqué dans le tableau suivant :
Horodateur des appels d’API ID document Propriété foo Horodateur de document (_ts) 15 A Rouge 10 35 G Bleu 20 35 A Orange 30 55 G Violet 50 55 A Carmine 60 75 G NeonBlue 70 En comparant les résultats de l’API à la liste des modifications apportées dans le document Cosmos DB, vous remarquerez qu’elles ne correspondent pas. L’événement de mise à jour pour documenter A, mis en surbrillance dans la table de modifications à l’horodateur 40, n’apparaît pas dans les résultats de l’appel d’API.
Pour comprendre pourquoi l’événement n’apparaît pas, nous examinerons les modifications apportées au document un entre les appels d’API aux horodateurs 35 et 55. Entre ces deux appels, le document A est modifié deux fois, comme suit :
ID document Propriété foo Événement Horodateur de document (_ts) A Pink Update 40 A Carmine Update 50 Lorsque l’appel d’API au timestamp 55 est effectué, l’API de flux de modification retourne la dernière version du document. Dans ce cas, la dernière version du document A est la mise à jour à l’horodateur 50, qui est la mise à jour vers la propriété foo de Pink à Carmine.
En raison de ce scénario, le connecteur de données peut manquer certaines modifications de document intermédiaires. Par exemple, certains événements peuvent être manqués si le service de connexion de données est arrêté pendant quelques minutes, ou si la fréquence des modifications de document est supérieure à la fréquence d’interrogation de l’API. Toutefois, l’état le plus récent de chaque document est capturé.
La suppression et la recréation d’un conteneur Cosmos DB ne sont pas prises en charge
Azure Data Explorer effectue le suivi du flux de modification en pointant la « position » à laquelle il se trouve dans le flux. Cette opération est effectuée à l’aide d’un jeton de continuation sur chaque partition physique du conteneur. Lorsqu’un conteneur est supprimé/recréé, le jeton de continuation n’est pas valide et n’est pas réinitialisé. Dans ce cas, vous devez supprimer et recréer la connexion de données.
Estimer les coûts
En quoi l’utilisation de la connexion de données Cosmos DB a-t-elle un impact sur l’utilisation des unités de requête (RU ) de votre conteneur Cosmos DB ?
Le connecteur invoque l’API Flux de modification Cosmos DB sur chaque partition physique de votre conteneur, jusqu’à une fois par seconde. Les coûts suivants sont associés à ces invocations :
| Coût | Description |
|---|---|
| Coûts fixes | Les coûts fixes sont d’environ 2 RU par partition physique toutes les secondes. |
| Coûts variables | Les coûts variables sont d’environ 2 % des RU utilisées pour écrire des documents, mais cela peut varier en fonction de votre scénario. Par exemple, si vous écrivez 100 documents dans un conteneur Cosmos DB, le coût d’écriture de ces documents est de 1 000 RU. Le coût correspondant pour l’utilisation du connecteur pour lire ce document est d’environ 2 % le coût d’écriture, environ 20 RU. |