Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article vous montre comment ingérer des objets blob de votre compte de stockage vers Azure Data Explorer en utilisant une connexion de données Event Grid. Vous allez créer une connexion de données Event Grid qui définit un abonnement Azure Event Grid. L’abonnement Event Grid route les événements de votre compte de stockage vers Azure Data Explorer via un hub d’événements Azure.
Note
L’ingestion prend en charge une taille de fichier maximale de 6 Go. Nous vous recommandons d’ingérer des fichiers entre 100 Mo et 1 Go.
Pour apprendre à créer la connexion à l’aide des SDK Kusto, consultez Créer une connexion de données Event Grid avec des SDK.
Pour obtenir des informations générales sur l’ingestion dans Azure Data Explorer à partir d’Event Grid, consultez Se connecter à Event Grid.
Note
Pour obtenir les meilleures performances avec la connexion Event Grid, définissez la propriété d’ingestion rawSizeBytes via les métadonnées de l’objet blob. Pour plus d’informations, consultez Propriétés d’ingestion.
Prerequisites
- Un abonnement Azure. Créez un compte Azure gratuit.
- Un cluster et une base de données Azure Data Explorer. Créer un cluster et une base de données.
- Une table de destination. Créer un tableau ou utilisez-en un existant.
- Un mappage d’ingestion pour la table.
- Un compte de stockage. Un abonnement de notification Event Grid peut être défini sur les comptes de stockage Azure pour
BlobStorage,StorageV2ou Data Lake Storage Gen2. - Veuillez vous assurer que le fournisseur de ressources Event Grid est enregistré.
Créer une connexion de données à Event Grid
Dans cette section, vous établissez une connexion entre Event Grid et votre table Azure Data Explorer.
Parcourez votre cluster Azure Data Explorer dans le portail Azure.
Sous Données, sélectionnez Databases>TestDatabase.
Sous Paramètres, sélectionnez Connexions de données, puis sélectionnez Ajouter une connexion de données>Event Grid (Blob storage).
Remplissez le formulaire de connexion de données Event Grid avec les informations suivantes :
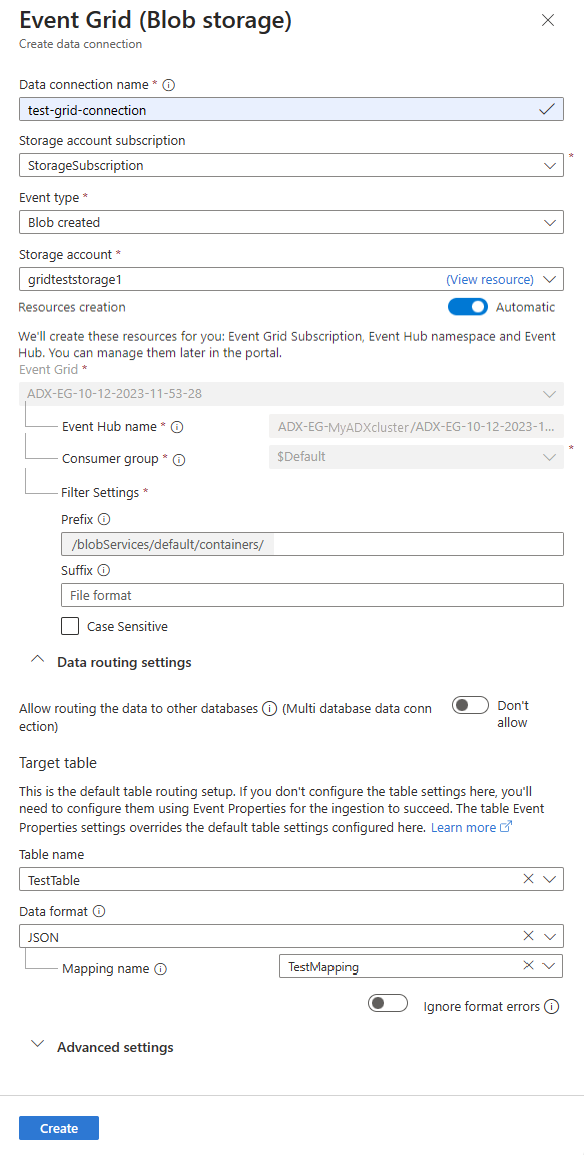
Réglage Valeur suggérée Description du champ Nom de la connexion de données test-grid-connection Nom de la connexion que vous souhaitez créer dans Azure Data Explorer. Les noms de connexion de données peuvent contenir uniquement des caractères alphanumériques, des tirets et des points, et comporter jusqu’à 40 caractères. Abonnement du compte de stockage Votre ID d’abonnement ID d’abonnement où se trouve votre compte de stockage. Type d'événement Blob créé ou renommé Type d’événement qui déclenche l’ingestion. Le renommage des blobs est uniquement prise en charge pour le stockage ADLSv2. Pour renommer un blob, accédez au blob dans le portail Azure, cliquez avec le bouton droit sur le blob et sélectionnez Renommer. Types pris en charge : Microsoft.Storage.BlobCreated ou Microsoft.Storage.BlobRenamed. Compte de stockage gridteststorage1 Nom du compte de stockage que vous avez créé précédemment. Création de ressources Automatique L’activation de la création automatique de ressources signifie qu’Azure Data Explorer crée un abonnement Event Grid, un espace de noms Event Hubs et un Event Hubs pour vous. Sinon, vous devez créer ces ressources manuellement pour garantir la création de la connexion de données. Consultez Créer manuellement des ressources pour l’ingestion Event Grid Vous pouvez également suivre des sujets Event Grid spécifiques. Définissez les filtres pour les notifications comme suit :
- Le champ Préfixe correspond au préfixe littéral du sujet. Comme le modèle appliqué commence par, il peut s’étendre sur plusieurs conteneurs, dossiers ou blobs. Les caractères génériques ne sont pas autorisés.
- Pour définir un filtre sur le conteneur d’objets blob, le champ doit être défini comme suit :
/blobServices/default/containers/[container prefix]. - Pour définir un filtre sur un préfixe d’objet blob (ou un dossier dans Azure Data Lake Gen2), le champ doit être défini comme suit :
/blobServices/default/containers/[container name]/blobs/[folder/blob prefix].
- Pour définir un filtre sur le conteneur d’objets blob, le champ doit être défini comme suit :
- Le champ Suffixe correspond au suffixe littéral du blob. Les caractères génériques ne sont pas autorisés.
- Le champ Sensible à la casse indique si les filtres de préfixe et de suffixe sont sensibles à la casse.
Pour plus d’informations sur le filtrage des événements, consultez Événements du stockage Blob.
- Le champ Préfixe correspond au préfixe littéral du sujet. Comme le modèle appliqué commence par, il peut s’étendre sur plusieurs conteneurs, dossiers ou blobs. Les caractères génériques ne sont pas autorisés.
Vous pouvez également spécifier les paramètres de routage des données en fonction des informations suivantes. Vous n’avez pas à spécifier tous les paramètres de routage des données. Des paramètres partiels sont également acceptés.
Réglage Valeur suggérée Description du champ Autoriser le routage des données vers d’autres bases de données (connexion de données à plusieurs bases de données) Ne pas autoriser Activez cette option si vous souhaitez remplacer la base de données cible par défaut associée à la connexion de données. Pour plus d’informations sur le routage de base de données, consultez Routage des événements. Nom du tableau TestTable Table que vous avez créée dans TestDatabase. Format de données JSON Les formats pris en charge sont APACHEAVRO, Avro, CSV, JSON, ORC, PARQUET, PSV, RAW, SCSV, SOHSV, TSV, TSVE, TXT et W3CLOG. Les options de compression prises en charge sont zip et gzip. Nom du mappage TestTable_mapping Le mappage que vous avez créé dans TestDatabase, qui mappe les données entrantes aux noms de colonnes et aux types de données de TestTable. Si vous ne spécifiez pas de nom, un mappage de données d’identité dérivé du schéma de la table est généré automatiquement. Note
Les noms de table et de mappage sont sensibles à la casse.
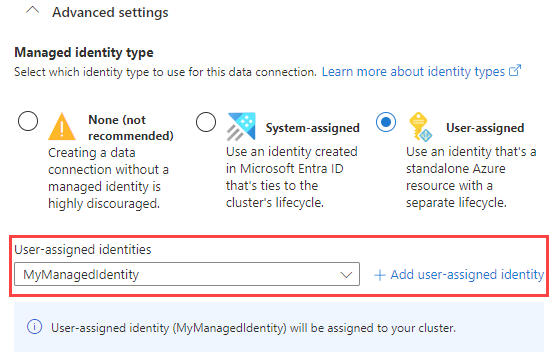
Vous pouvez également, sous Paramètres avancés, spécifier le type d’identité gérée utilisé par votre connexion de données. Par défaut, l’option Attribué par le système est sélectionnée.
Si vous sélectionnez Attribué par l’utilisateur, vous devez attribuer manuellement une identité gérée. Si vous sélectionnez un utilisateur qui n’est pas encore attribué à votre cluster, il sera attribué automatiquement. Pour plus d’informations, consultez Configurer des identités gérées pour votre cluster Azure Data Explorer.
Si vous sélectionnez Aucun, le compte de stockage et le hub d’événements sont authentifiés via des chaînes de connexion. Cette méthode n’est pas recommandée.
Sélectionnez Créer



Utiliser la connexion de données Event Grid
Cette section explique comment déclencher l’ingestion depuis Azure Blob Storage ou Azure Data Lake Gen 2 vers votre cluster après la création ou le renommage d’un blob.
Sélectionnez l’onglet approprié en fonction du type de SDK de stockage utilisé pour charger les blobs.
L’exemple de code suivant utilise le SDK Azure Blob Storage pour charger un fichier dans Azure Blob Storage. Le chargement déclenche la connexion de données Event Grid, qui ingère les données dans Azure Data Explorer.
var azureStorageAccountConnectionString = <storage_account_connection_string>;
var containerName = <container_name>;
var blobName = <blob_name>;
var localFileName = <file_to_upload>;
var uncompressedSizeInBytes = <uncompressed_size_in_bytes>;
var mapping = <mapping_reference>;
// Create a new container if it not already exists.
var azureStorageAccount = new BlobServiceClient(azureStorageAccountConnectionString);
var container = azureStorageAccount.GetBlobContainerClient(containerName);
container.CreateIfNotExists();
// Define blob metadata and uploading options.
IDictionary<String, String> metadata = new Dictionary<string, string>();
metadata.Add("rawSizeBytes", uncompressedSizeInBytes);
metadata.Add("kustoIngestionMappingReference", mapping);
var uploadOptions = new BlobUploadOptions
{
Metadata = metadata,
};
// Upload the file.
var blob = container.GetBlobClient(blobName);
blob.Upload(localFileName, uploadOptions);
Note
Azure Data Explorer ne supprimera pas les objets blob après l’ingestion. Conservez les blobs pendant trois à cinq jours en utilisant le cycle de vie du Stockage Blob Azure pour gérer la suppression des blobs.
Note
Le déclenchement de l’ingestion après une opération CopyBlob n’est pas pris en charge pour les comptes de stockage sur lesquels la fonctionnalité d’espace de noms hiérarchique est activée.
Importante
Nous vous déconseillons fortement de générer des événements de stockage à partir de code personnalisé et de les envoyer à des hubs d’événements. Si vous choisissez de le faire, assurez-vous que les événements produits respectent strictement le schéma des événements de stockage et les spécifications de format JSON appropriés.
Supprimer une connexion de données Event Grid
Pour supprimer la connexion Event Grid du portail Azure, procédez comme suit :
- Accédez à votre cluster. Dans le menu de gauche, sélectionnez Bases de données. Sélectionnez ensuite la base de données qui contient la table cible.
- Dans le menu de gauche, sélectionnez Connexions de données. Cochez ensuite la case en regard de la connexion de données Event Grid appropriée.
- Dans la barre de menu supérieure, sélectionnez Supprimer.