Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
L’ingestion des données est le processus utilisé pour charger des données d’une ou plusieurs sources dans une table dans Azure Data Explorer. Une fois ingérées, les données sont disponibles pour les requêtes. Dans cet article, vous allez apprendre à obtenir des données à partir du stockage Azure (conteneur ADLS Gen2, conteneur d’objets blob ou objets blob individuels) dans une table nouvelle ou existante.
Pour obtenir des informations générales sur l’ingestion des données, consultez la vue d’ensemble de l’ingestion des données Azure Data Explorer.
Avertissement
L’Assistant Obtenir des données ne prend pas en charge l’ingestion à partir du stockage Azure via des points de terminaison privés ou des points de terminaison privés managés. Suivez les instructions pour obtenir des données à l’aide de la commande .ingest .
Prérequis
- Un compte Microsoft ou une identité utilisateur Microsoft Entra. Un abonnement Azure n’est pas requis.
- Connectez-vous à l’interface utilisateur web d’Azure Data Explorer.
- Un cluster et une base de données Azure Data Explorer. Créez un cluster et une base de données.
- Un compte de stockage.
Obtenir des données
Dans le menu de gauche, sélectionnez Requête.
Cliquez avec le bouton droit sur la base de données dans laquelle vous souhaitez ingérer les données. Sélectionnez Obtenir les données.

Source
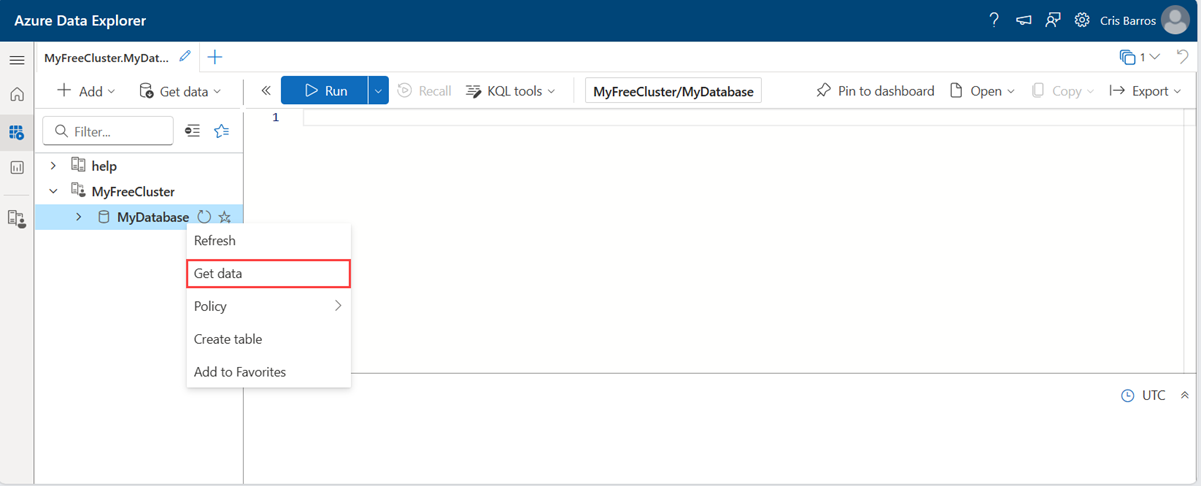
Dans la fenêtre Obtenir des données, l’onglet Source est sélectionné.
Sélectionnez la source de données dans la liste disponible. Dans cet exemple, vous ingérez des données à partir d’un stockage Azure.

Configurer
Sélectionnez une base de données et une table cibles. Si vous souhaitez ingérer des données dans une nouvelle table, sélectionnez +Nouvelle table et entrez un nom de table.
Remarque
Les noms de tables peuvent comporter jusqu’à 1024 caractères, y compris des espaces, des caractères alphanumériques, des traits d’union et des traits de soulignement. Les caractères spéciaux ne sont pas pris en charge.
Pour ajouter votre source, sélectionnez Sélectionner un conteneur ou ajouter un URI.
Si vous avez sélectionné Sélectionner un conteneur, renseignez les champs suivants :
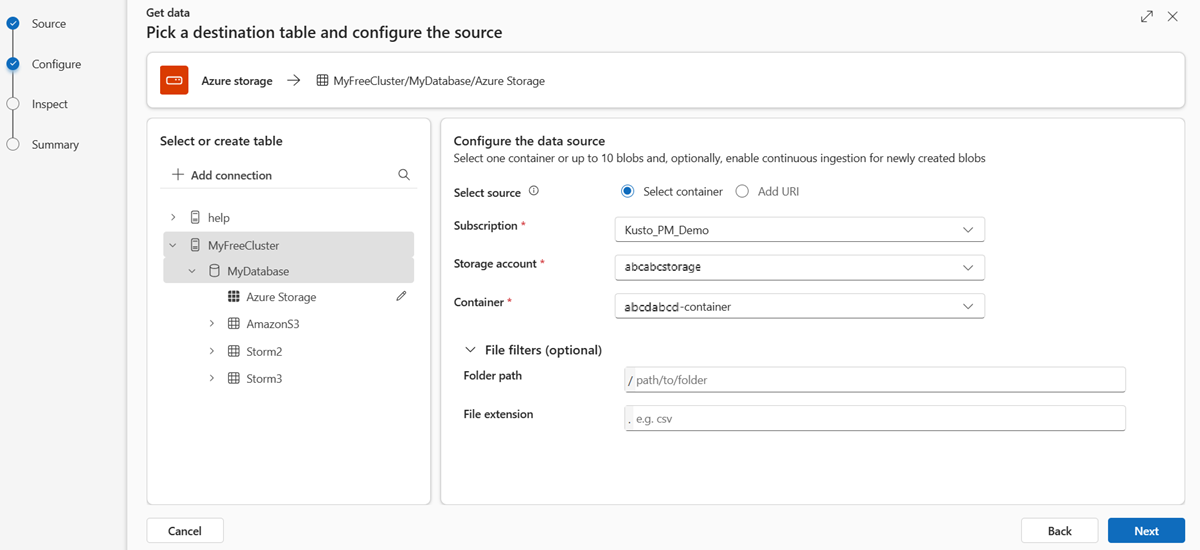
Paramètre Description du champ Abonnement ID d’abonnement où se trouve le compte de stockage. Compte de stockage Nom qui identifie votre compte de stockage. Conteneur Conteneur de stockage que vous souhaitez ingérer. Filtres de fichiers (facultatif) Chemin d’accès du dossier Filtre les données pour ingérer des fichiers avec un chemin d’accès de dossier spécifique. Extension de fichier Filtre les données pour ingérer des fichiers avec une extension de fichier spécifique uniquement. Si vous avez sélectionné Ajouter un URI :
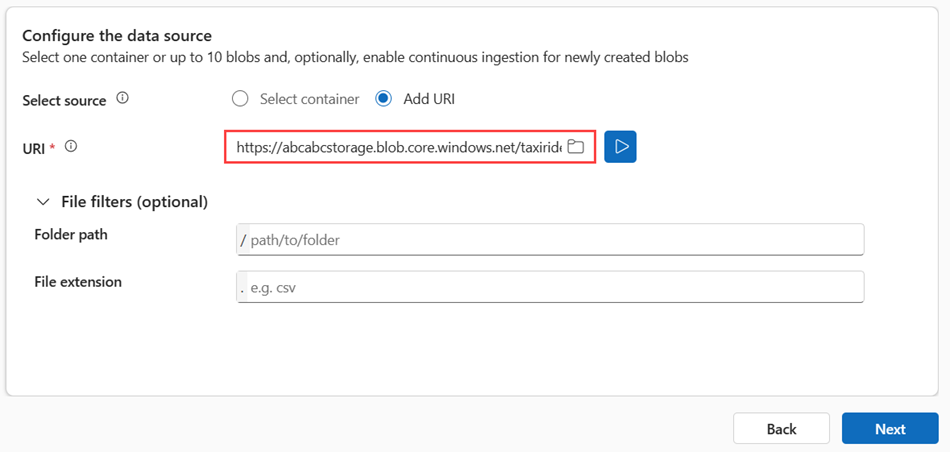
À partir du compte de stockage, générez une URL SAP pour le conteneur ou les objets blob individuels que vous souhaitez ingérer. Définissez les autorisations sur Lire et Lister pour les conteneurs ou sur Lire pour les blobs individuels. Pour plus d’informations, consultez Générer un jeton SAP.
Collez l’URL dans le champ URI
, puis sélectionnez plus ( ). Vous pouvez ajouter plusieurs URI pour des objets blob individuels ou un URI unique pour un conteneur.
Remarque
- Vous pouvez ajouter jusqu’à 10 objets blob individuels. Chaque objet blob peut être un maximum de 1 Go non compressé.
- Vous pouvez ingérer jusqu’à 5 000 blobs d’un seul conteneur.
- Vous ne pouvez pas ingérer des blobs et des conteneurs individuels au cours du même processus d'ingestion.
Sélectionnez Suivant.


Inspecter
L’onglet Inspecter s’ouvre avec un aperçu des données.
Pour terminer le processus d’ingestion, sélectionnez Terminer.

Si vous le souhaitez :
- Utilisez la liste déroulante Fichier de définition de schéma pour modifier le fichier à partir duquel le schéma est déduit.
- Modifiez le format de données déduit automatiquement en sélectionnant le format souhaité dans la liste déroulante. Consultez les formats de données pris en charge par Azure Data Explorer pour l’ingestion.
- Modifier les colonnes.
- Explorez les options avancées basées sur le type de données.
Modifier les colonnes
Remarque
- Pour les formats tabulaires (CSV, TSV, PSV), vous ne pouvez pas mapper deux fois une même colonne. Pour effectuer un mappage à une colonne existante, commencez par supprimer la nouvelle colonne.
- Vous ne pouvez pas changer un type de colonne existant. Si vous essayez de mapper à une colonne avec un format différent, vous risquez de vous retrouver avec des colonnes vides.
Les modifications que vous pouvez apporter dans une table dépendent des paramètres suivants :
- Si le type de la table est nouveau ou existant
- Si le type du mappage est nouveau ou existant
| Type de la table | Type de mappage | Ajustements disponibles |
|---|---|---|
| Nouvelle table | Nouveau mappage | Renommer une colonne, modifier le type de données, modifier la source de données, transformation de mappage, ajouter une colonne, supprimer une colonne |
| Table existante | Nouveau mappage | Ajoutez une colonne (vous pourrez ensuite modifier le type de données, la renommer ou la mettre à jour) |
| Table existante | Mappage existant | Aucune |

Mappage des transformations
Certains mappages de format de données (Parquet, JSON et Avro) prennent en charge des transformations simples au moment de l’ingestion. Pour appliquer des transformations de mappage, créez ou mettez à jour une colonne dans la fenêtre Modifier les colonnes.
Les transformations de mappage peuvent être effectuées sur une colonne de type string ou datetime, avec la source dont le type de données est int ou long. Les transformations de mappage prises en charge sont :
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Options avancées basées sur le type de données
Tabulaire (CSV, TSV, PSV) :
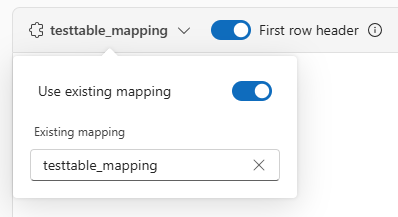
Si vous ingérez des formats tabulaires dans une table existante, vous pouvez sélectionner la liste déroulante du mappage de la table et choisir Utiliser le mappage existant. Les données tabulaires n’incluent pas nécessairement les noms de colonnes utilisés pour mapper les données sources aux colonnes existantes. Quand cette option est activée, le mappage est effectué dans l’ordre et le schéma de la table reste le même.
Sinon, créez un mappage.
Pour utiliser la première ligne en tant que noms de colonnes, sélectionnez Premier en-tête de ligne.
JSON :
- Pour déterminer la division de colonnes des données JSON, sélectionnez niveaux imbriqués, de 1 à 100.
Résumé
Dans la fenêtre Résumé , les trois étapes sont marquées avec des coches vertes lorsque l’ingestion des données se termine correctement. Vous pouvez afficher les commandes utilisées pour chaque étape, ou sélectionner une carte pour interroger, visualiser ou supprimer les données ingérées.
