Plug-in Python
Le plug-in Python exécute une fonction définie par l’utilisateur (UDF) à l’aide d’un script Python. Le script Python obtient des données tabulaires comme entrée et produit une sortie tabulaire. Le runtime du plug-in est hébergé dans des bacs à sable, s’exécutant sur les nœuds du cluster.
Syntaxe
T | evaluate [hint.distribution = (singleper_node | )] [hint.remote = (autolocal | )] python(output_schema, script [, script_parameters] [, external_artifacts][, spill_to_disk])
En savoir plus sur les conventions de syntaxe.
Paramètres
| Nom | Type | Requise | Description |
|---|---|---|---|
| output_schema | string |
✔️ | Littéral type qui définit le schéma de sortie des données tabulaires, retourné par le code Python. Le format est : typeof(ColumnName: ColumnType[, ...]). Par exemple, typeof(col1:string, col2:long). Pour étendre le schéma d’entrée, utilisez la syntaxe suivante : typeof(*, col1:string, col2:long). |
| script | string |
✔️ | Script Python valide à exécuter. Pour générer des chaînes multilignes, consultez conseils d’utilisation. |
| script_parameters | dynamic |
Un conteneur de propriétés de paires valeur de nom à passer au script Python en tant que dictionnaire réservé kargs . Pour plus d’informations, consultez les variables Python réservées. |
|
| hint.distribution | string |
Indicateur de répartition de l’exécution du plug-in sur plusieurs nœuds de cluster. La valeur par défaut est single. single signifie qu’une seule instance du script s’exécute sur l’ensemble des données de requête. per_node signifie que si la requête avant le bloc Python est distribuée, une instance du script s’exécute sur chaque nœud, sur les données qu’il contient. |
|
| hint.remote | string |
Cet indicateur n’est pertinent que pour les requêtes entre clusters. La valeur par défaut est auto. auto signifie que le serveur décide automatiquement dans quel cluster le code Python est exécuté. Définition de la valeur pour local forcer l’exécution du code Python sur le cluster local. Utilisez-le si le plug-in Python est désactivé sur le cluster distant. |
|
| external_artifacts | dynamic |
Un conteneur de propriétés de paires nom et URL pour les artefacts accessibles à partir du stockage cloud. Pour plus d’informations, consultez Utilisation d’artefacts externes. | |
| spill_to_disk | bool |
Spécifie une autre méthode pour sérialiser la table d’entrée vers le bac à sable Python. Pour sérialiser les grandes tables, définissez-les pour true accélérer la sérialisation et réduire considérablement la consommation de mémoire du bac à sable. La valeur par défaut est true. |
Variables Python réservées
Les variables suivantes sont réservées pour l’interaction entre Langage de requête Kusto et le code Python.
df: données tabulaires d’entrée (valeurs ci-dessus), sous forme deTpandasDataFrame.kargs: valeur de l’argument script_parameters , en tant que dictionnaire Python.result: DataFramepandascréé par le script Python, dont la valeur devient les données tabulaires envoyées à l’opérateur de requête Kusto qui suit le plug-in.
Activer le plug-in
Cette option est désactivée par défaut. Avant de commencer, passez en revue la liste des prérequis. Pour activer le plug-in et sélectionner la version de l’image Python, consultez Activer les extensions de langage sur votre cluster.
Image de bac à sable Python
Pour modifier la version de l’image Python, consultez Modifier l’image des extensions de langage Python sur votre cluster.
Pour afficher la liste des packages pour les différentes images Python, consultez la référence du package Python.
Remarque
- Par défaut, le plug-in importe numpy en tant que np et pandas en tant que . Si vous le souhaitez, vous pouvez importer d’autres modules en fonction des besoins.
- Certains packages peuvent être incompatibles avec les limitations appliquées par le bac à sable où le plug-in est exécuté.
Utiliser l’ingestion à partir de la stratégie de requête et de mise à jour
- Utilisez le plug-in dans les requêtes suivantes :
- Défini dans le cadre d’une stratégie de mise à jour, dont la table source est ingérée à l’aide d’une ingestion sans diffusion en continu .
- Exécutez dans le cadre d’une commande qui ingère à partir d’une requête, par
.set-or-appendexemple .
- Vous ne pouvez pas utiliser le plug-in dans une requête définie dans le cadre d’une stratégie de mise à jour, dont la table source est ingérée à l’aide de l’ingestion de streaming.
Exemples
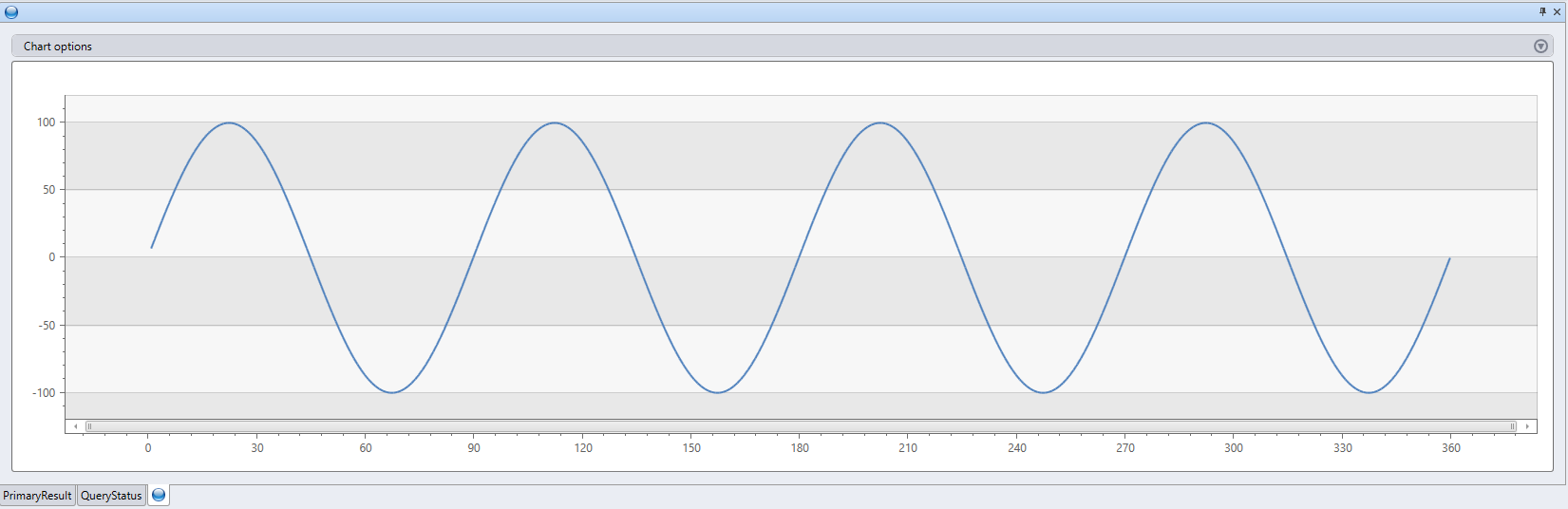
range x from 1 to 360 step 1
| evaluate python(
//
typeof(*, fx:double), // Output schema: append a new fx column to original table
```
result = df
n = df.shape[0]
g = kargs["gain"]
f = kargs["cycles"]
result["fx"] = g * np.sin(df["x"]/n*2*np.pi*f)
```
, bag_pack('gain', 100, 'cycles', 4) // dictionary of parameters
)
| render linechart
print "This is an example for using 'external_artifacts'"
| evaluate python(
typeof(File:string, Size:string), ```if 1:
import os
result = pd.DataFrame(columns=['File','Size'])
sizes = []
path = '.\\\\Temp'
files = os.listdir(path)
result['File']=files
for file in files:
sizes.append(os.path.getsize(path + '\\\\' + file))
result['Size'] = sizes
```,
external_artifacts =
dynamic({"this_is_my_first_file":"https://kustoscriptsamples.blob.core.windows.net/samples/R/sample_script.r",
"this_is_a_script":"https://kustoscriptsamples.blob.core.windows.net/samples/python/sample_script.py"})
)
| File | Taille |
|---|---|
| this_is_a_script | 120 |
| this_is_my_first_file | 105 |
Astuces pour les performances
- Réduisez le jeu de données d’entrée du plug-in à la quantité minimale requise (colonnes/lignes).
- Utilisez des filtres sur le jeu de données source, le cas échéant, avec le langage de requête de Kusto.
- Pour effectuer un calcul sur un sous-ensemble des colonnes sources, projetez uniquement ces colonnes avant d’appeler le plug-in.
- Utilisez
hint.distribution = per_nodechaque fois que la logique de votre script est distribuable. - Utilisez le langage de requête de Kusto chaque fois que possible, pour implémenter la logique de votre script Python.
Conseils d’utilisation
Pour générer des chaînes à plusieurs lignes contenant le script Python dans votre éditeur de requête, copiez votre script Python à partir de votre éditeur Python favori (Jupyter, Visual Studio Code, PyCharm, et ainsi de suite), collez-le dans votre éditeur de requête, puis placez le script complet entre les lignes contenant trois backticks consécutifs. Par exemple :
```
python code
```Utilisez l’opérateur
externaldatapour obtenir le contenu d’un script que vous avez stocké dans un emplacement externe, tel que stockage Blob Azure.
Exemple
let script =
externaldata(script:string)
[h'https://kustoscriptsamples.blob.core.windows.net/samples/python/sample_script.py']
with(format = raw);
range x from 1 to 360 step 1
| evaluate python(
typeof(*, fx:double),
toscalar(script),
bag_pack('gain', 100, 'cycles', 4))
| render linechart
Utilisation d’artefacts externes
Les artefacts externes du stockage cloud peuvent être mis à la disposition du script et utilisés lors de l’exécution.
Les URL référencées par la propriété artefacts externes doivent être les suivantes :
- Inclus dans la stratégie de légende du cluster.
- Dans un emplacement disponible publiquement ou fournissez les informations d’identification nécessaires, comme expliqué dans les chaîne de connexion de stockage.
Remarque
Lors de l’authentification d’artefacts externes à l’aide d’identités managées, l’utilisation SandboxArtifacts doit être définie sur la stratégie d’identité managée au niveau du cluster.
Les artefacts sont mis à la disposition du script pour qu’il consomme à partir d’un répertoire temporaire local. .\Temp Les noms fournis dans le conteneur de propriétés sont utilisés comme noms de fichiers locaux. Voir Exemples.
Pour plus d’informations sur le référencement de packages externes, consultez Installer des packages pour le plug-in Python.
Actualisation du cache d’artefacts externes
Les fichiers d’artefacts externes utilisés dans les requêtes sont mis en cache sur votre cluster. Si vous effectuez des mises à jour de vos fichiers dans le stockage cloud et que vous avez besoin d’une synchronisation immédiate avec votre cluster, vous pouvez utiliser la commande .clear cluster cache external-artifacts. Cette commande efface les fichiers mis en cache et garantit que les requêtes suivantes s’exécutent avec la dernière version des artefacts.
Installer des packages pour le plug-in Python
Vous devrez peut-être installer vous-même des packages pour les raisons suivantes :
- Le package est privé et est votre propre.
- Le package est public, mais n’est pas inclus dans l’image de base du plug-in.
Installez les packages comme suit :
Prérequis
Créez un conteneur d’objets blob pour héberger les packages, de préférence au même endroit que votre cluster. Par exemple,
https://artifactswestus.blob.core.windows.net/pythonen supposant que votre cluster se trouve dans la région USA Ouest.Modifiez la stratégie de légende du cluster pour autoriser l’accès à cet emplacement.
Cette modification nécessite des autorisations AllDatabasesAdmin .
Par exemple, pour activer l’accès à un objet blob situé dans
https://artifactswestus.blob.core.windows.net/python, exécutez la commande suivante :
.alter-merge cluster policy callout @'[ { "CalloutType": "sandbox_artifacts", "CalloutUriRegex": "artifactswestus\\.blob\\.core\\.windows\\.net/python/","CanCall": true } ]'
Installer des packages
Pour les packages publics dans PyPi ou d’autres canaux, téléchargez le package et ses dépendances.
- À partir d’une fenêtre cmd dans votre environnement Windows Python local, exécutez :
pip wheel [-w download-dir] package-name.Créez un fichier zip qui contient le package requis et ses dépendances.
- Pour les packages privés, compressez le dossier du package et les dossiers de ses dépendances.
- Pour les packages publics, compressez les fichiers téléchargés à l’étape précédente.
Remarque
- Veillez à télécharger le package compatible avec le moteur Python et la plateforme du runtime de bac à sable (actuellement 3.6.5 sur Windows)
- Veillez à compresser les
.whlfichiers eux-mêmes, et non à leur dossier parent. - Vous pouvez ignorer
.whlles fichiers des packages qui existent déjà avec la même version dans l’image de bac à sable de base.
Chargez le fichier compressé dans un objet blob à l’emplacement des artefacts (à l’étape 1).
Appelez le
pythonplug-in.- Spécifiez le
external_artifactsparamètre avec un conteneur de propriétés de nom et référencez le fichier zip (URL de l’objet blob, y compris un jeton SAP). - Dans votre code python inline, importez à partir de
sandbox_utilset appelezZipackagesainstall()méthode avec le nom du fichier zip.
- Spécifiez le
Exemple
Installez le package Faker qui génère des données fausses.
range ID from 1 to 3 step 1
| extend Name=''
| evaluate python(typeof(*), ```if 1:
from sandbox_utils import Zipackage
Zipackage.install("Faker.zip")
from faker import Faker
fake = Faker()
result = df
for i in range(df.shape[0]):
result.loc[i, "Name"] = fake.name()
```,
external_artifacts=bag_pack('faker.zip', 'https://artifacts.blob.core.windows.net/kusto/Faker.zip?*** REPLACE WITH YOUR SAS TOKEN ***'))
| id | Nom |
|---|---|
| 1 | Gary Tapia |
| 2 | Emma Evans |
| 3 | Ashley Bowen |
Contenu connexe
Pour plus d’exemples de fonctions UDF qui utilisent le plug-in Python, consultez la bibliothèque Functions.
Le plug-in Python exécute une fonction définie par l’utilisateur (UDF) à l’aide d’un script Python. Le script Python obtient des données tabulaires comme entrée et produit une sortie tabulaire.
Syntaxe
T | evaluate [hint.distribution = (singleper_node | )] [hint.remote = (autolocal | )] python(script output_schema , [, script_parameters] [, spill_to_disk])
En savoir plus sur les conventions de syntaxe.
Paramètres
| Nom | Type | Requise | Description |
|---|---|---|---|
| output_schema | string |
✔️ | Littéral type qui définit le schéma de sortie des données tabulaires, retourné par le code Python. Le format est : typeof(ColumnName: ColumnType[, ...]). Par exemple, typeof(col1:string, col2:long). Pour étendre le schéma d’entrée, utilisez la syntaxe suivante : typeof(*, col1:string, col2:long). |
| script | string |
✔️ | Script Python valide à exécuter. Pour générer des chaînes multilignes, consultez conseils d’utilisation. |
| script_parameters | dynamic |
Un conteneur de propriétés de paires valeur de nom à passer au script Python en tant que dictionnaire réservé kargs . Pour plus d’informations, consultez les variables Python réservées. |
|
| hint.distribution | string |
Indicateur de répartition de l’exécution du plug-in sur plusieurs nœuds de cluster. La valeur par défaut est single. single signifie qu’une seule instance du script s’exécute sur l’ensemble des données de requête. per_node signifie que si la requête avant le bloc Python est distribuée, une instance du script s’exécute sur chaque nœud, sur les données qu’il contient. |
|
| hint.remote | string |
Cet indicateur n’est pertinent que pour les requêtes entre clusters. La valeur par défaut est auto. auto signifie que le serveur décide automatiquement dans quel cluster le code Python est exécuté. Définition de la valeur pour local forcer l’exécution du code Python sur le cluster local. Utilisez-le si le plug-in Python est désactivé sur le cluster distant. |
|
| spill_to_disk | bool |
Spécifie une autre méthode pour sérialiser la table d’entrée vers le bac à sable Python. Pour sérialiser les grandes tables, définissez-les pour true accélérer la sérialisation et réduire considérablement la consommation de mémoire du bac à sable. La valeur par défaut est true. |
Variables Python réservées
Les variables suivantes sont réservées pour l’interaction entre Langage de requête Kusto et le code Python.
df: données tabulaires d’entrée (valeurs ci-dessus), sous forme deTpandasDataFrame.kargs: valeur de l’argument script_parameters , en tant que dictionnaire Python.result: DataFramepandascréé par le script Python, dont la valeur devient les données tabulaires envoyées à l’opérateur de requête Kusto qui suit le plug-in.
Activer le plug-in
Cette option est désactivée par défaut. Avant de commencer, activez le plug-in Python dans votre base de données KQL.
Image de bac à sable Python
Pour afficher la liste des packages pour les différentes images Python, consultez la référence du package Python.
Remarque
- Par défaut, le plug-in importe numpy en tant que np et pandas en tant que . Si vous le souhaitez, vous pouvez importer d’autres modules en fonction des besoins.
- Certains packages peuvent être incompatibles avec les limitations appliquées par le bac à sable où le plug-in est exécuté.
Utiliser l’ingestion à partir de la stratégie de requête et de mise à jour
- Utilisez le plug-in dans les requêtes suivantes :
- Défini dans le cadre d’une stratégie de mise à jour, dont la table source est ingérée à l’aide d’une ingestion sans diffusion en continu .
- Exécutez dans le cadre d’une commande qui ingère à partir d’une requête, par
.set-or-appendexemple .
- Vous ne pouvez pas utiliser le plug-in dans une requête définie dans le cadre d’une stratégie de mise à jour, dont la table source est ingérée à l’aide de l’ingestion de streaming.
Exemples
range x from 1 to 360 step 1
| evaluate python(
//
typeof(*, fx:double), // Output schema: append a new fx column to original table
```
result = df
n = df.shape[0]
g = kargs["gain"]
f = kargs["cycles"]
result["fx"] = g * np.sin(df["x"]/n*2*np.pi*f)
```
, bag_pack('gain', 100, 'cycles', 4) // dictionary of parameters
)
| render linechart
Astuces pour les performances
- Réduisez le jeu de données d’entrée du plug-in à la quantité minimale requise (colonnes/lignes).
- Utilisez des filtres sur le jeu de données source, le cas échéant, avec le langage de requête de Kusto.
- Pour effectuer un calcul sur un sous-ensemble des colonnes sources, projetez uniquement ces colonnes avant d’appeler le plug-in.
- Utilisez
hint.distribution = per_nodechaque fois que la logique de votre script est distribuable. - Utilisez le langage de requête de Kusto chaque fois que possible, pour implémenter la logique de votre script Python.
Conseils d’utilisation
Pour générer des chaînes à plusieurs lignes contenant le script Python dans votre éditeur de requête, copiez votre script Python à partir de votre éditeur Python favori (Jupyter, Visual Studio Code, PyCharm, et ainsi de suite), collez-le dans votre éditeur de requête, puis placez le script complet entre les lignes contenant trois backticks consécutifs. Par exemple :
```
python code
```Utilisez l’opérateur
externaldatapour obtenir le contenu d’un script que vous avez stocké dans un emplacement externe, tel que stockage Blob Azure.
Exemple
let script =
externaldata(script:string)
[h'https://kustoscriptsamples.blob.core.windows.net/samples/python/sample_script.py']
with(format = raw);
range x from 1 to 360 step 1
| evaluate python(
typeof(*, fx:double),
toscalar(script),
bag_pack('gain', 100, 'cycles', 4))
| render linechart
Contenu connexe
Pour plus d’exemples de fonctions UDF qui utilisent le plug-in Python, consultez la bibliothèque Functions.
Cette fonctionnalité n’est pas prise en charge.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour