Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Pour chaque source à l’exception d’Azure SQL Database, il est recommandé de conserver le partitionnement actuel comme valeur sélectionnée. Lorsque vous lisez tous les autres systèmes sources, les flux de données partitionnent automatiquement les données en fonction de la taille des données. Une nouvelle partition est créée pour environ 128 Mo de données. À mesure que la taille de vos données augmente, le nombre de partitions augmente.
Tout partitionnement personnalisé se produit après que Spark lit les données et affecte défavorablement les performances de votre flux de données. Comme les données sont partitionnées uniformément lors de la lecture, cela n'est pas recommandé, sauf si vous avez d'abord une bonne compréhension de la forme et de la cardinalité de vos données.
Note
Les vitesses de lecture peuvent être limitées par le débit de votre système source.
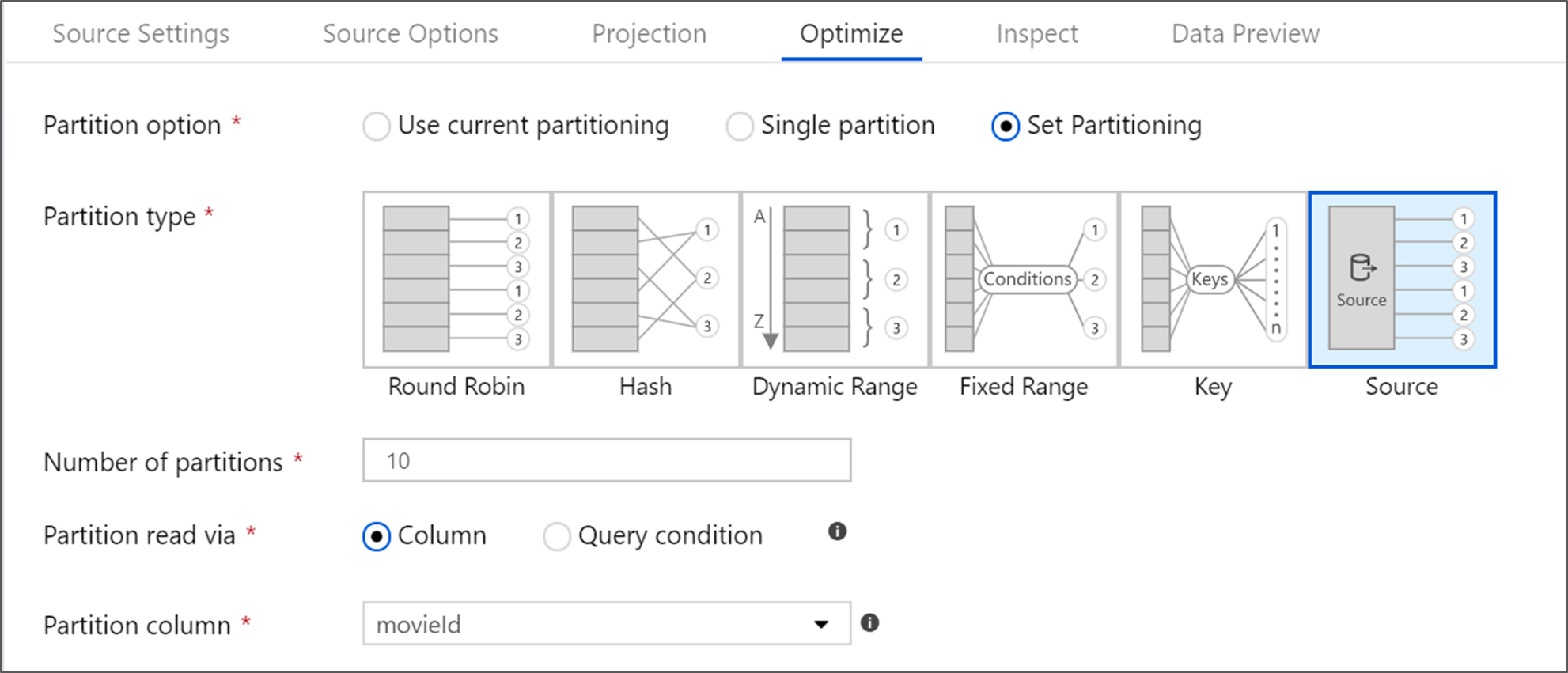
Sources de la base de données Azure SQL
Azure SQL Database a une option de partitionnement unique appelée partitionnement « Source ». L’activation du partitionnement source peut améliorer vos temps de lecture à partir d’Azure SQL Database en activant des connexions parallèles sur le système source. Spécifiez le nombre de partitions et comment partitionner vos données. Utilisez une colonne de partition avec une cardinalité élevée. Vous pouvez également entrer une requête qui correspond au schéma de partitionnement de votre table source.
Conseil / Astuce
Pour le partitionnement source, l’E/S du serveur SQL Server est le goulot d’étranglement. L’ajout de trop de partitions peut saturer votre base de données source. En règle générale, quatre ou cinq partitions sont idéales lors de l’utilisation de cette option.
Niveau d’isolation
Le niveau d’isolation de la lecture sur un système source Azure SQL affecte les performances. Choisir « Lecture non validée » offre les performances les plus rapides et réduit les risques de verrous sur la base de données. Pour en savoir plus sur les niveaux d’isolation SQL, consultez Présentation des niveaux d’isolation.
Lire via une requête
Vous pouvez lire à partir d’Azure SQL Database à l’aide d’une table ou d’une requête SQL. Si vous exécutez une requête SQL, la requête doit être terminée avant que la transformation puisse commencer. Les requêtes SQL peuvent être utiles pour pousser des opérations qui peuvent s’exécuter plus rapidement et réduire la quantité de données lues à partir d’un serveur SQL Server, comme les instructions SELECT, WHERE et JOIN. Lors de la délégation des opérations, vous perdez la possibilité de suivre la traçabilité et les performances des transformations avant que les données n'entrent dans le flux de données.
Sources Azure Synapse Analytics
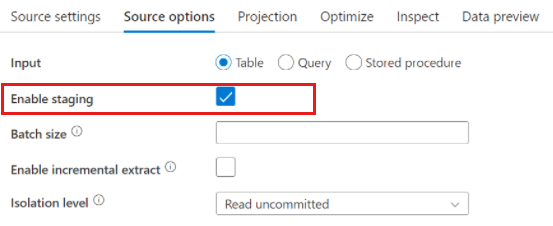
Lorsque vous utilisez Azure Synapse Analytics, un paramètre appelé Activer la préproduction existe dans les options sources. Cela permet au service de lire à partir de Synapse à l’aide de Staging, ce qui améliore considérablement les performances de lecture grâce à l'utilisation de la fonctionnalité de chargement en bloc la plus performante, telle que CETAS et la commande COPY. L’activation de Staging nécessite que vous spécifiiez un Stockage Blob Azure ou un emplacement de préproduction Azure Data Lake Storage Gen2 dans les paramètres d’activité du flux de données.
Sources basées sur des fichiers
Parquet vs texte délimité
Bien que les flux de données prennent en charge différents types de fichiers, le format Parquet natif Spark est recommandé pour des temps de lecture et d’écriture optimaux.
Si vous exécutez le même flux de données sur un ensemble de fichiers, nous vous recommandons de lire à partir d’un dossier, à l’aide de chemins génériques ou de lecture à partir d’une liste de fichiers. Une seule exécution d’activité de flux de données peut traiter tous vos fichiers par lots. Pour plus d’informations sur la configuration de ces paramètres, consultez la section Transformation source de la documentation du connecteur Stockage Blob Azure .
Si possible, évitez d’utiliser l’activité For-Each pour exécuter des flux de données sur un ensemble de fichiers. Cela aura pour effet que chaque itération de l’activité For-Each lance son propre cluster Spark, ce qui n’est souvent pas nécessaire et peut s’avérer onéreux.
Jeux de données inline et jeux de données partagés
Les jeux de données ADF et Synapse sont des ressources partagées dans vos fabriques et espaces de travail. Toutefois, lorsque vous lisez un grand nombre de dossiers et de fichiers sources avec du texte délimité et des sources JSON, vous pouvez améliorer les performances de la découverte de fichiers de flux de données en définissant l’option « Schéma projeté par l’utilisateur » dans la projection | Boîte de dialogue Options de schéma. Cette option désactive la découverte automatique du schéma par défaut d’ADF et améliore considérablement les performances de la découverte de fichiers. Avant de définir cette option, veillez à importer la projection afin que ADF dispose d’un schéma existant pour la projection. Cette option ne fonctionne pas avec la dérive de schéma.
Contenu connexe
- Vue d’ensemble des performances du flux de données
- Optimisation des puits
- Optimisation des transformations
- Utilisation de flux de données dans des pipelines
Consultez d’autres articles de flux de données liés aux performances :