Activité Power Query dans Azure Data Factory
L’activité Power Query vous permet de créer et d’exécuter des agrégateurs Power Query pour exécuter du data wrangling à grande échelle dans un pipeline Data Factory. Vous pouvez créer un agrégateur Power Query à partir de l’option de menu Nouvelles ressources ou en ajoutant une activité Power Query à votre pipeline.
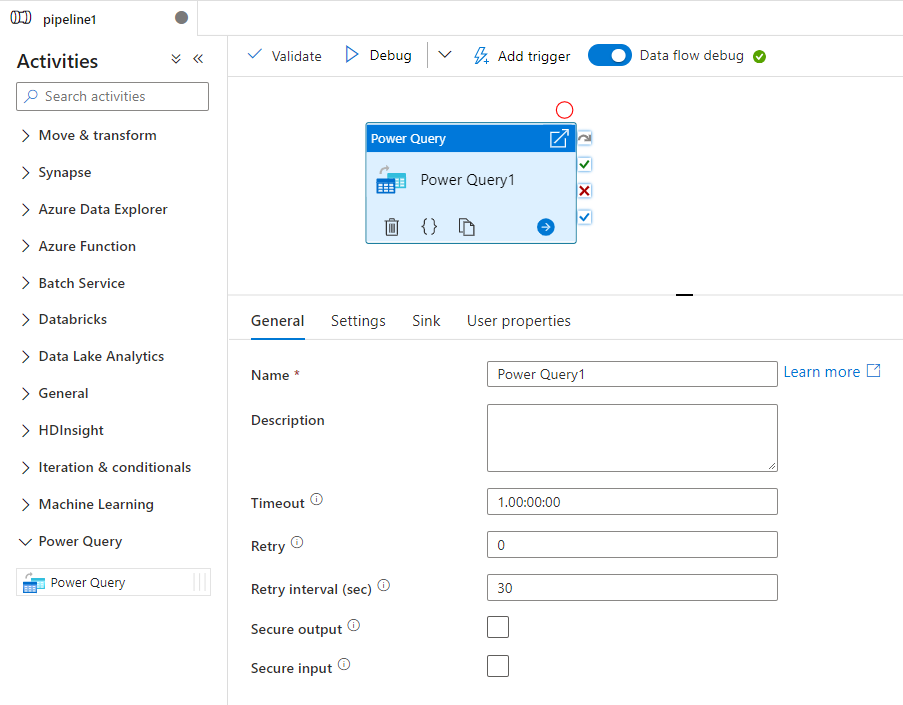
Vous pouvez travailler directement dans l’éditeur d’agrégation Power Query pour effectuer une exploration interactive des données, puis enregistrer votre travail. Une fois l’opération terminée, vous pouvez prendre votre activité Power Query et l’ajouter à un pipeline. Azure Data Factory effectuera automatiquement un scale-out et rendra opérationnel votre data wrangling à l’aide de l’environnement Spark de flux de données d’Azure Data Factory.
Créer une activité Power Query avec l’interface utilisateur
Pour utiliser une activité Power Query dans un pipeline, effectuez les étapes suivantes :
Recherchez Power Query dans le volet Activités du pipeline, puis faites glisser une activité Power Query vers le canevas du pipeline.
Sélectionnez la nouvelle activité Power Query sur le canevas si elle ne l’est pas déjà, et son onglet Paramètres pour modifier ses détails.
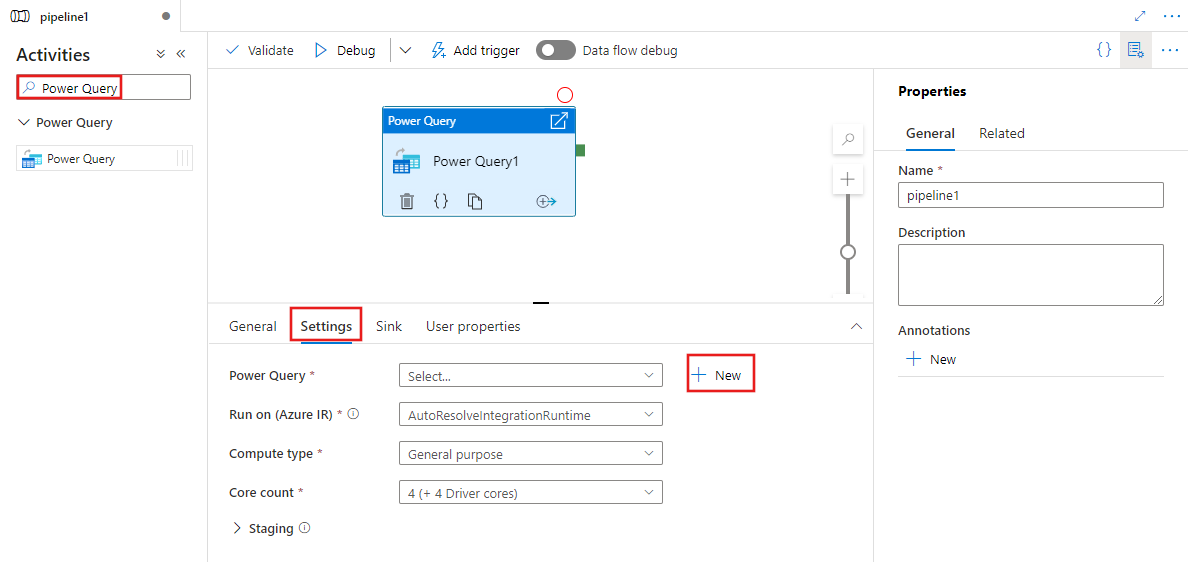
Sélectionnez une requête Power Query existante et sélectionnez Ouvrir, ou sélectionnez le bouton Nouveau pour ouvrir l’éditeur Power Query et créer une nouvelle requête.
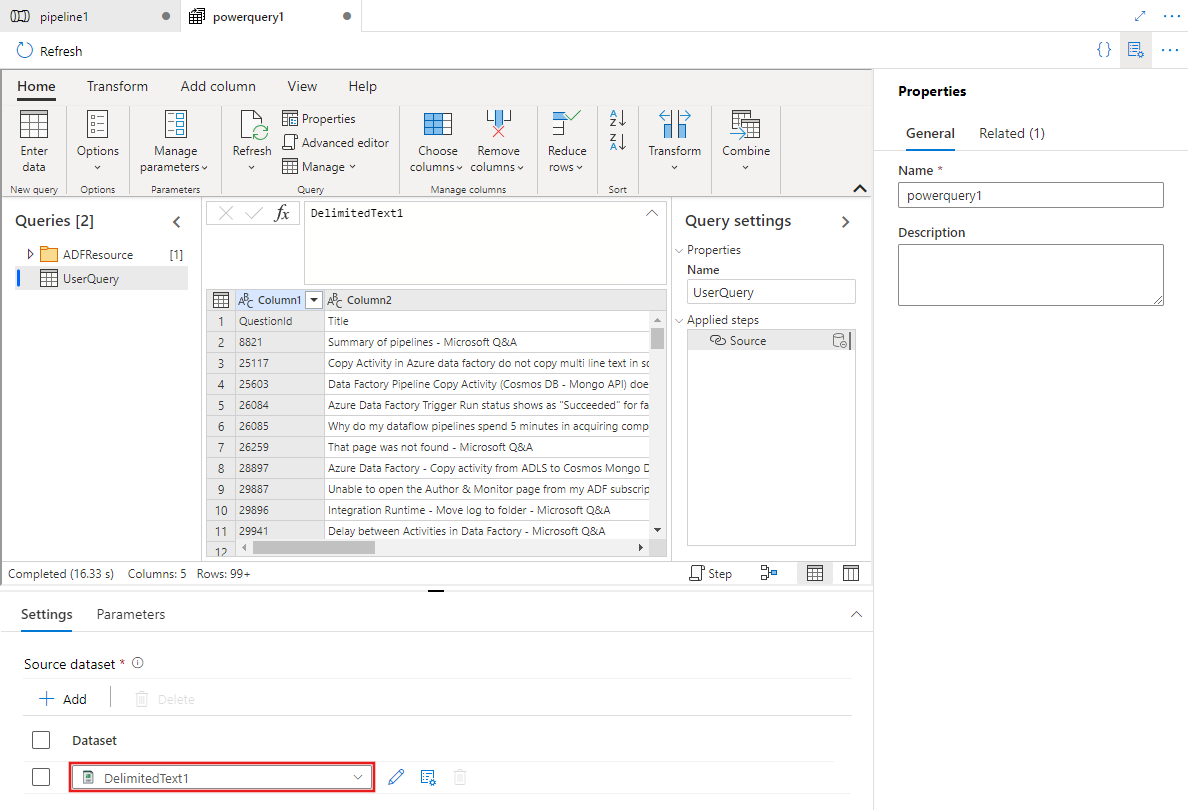
Sélectionnez un jeu de données existant ou sélectionnez Nouveau pour en définir un nouveau. Utilisez les fonctionnalités enrichies de Power Query directement dans l’expérience de modification du pipeline pour transformer le jeu de données en fonction de vos besoins. Vous pouvez ajouter plusieurs requêtes à partir de plusieurs jeux de données dans l’éditeur, et les utiliser par la suite.
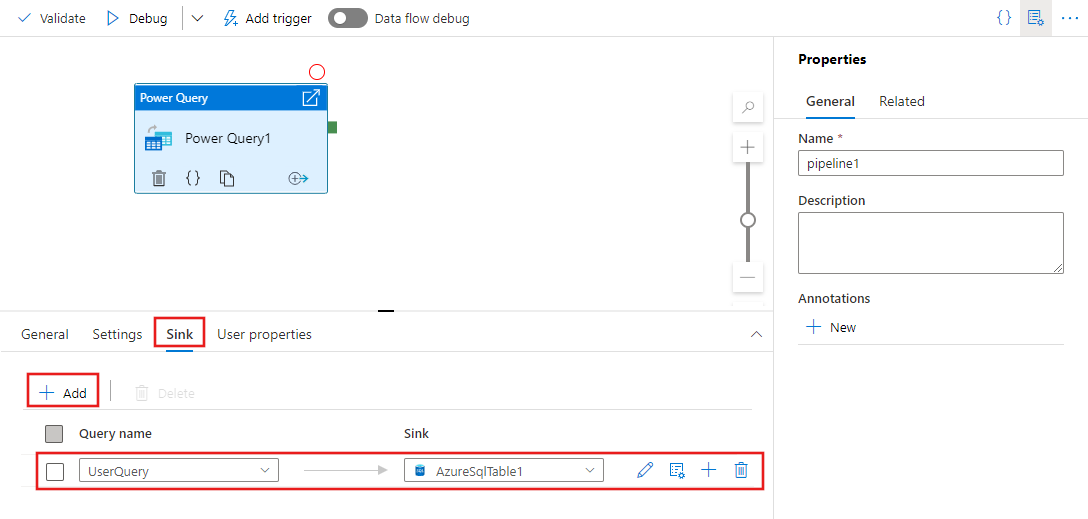
Après avoir défini une ou plusieurs requêtes Power Query au cours de l’étape précédente, vous pouvez également désigner des emplacements de récepteur pour aucune, une ou plusieurs d’entre elles, sous l’onglet Récepteur de l’activité Power Query.
Vous pouvez également utiliser la sortie de votre activité Power Query en tant qu’entrées d’autres activités. Voici un exemple d’activité For Each qui référence la sortie de la requête Power Query définie plus haut pour sa propriété Items. Ses éléments prennent en charge le contenu dynamique, où vous pouvez référencer n’importe quelle sortie de la requête Power Query utilisée comme entrée.
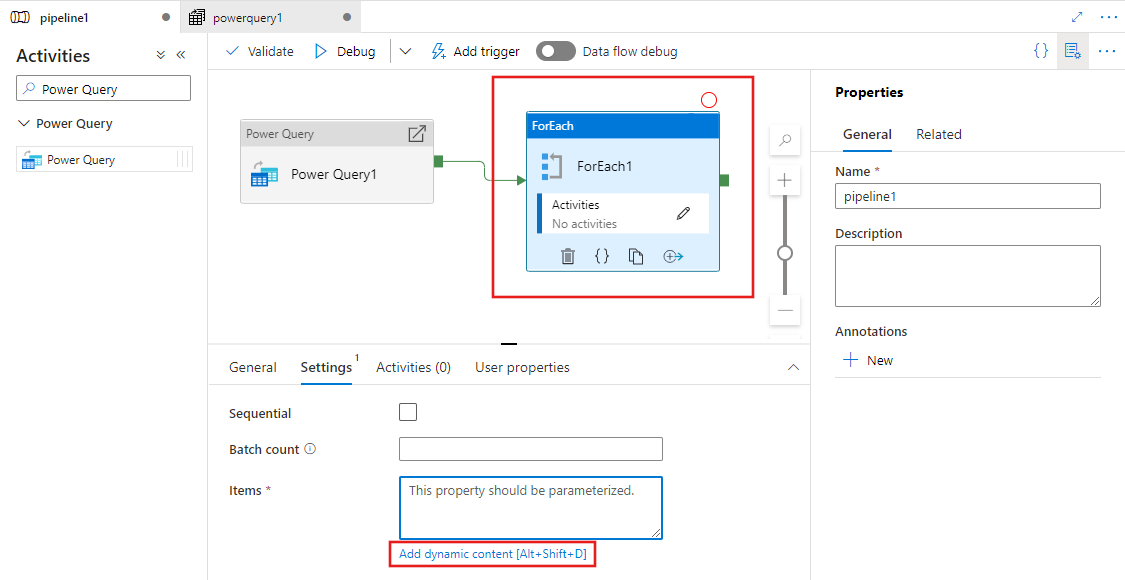
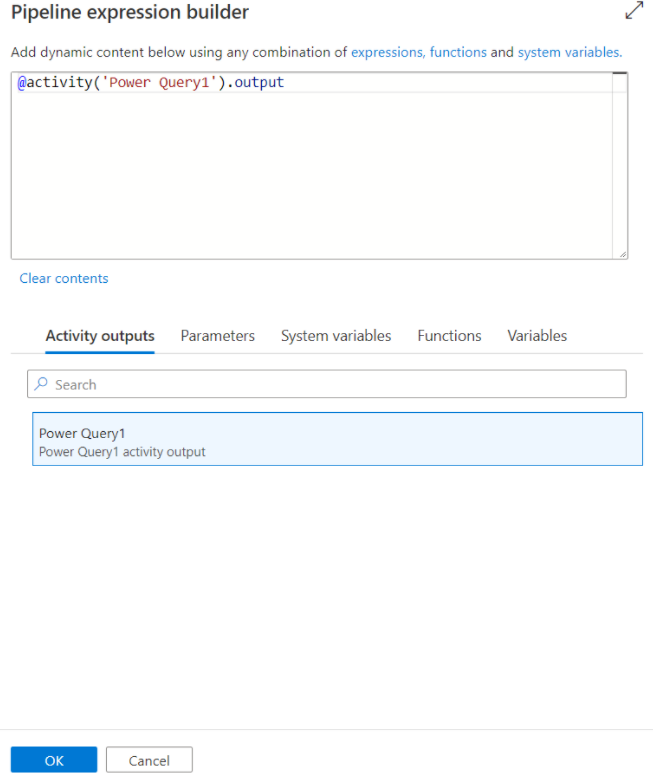
Tous les résultats d’activité sont affichés et peuvent être utilisés lors de la définition de votre contenu dynamique en les sélectionnant dans le volet constructeur d’expressions de pipeline.
Traduction en script de flux de données
Pour atteindre l’échelle avec votre activité Power Query, Azure Data Factory traduit votre script M en script de flux de données afin que vous puissiez exécuter vos Power Query à grande échelle à l’aide de l’environnement Spark de flux de données d’Azure Data Factory. Créez votre flux de données de wrangling à l’aide de la préparation des données sans code. Pour obtenir la liste des fonctions disponibles, consultez les fonctions de transformation.
Paramètres
- Power Query : choisissez une Power Query existante à exécuter ou créez-en une.
- Exécuter sur Azure IR : choisissez un Azure Integration Runtime existant pour définir l’environnement Compute pour votre Power Query ou en créez-en un.
- Type de calcul : si vous choisissez le runtime d’intégration de résolution automatique par défaut, vous pouvez sélectionner le type de calcul à appliquer au calcul de cluster Spark pour votre exécution de Power Query.
- Nombre de cœurs : si vous choisissez le runtime d’intégration de résolution automatique par défaut, vous pouvez sélectionner le nombre de cœurs à appliquer au calcul de cluster Spark pour votre exécution de Power Query.
Récepteur
Choisissez le jeu de données que vous souhaitez utiliser pour le lancement de vos données transformées une fois que le script Power Query M a été exécuté sur Spark. Pour plus d’informations sur la configuration des récepteurs, consultez la documentation sur les récepteurs de flux de données.
Vous avez la possibilité d’envoyer votre sortie vers plusieurs destinations. Cliquez sur le bouton plus (+) pour ajouter d’autres récepteurs à votre requête. Vous pouvez également diriger chaque sortie de requête de votre activité de wrangling Power Query vers différentes destinations.
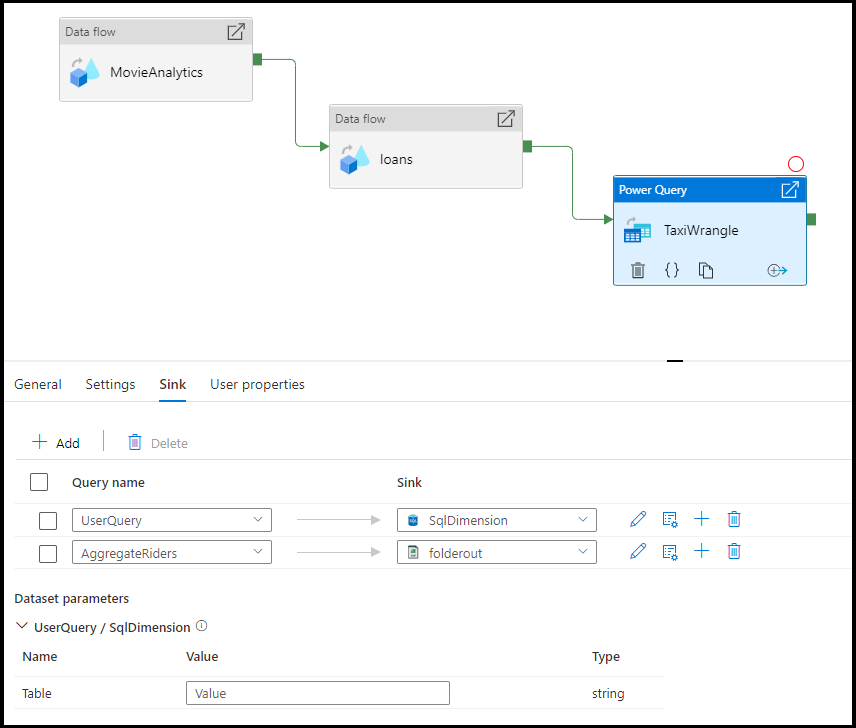
Mappage
Sous l’onglet Mappage, vous pouvez configurer le mappage de colonnes à partir de la sortie de votre activité Power Query vers le schéma cible du récepteur que vous avez choisi. Pour en savoir plus sur le mappage de colonnes, consultez la documentation sur le mappage du récepteur de flux de données.
Contenu connexe
En savoir plus sur les concepts du data wrangling à l’aide de Power Query dans Azure Data Factory