Migrer un schéma de base de données normalisé d’Azure SQL Database vers un conteneur dénormalisé Azure Cosmos DB
Ce guide explique comment prendre un schéma de base de données normalisé existant dans Azure SQL Database et le convertir en un schéma dénormalisé Azure Cosmos DB pour un chargement dans Azure Cosmos DB.
Les schémas SQL sont généralement modélisés à l’aide d’une troisième forme normale, pour aboutir à des schémas normalisés qui fournissent des niveaux élevés d’intégrité des données et moins de valeurs de données dupliquées. Des requêtes peuvent joindre des entités de différentes tables en vue de leur lecture. Azure Cosmos DB est optimisé pour les transactions et requêtes super rapides dans une collection ou un conteneur via des schémas dénormalisés avec des données autonomes dans un document.
En utilisant Azure Data Factory, nous créons un pipeline qui utilise un seul flux de données de mappage pour lire dans deux tables normalisées Azure SQL Database qui contiennent des clés primaires et étrangères comme relation d’entités. Data Factory va joindre ces tables en un seul flux en utilisant le moteur Spark de flux de données, collecter les lignes jointes dans des tableaux et produire des documents individuels nettoyés à insérer dans un nouveau conteneur Azure Cosmos DB.
Ce guide crée à la volée un conteneur nommé « orders » (commandes), qui va utiliser les tables SalesOrderHeader et SalesOrderDetail de l’exemple de base de données standard SQL Server AdventureWorks. Ces tables représentent des transactions de vente jointes par SalesOrderID. Chaque enregistrement de détails a sa propre clé primaire SalesOrderDetailID. La relation entre l’en-tête et le détail est 1:M. Nous effectuons une jointure sur SalesOrderID dans ADF, puis nous plaçons chaque enregistrement de détails associé dans un tableau nommé « detail ».
La requête SQL représentative pour ce guide est la suivante :
SELECT
o.SalesOrderID,
o.OrderDate,
o.Status,
o.ShipDate,
o.SalesOrderNumber,
o.ShipMethod,
o.SubTotal,
(select SalesOrderDetailID, UnitPrice, OrderQty from SalesLT.SalesOrderDetail od where od.SalesOrderID = o.SalesOrderID for json auto) as OrderDetails
FROM SalesLT.SalesOrderHeader o;
Le conteneur Azure Cosmos DB obtenu incorpore la requête interne dans un seul document et se présente comme suit :

Créer un pipeline
Sélectionnez +Nouveau pipeline pour créer un pipeline.
Ajoutez une activité de flux de données.
Dans l’activité de flux de données, sélectionnez Nouveau flux de données de mappage.
Nous construisons ce graphique de flux de données :
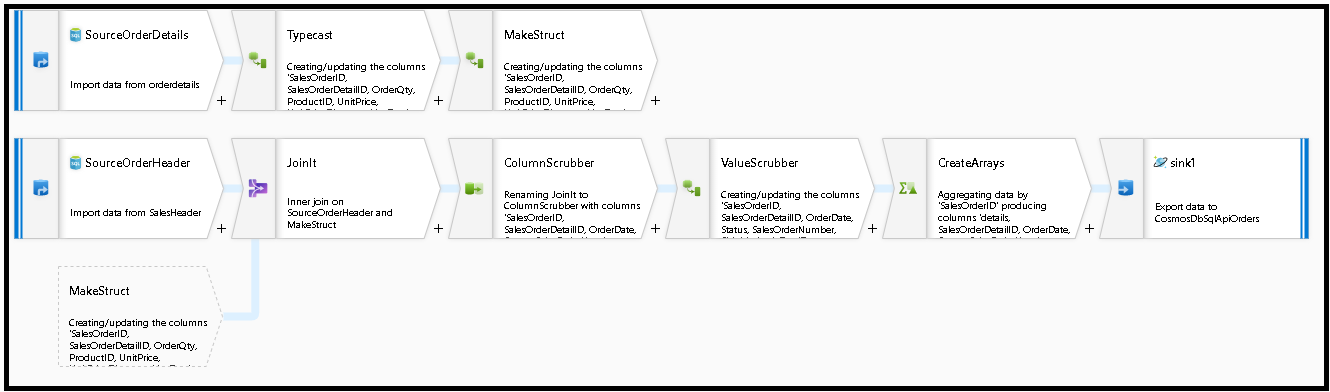
Définissez la source pour « SourceOrderDetails ». Pour dataset, créez un jeu de données Azure SQL Database qui pointe vers la table
SalesOrderDetail.Définissez la source pour « SourceOrderHeader ». Pour dataset, créez un jeu de données Azure SQL Database qui pointe vers la table
SalesOrderHeader.Dans la source supérieure, ajoutez une transformation Colonne dérivée après « SourceOrderDetails ». Appelez la nouvelle transformation « TypeCast ». Nous devons arrondir la colonne
UnitPriceet la caster vers un type de données Double pour Azure Cosmos DB. Définissez la formule sur :toDouble(round(UnitPrice,2)).Ajoutez une autre colonne dérivée nommée « MakeStruct ». C’est là que nous créons une structure hiérarchique pour stocker les valeurs de la table des détails. N’oubliez pas que les détails sont un relation
M:1à l’en-tête. Nommez la nouvelle structureorderdetailsstruct, puis créez la hiérarchie de cette manière, en affectant à chaque sous-colonne le nom de la colonne entrante :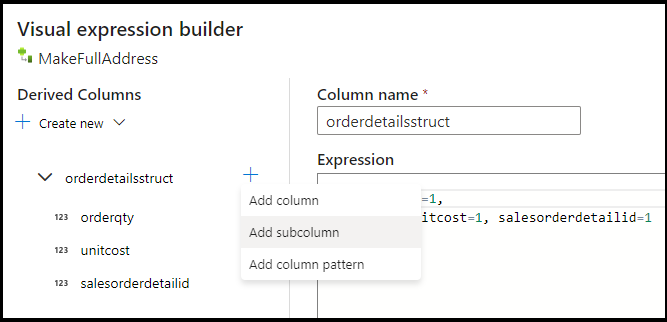
Nous allons maintenant accéder à la source de l’en-tête Sales. Ajoutez une transformation de jointure. Pour le côté droit, sélectionnez « MakeStruct ». Conservez le paramétrage de jointure interne et choisissez
SalesOrderIDpour les deux côtés de la condition de jointure.Sélectionnez l’onglet Aperçu des données dans la nouvelle jointure que vous avez ajoutée pour voir les résultats obtenus à ce stade. Vous devriez voir toutes les lignes d’en-tête jointes avec les lignes de détails. Il s’agit du résultat de la jointure formée à partir de
SalesOrderID. Ensuite, nous allons combinons les détails des lignes communes dans le struct des détails et nous agrégeons les lignes communes.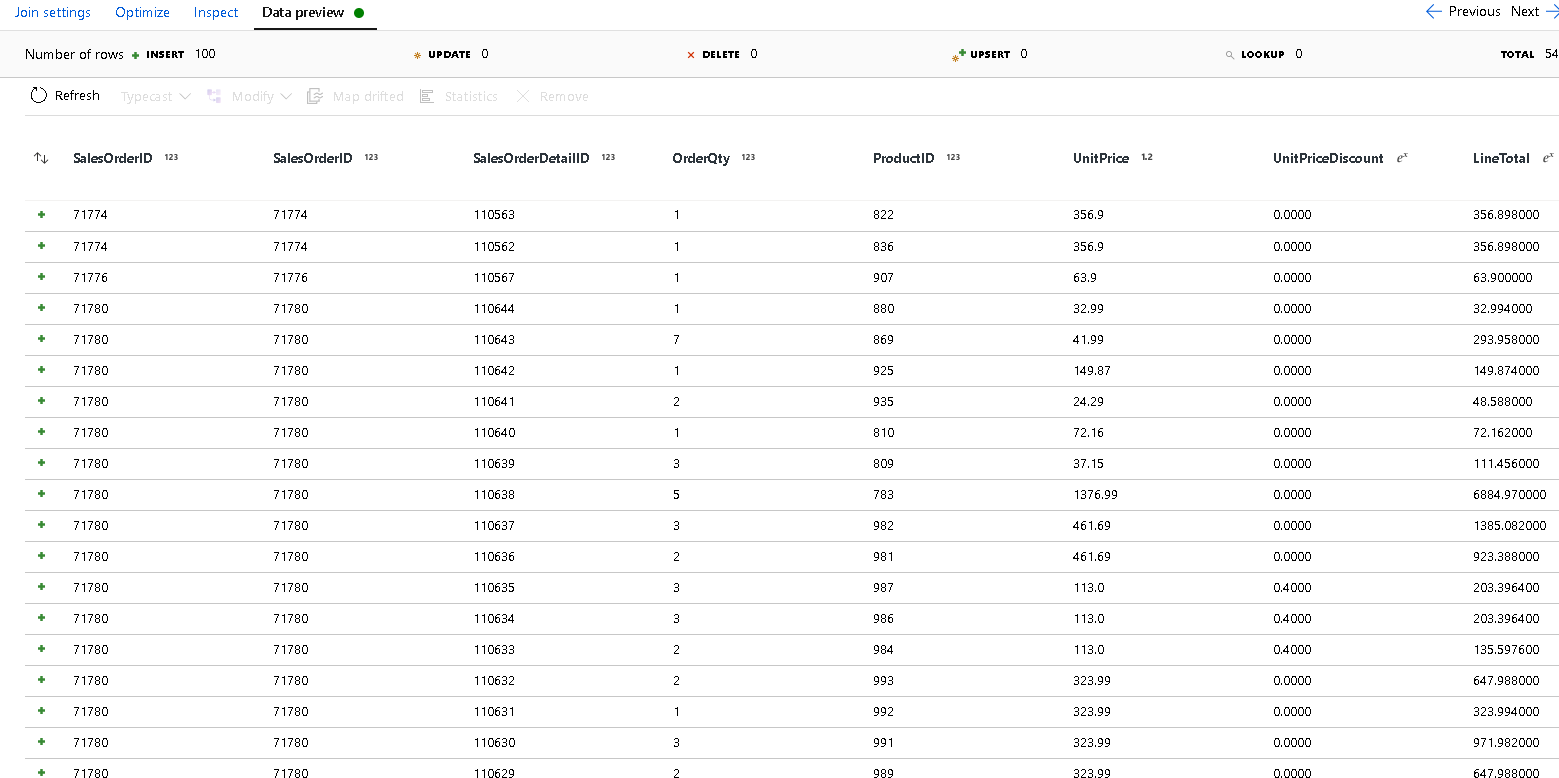
Avant de créer les tableaux pour dénormaliser ces lignes, nous devons supprimer les colonnes inutiles et vérifier que les valeurs de données correspondent aux types de données Azure Cosmos DB.
Ajoutez ensuite une transformation Select et définissez le mappage de champs pour qu’il ressemble à ceci :
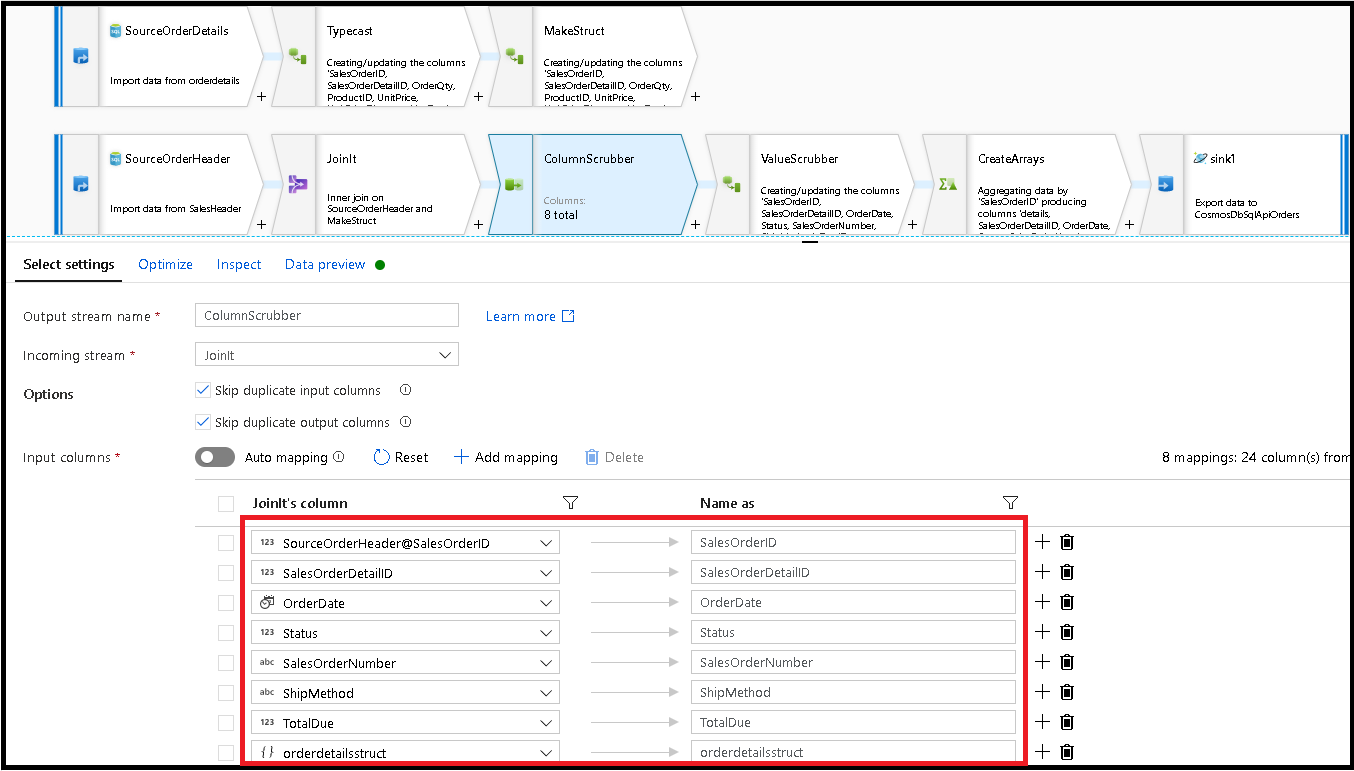
Nous allons maintenant caster à nouveau une colonne de devises, en l’occurrence
TotalDue. Comme à l’étape 7, définissez la formule sur :toDouble(round(TotalDue,2)).C’est ici que nous dénormalisons les lignes en les regroupant par la clé commune
SalesOrderID. Ajoutez une transformation d’agrégation et définissez Grouper par surSalesOrderID.Dans la formule d’agrégation, ajoutez une nouvelle colonne nommée « details » et utilisez cette formule pour collecter les valeurs dans la structure que nous avons créée précédemment, nommée
orderdetailsstruct:collect(orderdetailsstruct).La transformation d’agrégation génère uniquement des colonnes qui font partie de formules d’agrégation ou de regroupement. Par conséquent, nous devons également inclure les colonnes de l’en-tête sales. Pour ce faire, ajoutez un modèle de colonne dans la même transformation d’agrégation. Ce modèle inclut toutes les autres colonnes de la sortie, à l’exclusion des colonnes listées ci-dessous (OrderQty, UnitPrice et SalesOrderID) :
instr(name,'OrderQty')==0&&instr(name,'UnitPrice')==0&&instr(name,'SalesOrderID')==0
Utilisez la syntaxe « this » ($$) dans les autres propriétés afin de conserver les mêmes noms de colonne, et utilisez la fonction
first()en tant qu’agrégat : Cela indique à ADF de conserver la première valeur correspondante trouvée :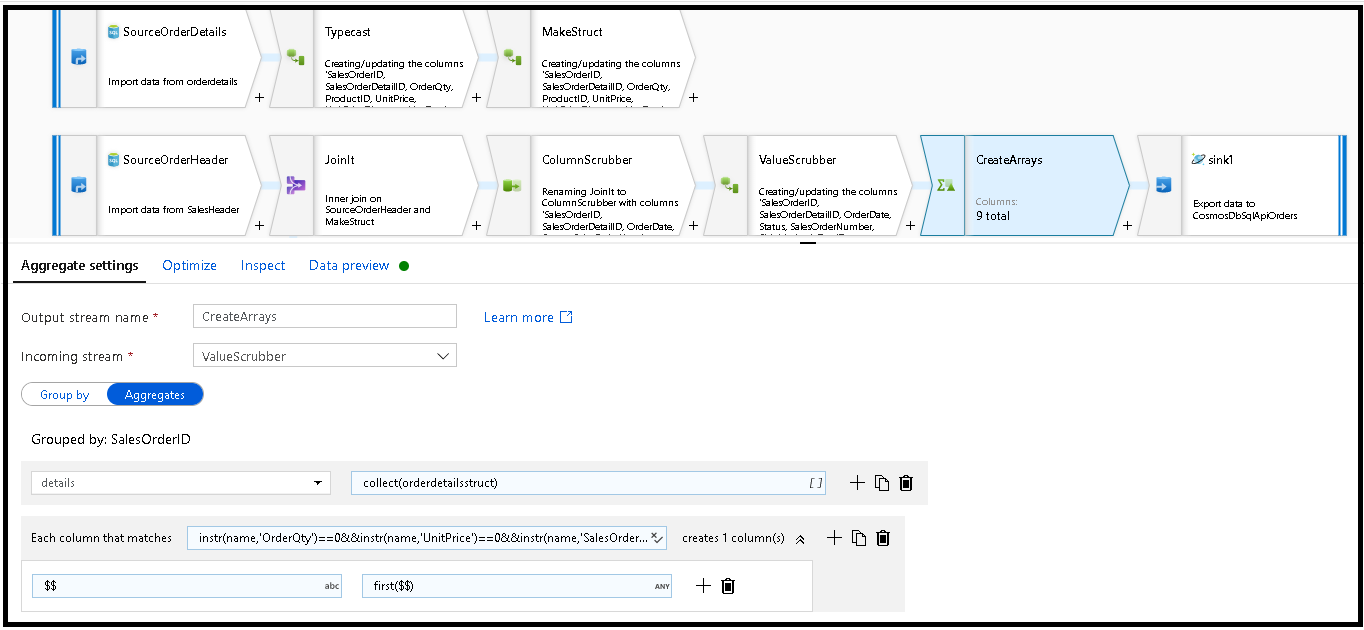
Nous sommes prêts à terminer le flux de migration en ajoutant une transformation de récepteur. Sélectionnez « Nouveau » en regard du jeu de données, puis ajoutez un jeu de données Azure Cosmos DB qui pointe vers votre base de données Azure Cosmos DB. Pour la collection, nous l’appelons « orders » ; elle n’a pas de schéma et pas de documents, car elle sera créée à la volée.
Dans Paramètres du récepteur, définissez la Clé de partition sur
/SalesOrderIDet l’action de collection sur « recréer ». Assurez-vous que l’onglet Mappage ressemble à ceci :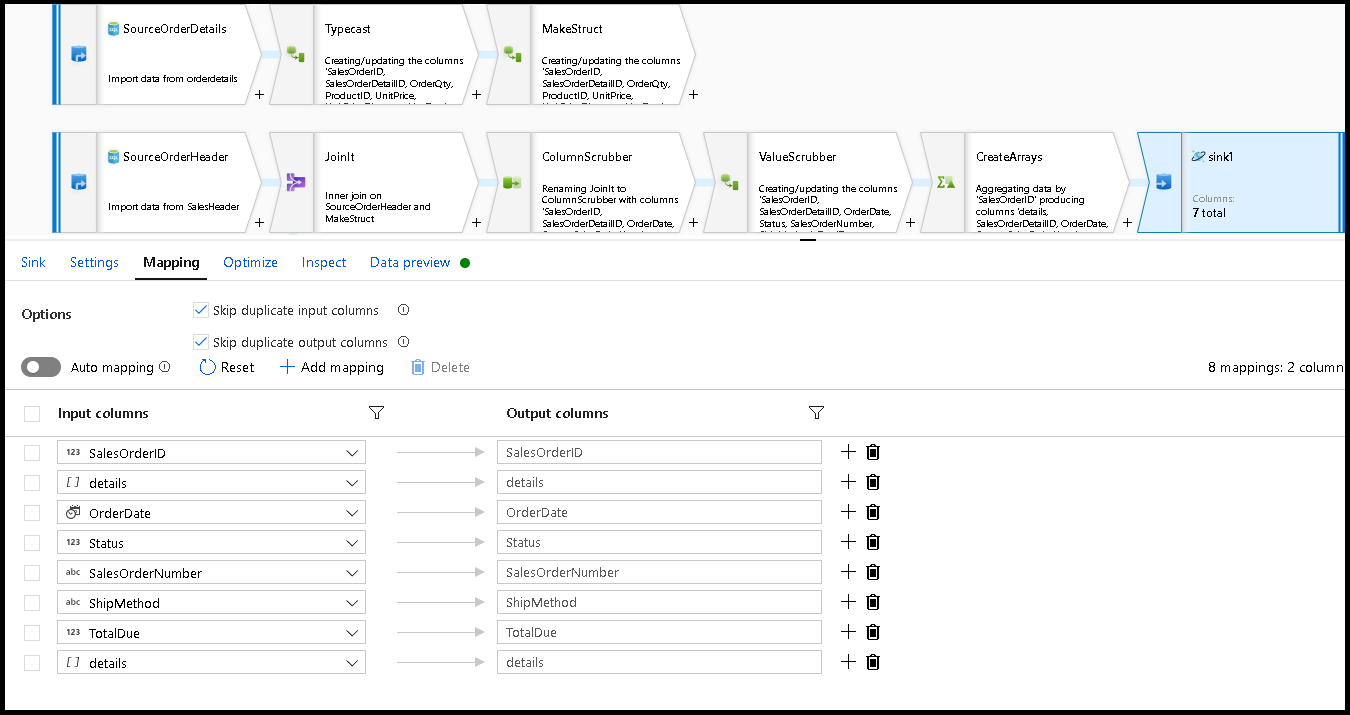
Sélectionnez l’aperçu des données pour vérifier que vous voyez ces 32 lignes prêtes pour être insérées en tant que nouveaux documents dans votre nouveau conteneur :
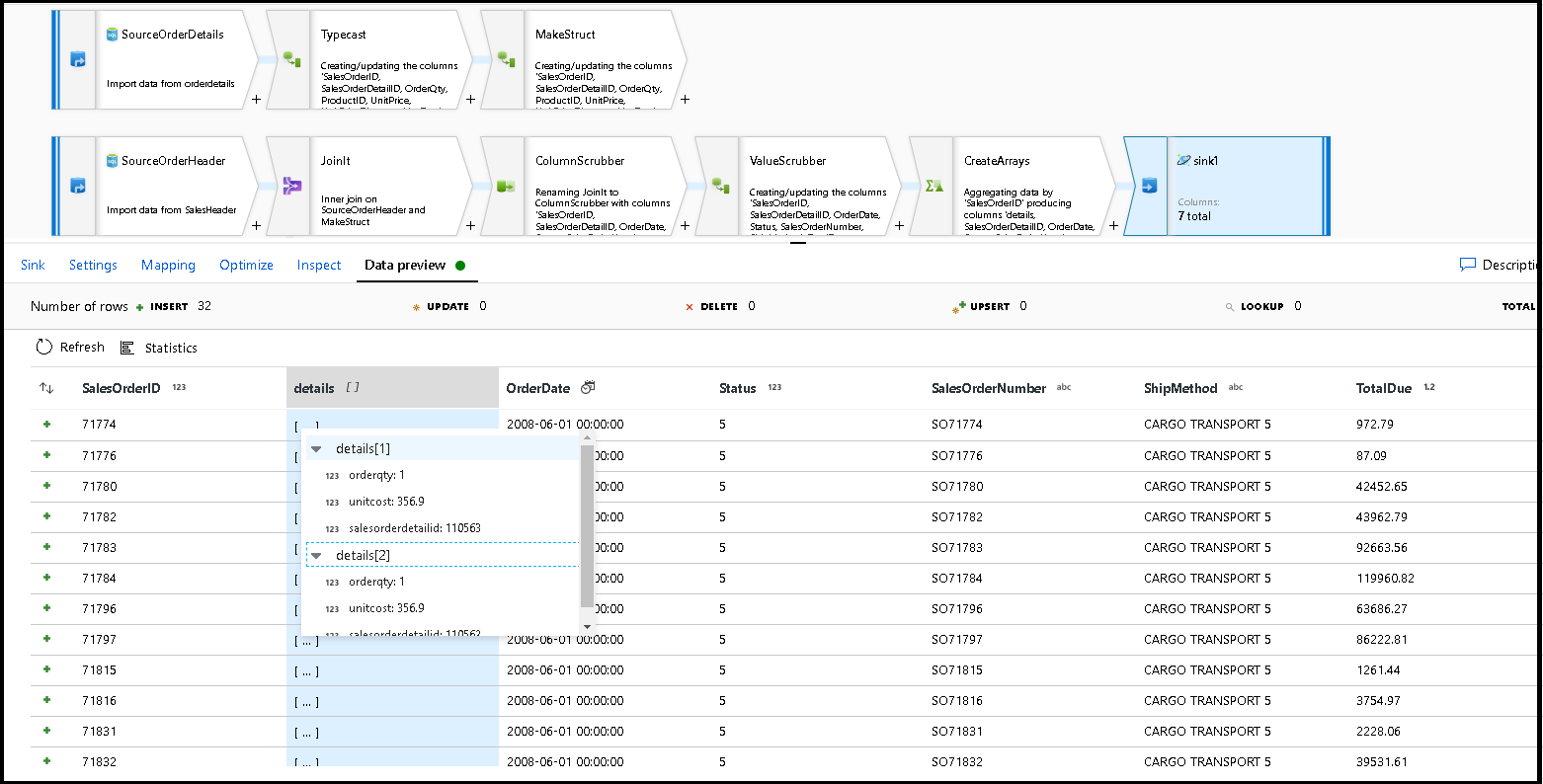
Si tout semble correct, vous êtes prêt à créer un pipeline, à y ajouter cette activité de flux de données et à l’exécuter. Vous pouvez l’exécuter à partir d’un débogage ou d’une exécution déclenchée. Après quelques minutes, vous devriez avoir un nouveau conteneur dénormalisé de commandes nommé « orders » dans votre base de données Azure Cosmos DB.
Contenu connexe
- Créez le reste de votre logique de flux de données à l’aide de transformations de flux de données de mappage.
- Téléchargez le modèle de pipeline terminé pour ce didacticiel et importez-le dans votre fabrique.