Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Data Factory dans Microsoft Fabric est la prochaine génération de Azure Data Factory, avec une architecture plus simple, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'intégration des données, commencez par Fabric Data Factory. Les charges de travail ADF existantes peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Cet article décrit un modèle de solution que vous pouvez utiliser pour extraire des données d’une source PDF à l’aide de Azure Data Factory et de Azure Document Intelligence dans Foundry Tools.
À propos de ce modèle de solution
Ce modèle analyse les données d’une source d’URL PDF à l’aide de deux appels Document Intelligence. Ensuite, il transforme la sortie en tables lisibles dans un flux de données et génère les données dans un récepteur de stockage.
Ce modèle comporte deux activités :
- Activité web pour appeler l’API de modèle de lecture prédéfinie de Document Intelligence
- Flux de données pour transformer des données extraites au format PDF
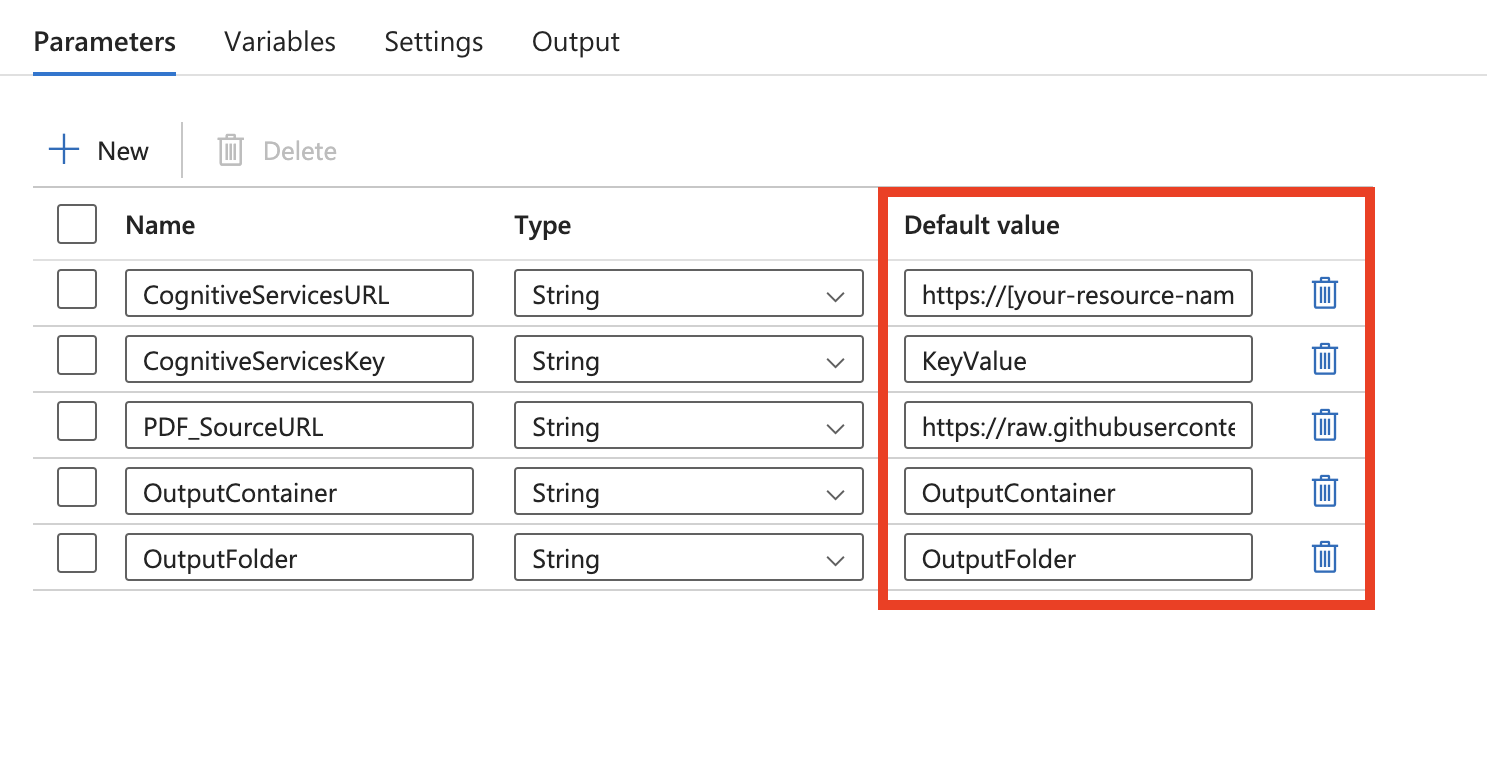
Ce modèle définit cinq paramètres :
- CognitiveServicesURL est l’URL Document Intelligence (« https://{endpoint}/formrecognizer/v2.1/layout/analyze »). Remplacez {endpoint} par le point de terminaison que vous avez obtenu avec votre abonnement Document Intelligence. Vous devez remplacer la valeur par défaut par votre propre URL.
- CognitiveServicesKey est la clé d’abonnement Document Intelligence. Vous devez remplacer la valeur par défaut par votre propre clé d’abonnement.
- PDF_SourceURL est l’URL de votre source PDF. Vous devez remplacer la valeur par défaut par votre propre URL.
- OutputContainer est le nom du chemin d’accès au conteneur dans lequel vous souhaitez que vos fichiers se trouvent dans votre magasin de destination. Vous devez remplacer la valeur par défaut par votre propre conteneur.
- OutputFolder est le nom du chemin d’accès au dossier dans lequel vous souhaitez que vos fichiers se trouvent dans votre magasin de destination. Vous devez remplacer la valeur par défaut par votre propre chemin d’accès au dossier.
Prérequis
- URL et clé du point d'accès de ressource Document Intelligence (créez une nouvelle ressource ici)
Utiliser ce modèle de solution
Accédez au modèle Extraire des données à partir d’un PDF. Créez une connexion à votre ressource Document Intelligence ou choisissez une connexion existante.
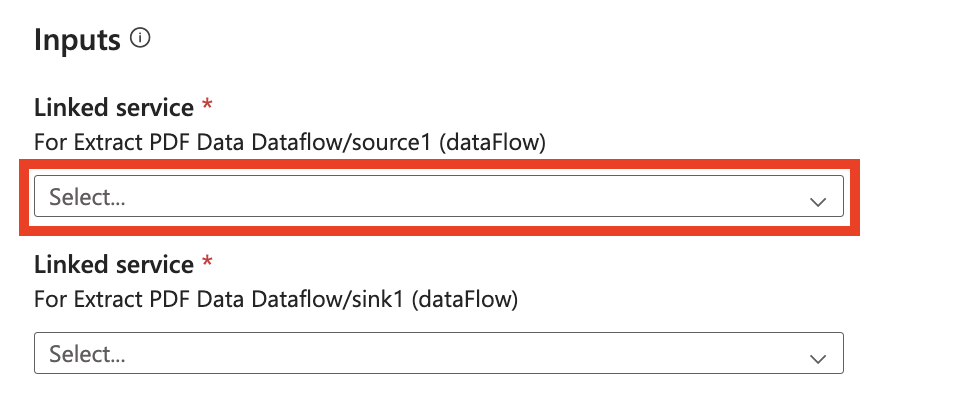
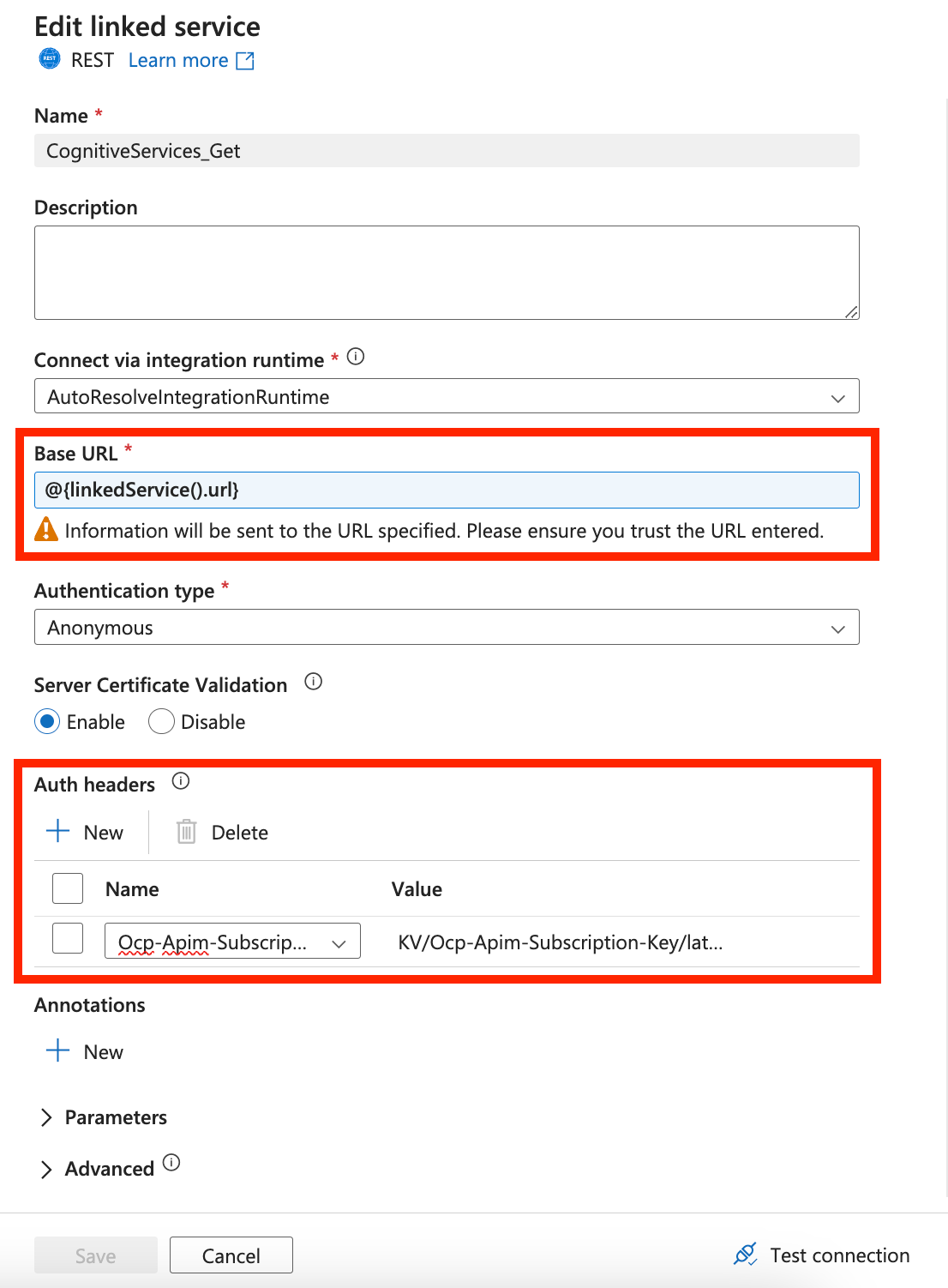
Dans votre connexion à Document Intelligence, veillez à ajouter un paramètre de service lié. Vous devez utiliser ce paramètre url comme URL de base dynamique. Vous devez également ajouter un nouvel en-tête d’authentification sous En-têtes d’authentification. Le nom doit être Ocp-Apim-Subscription-Key et la valeur doit être la valeur de clé que vous trouvez à partir de votre ressource Azure.
Créez une nouvelle connexion à votre magasin de stockage de destination ou choisissez une connexion existante. La destination choisie est l’emplacement de stockage des données PDF extraites.

Sélectionnez Utiliser ce modèle.
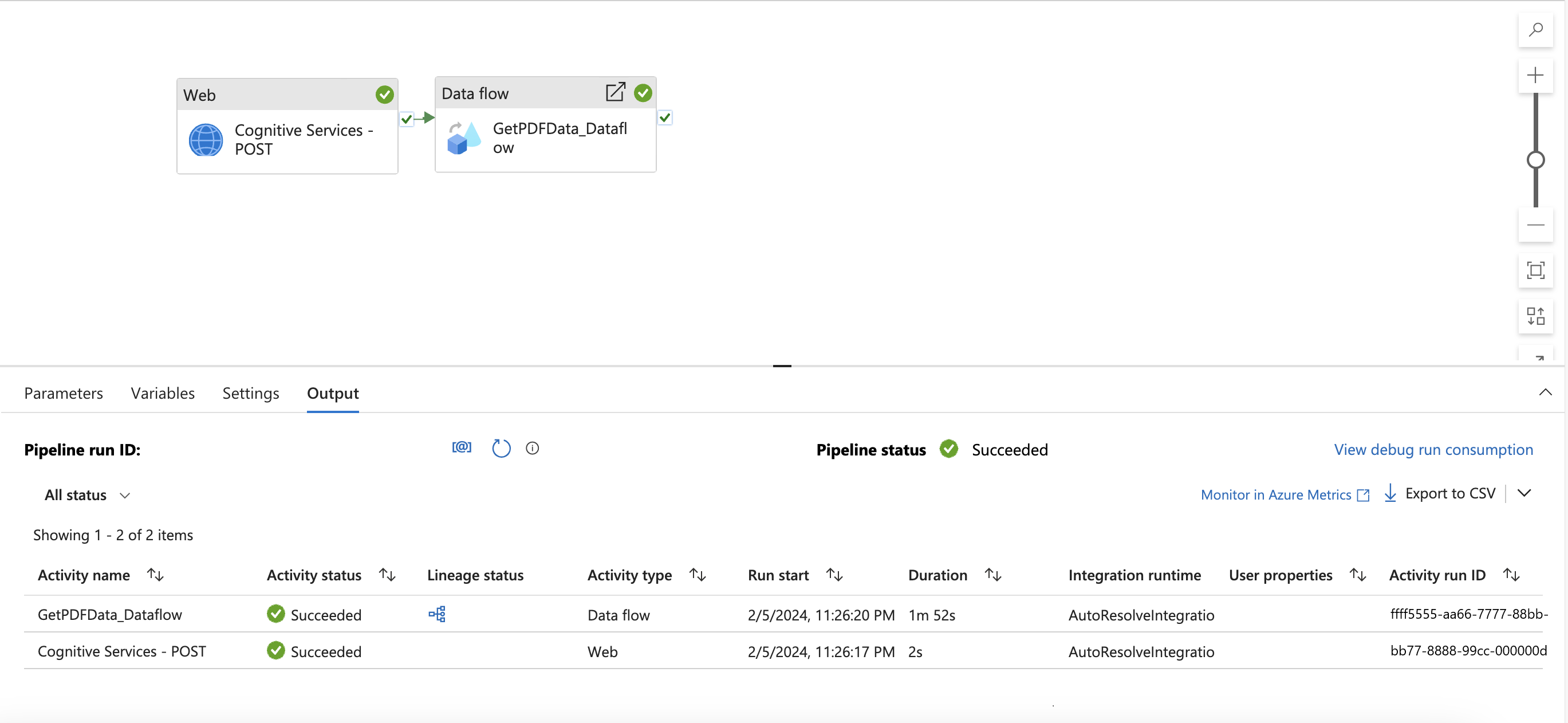
Le pipeline suivant doit s’afficher.
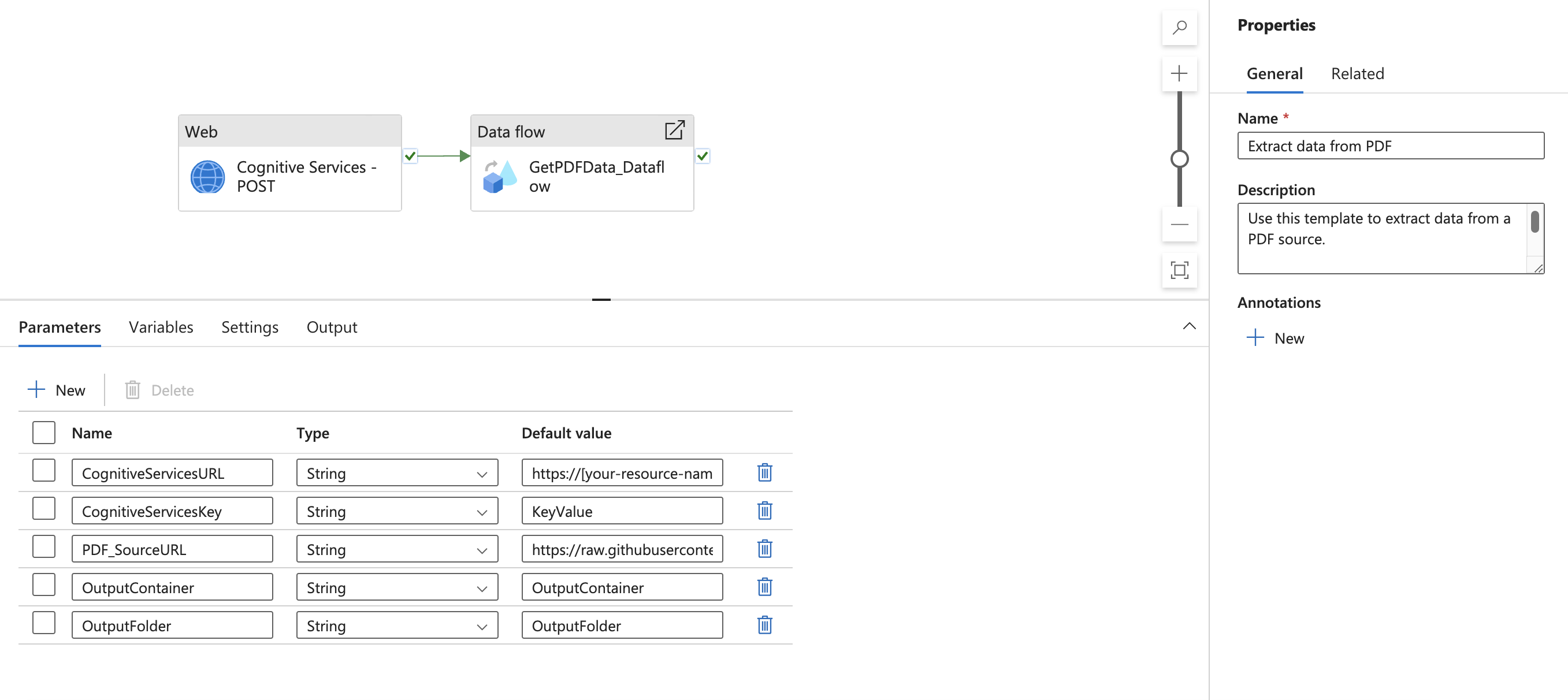
Accédez à l’activité Flux de données et recherchez Paramètres. Ici, vous devez ajouter du contenu dynamique pour le paramètre url de votre service lié. Après avoir cliqué sur Ajouter du contenu dynamique, le générateur d’expressions de pipeline s’ouvre. Sélectionnez Cognitive Services – Sortie d’activité POST. Ensuite, tapez ou copiez et collez « .output.ADFWebActivityResponseHeaders['Operation-Location']. » L’expression suivante doit alors figurer dans votre générateur d’expressions.
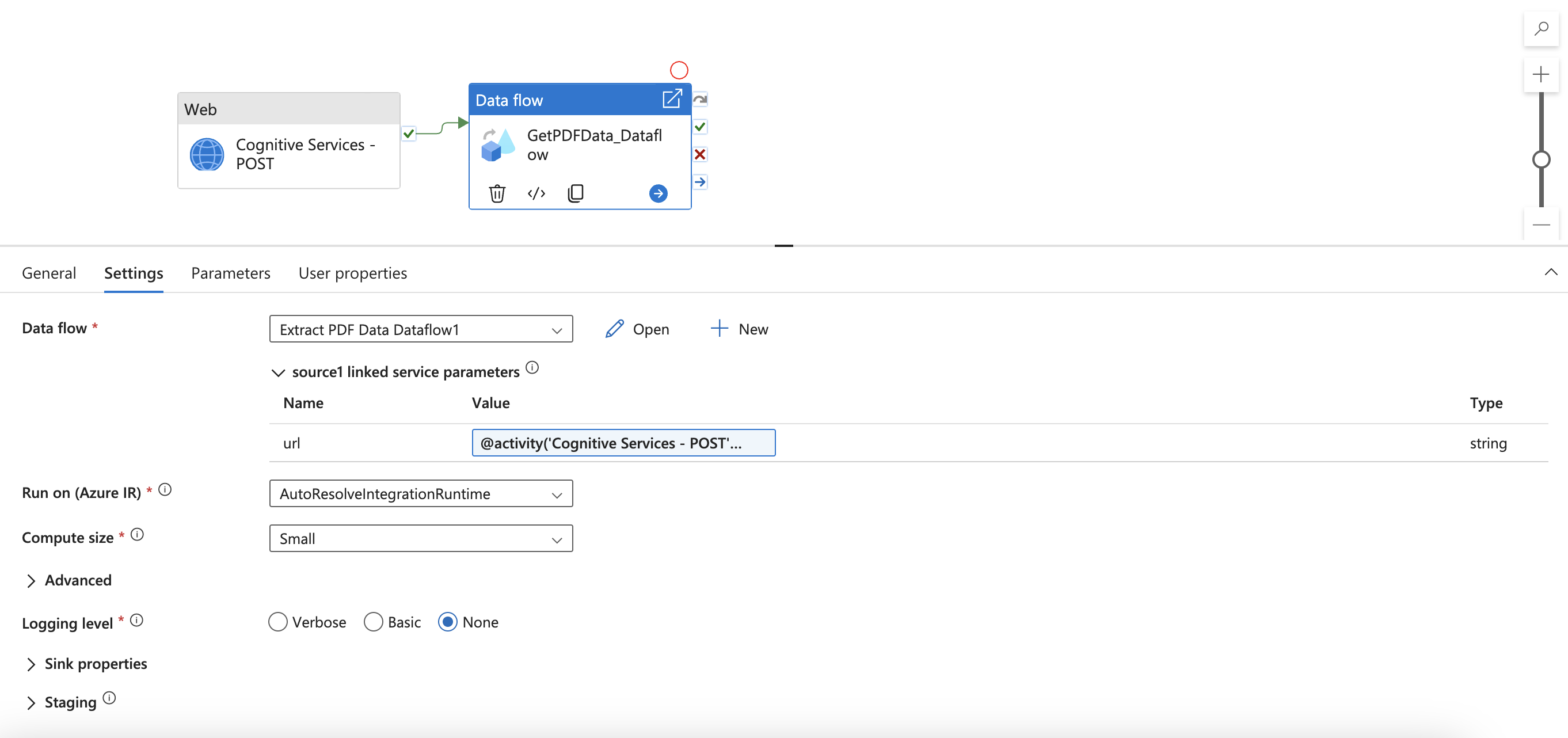
Cliquez sur OK pour revenir au pipeline.
Sélectionnez ensuite Déboguer.
Entrez des valeurs de paramètre, passez en revue les résultats et publiez.