Déployer une charge de travail IoT Edge avec le partage GPU sur votre Azure Stack Edge Pro.
Cet article décrit comment les charges de travail en conteneur peuvent partager les GPU sur votre appareil GPU Azure Stack Edge Pro. L’approche implique l’activation de Multi-Process Service (MPS), puis la spécification des charges de travail GPU via un déploiement de IoT Edge.
Prérequis
Avant de commencer, assurez-vous que :
Vous avez accès à un appareil GPU Azure Stack Edge Pro qui est activé et sur lequel est configuré le calcul. Vous avez le point de terminaison de l’API Kubernetes et vous avez ajouté ce point de terminaison au fichier
hostssur votre client qui accédera à l’appareil.Vous avez accès à un système client avec un système d’exploitation pris en charge. Si vous utilisez un client Windows, le système doit exécuter PowerShell 5.0 ou une version ultérieure pour accéder à l’appareil.
Enregistrez le fichier
jsonde déploiement suivant sur votre système local. Vous utiliserez les informations de ce fichier pour exécuter le déploiement IoT Edge. Ce déploiement est basé sur des conteneurs CUDA simples qui sont disponibles publiquement auprès de NVIDIA.{ "modulesContent": { "$edgeAgent": { "properties.desired": { "modules": { "cuda-sample1": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" }, "cuda-sample2": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" } }, "runtime": { "settings": { "minDockerVersion": "v1.25" }, "type": "docker" }, "schemaVersion": "1.1", "systemModules": { "edgeAgent": { "settings": { "image": "mcr.microsoft.com/azureiotedge-agent:1.0", "createOptions": "" }, "type": "docker" }, "edgeHub": { "settings": { "image": "mcr.microsoft.com/azureiotedge-hub:1.0", "createOptions": "{\"HostConfig\":{\"PortBindings\":{\"443/tcp\":[{\"HostPort\":\"443\"}],\"5671/tcp\":[{\"HostPort\":\"5671\"}],\"8883/tcp\":[{\"HostPort\":\"8883\"}]}}}" }, "type": "docker", "status": "running", "restartPolicy": "always" } } } }, "$edgeHub": { "properties.desired": { "routes": { "route": "FROM /messages/* INTO $upstream" }, "schemaVersion": "1.1", "storeAndForwardConfiguration": { "timeToLiveSecs": 7200 } } }, "cuda-sample1": { "properties.desired": {} }, "cuda-sample2": { "properties.desired": {} } } }
Vérifier le pilote GPU, version CUDA
La première étape consiste à vérifier que votre appareil exécute les versions de pilote GPU et CUDA requises.
Connectez-vous à l’interface PowerShell de votre appareil.
Exécutez la commande suivante :
Get-HcsGpuNvidiaSmiDans la sortie SMI NVIDIA, prenez note de la version du GPU et de la version de CUDA sur votre appareil. Si vous exécutez le logiciel Azure Stack Edge 2102, cette version correspond aux versions de pilote suivantes :
- Version du pilote GPU : 460.32.03
- Version CUDA : 11.2
Voici un exemple de sortie :
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Tue Feb 23 10:34:01 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 0000041F:00:00.0 Off | 0 | | N/A 40C P8 15W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Conservez cette session ouverte, car vous allez l’utiliser pour afficher la sortie SMI NVIDIA tout au long de l’article.
Déployer sans partage de contexte
Vous pouvez maintenant déployer une application sur votre appareil lorsque Multi-Process Service n’est pas en cours d’exécution et qu’il n’existe pas de partage de contexte. Le déploiement s’effectue via le portail Azure dans l’espace de noms iotedge qui existe sur votre appareil.
Créer un utilisateur dans l’espace de noms IoT Edge
Vous allez commencer par créer un utilisateur qui se connectera à l’espace de noms iotedge. Les modules IoT Edge sont déployés dans l’espace de noms iotedge. Pour plus d’informations, consultez la section Espace de noms Kubernetes sur votre appareil.
Procédez comme suit pour créer un utilisateur et lui accorder l’accès à l’espace de noms iotedge.
Connectez-vous à l’interface PowerShell de votre appareil.
Créez un nouvel utilisateur dans l’espace de noms
iotedge. Exécutez la commande suivante :New-HcsKubernetesUser -UserName <user name>Voici un exemple de sortie :
[10.100.10.10]: PS>New-HcsKubernetesUser -UserName iotedgeuser apiVersion: v1 clusters: - cluster: certificate-authority-data: ===========================//snipped //======================// snipped //============================= server: https://compute.myasegpudev.wdshcsso.com:6443 name: kubernetes contexts: - context: cluster: kubernetes user: iotedgeuser name: iotedgeuser@kubernetes current-context: iotedgeuser@kubernetes kind: Config preferences: {} users: - name: iotedgeuser user: client-certificate-data: ===========================//snipped //======================// snipped //============================= client-key-data: ===========================//snipped //======================// snipped ============================ PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=Copiez la sortie affichée en texte brut. Enregistrez la sortie sous la forme d’un fichier de configuration (sans extension) dans le dossier
.kubede votre profil utilisateur sur votre ordinateur local, par exempleC:\Users\<username>\.kube.Accordez à l’utilisateur que vous avez créé l’accès à l’espace de noms
iotedge. Exécutez la commande suivante :Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName <user name>Voici un exemple de sortie :
[10.100.10.10]: PS>Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName iotedgeuser [10.100.10.10]: PS>
Pour connaître les instructions détaillées, consultez Se connecter à un cluster Kubernetes et le gérer par le biais de kubectl sur votre appareil Azure Stack Edge Pro avec GPU.
Déployer des modules via le portail
Déployer des modules IoT Edge à l’aide du portail Azure Vous allez déployer des exemples de modules NVIDIA CUDA disponibles au public qui exécutent la simulation n-body.
Assurez-vous que le service IoT Edge est en cours d’exécution sur votre appareil.
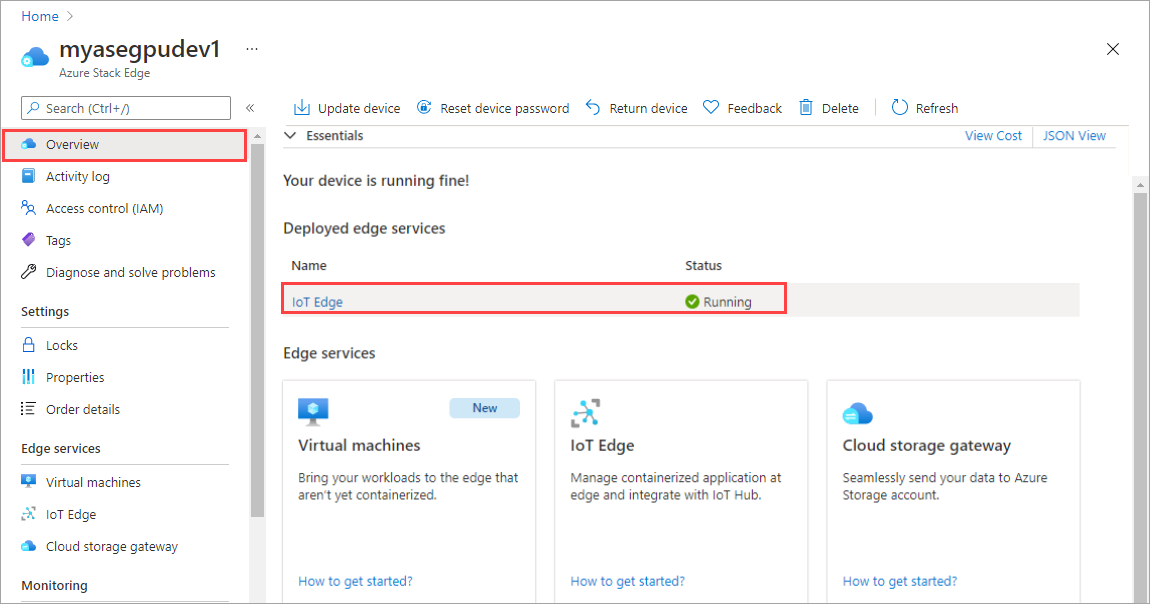
Dans le volet droit, sélectionnez la vignette IoT Edge. Accédez à IoT Edge > Propriétés. Dans le volet droit, sélectionnez la ressource IoT Hub associée à votre appareil.
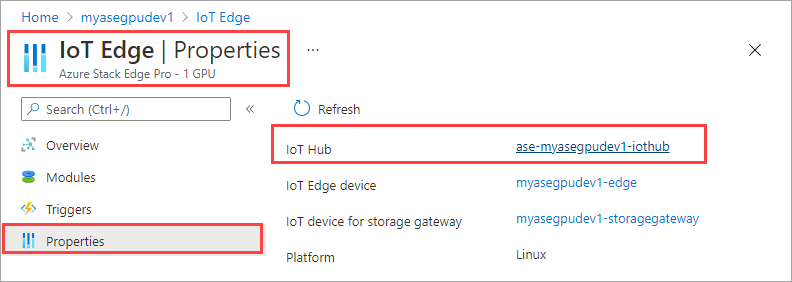
Dans la ressource IoT Hub, accédez à Gestion automatique des appareils > IoT Edge. Dans le volet droit, sélectionnez le service IoT Hub associée à votre appareil.
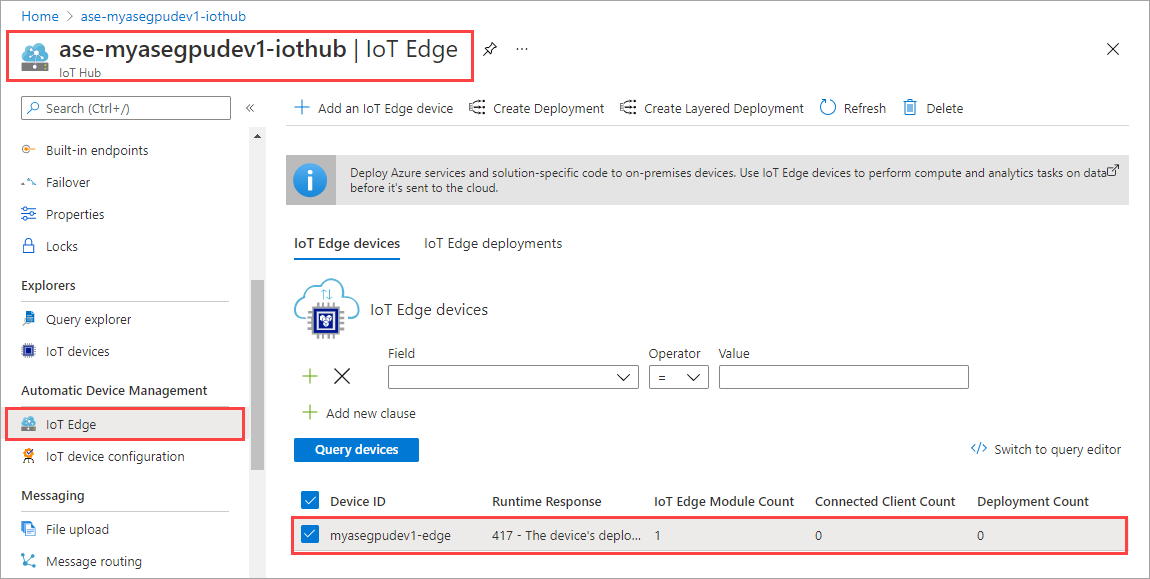
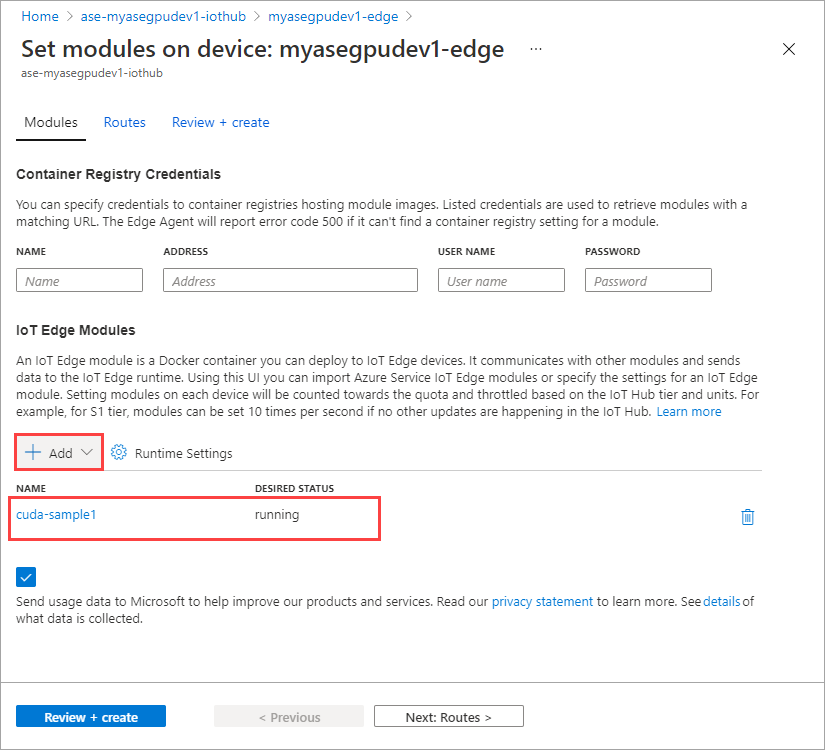
Sélectionnez Définir des modules.
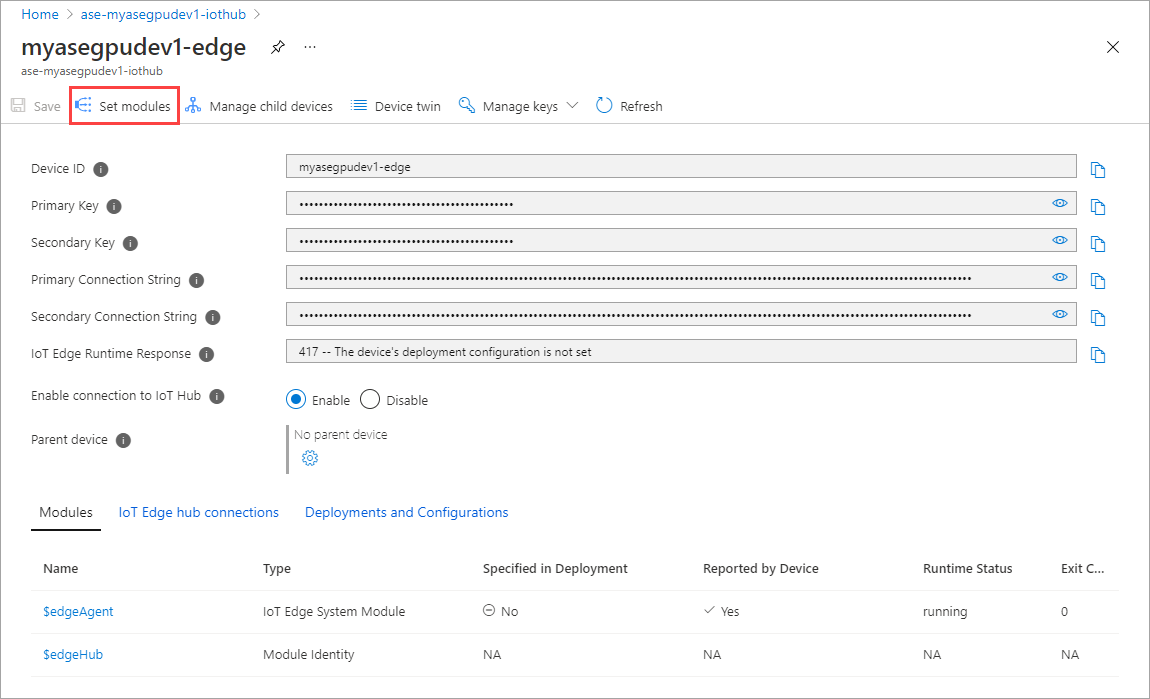
Sélectionnez +Ajouter > + Module IoT Edge.
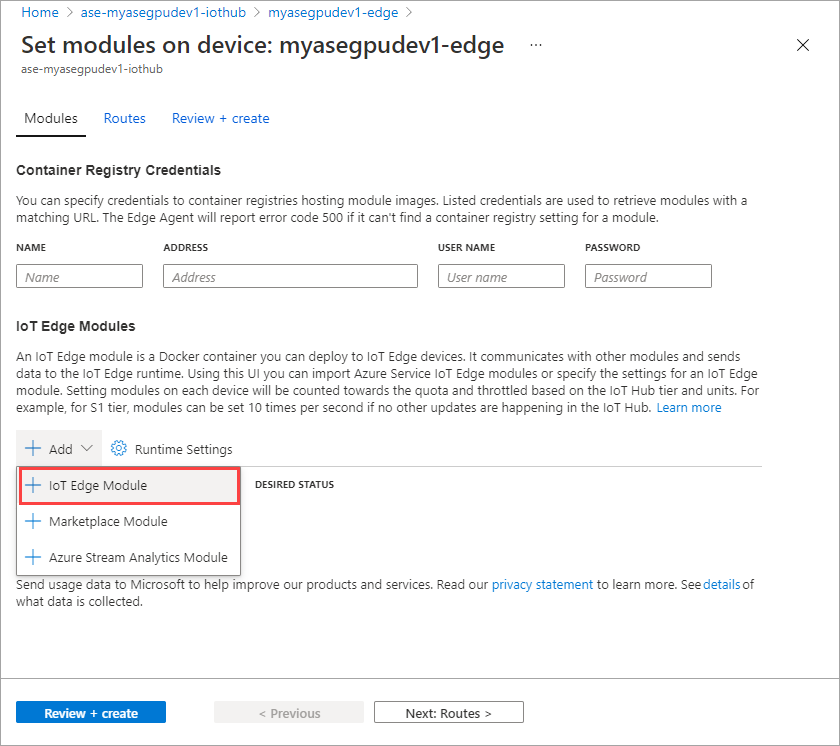
Dans l’onglet Paramètres du module, indiquez le nom du module IoT Edge et l’URI de l’image. Définissez la Stratégie d’extraction d’image sur la valeur Lors de la création.
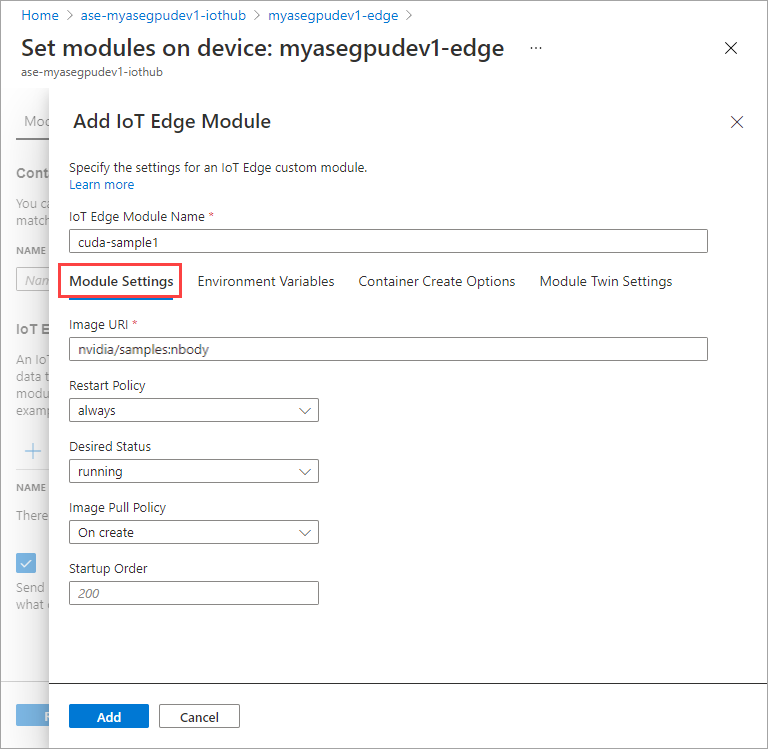
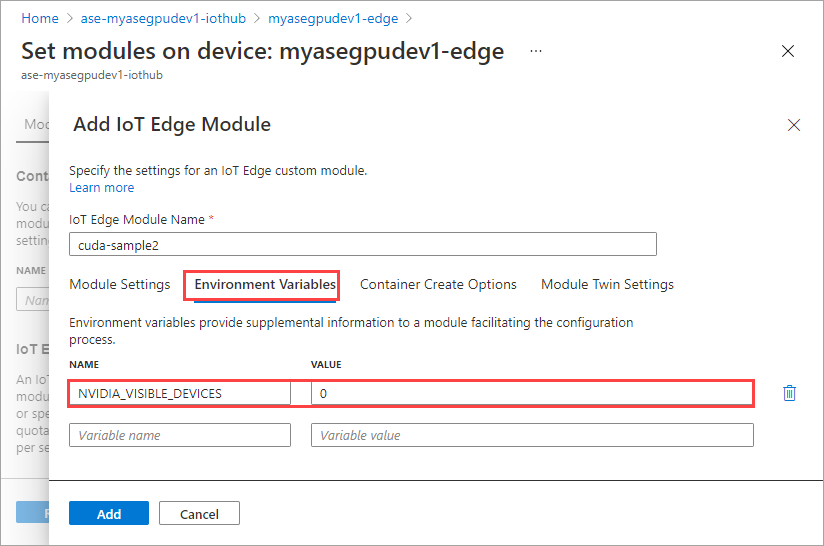
Dans l’onglet Variables d’environnement, définissez NVIDIA_VISIBLE_DEVICES sur 0.
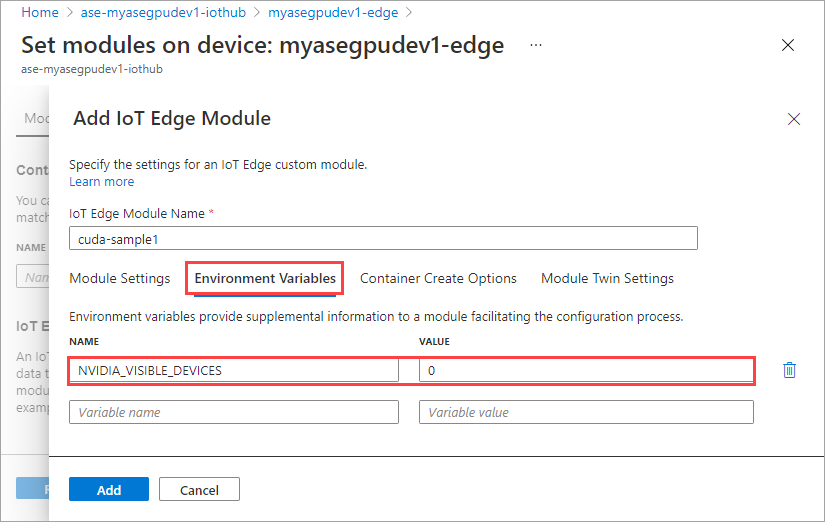
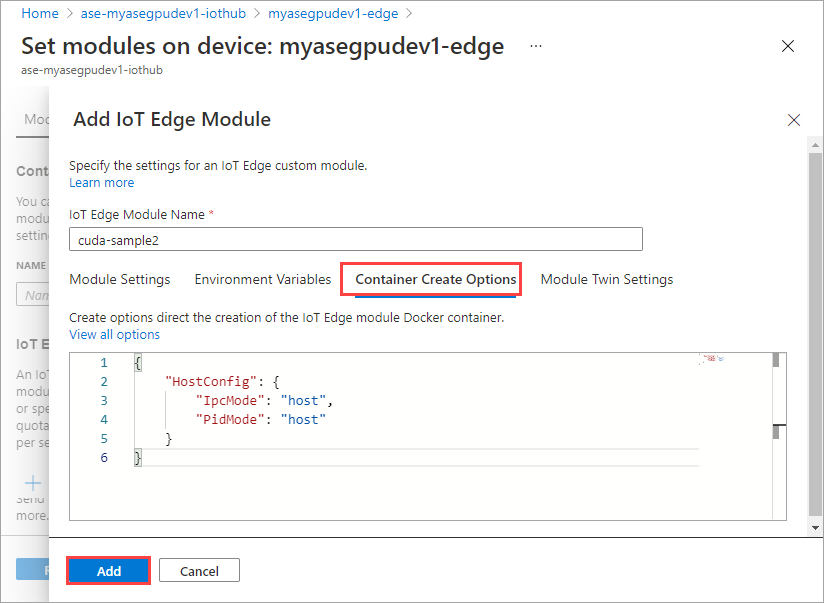
Dans l’onglet Options de création de conteneur, indiquez les options suivantes :
{ "Entrypoint": [ "/bin/sh" ], "Cmd": [ "-c", "/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done" ], "HostConfig": { "IpcMode": "host", "PidMode": "host" } }Les options s’affichent de la manière suivante :
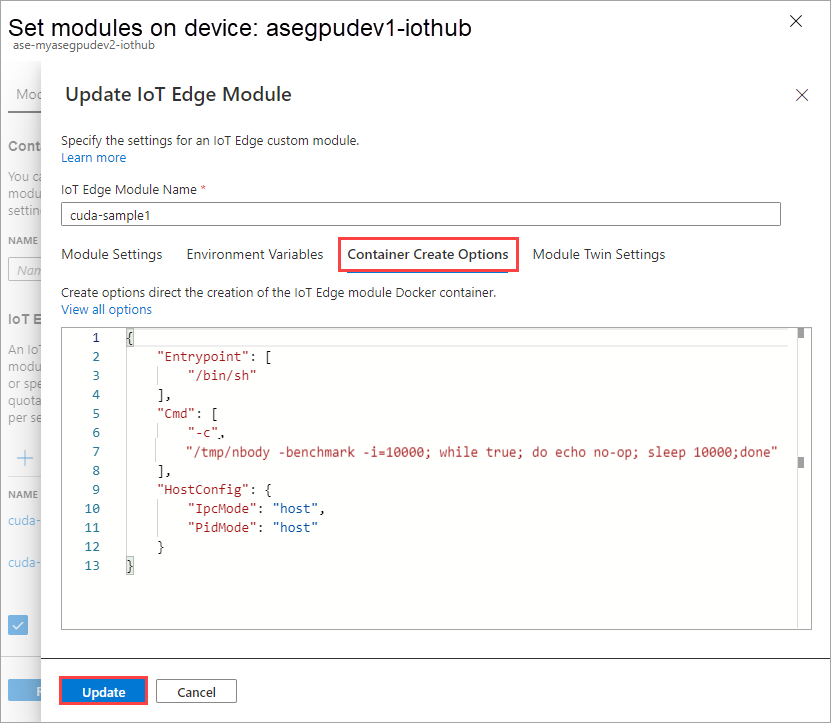
Sélectionnez Ajouter.
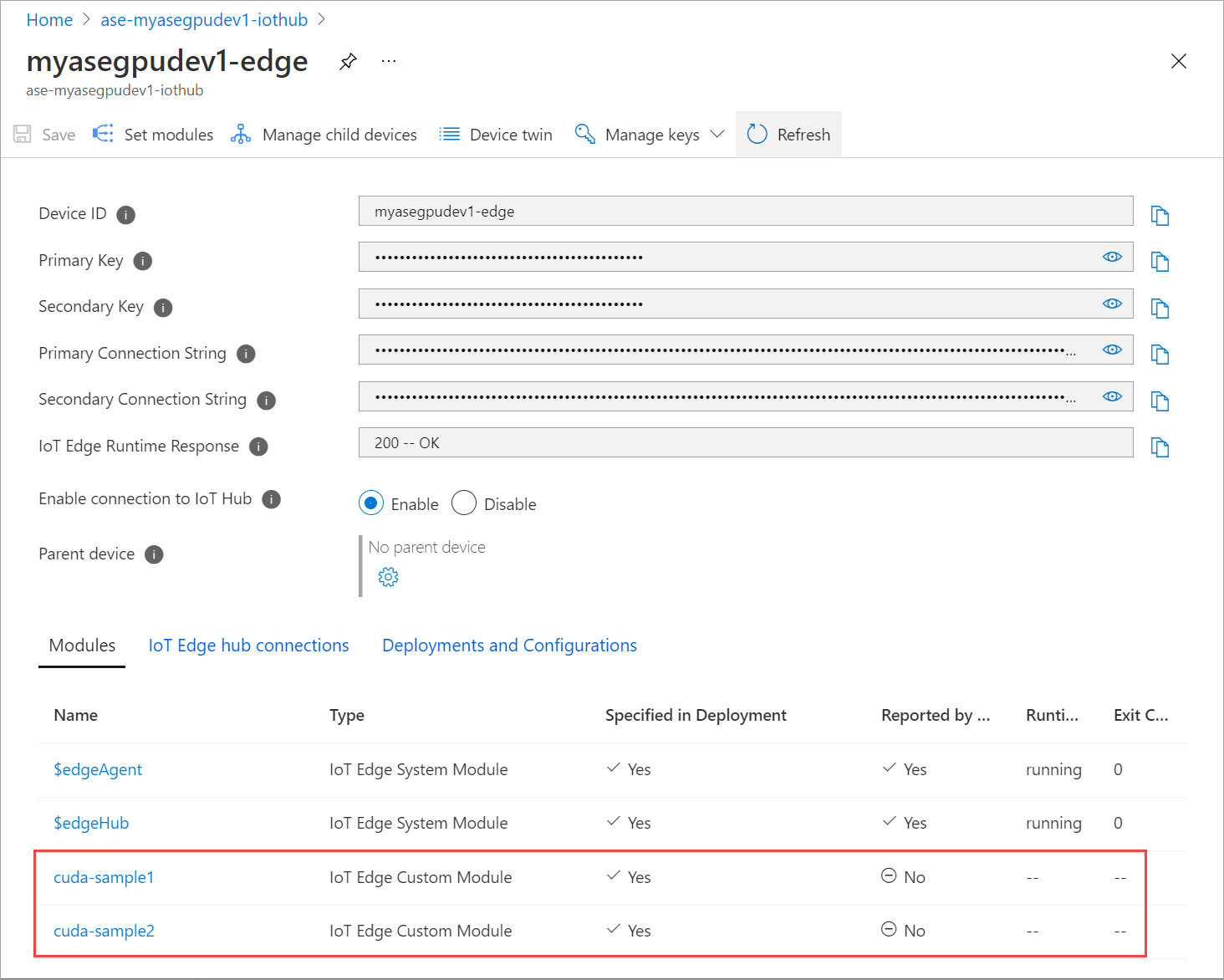
Le module que vous avez ajouté doit indiquer l’état En cours d’exécution.
Répétez l’ensemble de la procédure d’ajout d’un module que vous avez suivie lors de l’ajout du premier module. Dans cet exemple, fournissez le nom du module sous la forme
cuda-sample2.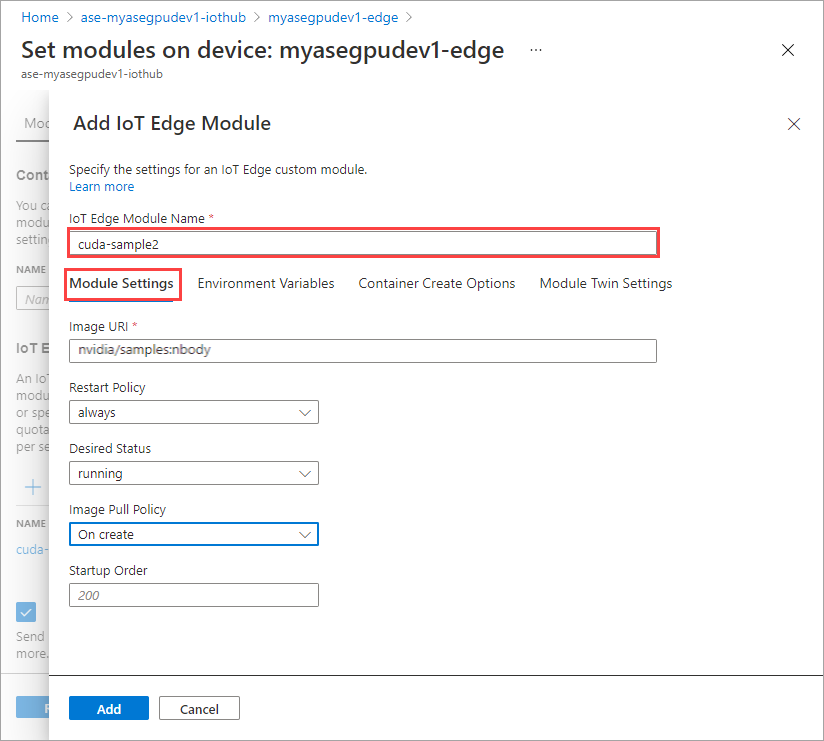
Utilisez la même variable d’environnement, car les deux modules partageront le même GPU.
Utilisez les options de création de conteneur que vous avez fournies pour le premier module, puis sélectionnez Ajouter.
Dans la page Définir les modules , sélectionnez Examiner + créer, puis Créer.
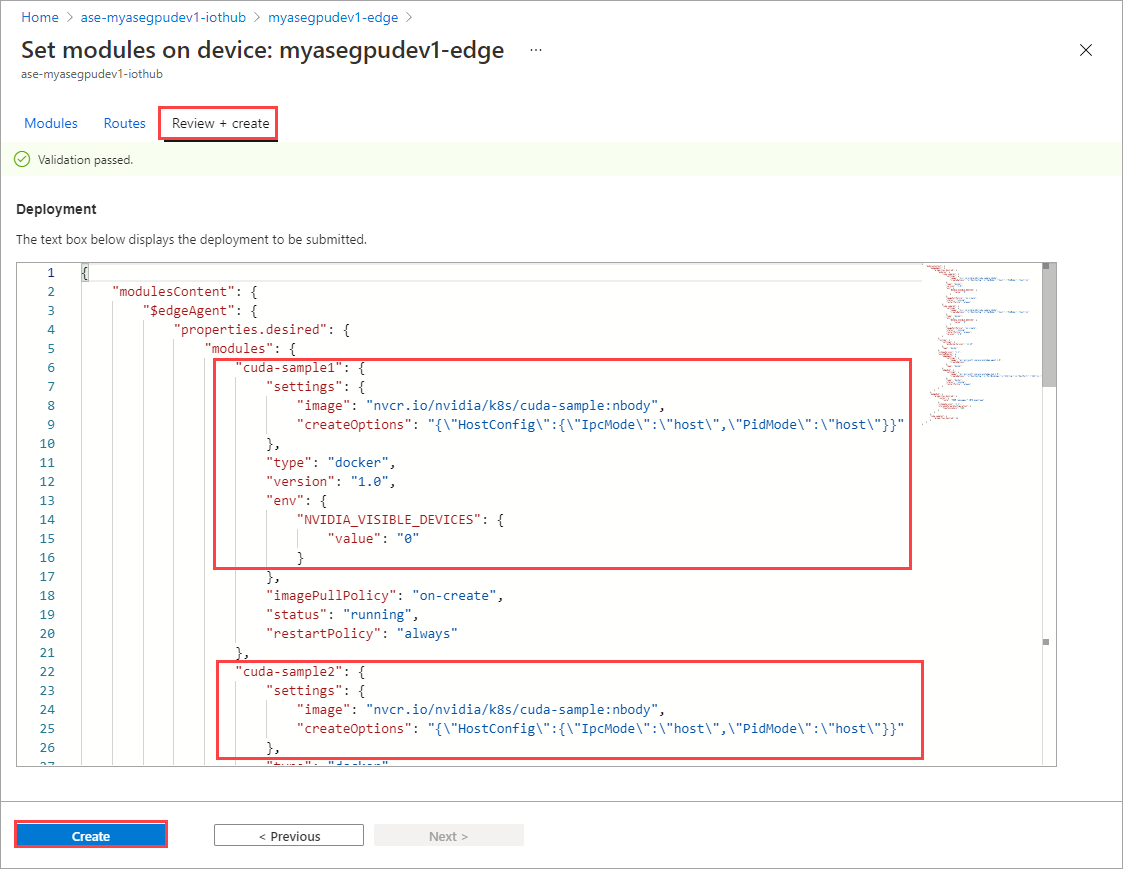
L’état d’exécution des deux modules doit maintenant indiquer En cours d’exécution.
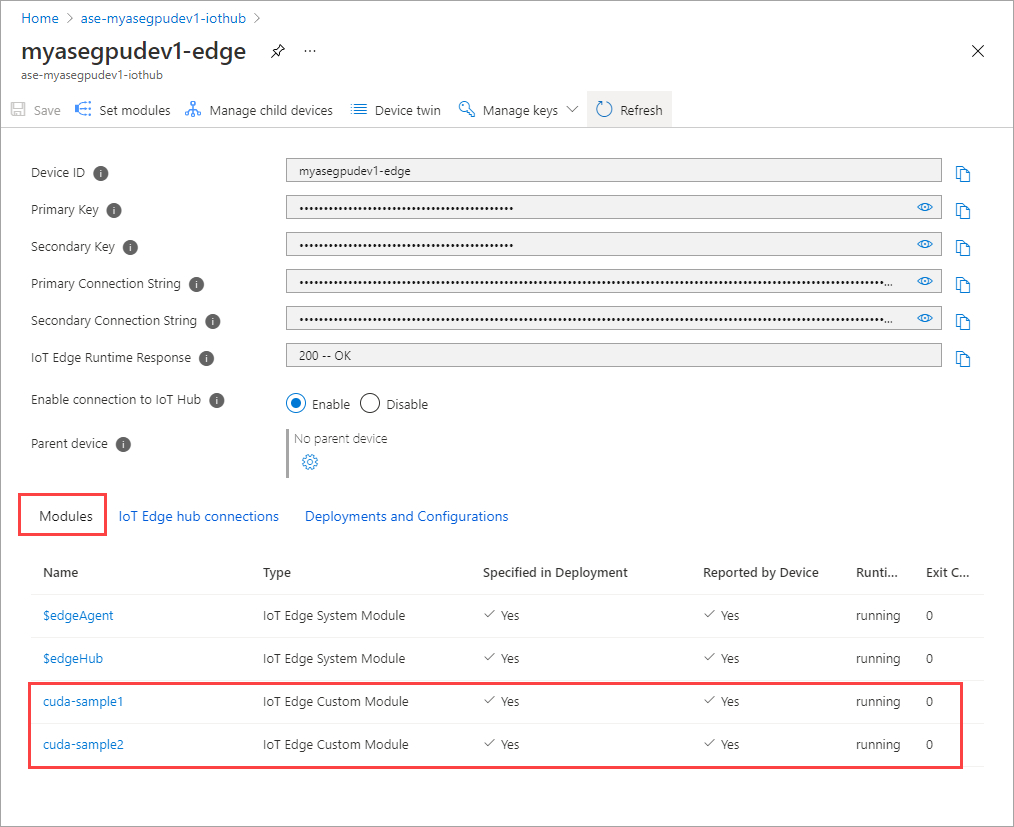
Surveiller le déploiement de la charge de travail
Ouvrez une nouvelle session PowerShell.
Dressez la liste de tous les pods exécutés dans l’espace de noms
iotedge. Exécutez la commande suivante :kubectl get pods -n iotedgeVoici un exemple de sortie :
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-ssng8 2/2 Running 0 5s cuda-sample2-6db6d98689-d74kb 2/2 Running 0 4s edgeagent-79f988968b-7p2tv 2/2 Running 0 6d21h edgehub-d6c764847-l8v4m 2/2 Running 0 24h iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 6d21h PS C:\WINDOWS\system32>Deux pods,
cuda-sample1-97c494d7f-lnmnsetcuda-sample2-d9f6c4688-2rld9, s’exécutent sur votre appareil.Tandis que les deux conteneurs exécutent la simulation n-body, consultez l’utilisation du GPU dans la sortie SMI NVIDIA. Accédez à l’interface PowerShell de l’appareil et exécutez
Get-HcsGpuNvidiaSmi.Voici un exemple de sortie lorsque les deux conteneurs exécutent la simulation n-body :
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:31:16 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 52C P0 69W / 70W | 221MiB / 15109MiB | 100% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 188342 C /tmp/nbody 109MiB | | 0 N/A N/A 188413 C /tmp/nbody 109MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Comme vous pouvez le voir, deux conteneurs s’exécutent avec la simulation n-body sur le GPU 0. Vous pouvez également afficher l’utilisation de la mémoire correspondante.
Une fois la simulation terminée, la sortie SMI NVIDIA indique qu’aucun processus n’est en cours d’exécution sur l’appareil.
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:54:48 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Une fois la simulation n-body terminée, consultez les journaux pour comprendre les détails du déploiement et le temps nécessaire à l’exécution de la simulation.
Voici un exemple de sortie du premier conteneur :
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample1-869989578c-ssng8 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170171.531 ms = 98.590 billion interactions per second = 1971.801 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Voici un exemple de sortie du deuxième conteneur :
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-d74kb cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170054.969 ms = 98.658 billion interactions per second = 1973.152 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Arrêtez le déploiement du module. Dans la ressource IoT Hub de votre appareil :
Accédez à Déploiement automatique des appareils > IoT Edge. Sélectionnez l’appareil IoT Edge correspondant à votre appareil.
Accédez à Définir des modules et sélectionnez un module.
Dans l’onglet Modules, sélectionnez un module.
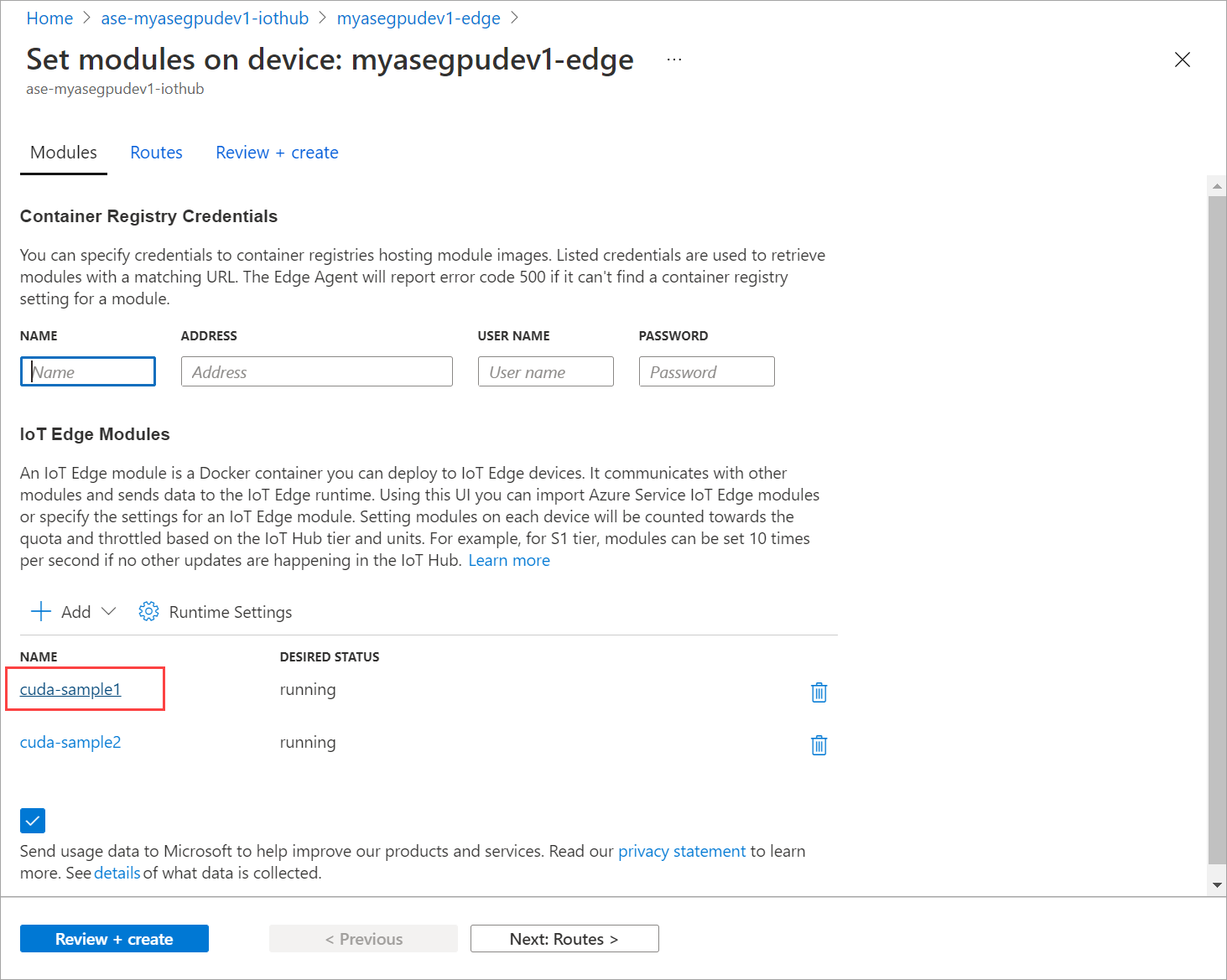
Dans l’onglet Paramètres du module, définissez l’état souhaité sur Arrêté. Sélectionnez Mettre à jour.
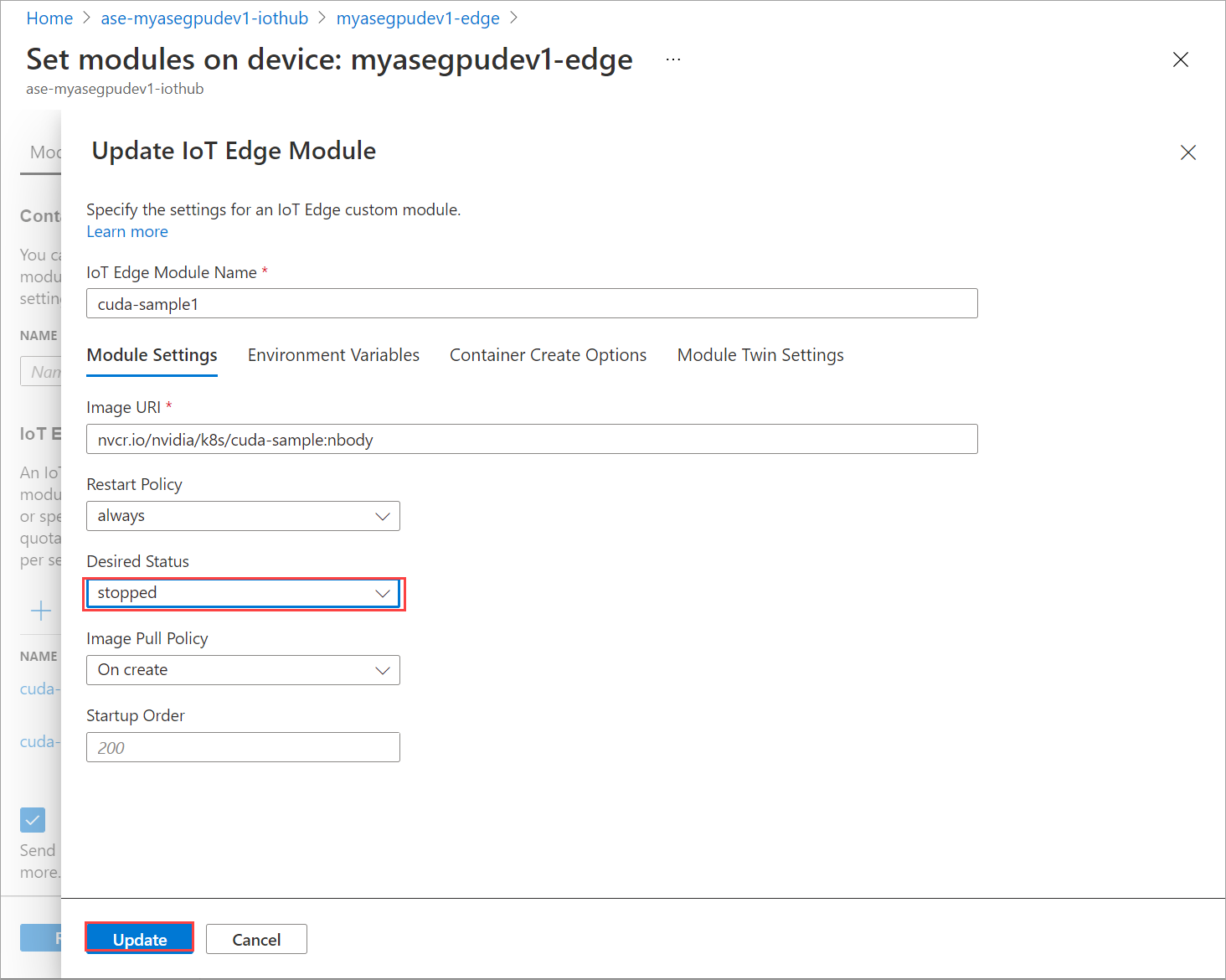
Répétez les étapes pour arrêter le deuxième module déployé sur l’appareil. Sélectionnez Vérifier + créer, puis Créer. Le déploiement doit être mis à jour.
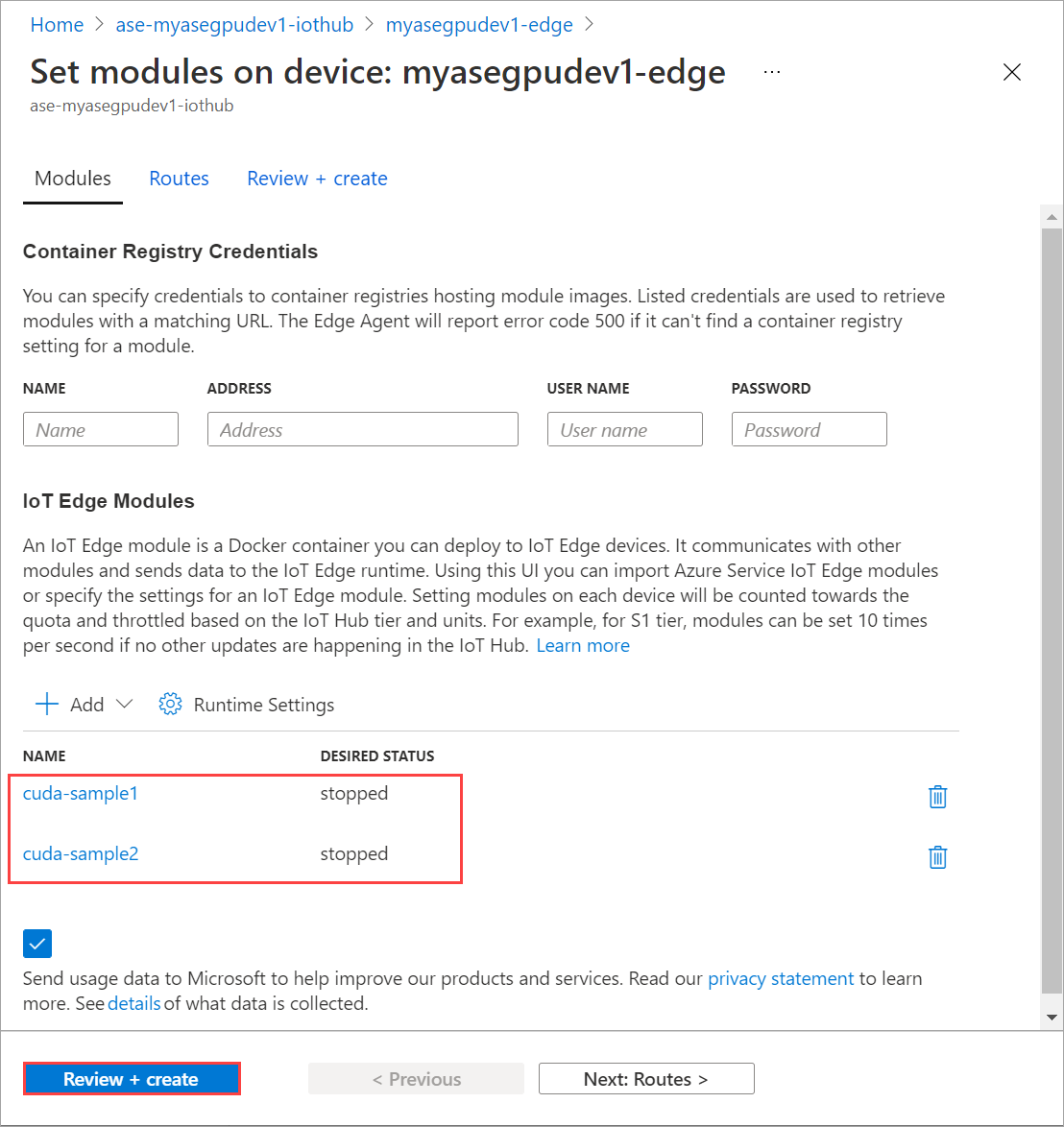
Actualisez plusieurs fois la page Définir des modules, jusqu’à ce que l’État d’exécution du module indique Arrêté.
Déployer avec partage de contexte
Vous pouvez maintenant déployer la simulation n-body sur deux conteneurs CUDA lorsque MPS s’exécute sur votre appareil. Vous devez d’abord activer MPS sur l’appareil.
Connectez-vous à l’interface PowerShell de votre appareil.
Pour activer MPS sur votre appareil, exécutez la commande
Start-HcsGpuMPS.[10.100.10.10]: PS>Start-HcsGpuMPS K8S-1HXQG13CL-1HXQG13: Set compute mode to EXCLUSIVE_PROCESS for GPU 0000191E:00:00.0. All done. Created nvidia-mps.service [10.100.10.10]: PS>Récupérez la sortie SMI NVIDIA à partir de l’interface PowerShell de l’appareil. Vous constatez que le processus
nvidia-cuda-mps-serverou le service MPS s’exécute sur l’appareil.Voici un exemple de sortie :
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:37:39 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 36C P8 9W / 70W | 28MiB / 15109MiB | 0% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmiDéployez les modules que vous avez arrêtés précédemment. Définissez l’État souhaité sur En cours d’exécution via l’option Définir des modules.
Voici l’exemple de sortie :
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-2zxh6 2/2 Running 0 44s cuda-sample2-6db6d98689-fn7mx 2/2 Running 0 44s edgeagent-79f988968b-7p2tv 2/2 Running 0 5d20h edgehub-d6c764847-l8v4m 2/2 Running 0 27m iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 5d20h PS C:\WINDOWS\system32>Vous constatez que les modules sont déployés et en cours d’exécution sur votre appareil.
Lorsque les modules sont déployés, la simulation n-body commence également à s’exécuter sur les deux conteneurs. Voici l’exemple de sortie lorsque la simulation est terminée sur le premier conteneur :
PS C:\WINDOWS\system32> kubectl -n iotedge logs cuda-sample1-869989578c-2zxh6 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155256.062 ms = 108.062 billion interactions per second = 2161.232 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Voici l’exemple de sortie lorsque la simulation est terminée sur le deuxième conteneur :
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-fn7mx cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155366.359 ms = 107.985 billion interactions per second = 2159.697 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Récupérez la sortie SMI NVIDIA auprès de l’interface PowerShell de l’appareil lorsque les deux conteneurs exécutent la simulation n-body. Voici un exemple de sortie : Il y a trois processus, le processus
nvidia-cuda-mps-server(type C) correspond au service MPS et les processus/tmp/nbody(type M + C) correspondent aux charges de travail de la simulation n-body déployées par les modules.[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:59:44 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 54C P0 69W / 70W | 242MiB / 15109MiB | 100% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 56832 M+C /tmp/nbody 107MiB | | 0 N/A N/A 56900 M+C /tmp/nbody 107MiB | | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmi