Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cette page explique comment Azure Databricks utilise Lakeguard pour appliquer l’isolation des utilisateurs dans les environnements de calcul partagés et le contrôle d’accès affiné dans le calcul dédié.
Qu’est-ce que Lakeguard ?
Lakeguard est un ensemble de technologies sur Databricks qui appliquent l’isolation du code et le filtrage des données afin que plusieurs utilisateurs puissent partager la même ressource de calcul de manière sécurisée et rentable, et accéder aux données avec des contrôles d’accès affinés en place sur le calcul offrant un accès privilégié aux ordinateurs.
Comment Lakeguard fonctionne-t-il ?
Dans les environnements de calcul partagés tels que le calcul classique standard, le calcul serverless et les entrepôts SQL, Lakeguard isole le code utilisateur du moteur Spark et d’autres utilisateurs. Cette conception permet à de nombreux utilisateurs de partager les mêmes ressources de calcul tout en conservant des limites strictes entre les utilisateurs, le pilote Spark et les exécuteurs.
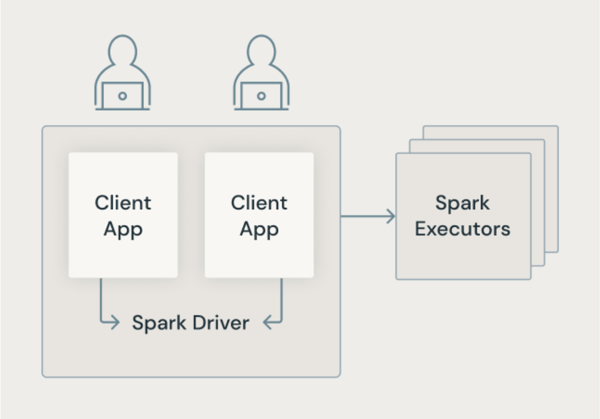
Architecture Spark classique
L’image suivante montre comment, dans l’architecture Spark traditionnelle, les applications utilisateur partagent une machine virtuelle JVM avec un accès privilégié à la machine sous-jacente.
Architecture Lakeguard
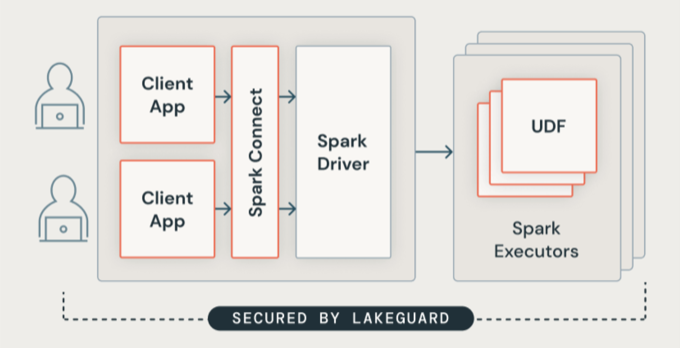
Lakeguard isole tout le code utilisateur à l’aide de conteneurs sécurisés. Cela permet à plusieurs charges de travail d’s’exécuter sur la même ressource de calcul tout en conservant une isolation stricte entre les utilisateurs.
Isolation du client Spark
Lakeguard isole les applications clientes du pilote Spark et les unes des autres à l’aide de deux composants clés :
Spark Connect : Lakeguard utilise Spark Connect (introduit avec Apache Spark 3.4) pour dissocier les applications clientes du pilote. Les applications clientes et les pilotes ne partagent plus la même machine virtuelle JVM ou classpath. Cette séparation empêche l’accès non autorisé aux données. Cette conception empêche également les utilisateurs d’accéder aux données résultant d’une sur-extraction lorsque les requêtes incluent des filtres au niveau des lignes ou des colonnes.
Note
Spark Connect reporte l’analyse et la résolution de noms au temps d’exécution, ce qui peut modifier le comportement de votre code. Consultez Comparer Spark Connect à Spark Classic.
Bac à sable de conteneur : chaque application cliente s’exécute dans son propre environnement de conteneur isolé. Cela empêche le code utilisateur d’accéder aux données d’autres utilisateurs ou à la machine sous-jacente. Le bac à sable utilise des techniques d’isolation basées sur des conteneurs pour créer des limites sécurisées entre les utilisateurs.
Isolation UDF
Par défaut, les exécuteurs Spark n’isolent pas les fonctions définies par l’utilisateur. Ce manque d’isolation peut permettre aux fonctions définies par l’utilisateur d’écrire des fichiers ou d’accéder à l’ordinateur sous-jacent.
Lakeguard isole le code défini par l’utilisateur, y compris les fonctions définies par l’utilisateur, sur les exécuteurs Spark par :
- Bac à sable (sandbox) de l’environnement d’exécution sur les exécuteurs Spark.
- Isoler le trafic réseau de sortie des fonctions définies par l’utilisateur pour empêcher l’accès externe non autorisé.
- Réplication de l’environnement client dans le bac à sable UDF afin que les utilisateurs puissent accéder aux bibliothèques requises.
Cette isolation s’applique aux fonctions définies par l’utilisateur sur le calcul standard et aux fonctions définies par l’utilisateur Python sur les entrepôts SQL et de calcul serverless.