Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article explique comment visualiser la traçabilité des données à l’aide de l’Explorateur de catalogues, des tables système de traçabilité des données et de l’API REST.
Vue d’ensemble de la traçabilité des données
Unity Catalog capture la traçabilité des données du runtime à travers les requêtes exécutées sur Azure Databricks. La traçabilité est prise en charge pour toutes les langues et est capturée au niveau des colonnes. Les données de traçabilité incluent les notebooks, les travaux et les tableaux de bord liés à la requête. Vous pouvez visualiser la traçabilité dans Catalog Explorer en quasi-temps réel et la récupérer par programmation en utilisant les tables système de traçabilité et l’API REST Databricks.
La traçabilité est agrégée pour tous les espaces de travail attachés à un metastore Unity Catalog. Cela signifie que la traçabilité capturée dans un espace de travail est visible dans les autres espaces de travail partageant ce metastore. Plus précisément, les tables et d’autres objets de données inscrits dans le metastore sont visibles par les utilisateurs disposant d’au moins BROWSE des autorisations sur ces objets, dans tous les espaces de travail attachés au metastore. Toutefois, des informations détaillées sur les objets au niveau de l’espace de travail, comme les blocs-notes et les tableaux de bord dans d’autres espaces de travail, sont masquées (voir limitations de traçabilité et autorisations de traçabilité).
Les données de traçabilité sont conservées pendant un an.
L’image suivante est un exemple de graphique de traçabilité.
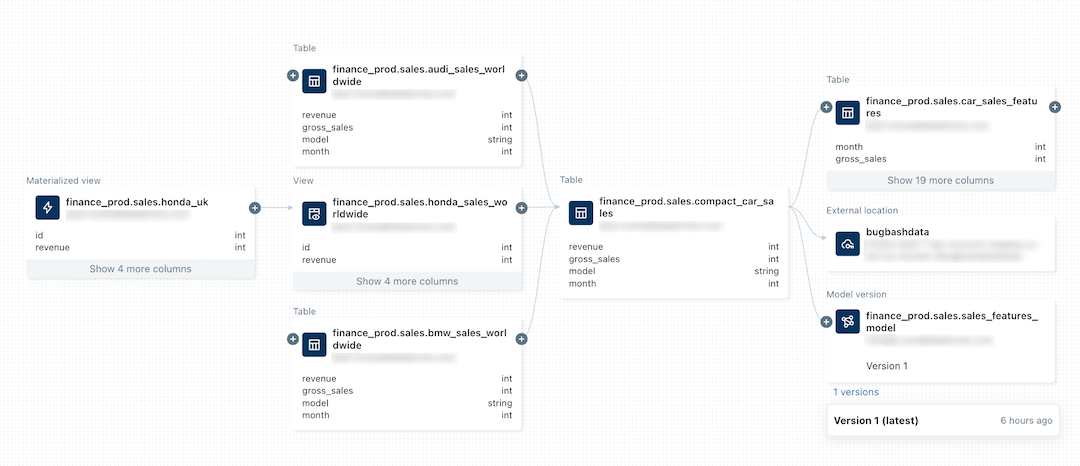
Pour plus d’informations sur le suivi de la traçabilité d’un modèle Machine Learning, consultez Suivre la traçabilité des données d’un modèle dans Unity Catalog.
Spécifications
Pour capturer la traçabilité des données à l’aide du catalogue Unity :
- Les tables doivent être enregistrées dans un metastore Unity Catalog.
- Les requêtes doivent utiliser le DataFrame Spark (par exemple, les fonctions Spark SQL qui retournent un DataFrame) ou des interfaces DATAbricks SQL telles que les notebooks ou l’éditeur de requête SQL.
Pour afficher la lignée des données :
- Vous devez disposer au moins du privilège
BROWSEsur le catalogue parent de la table ou de la vue. Le catalogue parent doit également être accessible à partir de l’espace de travail. Consultez Limiter l’accès au catalogue à des espaces de travail spécifiques. - Pour les blocs-notes, les travaux ou les tableaux de bord, vous devez disposer d’autorisations sur ces objets, comme défini par les paramètres de contrôle d’accès dans l’espace de travail. Pour plus d’informations, consultez autorisations de lignage.
- Pour un pipeline avec Unity Catalog, vous devez disposer des autorisations CAN VIEW sur le pipeline.
Voici les exigences de calcul à respecter :
- Le suivi de la traçabilité de la diffusion en continu entre des tables Delta nécessite Databricks Runtime 11.3 LTS ou version ultérieure.
- Le suivi de la traçabilité des colonnes pour les charges de travail Lakeflow Declarative Pipelines nécessite Databricks Runtime 13.3 LTS ou une version ultérieure.
Configuration réseau requise :
- Il est possible que vous deviez mettre à jour vos règles de pare-feu sortantes pour autoriser la connectivité au point de terminaison Event Hubs dans le plan de contrôle Azure Databricks. Cela s’applique généralement si votre espace de travail Azure Databricks est déployé dans votre propre réseau virtuel (également appelé injection de réseau virtuel). Pour obtenir le point de terminaison Event Hubs de la région de votre espace de travail, consultez Metastore, stockage Blob des artefacts, stockage des tables système, stockage Blob des journaux et adresses IP du point de terminaison Event Hubs. Si vous souhaitez obtenir plus d’informations sur la configuration de routages définis par l’utilisateur (UDR) pour Azure Databricks, consultez Paramètres de routage définis par l’utilisateur pour Azure Databricks.
Afficher la traçabilité des données à l’aide de l’Explorateur de catalogues
Pour utiliser l’Explorateur de catalogues et voir le lignage des tables :
Dans votre espace de travail Azure Databricks, cliquez sur
 Catalogue.
Catalogue.Recherchez votre table ou parcourez-la.
Sélectionnez l’onglet Traçabilité . Le panneau de traçabilité s’affiche et affiche les tables associées.
Pour afficher un graphique interactif de la traçabilité des données, cliquez sur Afficher le graphique de traçabilité.
Par défaut, un niveau est affiché dans le graphique. Cliquez sur l’icône
 d’un nœud pour afficher davantage de connexions si elles sont disponibles.
d’un nœud pour afficher davantage de connexions si elles sont disponibles.Cliquez sur une flèche reliant des nœuds dans le graphique de traçabilité pour ouvrir le panneau Connexion de traçabilité.
Le panneau Connexion de traçabilité affiche des détails sur la connexion, notamment les tables source et cible, les notebooks et les travaux.
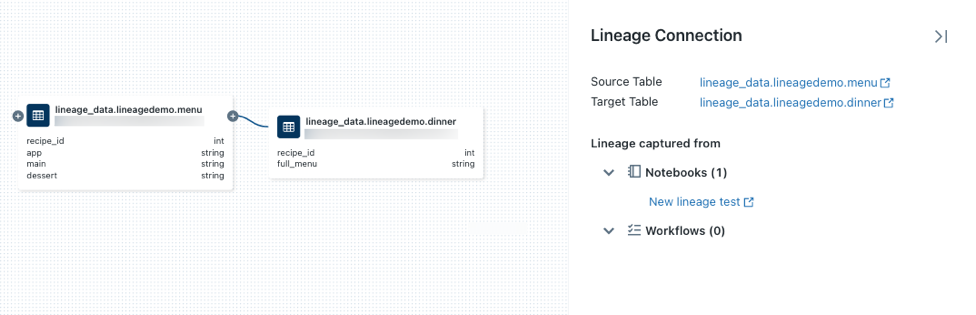
Pour afficher un bloc-notes associé à un tableau, sélectionnez le bloc-notes dans le panneau de connexion traçabilité ou fermez le graphique de traçabilité, puis cliquez sur Notebooks.
Pour ouvrir le notebook dans un nouvel onglet, cliquez sur le nom du notebook.
Pour afficher la traçabilité au niveau des colonnes, cliquez sur une colonne dans le graphique pour afficher des liens vers des colonnes associées. Par exemple, en cliquant sur la
full_menucolonne dans cet exemple de graphique, cela montre les colonnes en amont dont elle a été dérivée.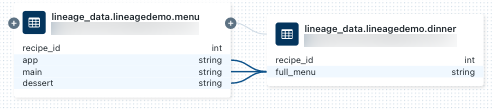
Afficher la traçabilité du travail
Pour afficher la traçabilité des travaux, accédez à l’onglet Traçabilité d’une table, sélectionnez Travaux, puis sélectionnez En aval. Le nom du travail apparaît sous Nom du travail comme consommateur de la table.
Afficher la traçabilité du tableau de bord
Pour afficher la traçabilité du tableau de bord, accédez à l’onglet Traçabilité d’un tableau, puis cliquez sur Tableaux de bord. Le tableau de bord apparaît sous Nom du tableau de bord comme consommateur de la table.
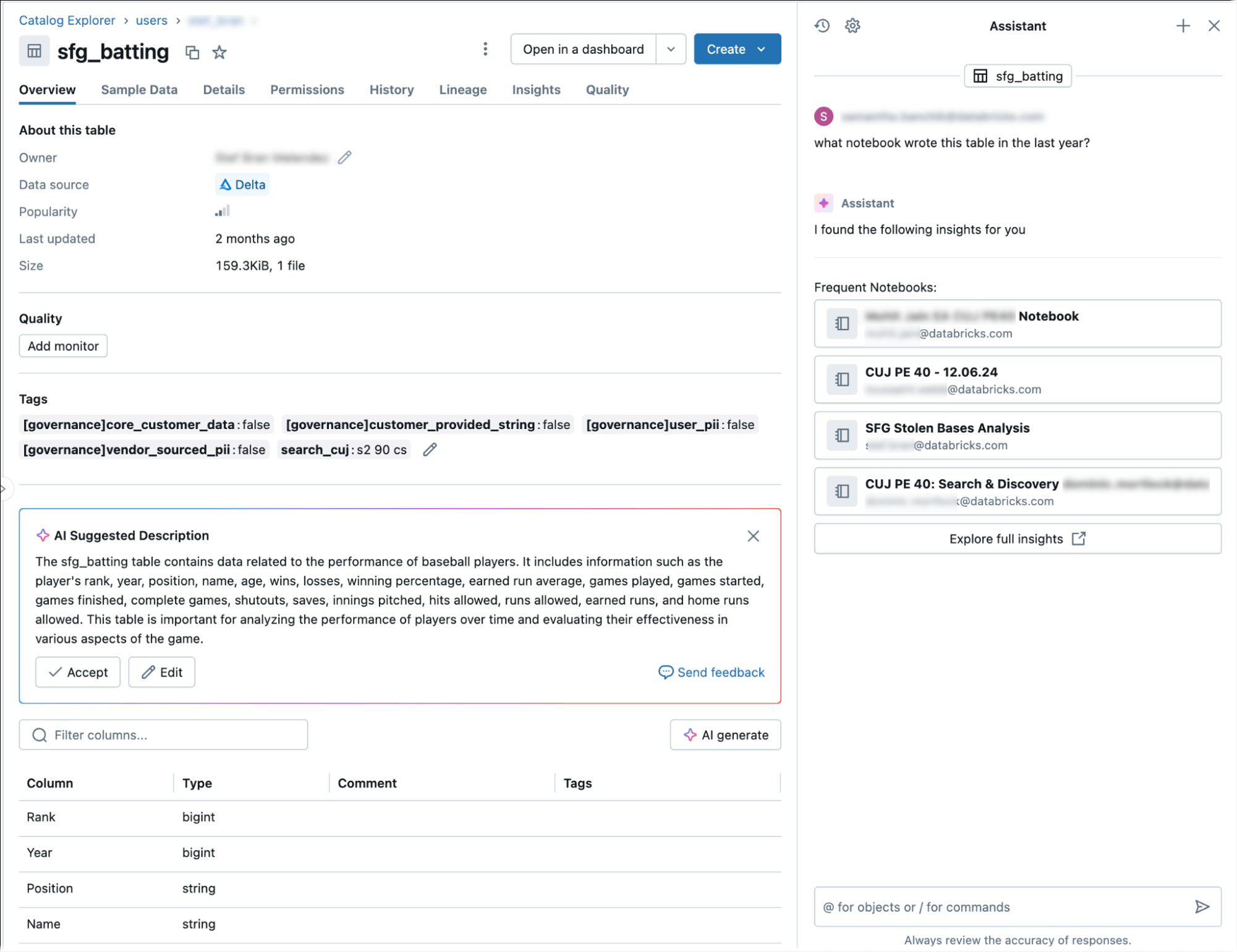
Obtenir la traçabilité des tables à l’aide de l’assistant Databricks
L’assistant Databricks fournit des informations détaillées sur la traçabilité des tables et leurs aperçus.
Pour obtenir des informations de traçabilité à l’aide de l’assistant :
- Dans la barre latérale de l’espace de travail, cliquez sur Catalogue.
- Parcourez ou recherchez le catalogue, cliquez sur le nom du catalogue, puis cliquez sur l'icône de l'assistant d'aide dans le produit, de couleur, située dans le coin supérieur droit.
- À l’invite de l'Assistant, tapez :
- /getTableLineages pour afficher les dépendances en amont et en aval.
- /getTableInsights pour accéder aux insights pilotés par les métadonnées, tels que l’activité utilisateur et les modèles de requête.
Ces requêtes permettent à l’Assistant de répondre à des questions telles que « afficher les lignées en aval » ou « qui consulte le plus souvent cette table ».
Interroger des données de traçabilité à l’aide de tables système
Vous pouvez utiliser les tables système de traçabilité pour interroger les données de traçabilité de manière programmatique. Pour obtenir des instructions détaillées, consultez Surveiller l’activité du compte avec des tables système et Référence sur les tables système de traçabilité.
Si votre espace de travail se trouve dans une région qui ne prend pas en charge les tables système de traçabilité, vous pouvez utiliser l’API REST de traçabilité des données pour récupérer les données de traçabilité de manière programmée.
Récupérer la traçabilité à l’aide de l’API REST Traçabilité des données
L’API de traçabilité des données vous permet de récupérer la traçabilité de table et de colonne. Toutefois, si votre espace de travail se situe dans une région qui prend en charge les tables système de traçabilité, vous devez utiliser des requêtes de table système au lieu de l’API REST. Les tables système constituent une meilleure option pour la récupération programmatique des données de traçabilité. La majorité des régions prennent en charge les tables système de traçabilité.
Importante
Pour accéder aux API REST Databricks, vous devez vous authentifier.
Récupérer la traçabilité des tables
Cet exemple récupère les données de filiation pour la table dinner.
Requête
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/table-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "include_entity_lineage": true}'
Remplacez <workspace-instance>.
Cet exemple utilise un fichier .netrc.
réponse
{
"upstreams": [
{
"tableInfo": {
"name": "menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
],
"downstreams": [
{
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
},
{
"tableInfo": {
"name": "dinner_price",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
]
}
Récupérer la traçabilité des colonnes
Cet exemple récupère les données de colonne pour la table dinner.
Requête
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/column-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "column_name": "dessert"}'
Remplacez <workspace-instance>.
Cet exemple utilise un fichier .netrc.
réponse
{
"upstream_cols": [
{
"name": "dessert",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "main",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "app",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
}
],
"downstream_cols": [
{
"name": "full_menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "dinner_price",
"table_type": "TABLE"
}
]
}
Autorisations de traçabilité
Les graphiques de traçabilité partagent le même modèle d’autorisation que Unity Catalog. Les tables et autres objets de données inscrits dans le metastore Du catalogue Unity sont visibles uniquement par les utilisateurs disposant d’au moins BROWSE des autorisations sur ces objets. Si un utilisateur n’a pas le privilège BROWSE ou SELECT sur une table, il ne peut pas explorer sa traçabilité. Les graphiques de traçabilité affichent des objets Unity Catalog sur tous les espaces de travail attachés au metastore, dès lors que l’utilisateur dispose des autorisations nécessaires sur les objets.
Par exemple, exécutez les commandes suivantes pour userA:
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
Lorsque userA affiche le graphe de traçabilité de la table lineage_data.lineagedemo.menu, ils voient s’afficher la table menu. Ils ne vont pas pouvoir consulter les informations sur les tables connexes, telles que la table lineage_data.lineagedemo.dinner en aval. La table dinner est affichée en tant que nœud masked dans l’affichage de userA et userA ne peut pas développer le graphique pour révéler les tables en aval des tables auxquelles il n’a pas l’autorisation d’accéder.
Si vous exécutez la commande suivante pour accorder l’autorisation BROWSE à userB, cet utilisateur peut afficher le graphique de traçabilité pour n’importe quelle table du lineage_data schéma :
GRANT BROWSE on lineage_data to `userB@company.com`;
De même, les utilisateurs de lineage doivent disposer d’autorisations spécifiques pour afficher des objets d’espace de travail tels que des notebooks, des travaux et des tableaux de bord. En outre, ils ne peuvent voir que des informations détaillées sur les objets d’espace de travail lorsqu’ils sont connectés à l’espace de travail dans lequel ces objets ont été créés. Des informations détaillées sur les objets au niveau de l'espace de travail dans d'autres espaces de travail sont masquées dans le graphique de lignage.
Pour plus d’informations sur la gestion de l’accès aux objets sécurisables dans Unity Catalog, consultez Gérer les privilèges dans Unity Catalog. Pour plus d’informations sur la gestion de l’accès aux objets de l’espace de travail comme les notebooks, les travaux et les tableaux de bord, consultez Listes de contrôle d’accès.
Limitations de lignée
La traçabilité des données présente les limitations suivantes. Ces limitations s’appliquent également aux tables de système de lignage :
Bien que le lignage soit agrégé pour tous les espaces de travail attachés au même metastore Unity Catalog, les détails des objets d’espace de travail, comme les notebooks et les tableaux de bord, sont visibles uniquement dans l’espace de travail dans lequel ils ont été créés.
La lignage étant calculé sur une période glissante d'un an, les données de lignage conservées il y a plus d'un an ne sont pas affichées. Par exemple, si une tâche ou une requête lit des données dans la table A et les écrit dans la table B, le lien entre les tables A et B est uniquement affiché pour une année. Vous pouvez filtrer les données de traçabilité par intervalle de temps sur une période d’un an.
Les travaux qui utilisent la demande de l'API
runs submitJobs ou le type de tâchespark submitne sont pas disponibles dans les vues de lignage. La traçabilité au niveau des tables et des colonnes est toujours capturée pour ces workflows, mais le lien vers l’exécution du travail n’est pas capturé.Si une table ou une vue est renommée, la traçabilité n’est pas capturée pour la table ou la vue renommée.
Si un schéma ou un catalogue est renommé, la traçabilité n’est pas capturée pour les tables et les vues sous le catalogue ou le schéma renommé.
Si vous utilisez des points de contrôle de jeu de données Spark SQL, la traçabilité n’est pas capturée.
Unity Catalog capture la traçabilité à partir de Lakeflow Declarative Pipelines dans la plupart des cas. Toutefois, dans certains cas, la couverture complète de la traçabilité ne peut pas être garantie, par exemple lorsque les pipelines utilisent des tables privées.
La traçabilité ne capture pas les fonctions Stack.
Les vues temporaires globales ne sont pas capturées dans la traçabilité.
Les tables sous
system.information_schemane sont pas capturées dans la traçabilité.Unity Catalog capture autant que possible la traçabilité au niveau des colonnes. Cependant, dans certains cas, la traçabilité au niveau des colonnes ne peut pas être capturée. Voici quelques-uns des éléments suivants :
La traçabilité des colonnes ne peut pas être capturée si la source ou la cible est référencée comme un chemin d’accès (par exemple :
select * from delta."s3://<bucket>/<path>"). La traçabilité des colonnes est uniquement prise en charge lorsque la source et la cible sont référencées par le nom de la table (exemple :select * from <catalog>.<schema>.<table>).Utilisation d’expressions de table courantes (CTEs), de renommage de colonnes, de fonctions définies par l’utilisateur (UDF) ou de jeux de données distribués résilients (RDD), qui peuvent masquer le mappage entre les colonnes source et cible.
La traçabilité complète au niveau des colonnes n’est pas capturée par défaut pour les opérations
MERGE.Vous pouvez activer la capture de la traçabilité pour les opérations
MERGEen définissant la propriété Sparkspark.databricks.dataLineage.mergeIntoV2Enabledsurtrue. L’activation de cet indicateur peut ralentir les performances des requêtes, en particulier dans les charges de travail qui impliquent des tables très larges.