Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cette page explique comment lire les données partagées avec vous à l’aide du protocole de partage ouvert Delta avec des jetons d’authentification. Il inclut des instructions pour lire des données partagées à l’aide des outils suivants :
- Databricks
- Apache Spark
- Pandas
- Power BI
- Tableau
Dans ce modèle de partage ouvert, vous utilisez un fichier d’informations d’identification, partagé avec un membre de votre équipe par le fournisseur de données, pour obtenir un accès en lecture sécurisé aux données partagées. L’accès persiste tant que les informations d’identification sont valides et que le fournisseur continue de partager les données. Les fournisseurs gèrent l’expiration et la rotation des informations d’identification. Les mises à jour des données sont disponibles en quasi temps réel. Vous pouvez lire et effectuer des copies des données partagées, mais vous ne pouvez pas modifier les données sources.
Remarque
Si des données ont été partagées avec vous à l’aide de Databricks-to-Databricks Delta Sharing, vous n’avez pas besoin d’un fichier d’informations d’identification pour accéder aux données, et cet article ne s’applique pas à vous. Pour obtenir des instructions, consultez Lire les données partagées à l’aide du partage Delta Databricks-to-Databricks (pour les destinataires).
Les sections suivantes décrivent comment utiliser Azure Databricks, Apache Spark, pandas et Power BI pour accéder et lire des données partagées à l’aide du fichier d’informations d’identification. Pour obtenir la liste complète des connecteurs Delta Sharing et les informations sur leur utilisation, consultez la documentation open source sur Delta Sharing. Si vous rencontrez des difficultés pour accéder aux données partagées, contactez le fournisseur de données.
Avant de commencer
Un membre de votre équipe doit télécharger le fichier d’informations d’identification partagé par le fournisseur de données. Consultez Obtenir l’accès dans le modèle de partage ouvert.
Il doit utiliser un canal sécurisé pour partager ce fichier ou cet emplacement de fichier avec vous.
Azure Databricks : lire des données partagées à l’aide de connecteurs de partage ouvert
Cette section explique comment importer un fournisseur et comment interroger les données partagées dans l’Explorateur de catalogues ou dans un notebook Python :
Si votre espace de travail Azure Databricks est activé pour Unity Catalog, utilisez l’interface utilisateur du fournisseur d’importation dans l’Explorateur de catalogues. Vous pouvez effectuer les opérations suivantes sans avoir à stocker ou spécifier un fichier d’informations d’identification :
- Créez des catalogues à partir de partages en cliquant sur un bouton.
- Utilisez les contrôles d’accès du catalogue Unity pour accorder l’accès aux tables partagées.
- Interroger des données partagées à l’aide de la syntaxe standard du catalogue Unity.
Si votre espace de travail Azure Databricks n’est pas activé pour Unity Catalog, utilisez les instructions de notebook Python comme exemple.
Explorateur de catalogues
Autorisations requises : un administrateur de metastore ou un utilisateur disposant à la fois des privilèges CREATE PROVIDER et USE PROVIDER pour votre metastore Unity Catalog.
Dans votre espace de travail Azure Databricks, cliquez sur
 Catalogue pour ouvrir l’Explorateur de catalogues.
Catalogue pour ouvrir l’Explorateur de catalogues.En haut du volet Catalogue, cliquez sur l’
 et sélectionnez Partage Delta.
et sélectionnez Partage Delta.Vous pouvez également, dans la page Accès rapide, cliquer sur le bouton Delta Sharing >.
Sous l’onglet Partagé avec moi , cliquez sur Importer des données.
Entrez le nom du fournisseur.
Le nom ne peut pas inclure d’espaces.
Chargez le fichier d’informations d’identification que le fournisseur a partagé avec vous.
De nombreux fournisseurs disposent de leurs propres réseaux Delta Sharing dont vous pouvez recevoir des partages. Pour plus d’informations, consultez configurations spécifiques au fournisseur.
(Facultatif) Entrez un commentaire.
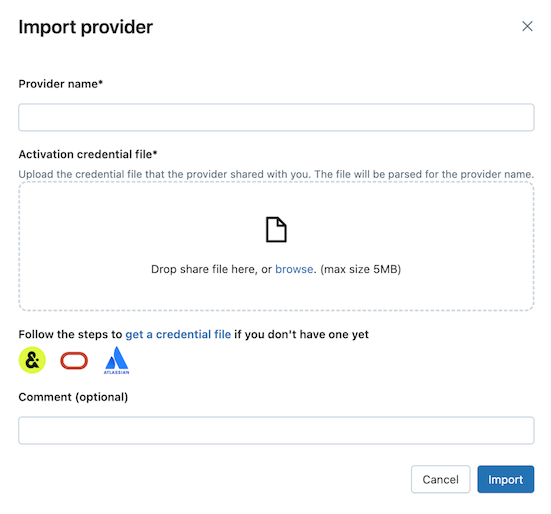
Cliquez sur Importer.
Créez des catalogues à partir des données partagées.
Sous l’onglet Partages , cliquez sur Créer un catalogue sur la ligne de partage.
Pour plus d’informations sur l’utilisation de SQL ou de l’interface CLI Databricks pour créer un catalogue à partir d’un partage, consultez Créer un catalogue à partir d’un partage.
Accordez l’accès aux catalogues.
Voir Comment rendre les données partagées disponibles pour mon équipe etgérer les autorisations pour les schémas, les tables et les volumes dans un catalogue de partage Delta.
Lisez les objets de données partagés comme vous le feriez pour n’importe quel objet de données inscrit dans le catalogue Unity.
Pour plus d’informations et d’exemples, consultez Les données Access dans une table ou un volume partagé.
Python
Cette section explique comment utiliser un connecteur de partage ouvert pour accéder aux données partagées à l’aide d’un notebook dans votre espace de travail Azure Databricks. Vous ou un autre membre de votre équipe stockez le fichier d’informations d’identification dans Azure Databricks, puis vous l’utilisez pour vous authentifier auprès du compte Azure Databricks du fournisseur de données et lire les données que le fournisseur de données a partagées avec vous.
Remarque
Ces instructions supposent que votre espace de travail Azure Databricks n’est pas activé pour Unity Catalog. Si vous utilisez Unity Catalog, vous n’avez pas besoin de pointer vers le fichier des informations d’identification lorsque vous lisez à partir du partage. Vous pouvez lire à partir de tables partagées comme vous le faites à partir de n’importe quelle table inscrite dans le catalogue Unity. Databricks vous recommande d’utiliser l’interface utilisateur du fournisseur d’importation dans l’Explorateur de catalogues au lieu des instructions fournies ici.
Tout d’abord, utilisez un notebook Python dans Azure Databricks pour stocker le fichier d’informations d’identification afin que les utilisateurs de votre équipe puissent accéder aux données partagées.
Dans un éditeur de texte, ouvrez le fichier d’informations d’identification.
Dans votre espace de travail Azure Databricks, cliquez sur Nouveau > Notebook.
- Entrez un nom.
- Affectez Python comme langage par défaut du notebook.
- Sélectionnez un cluster à attacher au notebook.
- Cliquez sur Créer.
Le bloc-notes s’ouvre dans l’éditeur de bloc-notes.
Pour utiliser Python ou pandas afin d’accéder aux données partagées, installez le connecteur Python delta-sharing. Dans l’éditeur de notebook, collez la commande suivante :
%sh pip install delta-sharingExécutez la cellule.
La
delta-sharingbibliothèque Python est installée dans le cluster si elle n’est pas déjà installée.Dans une nouvelle cellule, collez la commande suivante, qui charge le contenu du fichier d’informations d’identification dans un dossier dans DBFS.
Remplacez les variables comme suit :
<dbfs-path>: chemin du dossier ou vous souhaitez enregistrer le fichier d’informations d’identification.<credential-file-contents>: contenu du fichier d’informations d’identification. Il ne s’agit pas d’un chemin d’accès au fichier, mais du contenu copié du fichier.Le fichier d’informations d’identification contient du code JSON qui définit trois champs :
shareCredentialsVersion,endpointetbearerToken.%scala dbutils.fs.put("<dbfs-path>/config.share",""" <credential-file-contents> """)
Exécutez la cellule.
Une fois le fichier d’informations d’identification chargé, vous pouvez supprimer cette cellule. Tous les utilisateurs d’espace de travail peuvent lire le fichier d’informations d’identification à partir de DBFS, et le fichier d’informations d’identification est disponible dans DBFS sur tous les clusters et entrepôts SQL dans votre espace de travail. Pour supprimer la cellule, cliquez sur x dans le menu
 tout à droite.
tout à droite.
Maintenant que le fichier d’informations d’identification est stocké, vous pouvez utiliser un bloc-notes pour répertorier et lire des tables partagées
À l’aide de Python, listez les tables dans le partage.
Dans la nouvelle cellule, collez la commande suivante. Remplacez
<dbfs-path>par le chemin d’accès créé ci-dessus.Lorsque le code s’exécute, Python lit le fichier d’informations d’identification à partir de DBFS sur le cluster. Accédez aux données stockées dans DBFS au niveau du chemin
/dbfs/.import delta_sharing client = delta_sharing.SharingClient(f"/dbfs/<dbfs-path>/config.share") client.list_all_tables()Exécutez la cellule.
Le résultat est un tableau de tables et des métadonnées pour chaque table. La sortie suivante montre deux tables :
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]Si la sortie est vide ou ne contient pas les tables attendues, contactez le fournisseur de données.
Interroger une table partagée.
Utilisation de Scala :
Dans la nouvelle cellule, collez la commande suivante. Lorsque le code s’exécute, le fichier d’informations d’identification est lu à partir de DBFS via JVM.
Remplacez les variables comme suit :
-
<profile-path>: chemin DBFS du fichier d’informations d’identification. Par exemple :/<dbfs-path>/config.share. -
<share-name>: valeur deshare=pour la table. -
<schema-name>: valeur deschema=pour la table. -
<table-name>: valeur dename=pour la table.
%scala spark.read.format("deltaSharing") .load("<profile-path>#<share-name>.<schema-name>.<table-name>").limit(10);Exécutez la cellule. Chaque fois que vous chargez la table partagée, vous voyez les données actualisées à partir de la source.
-
Avec SQL :
Pour interroger les données à l’aide de SQL, vous devez créer une table locale dans l’espace de travail à partir de la table partagée, puis interroger la table locale. Les données partagées ne sont pas stockées ou mises en cache dans la table locale. Chaque fois que vous interrogez la table locale, vous voyez l’état actuel des données partagées.
Dans la nouvelle cellule, collez la commande suivante.
Remplacez les variables comme suit :
-
<local-table-name>: nom de la table locale. -
<profile-path>: emplacement du fichier d’informations d’identification. -
<share-name>: valeur deshare=pour la table. -
<schema-name>: valeur deschema=pour la table. -
<table-name>: valeur dename=pour la table.
%sql DROP TABLE IF EXISTS table_name; CREATE TABLE <local-table-name> USING deltaSharing LOCATION "<profile-path>#<share-name>.<schema-name>.<table-name>"; SELECT * FROM <local-table-name> LIMIT 10;Lorsque vous exécutez la commande, les données partagées sont interrogées directement. En guise de test, la table est interrogée et les dix premiers résultats sont retournés.
-
Si la sortie est vide ou ne contient pas les données attendues, contactez le fournisseur de données.
Apache Spark : lire des données partagées
Effectuez ces étapes pour accéder à des données partagées dans Apache Spark 3. x ou version ultérieure.
Ces instructions supposent que vous avez accès au fichier d’informations d’identification partagé par le fournisseur de données. Consultez Obtenir l’accès dans le modèle de partage ouvert.
Remarque
Si vous utilisez Spark sur un espace de travail Azure Databricks activé pour Unity Catalog et que vous avez utilisé l’interface utilisateur du fournisseur d’importation pour importer le fournisseur et le partager, les instructions de cette section ne s’appliquent pas à vous. Vous pouvez accéder aux tables partagées comme vous le feriez pour n’importe quelle autre table inscrite dans le catalogue Unity. Vous n’avez pas besoin d’installer le delta-sharing connecteur Python ou de fournir le chemin d’accès au fichier d’informations d’identification. Consultez Azure Databricks : Lire des données partagées à l’aide de connecteurs de partage ouverts.
Installez les connecteurs Delta Sharing Python et Spark
Pour accéder aux métadonnées relatives aux données partagées, telles que la liste des tables partagées avec vous, suivez les étapes suivantes. Cet exemple utilise Python.
Installez le connecteur Delta Sharing Python :
pip install delta-sharingInstallez le connecteur Apache Spark.
Répertoriez les tables partagées à l’aide de Spark
Répertoriez les tables dans le partage. Dans l’exemple suivant, remplacez <profile-path> par l’emplacement du fichier d’informations d’identification.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Le résultat est un tableau de tables et des métadonnées pour chaque table. La sortie suivante montre deux tables :
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]
Si la sortie est vide ou ne contient pas les tables attendues, contactez le fournisseur de données.
Accédez aux données partagées à l’aide de Spark
Exécutez la commande suivante, en remplaçant ces variables :
-
<profile-path>: emplacement du fichier d’informations d’identification. -
<share-name>: valeur deshare=pour la table. -
<schema-name>: valeur deschema=pour la table. -
<table-name>: valeur dename=pour la table. -
<version-as-of>: facultatif. La version de la table dans laquelle charger les données. Fonctionne uniquement si le fournisseur de données partage l’historique de la table. Nécessitedelta-sharing-sparkla version 0.5.0 ou ultérieure. -
<timestamp-as-of>: facultatif. Chargez les données à la version avant ou à l’horodatage donné. Fonctionne uniquement si le fournisseur de données partage l’historique de la table. Nécessitedelta-sharing-sparkla version 0.6.0 ou ultérieure.
Python
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", version=<version-as-of>)
spark.read.format("deltaSharing")\
.option("versionAsOf", <version-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10))
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", timestamp=<timestamp-as-of>)
spark.read.format("deltaSharing")\
.option("timestampAsOf", <timestamp-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10))
Langage de programmation Scala
Exécutez la commande suivante, en remplaçant ces variables :
-
<profile-path>: emplacement du fichier d’informations d’identification. -
<share-name>: valeur deshare=pour la table. -
<schema-name>: valeur deschema=pour la table. -
<table-name>: valeur dename=pour la table. -
<version-as-of>: facultatif. La version de la table dans laquelle charger les données. Fonctionne uniquement si le fournisseur de données partage l’historique de la table. Nécessitedelta-sharing-sparkla version 0.5.0 ou ultérieure. -
<timestamp-as-of>: facultatif. Chargez les données à la version avant ou à l’horodatage donné. Fonctionne uniquement si le fournisseur de données partage l’historique de la table. Nécessitedelta-sharing-sparkla version 0.6.0 ou ultérieure.
spark.read.format("deltaSharing")
.option("versionAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
spark.read.format("deltaSharing")
.option("timestampAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
Accéder au flux de données modifiées partagées à l’aide de Spark
Si l’historique de la table a été partagé avec vous et que le flux de données modifiées (CDF) est activé sur la table source, vous pouvez accéder au flux de données modifiées en exécutant ce qui suit, en remplaçant ces variables. Nécessite delta-sharing-spark la version 0.5.0 ou ultérieure.
Un seul paramètre de début doit être fourni.
-
<profile-path>: emplacement du fichier d’informations d’identification. -
<share-name>: valeur deshare=pour la table. -
<schema-name>: valeur deschema=pour la table. -
<table-name>: valeur dename=pour la table. -
<starting-version>: facultatif. Version de départ de la requête, inclusive. Spécifiez le type Long. -
<ending-version>: facultatif. Version finale de la requête, incluse. Si la version finale n’est pas fournie, l’API utilise la dernière version de la table. -
<starting-timestamp>: facultatif. Timestamp de début de la requête, converti en version créée à une date ultérieure ou égale à ce timestamp. Spécifiez-le sous forme de chaîne au formatyyyy-mm-dd hh:mm:ss[.fffffffff]. -
<ending-timestamp>: facultatif. Le timestamp de fin de la requête est converti en version créée antérieurement ou égale à ce timestamp. Spécifiez-le sous forme de chaîne au formatyyyy-mm-dd hh:mm:ss[.fffffffff]
Python
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("statingVersion", <starting-version>)\
.option("endingVersion", <ending-version>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingTimestamp", <starting-timestamp>)\
.option("endingTimestamp", <ending-timestamp>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Langage de programmation Scala
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("statingVersion", <starting-version>)
.option("endingVersion", <ending-version>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingTimestamp", <starting-timestamp>)
.option("endingTimestamp", <ending-timestamp>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Si la sortie est vide ou ne contient pas les données attendues, contactez le fournisseur de données.
Accéder à une table partagée à l’aide de Spark Structured Streaming
Si l’historique de la table est partagé avec vous, vous pouvez lire en continu les données partagées. Nécessite delta-sharing-spark la version 0.6.0 ou ultérieure.
Options prises en charge :
-
ignoreDeletes: ignorer les transactions qui suppriment des données. -
ignoreChanges: retraiter les mises à jour si les fichiers ont dû être réécrits dans la table source en raison d’une opération de modification des données telle queUPDATE,MERGE INTO,DELETE(dans les partitions) ouOVERWRITE. Des lignes inchangées peuvent toujours être émises. Par conséquent, vos consommateurs en aval doivent être en mesure de gérer les doublons. Les suppressions ne sont pas propagées en aval.ignoreChangesenglobeignoreDeletes. Par conséquent, si vous utilisezignoreChanges, votre flux n’est pas interrompu par des suppressions ou des mises à jour de la table source. -
startingVersion: version de table partagée à partir de laquelle démarrer. Toutes les modifications de table à partir de cette version (incluse) seront lues par la source de streaming. -
startingTimestamp: Timestamp de départ. Toutes les modifications de table validées à partir de ce timestamp (inclus) seront lues par la source de streaming. Exemple :"2023-01-01 00:00:00.0". -
maxFilesPerTrigger: nombre de nouveaux fichiers à prendre en compte dans chaque micro-lot. -
maxBytesPerTrigger: quantité de données traitées dans chaque micro-lot. Cette option définit une valeur « soft max », qui signifie qu’un lot traite approximativement cette quantité de données et peut traiter plus que la limite afin de faire avancer la requête de streaming dans les cas où la plus petite unité d’entrée est supérieure à cette limite. -
readChangeFeed: diffuser en continu le flux de changements de données de la table partagée.
Options non prises en charge :
Trigger.availableNow
Exemples de requêtes Structured Streaming
Langage de programmation Scala
spark.readStream.format("deltaSharing")
.option("startingVersion", 0)
.option("ignoreChanges", true)
.option("maxFilesPerTrigger", 10)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Python
spark.readStream.format("deltaSharing")\
.option("startingVersion", 0)\
.option("ignoreDeletes", true)\
.option("maxBytesPerTrigger", 10000)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Consultez également les concepts de diffusion en continu structuré.
Lire les tables avec un mappage de colonnes ou des vecteurs de suppression activés
Important
Cette fonctionnalité est disponible en préversion publique.
Les vecteurs de suppression sont une fonctionnalité d’optimisation du stockage que votre fournisseur peut activer sur les tables Delta partagées. Consultez Que sont les vecteurs de suppression ?.
Azure Databricks prend également en charge le mappage de colonnes pour des tables Delta. Consultez Renommage et suppression des colonnes avec le mappage de colonnes Delta Lake.
Si votre fournisseur a partagé une table avec un mappage de colonne ou des vecteurs de suppression activés, vous pouvez lire la table à l’aide du calcul qui exécute delta-sharing-spark 3.1 ou une version ultérieure. Si vous utilisez des clusters Databricks, vous pouvez effectuer des lectures par lots à l’aide d’un cluster exécutant Databricks Runtime 14.1 ou version ultérieure. Les requêtes CDF et de streaming nécessitent Databricks Runtime 14.2 ou version ultérieure.
Vous pouvez effectuer des requêtes par lots telles quelles, car elles peuvent résoudre automatiquement responseFormat en fonction des fonctionnalités de table de la table partagée.
Pour lire un flux des changements de données (CDF) ou pour effectuer des requêtes de streaming sur des tables partagées avec des vecteurs de suppression ou un mappage de colonnes activé, vous devez définir l’option supplémentaire responseFormat=delta.
Les exemples suivants montrent les requêtes batch, CDF et de streaming :
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("...")
.master("...")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
// Batch query
spark.read.format("deltaSharing").load(tablePath)
// CDF query
spark.read.format("deltaSharing")
.option("readChangeFeed", "true")
.option("responseFormat", "delta")
.option("startingVersion", 1)
.load(tablePath)
// Streaming query
spark.readStream.format("deltaSharing").option("responseFormat", "delta").load(tablePath)
Pandas : lire les données partagées
Effectuez ces étapes pour accéder à des données partagées dans pandas 0.25.3 ou version ultérieure.
Ces instructions supposent que vous avez accès au fichier d’informations d’identification partagé par le fournisseur de données. Consultez Obtenir l’accès dans le modèle de partage ouvert.
Remarque
Si vous utilisez pandas sur un espace de travail Azure Databricks activé pour Unity Catalog et que vous avez utilisé l’interface utilisateur du fournisseur d’importation pour importer le fournisseur et le partager, les instructions de cette section ne s’appliquent pas à vous. Vous pouvez accéder aux tables partagées comme vous le feriez pour n’importe quelle autre table inscrite dans le catalogue Unity. Vous n’avez pas besoin d’installer le delta-sharing connecteur Python ou de fournir le chemin d’accès au fichier d’informations d’identification. Consultez Azure Databricks : Lire des données partagées à l’aide de connecteurs de partage ouverts.
Installer le connecteur Delta Sharing Python
Pour accéder aux métadonnées relatives aux données partagées, telles que la liste des tables partagées avec vous, vous devez installer le connecteur Delta Sharing Python.
pip install delta-sharing
Répertoriez les tables partagées en utilisant Pandas
Pour répertorier les tables dans le partage, exécutez la commande suivante, en remplaçant <profile-path>/config.share par l’emplacement du fichier d’informations d’identification.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Si la sortie est vide ou ne contient pas les tables attendues, contactez le fournisseur de données.
Accéder aux données partagées à l’aide de pandas
Pour accéder aux données partagées dans pandas à l’aide de Python, exécutez la commande suivante, en remplaçant les variables comme suit :
-
<profile-path>: emplacement du fichier d’informations d’identification. -
<share-name>: valeur deshare=pour la table. -
<schema-name>: valeur deschema=pour la table. -
<table-name>: valeur dename=pour la table.
import delta_sharing
delta_sharing.load_as_pandas(f"<profile-path>#<share-name>.<schema-name>.<table-name>")
Accéder à un flux de données modifiées partagé en utilisant Pandas
Pour accéder au flux de données de modification d’une table partagée dans pandas à l’aide de Python, exécutez la commande suivante, en remplaçant les variables comme suit. Un flux de données modifiées peut ne pas être disponible, selon que le fournisseur de données a partagé ou non le flux de données modifiées pour la table.
-
<starting-version>: facultatif. Version de départ de la requête, inclusive. -
<ending-version>: facultatif. Version finale de la requête, incluse. -
<starting-timestamp>: facultatif. Timestamp de début de la requête. Il est converti en version créée à une date ultérieure ou égale à cet horodateur. -
<ending-timestamp>: facultatif. Timestamp de fin de la requête. Il est converti en version créée antérieure ou égale à cet horodateur.
import delta_sharing
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<starting-version>)
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
Si la sortie est vide ou ne contient pas les données attendues, contactez le fournisseur de données.
Power BI : lire des données partagées
Le connecteur Delta Sharing Power BI vous permet de découvrir, d’analyser et de visualiser les jeux de données partagés avec vous via le protocole ouvert Delta Sharing.
Spécifications
- Power BI Desktop 2.99.621.0 ou version ultérieure
- Accès au fichier d’informations d’identification partagé par le fournisseur de données. Consultez Obtenir l’accès dans le modèle de partage ouvert.
Se connecter à Databricks
Pour vous connecter à Azure Databricks à l’aide du connecteur Delta Sharing, suivez les étapes suivantes :
- Ouvrez le fichier d’informations d’identification à l’aide d’un éditeur de texte pour récupérer l’URL du point de terminaison ainsi que le jeton.
- Ouvrez Power BI Desktop.
- Dans le menu Obtenir des données, recherchez Delta Sharing.
- Sélectionnez le connecteur et cliquez sur Se connecter.
- Entrez l’URL du point de terminaison que vous avez copiée à partir du fichier d’informations d’identification dans le champ Delta Sharing Server URL (URL du serveur Delta Sharing).
- Sous l’onglet Options avancées, vous pouvez également définir une limite de lignes afin de limiter le nombre maximal de lignes qu’il est possible de télécharger. Par défaut, cette valeur est définie sur 1 million de lignes.
- Cliquez sur OK.
- Pour Authentification, copiez le jeton que vous avez récupéré à partir du fichier d’informations d’identification dans le champ Jeton du porteur.
- Cliquez sur Connecter.
Limitations du connecteur Delta Sharing Power BI
Le connecteur Delta Sharing Power BI présente les limitations suivantes :
- Les données qui sont chargées par le connecteur doivent pouvoir toutes être contenues dans la mémoire de votre ordinateur. Pour gérer cette exigence, le connecteur limite le nombre de lignes importées à la limite de lignes que vous définissez sous l’onglet Options avancées dans Power BI Desktop.
Tableau : lire les données partagées
Le connecteur Tableau Delta Sharing vous permet de découvrir, d’analyser et de visualiser les jeux de données qui sont partagés avec vous via le protocole ouvert Delta Sharing.
Spécifications
- Tableau Desktop et Tableau Server 2024.1 ou version ultérieure
- Accès au fichier d’informations d’identification partagé par le fournisseur de données. Consultez Obtenir l’accès dans le modèle de partage ouvert.
Se connecter à Azure Databricks
Pour vous connecter à Azure Databricks à l’aide du connecteur Delta Sharing, suivez les étapes suivantes :
- Accédez à Tableau Exchange, suivez les instructions pour télécharger le connecteur de partage Delta et placez-le dans un dossier de bureau approprié.
- Ouvrez Tableau Desktop.
- Dans la page Connecteurs, recherchez « Partage delta par Databricks ».
- Sélectionnez Charger un fichier de partage, puis choisissez le fichier d’informations d’identification partagé par le fournisseur.
- Cliquez sur Get Data (Obtenir les données).
- Dans l’Explorateur de données, sélectionnez la table.
- Ajoutez éventuellement des filtres SQL ou des limites de ligne.
- Cliquez sur Obtenir des données de table.
Limitations du connecteur Tableau Delta Sharing
Le connecteur Tableau Delta Sharing présente les limitations suivantes :
- Les données qui sont chargées par le connecteur doivent pouvoir toutes être contenues dans la mémoire de votre ordinateur. Pour gérer cette exigence, le connecteur limite le nombre de lignes importées à la limite de lignes que vous avez définie dans Tableau.
- Toutes les colonnes sont retournées en tant que type
String. - Le filtre SQL fonctionne uniquement si votre serveur de partage Delta prend en charge le predicateHint.
- Les vecteurs de suppression ne sont pas pris en charge.
Demander une nouvelle autorisation
Si l’URL d’activation de vos informations d’identification ou vos informations d’identification téléchargées sont perdues, endommagées ou compromises, ou si vos informations d’identification expirent sans que votre fournisseur ne vous en envoie de nouvelles, contactez votre fournisseur pour demander de nouvelles informations d’identification.