Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les pipelines peuvent contenir de nombreux jeux de données avec de nombreux flux pour les maintenir à jour. Les pipelines gèrent automatiquement les mises à jour et les clusters pour les mettre à jour efficacement. Toutefois, il existe une surcharge avec la gestion d’un grand nombre de flux, et parfois, cela peut entraîner une initialisation plus grande que prévu ou même une surcharge de gestion pendant le traitement.
Si vous rencontrez des retards en attendant que les pipelines déclenchés s'initialisent, tels que des temps d’initialisation supérieurs à cinq minutes, envisagez de fractionner le traitement en plusieurs pipelines, même lorsque les jeux de données utilisent les mêmes données source.
Note
Les pipelines déclenchés effectuent les étapes d’initialisation chaque fois qu’ils sont déclenchés. Les pipelines continus effectuent uniquement les étapes d’initialisation lorsqu’ils sont arrêtés et redémarrés. Cette section est la plus utile pour optimiser l’initialisation d’un pipeline activé.
Quand envisager de fractionner un pipeline
Il existe plusieurs cas où le fractionnement d’un pipeline peut être avantageux pour des raisons de performances.
- Les phases
INITIALIZINGetSETTING_UP_TABLESprennent plus de temps que vous le souhaitez, ce qui impacte le temps total de votre pipeline. Si cela dure plus de 5 minutes, souvent, la performance est améliorée en fractionnant le pipeline. - Le pilote qui gère le cluster peut devenir un goulot d’étranglement lors de l’exécution de nombreuses tables de streaming (plus de 30 à 40) au sein d’un seul pipeline. Si votre pilote ne répond pas, vos durées pour les requêtes de diffusion en continu augmenteront, ce qui affectera le temps total de votre mise à jour.
- Un pipeline déclenché avec plusieurs flux de tables en streaming pourrait ne pas être capable d'effectuer toutes les mises à jour de flux pouvant être parallélisées en parallèle.
Détails sur les problèmes de performances
Cette section décrit certains des problèmes de performances qui peuvent survenir à partir de nombreuses tables et flux dans un seul pipeline.
Goulots d’étranglement dans les phases INITIALISATION et CONFIGURATION_DES_TABLES
Les phases initiales de l’exécution peuvent être un goulot d’étranglement des performances, en fonction de la complexité du pipeline.
PHASE D’INITIALISATION
Pendant cette phase, les plans logiques sont créés, y compris les plans de création du graphique de dépendances et la détermination de l’ordre des mises à jour de table.
phase de Configuration des tables
Au cours de cette phase, les processus suivants sont effectués, en fonction des plans créés dans la phase précédente :
- Validation et résolution du schéma pour toutes les tables définies dans le pipeline.
- Générez le graphe de dépendances et déterminez l’ordre d’exécution des tables.
- Vérifiez si chaque jeu de données est actif dans le pipeline ou est nouveau depuis toute mise à jour précédente.
- Créez des tables de streaming dans la première mise à jour et, pour les vues matérialisées, créez des vues temporaires ou des tables de sauvegarde requises pendant chaque mise à jour du pipeline.
Pourquoi l'initialisation et la configuration des tables peuvent prendre plus longtemps
Les grands pipelines avec de nombreux flux pour de nombreux jeux de données peuvent prendre plus de temps pour plusieurs raisons :
- Pour les pipelines avec de nombreux flux et dépendances complexes, ces phases peuvent prendre plus de temps en raison du volume de travail à effectuer.
- Les transformations complexes, y compris
Auto CDCles transformations, peuvent créer un goulot d’étranglement des performances, en raison des opérations nécessaires pour générer les tables à partir des transformations définies. - Il existe également des scénarios où un nombre significatif de flux peut entraîner une lenteur, même si ces flux ne font pas partie d’une mise à jour. Prenons l’exemple d’un pipeline comportant plus de 700 flux, dont moins de 50 sont mis à jour pour chaque déclencheur, en fonction d’une configuration. Dans cet exemple, chaque exécution doit parcourir certaines des étapes de toutes les 700 tables, obtenir les trames de données, puis sélectionner celles à exécuter.
Goulots d’étranglement dans le pilote logiciel
Le pilote gère les mises à jour au sein de l’exécution. Il doit exécuter une logique pour chaque table afin de décider quelles instances d’un cluster doivent gérer chaque flux. Lors de l’exécution de plusieurs tables de streaming (plus de 30 à 40) au sein d’un seul pipeline, le pilote peut devenir un goulot d’étranglement pour les ressources du processeur, car il gère le travail sur le cluster.
Le pilote peut également rencontrer des problèmes de mémoire. Cela peut se produire plus souvent lorsque le nombre de flux parallèles est de 30 ou plus. Il n’existe pas de nombre spécifique de flux ou de jeux de données qui peuvent entraîner des problèmes de mémoire de pilote, mais qui dépendent de la complexité des tâches qui s’exécutent en parallèle.
Les flux de streaming peuvent s’exécuter en parallèle, mais cela nécessite que le pilote utilise simultanément la mémoire et le processeur pour tous les flux. Dans un pipeline déclenché, le pilote peut traiter un sous-ensemble de flux en parallèle à la fois, afin d’éviter les contraintes de mémoire et d’UC.
Dans tous ces cas, le fractionnement des pipelines afin qu’il existe un ensemble optimal de flux dans chacun d’eux peut accélérer l’initialisation et le temps de traitement.
Compromis liés à la division des pipelines
Lorsque tous vos flux se trouvent dans le même pipeline, Lakeflow Spark Declarative Pipelines gère les dépendances pour vous. Lorsqu’il existe plusieurs pipelines, vous devez gérer les dépendances entre les pipelines.
Dépendances Vous pouvez avoir un pipeline en aval qui dépend de plusieurs pipelines en amont (au lieu d’un). Par exemple, si vous avez trois pipelines,
pipeline_A,pipeline_B, etpipeline_C, et quepipeline_Cdépend des deuxpipeline_Aetpipeline_B, vous souhaitez quepipeline_Cse mette à jour uniquement après quepipeline_Aetpipeline_Baient terminé leurs mises à jour respectives. Une façon de résoudre ce problème consiste à orchestrer les dépendances en faisant de chaque pipeline une tâche dans un job avec les dépendances correctement modélisées, de sorte quepipeline_Cne soit mis à jour qu'après quepipeline_Aetpipeline_Bsont terminés.Concurrence Vous pourriez avoir différents flux dans un pipeline qui prennent des durées très différentes pour se terminer, par exemple, si
flow_Ase met à jour en 15 secondes et queflow_Bprend plusieurs minutes. Il peut être utile d’examiner les heures de requête avant de fractionner vos pipelines et de regrouper des requêtes plus courtes ensemble.
Planifier le fractionnement de vos pipelines
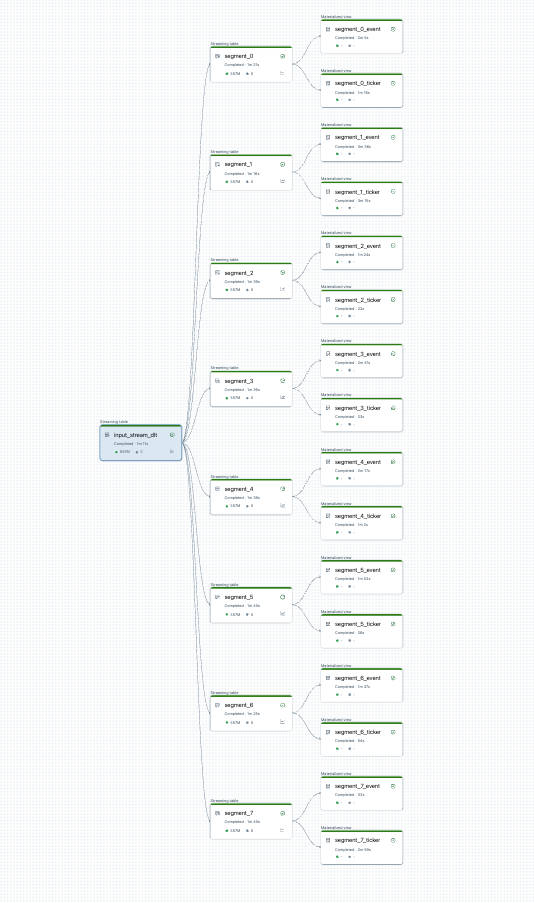
Vous pouvez visualiser votre fractionnement de pipeline avant de commencer. Voici un graphique d’un pipeline source qui traite 25 tables. Une source de données racine unique est divisée en 8 segments, chacun ayant 2 vues.
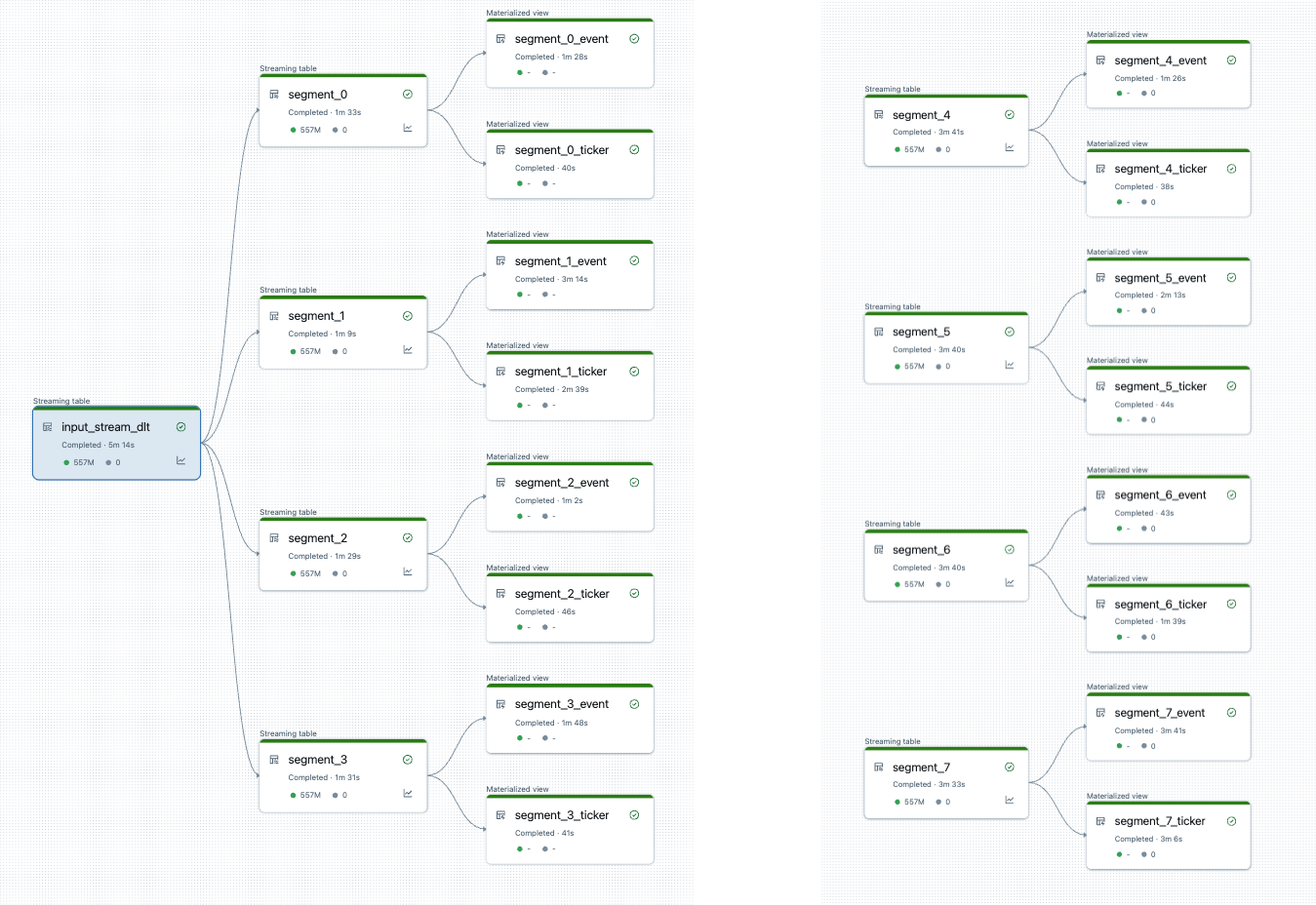
Après le fractionnement du pipeline, il existe deux pipelines. Un traite la source de données primaires, ainsi que 4 segments et leurs vues associées. Le deuxième pipeline traite les 4 autres segments et leurs vues qui leur sont associées. Le deuxième pipeline s’appuie sur le premier pour mettre à jour la source de données racine.
Fractionner le pipeline sans actualisation complète
Une fois que vous avez planifié votre fractionnement de pipelines, créez, si nécessaire, de nouveaux pipelines et déplacez les tables entre les pipelines pour équilibrer la charge des pipelines. Vous pouvez déplacer des tables sans provoquer une actualisation complète.
Pour en savoir plus, consultez Déplacer des tables entre des pipelines.
Il existe certaines limitations avec cette approche :
- Les pipelines doivent se trouver dans le catalogue Unity.
- Les pipelines source et de destination doivent se trouver dans le même espace de travail. Les déplacements inter-espaces de travail ne sont pas pris en charge.
- Le pipeline de destination doit être créé et exécuté une fois (même s’il échoue) avant le déplacement.
- Vous ne pouvez pas déplacer une table d’un pipeline qui utilise le mode de publication par défaut vers celui qui utilise le mode de publication hérité. Pour plus d’informations, consultez le schéma LIVE (hérité).