Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans l’ingénierie des données, le remplissage fait référence au processus de traitement rétroactif des données historiques par le biais d’un pipeline de données conçu pour traiter les données actuelles ou de diffusion en continu.
En règle générale, il s’agit d’un flux distinct qui envoie des données dans vos tables existantes. L’illustration suivante montre un flux de remplissage envoyant des données historiques aux tables bronze de votre pipeline.
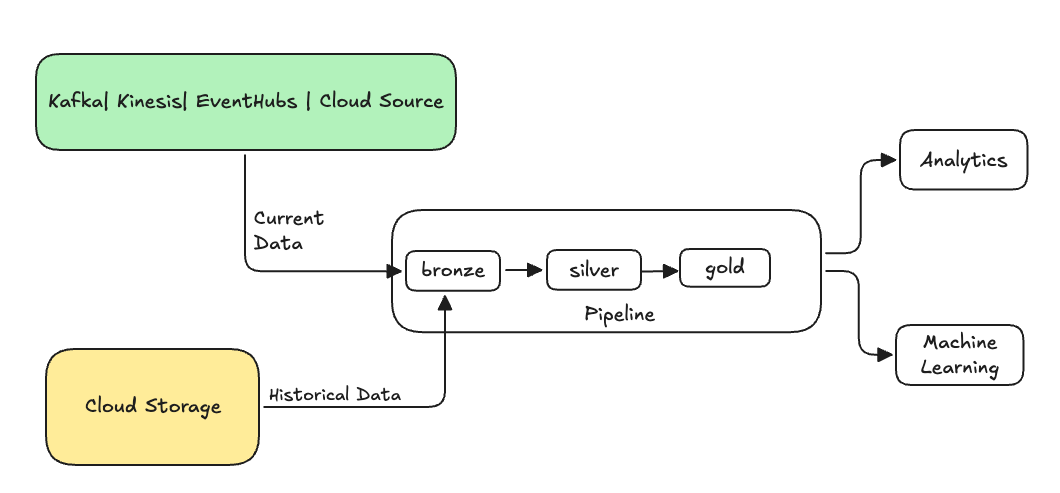
Certains scénarios qui peuvent nécessiter un remblai :
- Traitez les données historiques d’un système hérité pour entraîner un modèle Machine Learning (ML) ou créer un tableau de bord d’analyse de tendance historique.
- Retraitez un sous-ensemble de données en raison d’un problème de qualité des données liées aux sources de données en amont.
- Vos besoins métier ont changé et vous devez renvoyer des données pour une période différente qui n’a pas été couverte par le pipeline initial.
- Votre logique métier a changé et vous devez retraiter les données historiques et actuelles.
Un réapprovisionnement dans les pipelines déclaratifs Spark Lakeflow est pris en charge avec un flux d’ajout spécialisé qui utilise l’option ONCE . Pour plus d’informations sur l’option, consultez append_flow ou ONCE
Considérations relatives au remplissage des données historiques dans une table de flux
- En règle générale, ajoutez les données à la table de streaming bronze. Les couches d’argent et d’or en aval récupèrent les nouvelles données de la couche bronze.
- Vérifiez que votre pipeline peut gérer correctement les données dupliquées au cas où les mêmes données sont ajoutées plusieurs fois.
- Vérifiez que le schéma de données historiques est compatible avec le schéma de données actuel.
- Tenez compte de la taille du volume de données et du contrat SLA de temps de traitement requis, et configurez en conséquence les tailles de cluster et de lot.
Exemple : ajout d’un remplissage à un pipeline existant
Dans cet exemple, supposons que vous disposez d’un pipeline qui ingère des données brutes d’inscription d’événements à partir d’une source de stockage cloud, à compter du 01 janvier 2025. Vous réalisez ultérieurement que vous souhaitez compléter rétroactivement les trois années précédentes de données historiques pour les besoins d'analyse et de rapports en aval. Toutes les données se trouvent à un emplacement, partitionnés par année, mois et jour, au format JSON.
Pipeline initiale
Voici le code de pipeline de démarrage qui ingère de façon incrémentielle les données d’inscription d’événements brutes à partir du stockage cloud.
Python
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
incremental_load_path = f"{source_root_path}/*/*/*"
# create a streaming table and the default flow to ingest streaming events
@dp.table(name="registration_events_raw", comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2025-01-01T00:00:00.000+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}") # safeguard to not process data before begin_year
)
SQL
-- create a streaming table and the default flow to ingest streaming events
CREATE OR REFRESH STREAMING LIVE TABLE registration_events_raw AS
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025'; -- safeguard to not process data before begin_year
Ici, nous utilisons l’option modifiedAfter Chargeur automatique pour nous assurer que nous ne traitons pas toutes les données à partir du chemin de stockage cloud. Le traitement incrémentiel est arrêté à cette frontière.
Conseil / Astuce
D’autres sources de données, telles que Kafka, Blobs et Azure Event Hubs, ont des options de lecture équivalentes pour obtenir le même comportement.
Remplissage des données des 3 dernières années
Vous souhaitez maintenant ajouter un ou plusieurs flux pour recharger les données précédentes. Dans cet exemple, procédez comme suit :
- Utilisez le
append onceflux. Cela effectue un remplissage unique sans continuer à s’exécuter après ce premier remplissage. Le code reste dans votre pipeline et, si le pipeline est toujours entièrement actualisé, le remplissage est réexécuté. - Créez trois flux de remplissage, un pour chaque année (dans ce cas, les données sont divisées par année dans le chemin). Pour Python, nous paramétrons la création des flux, mais dans SQL, nous répétons le code trois fois, une fois pour chaque flux.
Si vous travaillez sur votre propre projet et que vous n’utilisez pas de calcul sans serveur, vous pouvez ajuster le nombre maximum de travailleurs pour le pipeline. L’augmentation du nombre maximal de workers garantit que vous disposez des ressources nécessaires pour traiter les données historiques tout en continuant à traiter les données de streaming actuelles dans le contrat SLA attendu.
Conseil / Astuce
Si vous utilisez le calcul serverless avec une mise à l’échelle automatique améliorée (valeur par défaut), votre cluster augmente automatiquement quand votre charge augmente.
Python
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
backfill_years = spark.conf.get("backfill_years") # e.g. "2024,2023,2022"
incremental_load_path = f"{source_root_path}/*/*/*"
# meta programming to create append once flow for a given year (called later)
def setup_backfill_flow(year):
backfill_path = f"{source_root_path}/year={year}/*/*"
@dp.append_flow(
target="registration_events_raw",
once=True,
name=f"flow_registration_events_raw_backfill_{year}",
comment=f"Backfill {year} Raw registration events")
def backfill():
return (
spark
.read
.format("json")
.option("inferSchema", "true")
.load(backfill_path)
)
# create the streaming table
dp.create_streaming_table(name="registration_events_raw", comment="Raw registration events")
# append the original incremental, streaming flow
@dp.append_flow(
target="registration_events_raw",
name="flow_registration_events_raw_incremental",
comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2024-12-31T23:59:59.999+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}")
)
# parallelize one time multi years backfill for faster processing
# split backfill_years into array
for year in backfill_years.split(","):
setup_backfill_flow(year) # call the previously defined append_flow for each year
SQL
-- create the streaming table
CREATE OR REFRESH STREAMING TABLE registration_events_raw;
-- append the original incremental, streaming flow
CREATE FLOW
registration_events_raw_incremental
AS INSERT INTO
registration_events_raw BY NAME
SELECT * FROM STREAM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025';
-- one time backfill 2024
CREATE FLOW
registration_events_raw_backfill_2024
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2024/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2023
CREATE FLOW
registration_events_raw_backfill_2023
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2023/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2022
CREATE FLOW
registration_events_raw_backfill_2022
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2022/*/*",
format => "json",
inferColumnTypes => true
);
Cette implémentation met en évidence plusieurs modèles importants.
Séparation des responsabilités
- Le traitement incrémentiel est indépendant des opérations de remplissage.
- Chaque flux a ses propres paramètres de configuration et d’optimisation.
- Il existe une distinction claire entre les opérations incrémentielles et de remplissage.
Exécution contrôlée
- L’utilisation de l’option
ONCEgarantit que chaque remplissage s’exécute exactement une fois. - Le flux de remplissage reste dans le graphique de pipeline, mais devient inactif une fois terminé. Il est prêt à être utilisé lors de l’actualisation complète, automatiquement.
- Il existe une piste d’audit claire des opérations de remplissage dans la définition du pipeline.
Optimisation du traitement
- Vous pouvez diviser le large lot de données à remplir en plusieurs lots plus petits pour un traitement plus rapide ou pour mieux contrôler le processus.
- L'utilisation de l'autoscaling amélioré adapte dynamiquement la taille du cluster en fonction de sa charge actuelle.
Évolution du schéma
- L'utilisation de
schemaEvolutionMode="addNewColumns"gère les changements de schéma sans problème. - Vous disposez d’une inférence de schéma cohérente entre les données historiques et actuelles.
- Il existe une gestion sécurisée des nouvelles colonnes dans les données plus récentes.