Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Remarque
La version open source de Hyperopt n’est plus conservée.
Hyperopt n’est pas inclus dans Databricks Runtime pour Machine Learning après 16.4 LTS ML. Azure Databricks recommande d’utiliser Optuna pour l’optimisation sur un seul nœud ou RayTune pour une expérience similaire à la fonctionnalité de réglage des hyperparamètres distribuée d’Hyperopt supprimée. En savoir plus sur l’utilisation de RayTune sur Azure Databricks.
Cet exemple de notebook montre comment mettre à l’échelle l'optimisation des hyperparamètres d'une seule machine sur un cluster Azure Databricks à l’aide d’Hyperopt avec SparkTrials. Ajustement d'un classifieur SVM scikit-learn sur le jeu de données Iris, vous créez d'abord un flux de travail sur une seule machine fmin(), puis vous le parallélisez sur les workers Spark, MLflow assurant automatiquement le suivi de chaque essai.
Importer des packages requis et charger un jeu de données
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
from hyperopt import fmin, tpe, hp, SparkTrials, STATUS_OK, Trials
# If you are running Databricks Runtime for Machine Learning, `mlflow` is already installed and you can skip the following line.
import mlflow
# Load the iris dataset from scikit-learn
iris = iris = load_iris()
X = iris.data
y = iris.target
Partie 1. Flux de travail Hyperopt à machine unique
Voici les étapes d’un flux de travail Hyperopt :
- Définissez une fonction à réduire.
- Définissez un espace de recherche sur des hyperparamètres.
- Sélectionnez un algorithme de recherche.
- Exécutez l’algorithme de réglage avec Hyperopt
fmin().
Pour plus d’informations, consultez la documentation Hyperopt.
Définir une fonction pour réduire
Dans cet exemple, nous utilisons un classifieur à vecteurs de support. L’objectif est de trouver la meilleure valeur pour le paramètre Cde régularisation.
La plupart du code d’un flux de travail Hyperopt se trouve dans la fonction objective. Cet exemple utilise le classifieur à vecteurs de support de scikit-learn.
Si votre cluster utilise Databricks Runtime 11.3 ML, modifiez le classificateur à vecteurs de support pour qu'il prenne un argument positionnel. clf = SVC(C)
def objective(C):
# Create a support vector classifier model
clf = SVC(C=C)
# Use the cross-validation accuracy to compare the models' performance
accuracy = cross_val_score(clf, X, y).mean()
# Hyperopt tries to minimize the objective function. A higher accuracy value means a better model, so you must return the negative accuracy.
return {'loss': -accuracy, 'status': STATUS_OK}
Définir l’espace de recherche sur les hyperparamètres
Pour plus d’informations sur la définition d’un espace de recherche et d’expressions de paramètre, consultez la documentation Hyperopt .
search_space = hp.lognormal('C', 0, 1.0)
Sélectionner un algorithme de recherche
Les deux principaux choix sont les suivants :
-
hyperopt.tpe.suggest: Arborescence des estimateurs parzen, une approche bayésienne qui sélectionne de manière itérative et adaptative les nouveaux paramètres d’hyperparamètres à explorer en fonction des résultats passés -
hyperopt.rand.suggest: Recherche aléatoire, approche non adaptative qui échantillonne sur l’espace de recherche
algo=tpe.suggest
Exécuter l’algorithme de réglage avec Hyperopt fmin()
Définissez max_evals le nombre maximal de points dans l’espace hyperparamètre à tester, c’est-à-dire le nombre maximal de modèles à ajuster et à évaluer.
argmin = fmin(
fn=objective,
space=search_space,
algo=algo,
max_evals=16)
# Print the best value found for C
print("Best value found: ", argmin)
Partie 2. Réglage distribué à l’aide d’Apache Spark et de MLflow
Pour distribuer le réglage, ajoutez un autre argument à fmin(): une Trials classe appelée SparkTrials.
SparkTrials prend 2 arguments facultatifs :
-
parallelism: nombre de modèles à ajuster et à évaluer simultanément. La valeur par défaut est le nombre d’emplacements de tâches Spark disponibles. -
timeout: durée maximale (en secondes) pendant laquellefmin()peut s'exécuter. La valeur par défaut n’est pas limite de temps maximale.
Cet exemple utilise la fonction objective très simple définie dans Cmd 7. Dans ce cas, la fonction s’exécute rapidement et la surcharge de démarrage des travaux Spark domine le temps de calcul, de sorte que les calculs pour le cas distribué prennent plus de temps. Pour les problèmes typiques du monde réel, la fonction objective est plus complexe et l'utilisation de SparkTrails pour distribuer les calculs est plus rapide que l'optimisation sur une seule machine.
Le suivi MLflow automatisé est activé par défaut. Pour l’utiliser, appelez mlflow.start_run() avant d’appeler fmin() comme indiqué dans l’exemple.
from hyperopt import SparkTrials
# To display the API documentation for the SparkTrials class, uncomment the following line.
# help(SparkTrials)
spark_trials = SparkTrials()
with mlflow.start_run():
argmin = fmin(
fn=objective,
space=search_space,
algo=algo,
max_evals=16,
trials=spark_trials)
# Print the best value found for C
print("Best value found: ", argmin)
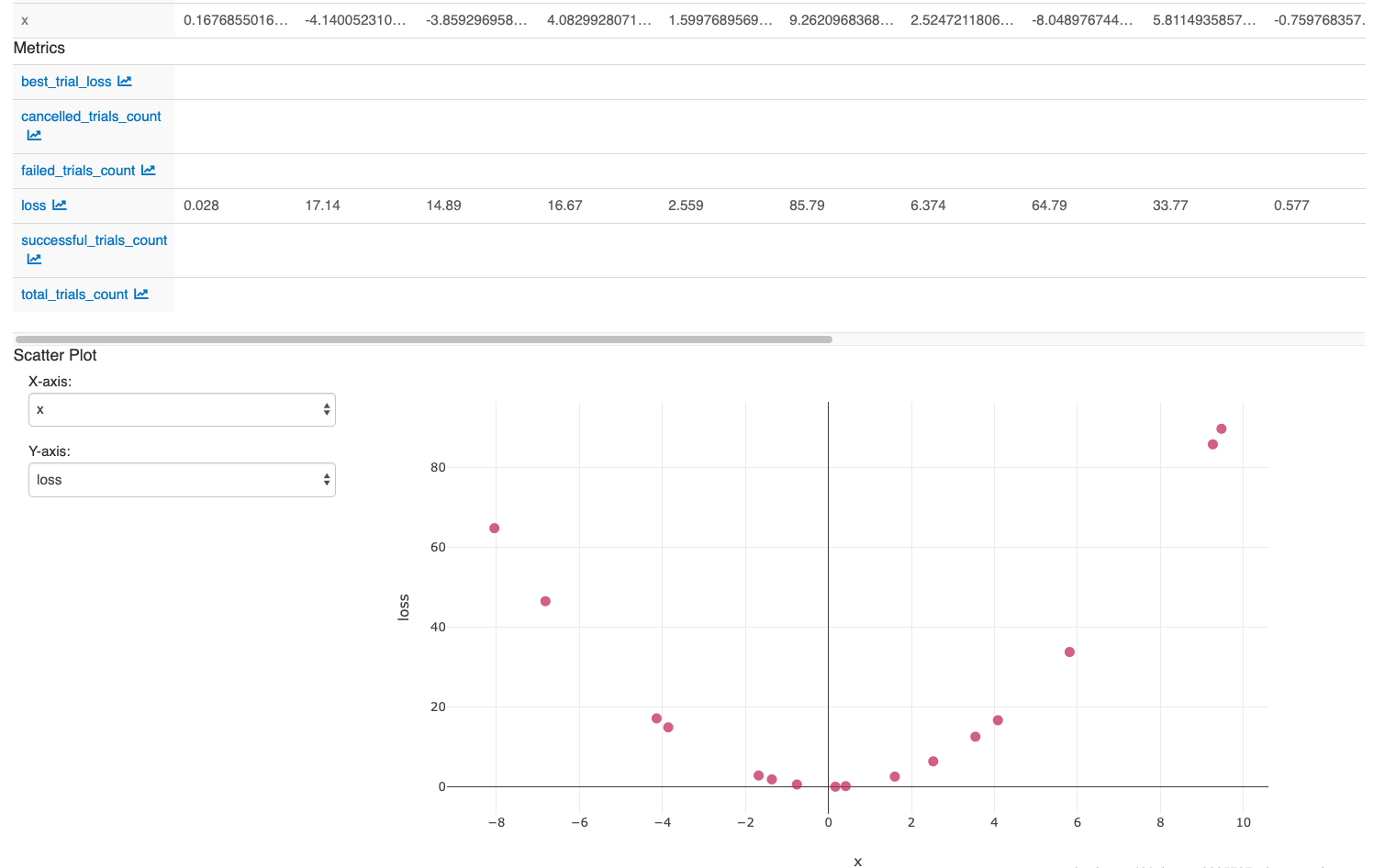
Pour afficher l’expérience MLflow associée au bloc-notes, cliquez sur l’icône Expérience dans la barre de contexte du bloc-notes en haut à droite. Là, vous pouvez afficher toutes les exécutions de tâches. Pour afficher les exécutions dans l'interface utilisateur MLflow, cliquez sur l'icône située à l'extrême droite à côté de exécutions d'expériences.
Pour examiner l’effet du réglage C:
- Sélectionnez les exécutions obtenues, puis cliquez sur Comparer.
- Dans le nuage de points, sélectionnez C pour l’axe X et loss pour l’axe Y.
Une fois que vous avez effectué les actions dans la dernière cellule du bloc-notes, votre interface utilisateur MLflow doit afficher :