Utiliser des tables en ligne pour la mise en service de fonctionnalités en temps réel
Important
Les tables en ligne sont en préversion publique. Pendant la préversion, l’ingestion de données dans les tables en ligne consomme des unités Databricks (DBU) SQL Serverless. La tarification finale des tables en ligne sera mise à disposition à une date ultérieure.
La préversion des tableaux en ligne est disponible dans les régions suivantes : westus, eastus, eastus2, northeurope, westeurope.
Une table en ligne est une copie en lecture seule d’une table Delta stockée dans un format orienté ligne optimisé pour l’accès en ligne. Les tables en ligne sont des tables entièrement serverless qui adaptent automatiquement leur capacité de débit à la charge de la requête et fournissent un accès à faible latence et à haut débit aux données, quelle que soit leur échelle. Les tables en ligne sont conçues pour fonctionner avec les applications de service de modèles Mosaic AI, de mise en service de fonctionnalité et de génération augmentée de récupération (RAG) dans lesquelles elles sont utilisées pour des recherches rapides de données.
Vous pouvez également utiliser des tables en ligne dans des requêtes à l’aide de Lakehouse Federation. Lorsque vous utilisez Lakehouse Federation, il vous faut utiliser un entrepôt SQL serverless pour accéder aux tables en ligne. Seules les opérations de lecture (SELECT) sont autorisées. Cette fonctionnalité est destinée à des fins interactives ou de débogage uniquement et ne doit pas être utilisée pour les charges de travail critiques pour la mission.
La création d’une table en ligne à l’aide de l’interface utilisateur Databricks se fait en une seule étape. Il vous suffit de sélectionner la table Delta dans l’Explorateur de catalogues et de choisir Créer une table en ligne. Vous pouvez également utiliser l’API REST ou le kit de développement logiciel (SDK) Databricks pour créer et gérer des tables en ligne. Consultez Utiliser des tables en ligne à l’aide d’API.
Spécifications
- L’espace de travail doit être activé pour le catalogue Unity. Suivez la documentation pour créer un Metastore Unity Catalog, l’activer dans un espace de travail et créer un catalogue.
- Un modèle doit être inscrit dans Unity Catalog pour pouvoir accéder aux tables en ligne.
Travailler avec des tables en ligne en utilisant l’interface utilisateur
Cette section explique comment créer et supprimer des tables en ligne, et comment vérifier l’état et déclencher des mises à jour des tables en ligne.
Créer une table en ligne à l’aide de l’interface utilisateur
Vous créez une table en ligne à l’aide de Catalog Explorer. Pour plus d’informations sur les autorisations requises, consultez Autorisations utilisateur.
Pour créer une table en ligne, la table Delta source doit avoir une clé primaire. Si la table Delta que vous souhaitez utiliser n’a pas de clé primaire, créez-en une en suivant les instructions suivantes : Utiliser une table Delta existante dans Unity Catalog en tant que table de fonctionnalités.
Dans l’Explorateur de catalogues, accédez à la table source que vous souhaitez synchroniser avec une table en ligne. Dans le menu Créer, sélectionnez Table en ligne.
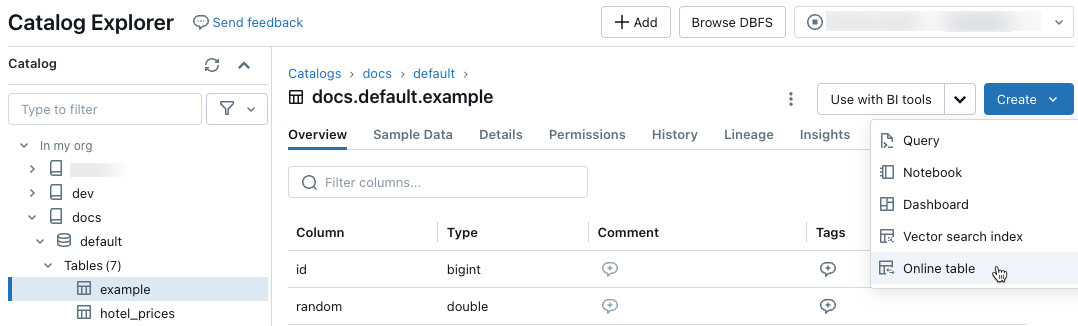
Utilisez les sélecteurs dans la boîte de dialogue pour configurer la table en ligne.
Nom : nom à utiliser pour la table en ligne dans Unity Catalog.
Clé primaire : colonne(s) de la table source à utiliser comme clé(s) primaire(s) dans la table en ligne.
Clé de série chronologique : (facultative). Colonne de la table source à utiliser comme clé de série chronologique. Quand elle est spécifiée, la table en ligne inclut uniquement la ligne avec la dernière valeur de clé de série chronologique pour chaque clé primaire.
Mode de synchronisation : spécifie comment le pipeline de synchronisation met à jour la table en ligne. Sélectionnez l’une des options : Capture instantanée, Déclenchée ou Continue.
Stratégie Description Snapshot Le pipeline s’exécute une fois pour prendre un instantané de la table source et le copier dans la table en ligne. Les modifications ultérieures apportées à la table source sont automatiquement reflétées dans la table en ligne en prenant un nouvel instantané de la source et en créant une copie. Le contenu de la table en ligne est mis à jour atomiquement. Déclenchée Le pipeline s’exécute une fois pour créer une copie de capture instantanée initiale de la table source dans la table en ligne. Contrairement au mode de synchronisation de captures instantanées, lorsque la table en ligne est actualisée, seules les modifications apportées depuis la dernière exécution du pipeline sont récupérées et appliquées à la table en ligne. L’actualisation incrémentielle peut être déclenchée manuellement ou automatiquement selon une planification. Continue Le pipeline s’exécute en continu. Les modifications ultérieures apportées à la table source sont appliquées de manière incrémentielle à la table en ligne en mode de diffusion en continu en temps réel. Aucune actualisation manuelle n’est nécessaire.
Remarque
Pour prendre en charge le mode de synchronisation déclenché ou continu, la table source doit avoir l’option Flux des changements de données activée.
- Lorsque vous avez terminé, cliquez sur Confirmer. La page de table en ligne s’affiche.
- La nouvelle table en ligne est créée sous le catalogue, le schéma et le nom spécifiés dans la boîte de dialogue de création. Dans l’Explorateur de catalogues, la table en ligne est indiquée par
 .
.
Obtenir des mises à jour de l’état et des déclencheurs à l’aide de l’interface utilisateur
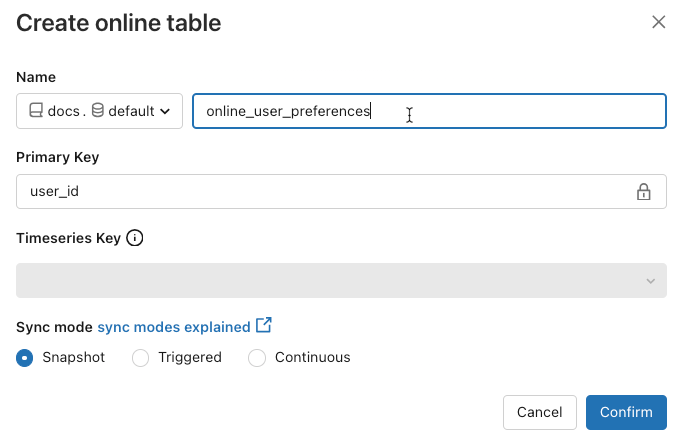
Pour vérifier l’état de la table en ligne, cliquez sur le nom de la table dans le catalogue pour l’ouvrir. La page de table en ligne s’affiche avec l’onglet Vue d’ensemble ouvert. La section Ingestion des données affiche l’état de la dernière mise à jour. Pour déclencher une mise à jour, cliquez sur Synchroniser maintenant. La section Ingestion des données inclut également un lien vers le pipeline Delta Live Tables qui met à jour la table.
Supprimer une table en ligne à l’aide de l’interface utilisateur
Dans la page de tableau en ligne, sélectionnez Supprimer dans le menu kebab ![]() .
.
Utiliser des tables en ligne à l’aide d’API
Vous pouvez également utiliser le Kit de développement logiciel (SDK) Databricks ou l’API REST pour créer et gérer des tables en ligne.
Pour obtenir des informations de référence, consultez la documentation de référence pour le KIT de développement logiciel (SDK) Databricks pour Python ou l’API REST.
Spécifications
SDK Databricks version 0.20 ou ultérieure.
Créer une table en ligne à l’aide d’API
Kit de développement logiciel (SDK) Databricks – Python
from pprint import pprint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import *
w = WorkspaceClient(host='https://xxx.databricks.com', token='xxx')
# Create an online table
spec = OnlineTableSpec(
primary_key_columns=["pk_col"],
source_table_full_name="main.default.source_table",
run_triggered=OnlineTableSpecTriggeredSchedulingPolicy.from_dict({'triggered': 'true'})
)
w.online_tables.create(name='main.default.my_online_table', spec=spec)
API REST
curl --request POST "https://xxx.databricks.com/api/2.0/online-tables" \
--header "Authorization: Bearer xxx" \
--data '{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["a"]
}
}'
La table en ligne démarre automatiquement la synchronisation après sa création.
Obtenir l’état et déclencher l’actualisation à l’aide d’API
Vous pouvez afficher l’état et la spécification de la table en ligne en suivant l’exemple ci-dessous. Si votre table en ligne n’est pas continue et que vous souhaitez déclencher une actualisation manuelle de ses données, vous pouvez pour cela utiliser l’API de pipeline.
Utilisez l’ID de pipeline associé à la table en ligne dans la spécification de la table en ligne, et démarrez une nouvelle mise à jour sur le pipeline pour déclencher l’actualisation. Ceci équivaut à un clic sur Synchroniser maintenant dans l’interface utilisateur de la table en ligne dans l’Explorateur de catalogues.
Kit de développement logiciel (SDK) Databricks – Python
pprint(w.online_tables.get('main.default.my_online_table'))
# Sample response
OnlineTable(name='main.default.my_online_table',
spec=OnlineTableSpec(perform_full_copy=None,
pipeline_id='some-pipeline-id',
primary_key_columns=['pk_col'],
run_continuously=None,
run_triggered={},
source_table_full_name='main.default.source_table',
timeseries_key=None),
status=OnlineTableStatus(continuous_update_status=None,
detailed_state=OnlineTableState.PROVISIONING,
failed_status=None,
message='Online Table creation is '
'pending. Check latest status in '
'Delta Live Tables: '
'https://xxx.databricks.com/pipelines/some-pipeline-id',
provisioning_status=None,
triggered_update_status=None))
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
w.pipelines.start_update(pipeline_id='some-pipeline-id', full_refresh=True)
API REST
curl --request GET \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
# Sample response
{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["pk_col"],
"pipeline_id": "some-pipeline-id"
},
"status": {
"detailed_state": "PROVISIONING",
"message": "Online Table creation is pending. Check latest status in Delta Live Tables: https://xxx.databricks.com#joblist/pipelines/some-pipeline-id"
}
}
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
curl --request POST "https://xxx.databricks.com/api/2.0/pipelines/some-pipeline-id/updates" \
--header "Authorization: Bearer xxx" \
--data '{
"full_refresh": true
}'
Supprimer une table en ligne à l’aide d’API
Kit de développement logiciel (SDK) Databricks – Python
w.online_tables.delete('main.default.my_online_table')
API REST
curl --request DELETE \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
La suppression de la table en ligne arrête toute synchronisation continue des données et libère toutes ses ressources.
Mettre en service des données de table en ligne à l’aide d’un point de terminaison de mise en service de fonctionnalités
Pour les modèles et les applications hébergés en dehors de Databricks, vous pouvez créer un point de terminaison de mise en service de fonctionnalités à partir de tables en ligne. Le point de terminaison rend les fonctionnalités disponibles à faible latence à l’aide d’une API REST.
Créer une spécification de fonctionnalité.
Lorsque vous créez une spécification de fonctionnalité, vous spécifiez la table Delta source. Cela permet à la spécification de fonctionnalité d’être utilisée dans les scénarios hors connexion et en ligne. Pour les recherches en ligne, le point de terminaison de mise en service utilise automatiquement la table en ligne pour effectuer des recherches de fonctionnalités à faible latence.
La table Delta source et la table en ligne doivent utiliser la même clé primaire.
La spécification de fonctionnalité peut être consultée dans l’onglet Fonction dans l’Explorateur de catalogues.
from databricks.feature_engineering import FeatureEngineeringClient, FeatureLookup fe = FeatureEngineeringClient() fe.create_feature_spec( name="catalog.default.user_preferences_spec", features=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ] )Créer un point de terminaison de mise en service de fonctionnalités.
Cette étape suppose que vous avez créé une table en ligne nommée
user_preferences_online_tablequi synchronise les données de la table Deltauser_preferences. Utilisez la spécification de fonctionnalité pour créer un point de terminaison de mise en service de fonctionnalités. Le point de terminaison rend les données disponibles via une API REST à l’aide de la table en ligne associée.Remarque
L’utilisateur qui effectue cette opération doit être le propriétaire de la table hors connexion et de la table en ligne.
Kit de développement logiciel (SDK) Databricks – Python
from databricks.sdk import WorkspaceClient from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput workspace = WorkspaceClient() # Create endpoint endpoint_name = "fse-location" workspace.serving_endpoints.create_and_wait( name=endpoint_name, config=EndpointCoreConfigInput( served_entities=[ ServedEntityInput( entity_name=feature_spec_name, scale_to_zero_enabled=True, workload_size="Small" ) ] ) )API Python
fe.create_feature_serving_endpoint( name="user-preferences", config=EndpointCoreConfig( served_entities=ServedEntity( feature_spec_name="catalog.default.user_preferences_spec", workload_size="Small", scale_to_zero_enabled=True ) ) )Obtenir des données à partir du point de terminaison de mise en service de fonctionnalités.
Pour accéder au point de terminaison d’API, envoyez une requête HTTP GET à l’URL du point de terminaison. L’exemple montre comment effectuer cette opération avec des API Python. Pour d’autres langages et outils, consultez Service de fonctionnalités.
# Set up credentials export DATABRICKS_TOKEN=...url = "https://{workspace_url}/serving-endpoints/user-preferences/invocations" headers = {'Authorization': f'Bearer {DATABRICKS_TOKEN}', 'Content-Type': 'application/json'} data = { "dataframe_records": [{"user_id": user_id}] } data_json = json.dumps(data, allow_nan=True) response = requests.request(method='POST', headers=headers, url=url, data=data_json) if response.status_code != 200: raise Exception(f'Request failed with status {response.status_code}, {response.text}') print(response.json()['outputs'][0]['hotel_preference'])
Utiliser des tables en ligne avec des applications RAG
Les applications RAG sont un cas d’usage courant pour les tables en ligne. Vous créez une table en ligne pour les données structurées dont l’application RAG a besoin et l’hébergez sur un point de terminaison de mise en service de fonctionnalités. L’application RAG utilise le point de terminaison de mise en service de fonctionnalités pour rechercher les données pertinentes de la table en ligne.
Les étapes typiques sont les suivantes :
- Créer un point de terminaison de mise en service de fonctionnalités.
- Créer un LangChainTool qui utilise le point de terminaison pour rechercher des données pertinentes.
- Utiliser l’outil dans l’agent LangChain pour récupérer les données pertinentes.
- Créer un point de terminaison de mise en service de modèles pour héberger l’application LangChain.
Pour des instructions pas à pas, consultez l’exemple de notebook suivant :
Exemples de Notebook
Le notebook suivant illustre comment publier des fonctionnalités dans des tables en ligne pour une utilisation en temps réel et une recherche automatisée des fonctionnalités.
Notebook de démonstration des tables en ligne
Le notebook suivant montre comment utiliser des tables en ligne Databricks et des points de terminaison de service de fonctionnalités pour la Génération Augmentée de Récupération (RAG).
Tables en ligne avec notebook de démonstration d’applications RAG
Utiliser des tables en ligne avec le service de modèles Mosaic AI
Vous pouvez utiliser des tables en ligne pour rechercher des fonctionnalités pour le service de modèles Mosaic AI. Lorsque vous synchronisez une table de fonctionnalités vers une table en ligne, les modèles formés à l’aide de fonctionnalités de cette table de fonctionnalités recherchent automatiquement les valeurs de fonctionnalités de la table en ligne pendant l’inférence. Aucune configuration supplémentaire n’est nécessaire.
Utiliser un
FeatureLookuppour effectuer l'apprentissage du modèle.Pour l’apprentissage du modèle, utilisez des fonctionnalités de la table de fonctionnalités hors connexion dans le jeu d’apprentissage de modèle, comme illustré dans l’exemple suivant :
training_set = fe.create_training_set( df=id_rt_feature_labels, label='quality', feature_lookups=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ], exclude_columns=['user_id'], )Servez le modèle avec le service de modèles Mosaic AI. Le modèle recherche automatiquement les fonctionnalités de la table en ligne. Consultez Recherche automatique de fonctionnalités avec des modèles MLflow sur Databricks pour plus de détails.
Autorisations utilisateur
Vous devez disposer des autorisations suivantes pour créer une table en ligne :
- Privilège
SELECTsur la table source. - Privilège
USE_CATALOGsur le catalogue de destination. - Privilèges
USE_SCHEMAetCREATE_TABLEsur le schéma de destination.
Pour gérer le pipeline de synchronisation des données d’une table en ligne, vous devez être le propriétaire de la table en ligne ou obtenir le privilège REFRESH sur la table en ligne. Les utilisateurs qui n’ont pas les privilèges USE_CATALOG et USE_SCHEMA sur le catalogue ne voient pas la table en ligne dans l’Explorateur de catalogues.
En outre, le metastore Unity Catalog doit disposer de Privilege Model version 1.0.
Modèle d’autorisation de point de terminaison
Un principal de service système unique est créé automatiquement pour un point de terminaison de mise en service de fonctionnalités ou de modèles avec des autorisations limitées requises pour interroger des données et exécuter des fonctions. Ce principal de service permet aux points de terminaison d’accéder aux données et aux ressources de fonction indépendamment de l’utilisateur qui a créé la ressource et garantit que le point de terminaison peut continuer à fonctionner si le créateur quitte l’espace de travail.
La durée de vie de ce principal de service système est la durée de vie du point de terminaison. Les journaux d’audit peuvent indiquer les enregistrements générés par le système pour le propriétaire du catalogue Unity Catalog en accordant les privilèges nécessaires à ce principal de service système.
Limites
- Une seule table en ligne est prise en charge par table source.
- Une table en ligne et sa table source peuvent avoir au maximum 1000 colonnes.
- Les colonnes de types de données ARRAY, MAP ou STRUCT ne peuvent pas être utilisées comme clés primaires dans la table en ligne.
- Si une colonne est utilisée comme clé primaire dans la table en ligne, toutes les lignes de la table source où la colonne contient des valeurs Null sont ignorées.
- Les tables étrangères, système et internes ne sont pas prises en charge en tant que tables sources.
- Les tables sources sans flux de données de modification Delta activé prennent uniquement en charge le mode de synchronisation Capture instantanée.
- Les tables de partage Delta sont uniquement prises en charge en mode de synchronisation Capture instantanée.
- Les noms de catalogue, de schéma et de table en ligne ne peuvent contenir que des caractères alphanumériques et des traits de soulignement, et ne doivent pas commencer par des nombres. Les tirets (
-) ne sont pas autorisés. - Les colonnes de type String sont limitées à 64 Ko de longueur.
- Les noms de colonnes sont limités à 64 caractères.
- La taille maximale de la ligne est de 2 Mo.
- La taille maximale d’une table en ligne pendant la préversion publique contrôlée est de 200 Go de données utilisateur non compressées.
- La taille combinée de toutes les tables en ligne d’un metastore Unity Catalog pendant la préversion publique contrôlée est de 1 To de données utilisateur non compressées.
- Le nombre maximal de requêtes par seconde (QPS) est de 200. Cette limite peut être augmentée à 25 000 ou plus. Contactez votre équipe des comptes Databricks pour relever la limite.
Dépannage
Je ne vois pas l’option Créer une table en ligne
La cause est généralement que le type de la table à partir de laquelle vous essayez de synchroniser (la table source) n’est pas pris en charge. Vérifiez que le type sécurisable de la table source (indiqué dans l’Explorateur de catalogues de l’onglet Détails) est l’une des options prises en charge ci-dessous :
TABLE_EXTERNALTABLE_DELTATABLE_DELTA_EXTERNALTABLE_DELTASHARINGTABLE_DELTASHARING_MUTABLETABLE_STREAMING_LIVE_TABLETABLE_STANDARDTABLE_FEATURE_STORETABLE_FEATURE_STORE_EXTERNALTABLE_VIEWTABLE_VIEW_DELTASHARINGTABLE_MATERIALIZED_VIEW
Je ne peux pas sélectionner les modes de synchronisation Déclenché ou Continu lors de la création d’une table en ligne
Cela se produit si la table source n’a pas activé le flux de données de modification Delta ou s’il s’agit d’une vue ou d’une vue matérialisée. Pour utiliser le mode de synchronisation Incrémentielle, activez le flux de données modifiées sur la table source ou utilisez une table sans vue.
La mise à jour de table en ligne échoue, ou son état indique Hors connexion
Pour commencer à résoudre cette erreur, cliquez sur l’ID de pipeline qui s’affiche sous l’onglet Vue d’ensemble de la table en ligne dans l’Explorateur de catalogues.
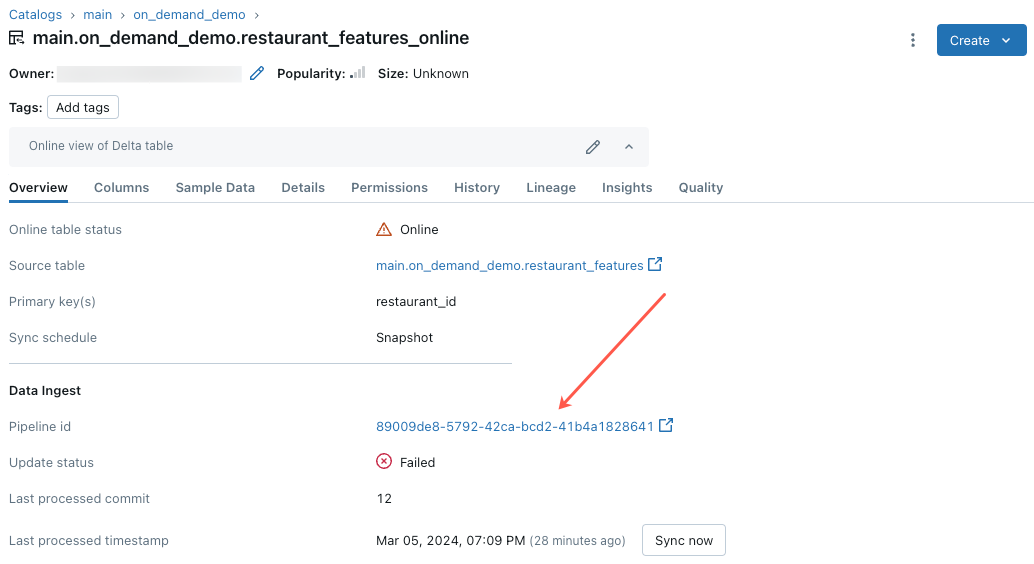
Dans la page d’interface utilisateur du pipeline qui s’affiche, cliquez sur l’entrée indiquant « Failed to resolve flow __online_table ».
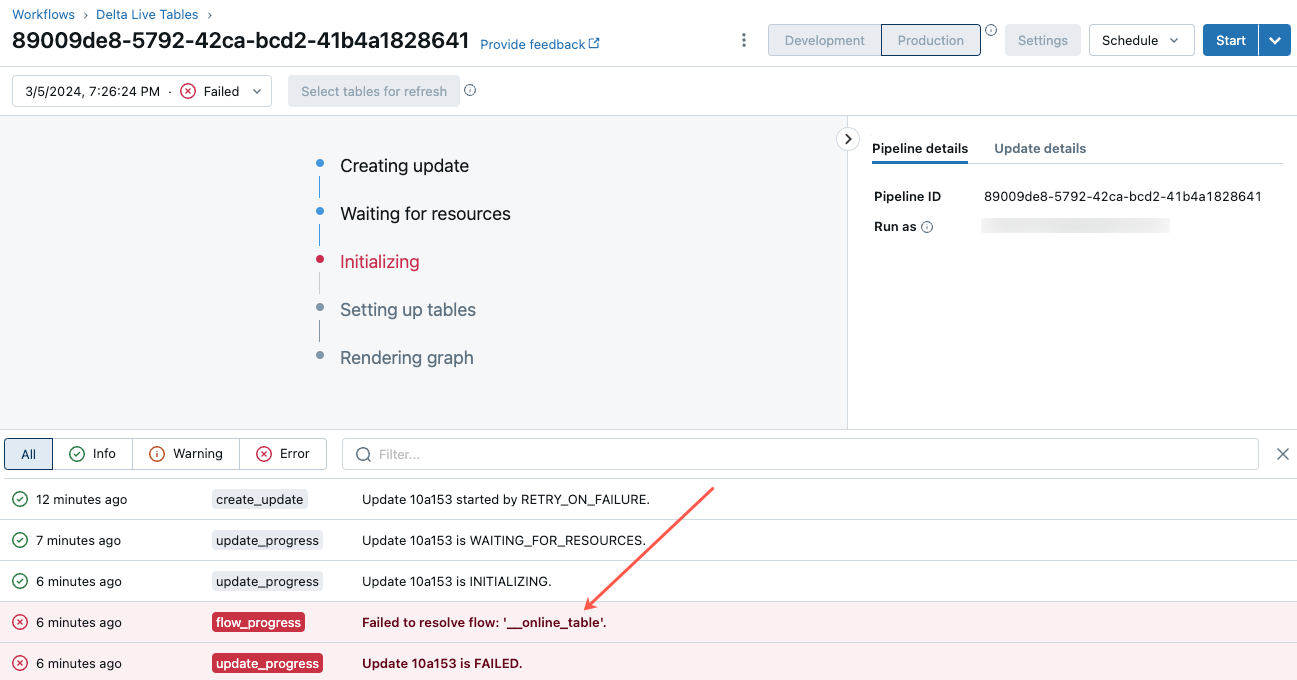
Une fenêtre contextuelle s’affiche avec des détails dans la section Error details.
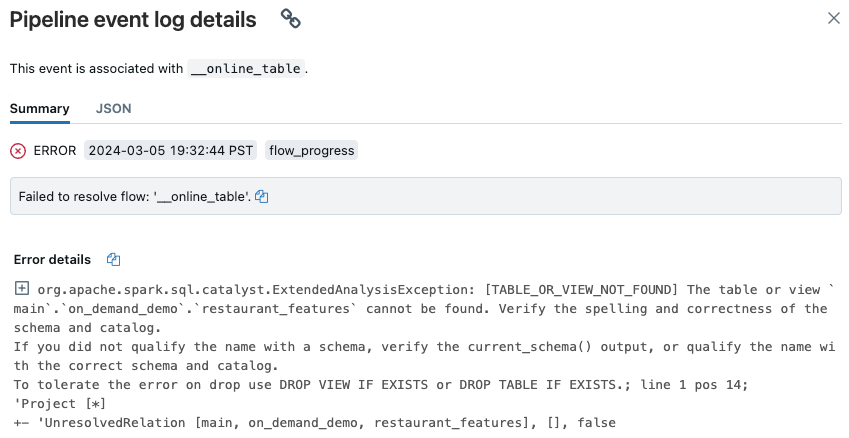
Les causes courantes des erreurs sont les suivantes :
La table source a été supprimée, ou supprimée puis recréée avec le même nom, pendant que la table en ligne était en cours de synchronisation. Ceci est particulièrement courant avec les tables en ligne continues, car elles sont constamment en cours de synchronisation.
La table source est inaccessible par le biais du calcul serverless à cause des paramètres de pare-feu. Dans ce cas, la section Error details peut afficher le message d’erreur « Failed to start the DLT service on cluster xxx… ».
La taille agrégée des tables en ligne dépasse la limite de 1 Tio (taille non compressée) à l’échelle du metastore. La limite de 1 Tio fait référence à la taille non compressée après le développement de la table Delta au format orienté ligne. La taille de la table au format ligne peut être nettement supérieure à la taille de la table Delta affichée dans l’Explorateur de catalogues, qui fait référence à la taille compressée de la table dans un format orienté colonne. Elle peut être jusqu’à 100 fois plus grande, en fonction du contenu de la table.
Pour estimer la taille non compressée et développée au format orienté ligne d’une table Delta, utilisez la requête suivante à partir d’un entrepôt SQL serverless. La requête retourne la taille estimée de la table développée en octets. L’exécution réussie de cette requête confirme également que le calcul serverless peut accéder à la table source.
SELECT sum(length(to_csv(struct(*)))) FROM `source_table`;
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour