Effectuer l’évaluation de votre propre point de terminaison LLM
Cet article fournit un exemple de notebook recommandé par Databricks pour l’évaluation d’un point de terminaison LLM. Il contient également une présentation de la manière dont Databricks effectue l’inférence LLM et calcule la latence et le débit en tant que métriques de performances de point de terminaison.
L’inférence LLM sur Databricks mesure les jetons par seconde pour le mode de débit approvisionné pour les API Foundation Model. Consultez Que signifient les plages de jetons par seconde dans le débit approvisionné ?
Notebook d’exemple d’évaluation
Vous pouvez importer le notebook suivant dans votre environnement Databricks et spécifier le nom de votre point de terminaison LLM pour exécuter un test de charge.
Évaluation d’un point de terminaison LLM
Présentation de l’inférence LLM
Les LLM effectuent une inférence dans un processus en deux étapes :
- Préremplissage, où les jetons de l’invite d’entrée sont traités en parallèle.
- Décodage, où le texte est généré un jeton à la fois de manière régressive automatique. Chaque jeton généré est ajouté à l’entrée et renvoyé dans le modèle pour générer le jeton suivant. La génération s’arrête lorsque le LLM génère un jeton d’arrêt spécial ou lorsqu’une condition définie par l’utilisateur est remplie.
La plupart des applications de production ont un budget de latence et Databricks vous recommande de maximiser le débit en fonction du budget de latence.
- Le nombre de jetons d’entrée a un impact considérable sur la mémoire requise pour traiter les requêtes.
- Le nombre de jetons de sortie domine la latence globale de la réponse.
Databricks divise l’inférence LLM en sous-métriques suivantes :
- Délai du premier jeton (TTFT) : il s’agit de la rapidité avec laquelle les utilisateurs commencent à voir la sortie du modèle après avoir entré leur requête. Les délais faibles pour une réponse sont essentiels dans les interactions en temps réel, mais moins importants dans les charges de travail hors connexion. Cette métrique dépend du temps nécessaire pour traiter l’invite, puis générer le premier jeton de sortie.
- Durée par jeton de sortie (TPOT) : le temps nécessaire pour générer un jeton de sortie pour chaque utilisateur qui interroge le système. Cette métrique correspond à la façon dont chaque utilisateur perçoit la « vitesse » du modèle. Par exemple, un TPOT de 100 millisecondes par jeton correspondrait à 10 jetons par seconde, ou environ 450 mots par minute, ce qui est plus rapide que ce qu’une personne typique peut lire.
En fonction de ces métriques, la latence totale et le débit peuvent être définis comme suit :
- Latence = TTFT + (TPOT) * (nombre de jetons à générer)
- Ddébit = nombre de jetons de sortie par seconde sur toutes les requêtes simultanées
Sur Databricks, les points de terminaison de mise en service LLM peuvent être mis à l’échelle pour correspondre à la charge envoyée par les clients avec plusieurs requêtes simultanées. Il existe un compromis entre la latence et le débit. Cela est dû au fait que sur les points de terminaison de mise en service LLM, les requêtes simultanées peuvent être, et sont traitées en même temps. À faible charge de requêtes simultanées, la latence est la plus faible possible. Toutefois, si vous augmentez la charge de requêtes, la latence peut augmenter, mais le débit augmente probablement également. Cela est dû au fait que les jetons par seconde correspondant à deux requêtes peuvent être traitées en moins de deux fois le temps.
Par conséquent, le contrôle du nombre de requêtes parallèles dans votre système est essentiel pour équilibrer la latence et le débit. Si vous avez un cas d’usage à faible latence, vous souhaitez envoyer moins de demandes simultanées au point de terminaison pour conserver une faible latence. Si vous avez un cas d’usage à débit élevé, vous souhaitez saturer le point de terminaison avec un grand nombre de requêtes simultanées, car un débit plus élevé vaut la peine même au détriment de la latence.
Harnais d’évaluation Databricks
Le notebook d’exemple d’évaluation précédemment partagé est le harnais d’évaluation Databricks. Le notebook affiche les métriques de latence et de débit, et trace la courbe de débit par rapport à la latence sur différents nombres de requêtes parallèles. La mise à l’échelle automatique des points de terminaison Databricks est basée sur une stratégie « équilibrée » entre la latence et le débit. Dans le notebook, vous constatez que, comme davantage d’utilisateurs simultanés interrogent le point de terminaison en même temps, la latence augmente en même temps que le débit.
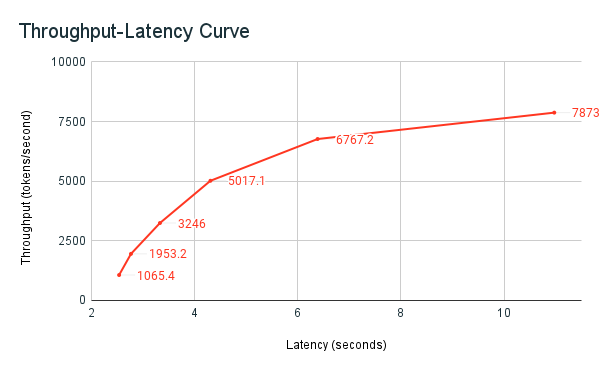
La philosophie Databricks sur l’évaluation des performances LLM est décrite plus en détail dans le blog LLM Inference Performance Engineering: Best Practices.