Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
TensorBoard est une suite d’outils de visualisation permettant de déboguer, d’optimiser et de comprendre TensorFlow, PyTorch, Hugging Face Transformers et d’autres programmes de Machine Learning.
Utiliser TensorBoard
Le démarrage de TensorBoard dans Azure Databricks n’est pas différent de son démarrage sur un notebook Jupyter sur votre ordinateur local.
Chargez la commande
%tensorboardmagique et définissez votre répertoire de journaux.%load_ext tensorboard experiment_log_dir = <log-directory>Appelez la commande magique
%tensorboard.%tensorboard --logdir $experiment_log_dirLe serveur TensorBoard démarre et affiche l’interface utilisateur intégrée dans le notebook. Il fournit également un lien permettant d’ouvrir TensorBoard dans un nouvel onglet.
La capture d’écran suivante montre l’interface utilisateur de TensorBoard démarrée dans un dossier de logs déjà peuplé.
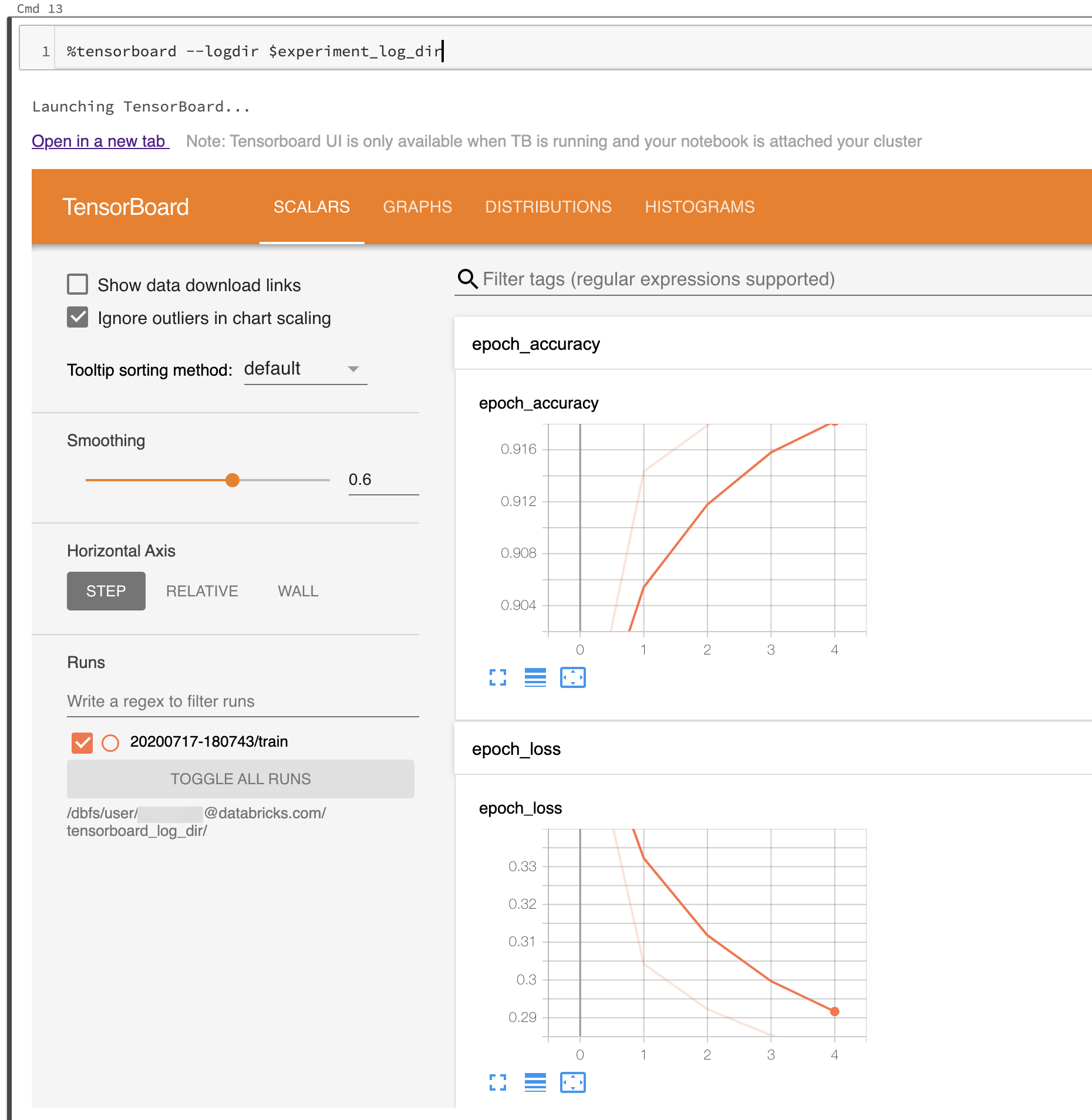
Vous pouvez également démarrer TensorBoard à l’aide du module notebook de TensorBoard directement.
from tensorboard import notebook
notebook.start("--logdir {}".format(experiment_log_dir))
Fichiers journaux et répertoires TensorBoard
TensorBoard visualise vos programmes d'apprentissage automatique en lisant les journaux générés par les callbacks et les fonctions dans TensorBoard ou PyTorch. Pour générer des journaux pour d’autres bibliothèques de Machine Learning, vous pouvez écrire directement des journaux à l’aide d’enregistreurs de fichiers TensorFlow (voir Module : tf.summary pour TensorFlow 2.x et Module : tf.compat.v1.summary pour l’API antérieure dans TensorFlow 1.x).
Pour veiller à ce que vos journaux d’expérience soient stockés de manière fiable, Databricks recommande d’écrire des journaux sur un stockage cloud plutôt que sur le système de fichiers éphémère du cluster. Pour chaque expérience, démarrez TensorBoard dans un répertoire unique. Pour chaque exécution de votre code de Machine Learning dans l’expérience qui génère des journaux, définissez le rappel ou l’enregistreur de fichier de TensorBoard pour écrire dans un sous-répertoire du répertoire d’expérience. De cette façon, les données de l’interface utilisateur de TensorBoard sont séparées en plusieurs exécutions.
Lisez la documentation officielle de TensorBoard pour commencer à utiliser TensorBoard pour consigner les informations de votre programme de Machine Learning.
Gérer les processus TensorBoard
Les processus TensorBoard démarrés dans un notebook Azure Databricks ne sont pas terminés lorsque le notebook est détaché ou que la boucle REPL est redémarrée (par exemple, lorsque vous effacez l’état du notebook). Pour tuer manuellement un processus TensorBoard, envoyez-lui un signal de fin en utilisant %sh kill -15 pid. Des processus TensorBoard arrêtés de manière incorrecte pourraient endommager notebook.list().
Pour répertorier les serveurs TensorBoard en cours d’exécution sur votre cluster, avec leurs répertoires de journaux et leurs identifiants de processus correspondants, exécutez notebook.list() à partir du module notebook de TensorBoard.
Problèmes connus
- L’interface utilisateur TensorBoard inlined se trouve dans un iframe. Les fonctionnalités de sécurité des navigateurs empêchent les liens externes de l’interface utilisateur de fonctionner, sauf si vous ouvrez le lien dans un nouvel onglet.
- L’option
--window_titlede TensorBoard est remplacée sur Azure Databricks. - Par défaut, TensorBoard analyse une plage de ports pour sélectionner un port à écouter. Si de trop nombreux processus TensorBoard sont exécutés sur le cluster, tous les ports de la plage de ports peuvent être indisponibles. Vous pouvez contourner cette limitation en spécifiant un numéro de port avec l’argument
--port. Le port spécifié doit être compris entre 6006 et 6106. - Pour que les liens de téléchargement fonctionnent, vous devez ouvrir TensorBoard dans un onglet.
- Lorsque vous utilisez TensorBoard 1.15.0, l’onglet Projector (Projecteur) est vide. Comme solution de contournement, pour accéder directement à la page du projecteur, vous pouvez remplacer
#projectordans l’URL pardata/plugin/projector/projector_binary.html. - TensorBoard 2.4.0 présente un problème connu qui peut influer sur le rendu de TensorBoard en cas de mise à niveau.
- Si vous journalisez des données liées à TensorBoard dans des volumes DBFS ou UC, vous risquez d’obtenir une erreur telle que
No dashboards are active for the current data set. Pour surmonter cette erreur, il est conseillé d'appelerwriter.flush()etwriter.close()après avoir utiliséwriterpour journaliser les données. Cela permet de s’assurer que toutes les données enregistrées sont correctement écrites et disponibles pour le rendu de TensorBoard.