Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article décrit comment MLflow sur Databricks est utilisé pour développer des agents d’INTELLIGENCE artificielle de haute qualité et des modèles Machine Learning.
Remarque
Si vous commencez simplement avec Azure Databricks, envisagez d’essayer MLflow sur Databricks Free Edition.
Qu’est-ce que MLflow ?
MLflow est la plus grande plateforme d’ingénierie d’IA open source pour les agents, les llms et les modèles ML. MLflow permet aux équipes de toutes tailles de déboguer, évaluer, surveiller et optimiser les applications IA de qualité de production tout en contrôlant les coûts et en gérant l’accès aux modèles et aux données. Avec plus de 30 millions de téléchargements mensuels, des milliers d’organisations s’appuient sur MLflow chaque jour pour expédier l’IA en production avec confiance.
L’ensemble complet de fonctionnalités de MLflow pour les agents et les applications LLM inclut l’observabilité, l’évaluation, la gestion rapide, une passerelle IA pour gérer les coûts et l’accès aux modèles, etc.
Pour le développement de modèles Machine Learning (ML), MLflow fournit un suivi des expériences, des fonctionnalités d’évaluation de modèle, un registre de modèles de production et des outils de déploiement de modèles.
MLflow prend en charge n’importe quel fournisseur LLM, framework agent, bibliothèque ML et langage de programmation. MLflow fournit des kits SDK natifs pour Python, TypeScript/JavaScript, Java et R.
MLflow 3
MLflow 3 sur Azure Databricks offre une observabilité, une évaluation et une gestion rapide des agents et des applications LLM. Pour le développement de modèles ML, MLflow 3 fournit le suivi des expériences, l’évaluation des modèles, un registre de modèles de production et des outils de déploiement de modèles. À l’aide de MLflow 3 sur Azure Databricks, vous pouvez :
Effectuez le suivi et analysez de manière centralisée les performances de vos modèles, applications IA et agents dans tous les environnements, à partir de requêtes interactives dans un notebook de développement via des déploiements de traitement par lots de production ou en temps réel.
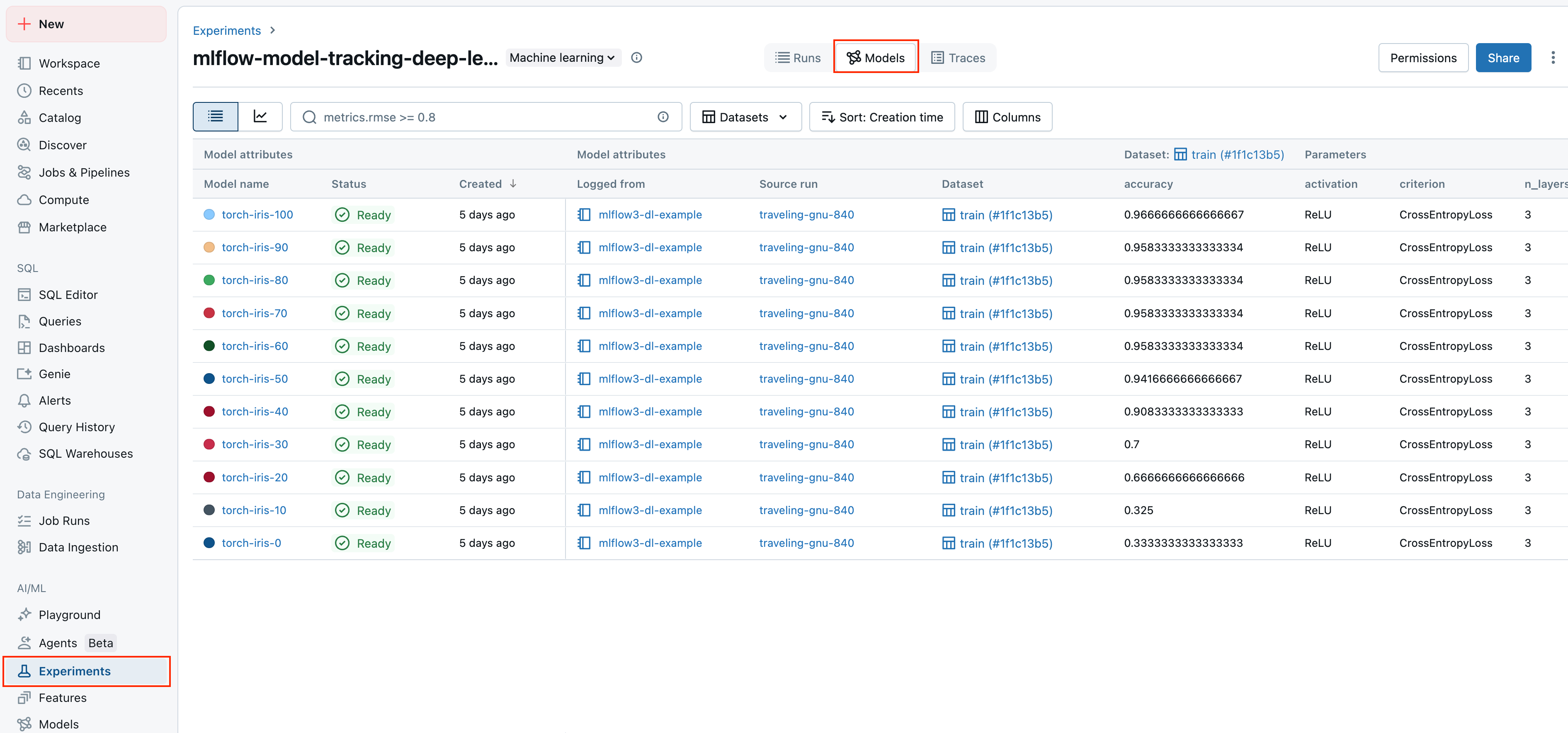
Orchestrez les flux de travail d’évaluation et de déploiement à l’aide du catalogue Unity et accédez aux journaux d’état complets pour chaque version de votre modèle, application IA ou agent.
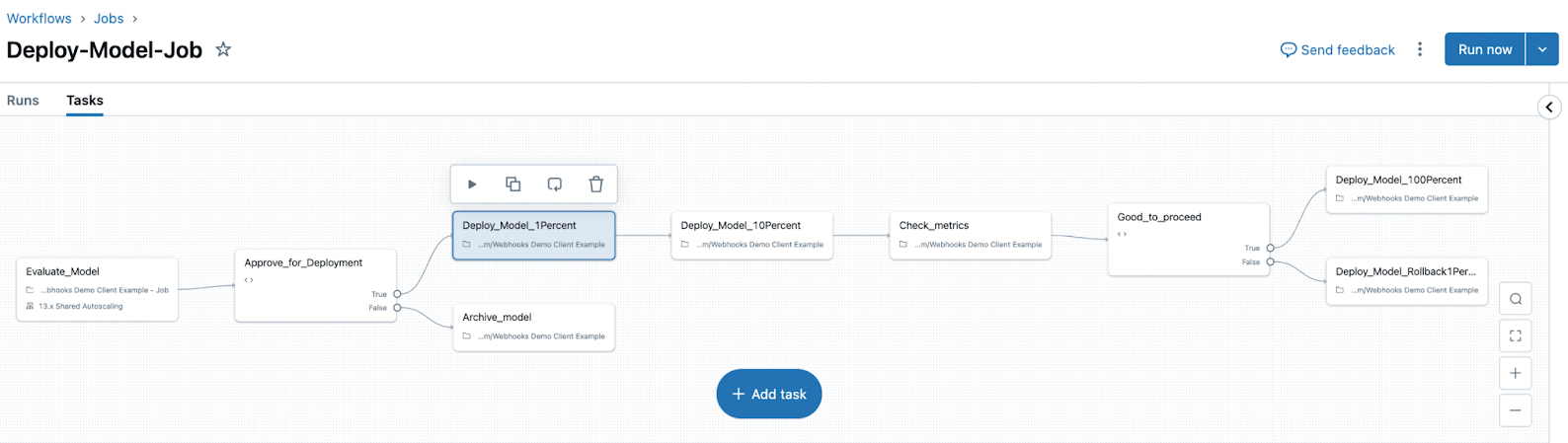
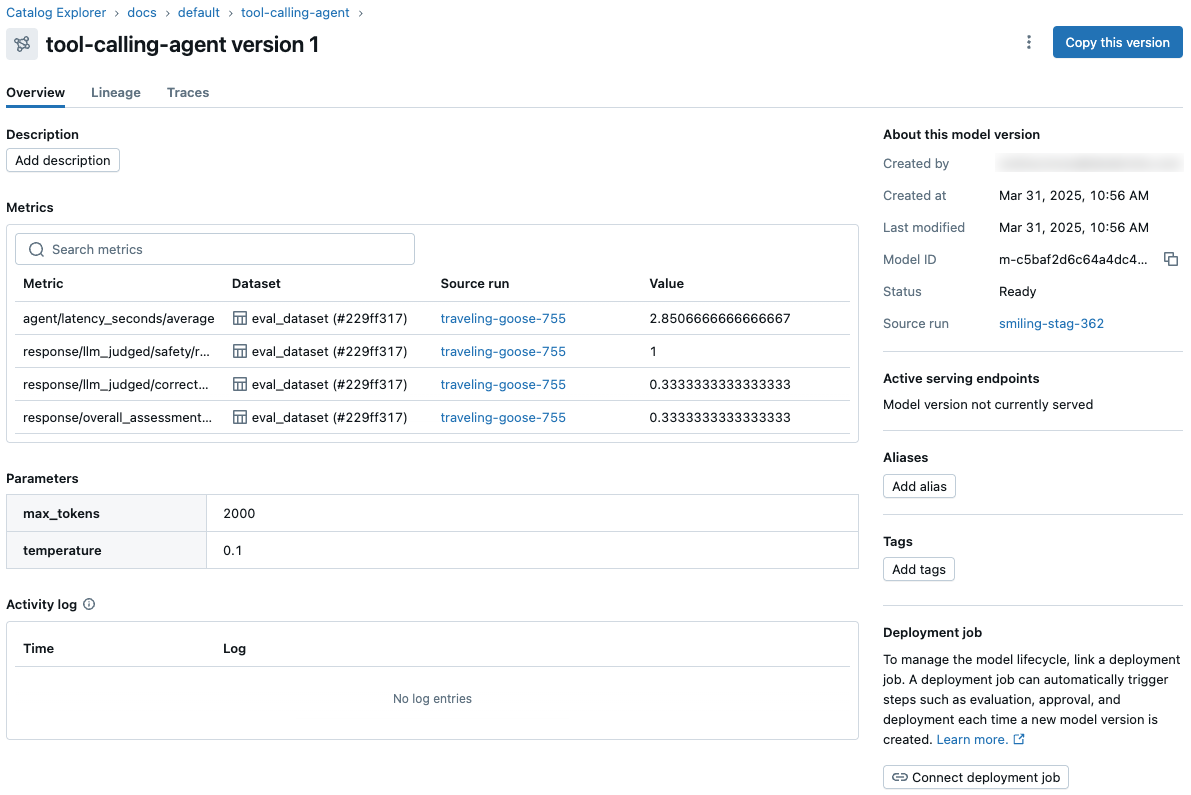
Affichez et accédez aux métriques et paramètres du modèle à partir de la page de version du modèle dans le catalogue Unity et à partir de l’API REST.
Annotez les demandes et réponses (traces) pour toutes vos applications et agents IA de génération, ce qui permet aux experts humains et aux techniques automatisées (telles que LLM-as-a-juge) de fournir des commentaires enrichis. Vous pouvez tirer parti de ces commentaires pour évaluer et comparer les performances des versions d’application et créer des jeux de données pour améliorer la qualité.
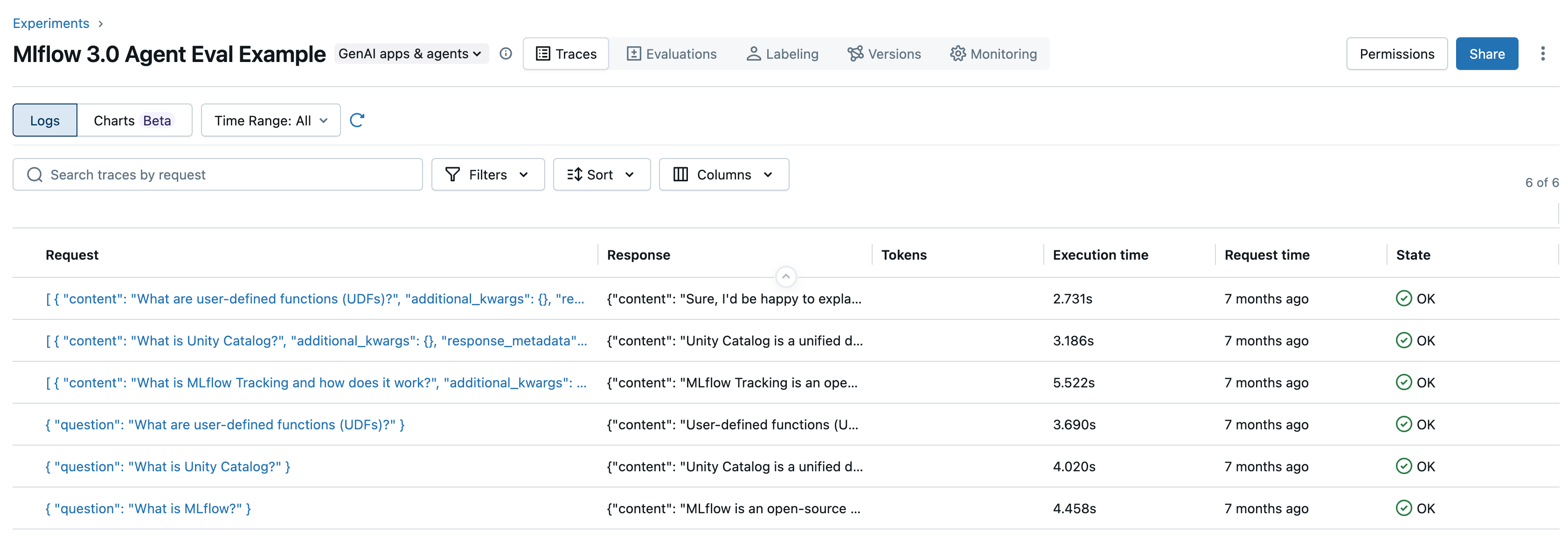
Ces fonctionnalités simplifient et rationalisent l’évaluation, le déploiement, le débogage et la surveillance de toutes vos initiatives IA.
MLflow 3 présente également les concepts des modèles journalisés et des travaux de déploiement.
-
Les modèles journalisés vous aident à suivre la progression d’un modèle tout au long de son cycle de vie. Lorsque vous consignez un modèle à l’aide de
log_model(), unLoggedModelest créé qui persiste tout au long du cycle de vie du modèle, à travers différents environnements et exécutions, et contient des liens vers des artéfacts tels que les métadonnées, les métriques, les paramètres et le code utilisé pour générer le modèle. Vous pouvez utiliser le modèle journalisé pour comparer les modèles entre eux, rechercher le modèle le plus performant et suivre les informations pendant le débogage. - Les travaux de déploiement peuvent être utilisés pour gérer le cycle de vie du modèle, notamment les étapes telles que l’évaluation, l’approbation et le déploiement. Ces flux de travail de modèle sont régis par le catalogue Unity, et tous les événements sont enregistrés dans un journal d’activité disponible dans la page de version du modèle dans le catalogue Unity.
Consultez les articles suivants pour installer et commencer à utiliser MLflow 3.
- Prise en main de MLflow 3 pour les modèles.
- Suivez et comparez les modèles à l’aide de modèles journalisés MLflow.
- Améliorations apportées au Registre de modèles avec MLflow 3.
- Tâches de déploiement MLflow 3.
MLflow managé par Databricks
Databricks fournit une version entièrement gérée et hébergée de MLflow, qui s’appuie sur l’expérience open source pour la rendre plus robuste et évolutive pour une utilisation d’entreprise.
Agents et applications LLM
MLflow sur Databricks fournit une plateforme complète pour le développement, l’évaluation et la surveillance d’agents et d’applications LLM.
- Observability :MLflow Tracing enregistre les entrées, les sorties et les métadonnées associées à chaque étape intermédiaire d’une requête, ce qui vous permet de trouver rapidement la source du comportement inattendu dans les agents.
- Évaluation: Utilisez l’évaluation de l’agent d’IA Mosaïque pour mesurer et améliorer la qualité de l’agent, alimentée par l’évaluation MLflow.
- Gestion des invites : Versionner, gérer et itérer sur les modèles d’invite utilisés dans vos applications IA.
- Développement de l’agent : Utilisez Mosaïque AI Agent Framework pour créer des agents, qui s’appuient sur MLflow pour suivre le code de l’agent, les métriques de performances et les traces.
- Débogage interactif : Utilisez Le code Genie pour l’observabilité et l’évaluation de l’agent pour l’accès en langage naturel aux traces, aux exécutions d’évaluation, aux scoreurs et bien plus encore dans votre expérience MLflow.
Développement de modèles ML
MLflow sur Databricks fournit le suivi des expériences, l’évaluation des modèles, un registre de modèles de production et des outils de déploiement de modèles pour le développement de modèles ML.
Le diagramme suivant montre comment Databricks s’intègre à MLflow pour entraîner et déployer des modèles Machine Learning.
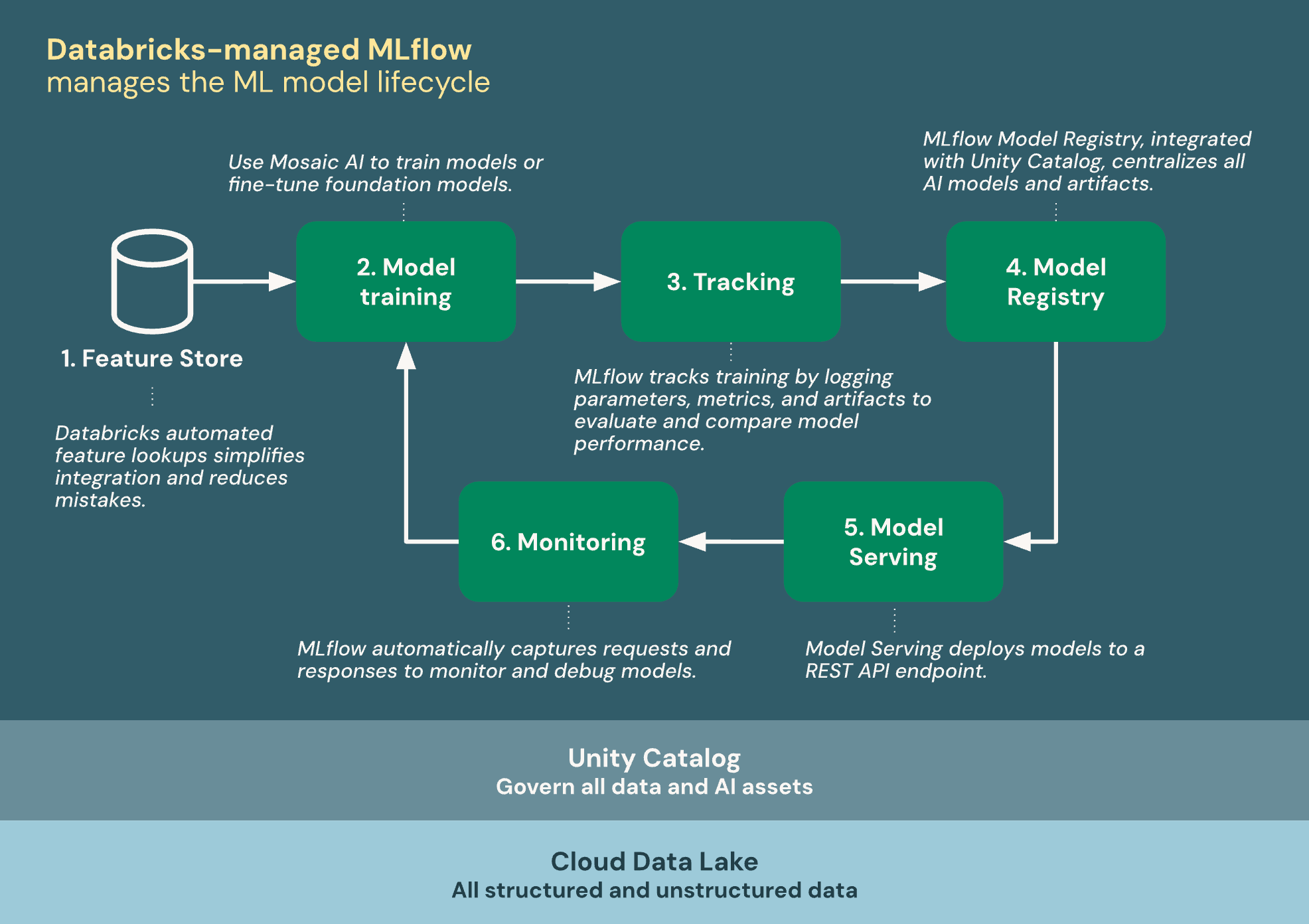
MLflow géré par Databricks repose sur Unity Catalog et Cloud lac de données pour unifier toutes vos ressources de données et d’IA dans le cycle de vie ML :
- Magasin de fonctionnalités : Les recherches automatisées de fonctionnalités Databricks simplifient l’intégration et réduisent les erreurs.
- Entraîner des modèles : Utilisez l’IA de Mosaïque pour entraîner des modèles ou ajuster les modèles de base.
- Suivi : MLflow effectue le suivi de l’apprentissage en journalisant les paramètres, les métriques et les artefacts pour évaluer et comparer les performances du modèle.
- Registre de modèles : MLflow Model Registry, intégré à Unity Catalog centralise les modèles et artefacts IA.
- Service de modèle : Mosaïque AI Model Service déploie des modèles sur un point de terminaison d’API REST.
- Surveillance: Mosaïque AI Model Service capture automatiquement les demandes et les réponses pour surveiller et déboguer des modèles. MLflow augmente ces données avec des données de trace pour chaque requête.
Entraînement du modèle
Les modèles MLflow sont au cœur du développement IA et ML sur Databricks. Les modèles MLflow sont un format standardisé pour empaqueter des modèles Machine Learning et des agents d’INTELLIGENCE artificielle générative. Le format standardisé garantit que les modèles et les agents peuvent être utilisés par les outils et workflows en aval sur Databricks.
- Documentation MLflow - Modèles.
Databricks fournit des fonctionnalités pour vous aider à entraîner différents types de modèles ML.
Suivi des expériences
Databricks utilise des expériences MLflow en tant qu’unités organisationnelles pour suivre votre travail lors du développement de modèles.
Le suivi des expériences vous permet de journaliser et de gérer les paramètres, les métriques, les artefacts et les versions de code pendant l’apprentissage automatique et le développement de l’agent. L’organisation des journaux d’activité dans des expériences et des exécutions vous permet de comparer les modèles, d’analyser les performances et d’itérer plus facilement.
- Suivi des expériences à l’aide de Databricks.
- Consultez la documentation MLflow pour obtenir des informations générales sur les exécutions et le suivi des expériences.
Registre de modèles avec le catalogue Unity
MLflow Model Registry est un référentiel de modèles centralisé, une interface utilisateur et un ensemble d’API pour la gestion du processus de déploiement de modèle.
Databricks intègre Model Registry à Unity Catalog pour fournir une gouvernance centralisée pour les modèles. L’intégration du catalogue Unity vous permet d’accéder aux modèles entre les espaces de travail, de suivre la traçabilité des modèles et de découvrir des modèles à réutiliser.
- Gérez les modèles à l’aide du catalogue Databricks Unity.
- Consultez la documentation MLflow pour obtenir des informations générales sur le Registre de modèles.
Utilisation de modèles
Databricks Model Service est étroitement intégré au Registre de modèles MLflow et fournit une interface unifiée et évolutive pour le déploiement, la gouvernance et l’interrogation de modèles IA. Chaque modèle que vous servez est disponible en tant qu’API REST que vous pouvez intégrer dans des applications web ou clientes.
Bien qu’ils soient des composants distincts, Model Service s’appuie fortement sur le Registre de modèles MLflow pour gérer le contrôle de version des modèles, la gestion des dépendances, la validation et la gouvernance.
Fonctionnalités open source vs. fonctionnalités MLflow gérées par Databricks
Pour connaître les concepts, API et fonctionnalités MLflow généraux partagés entre les versions gérées par Open Source et Databricks, reportez-vous à la documentation MLflow. Pour obtenir des fonctionnalités exclusives à MLflow managée par Databricks, consultez la documentation Databricks.
Le tableau suivant met en évidence les principales différences entre MLflow open source et MLflow géré par Databricks et fournit des liens de documentation pour vous aider à en savoir plus :
| Caractéristique | Disponibilité sur MLflow open source | Disponibilité sur MLflow managé par Databricks |
|---|---|---|
| Sécurité | L’utilisateur doit fournir sa propre couche de gouvernance de sécurité | Sécurité de niveau professionnel Databricks |
| Récupération d’urgence | Non disponible | Reprise après sinistre Databricks |
| Suivi des expériences | API MLflow Tracking | API MLflow Tracking intégrée à Databricks advanced experiment tracking |
| Registre de modèles | Registre de modèles MLflow | Registre de modèles MLflow intégré au catalogue Databricks Unity |
| Intégration d’Unity Catalog | Intégration open source à Unity Catalog | Catalogue Databricks Unity |
| Déploiement de modèle | Intégrations configurées par l’utilisateur avec des solutions de service externe (SageMaker, Kubernetes, services de conteneur, et ainsi de suite) | Solutions de service de service de modèle Databricks et de service externe |
| Agents d’IA | Développement LLM MLflow | Développement LLM MLflow intégré à Mosaic AI Agent Framework et Évaluation de l’agent |
| Chiffrement | Non disponible | Chiffrement à l’aide de clés gérées par le client |
Remarque
La collecte de données de télémétrie open source a été introduite dans MLflow 3.2.0 et est désactivée par défaut sur Databricks. Pour plus d’informations, reportez-vous à la documentation de suivi de l’utilisation de MLflow.