Exécuter des projets MLflow sur Azure Databricks
Avertissement
Les projets MLflow ne sont plus pris en charge.
Un projet MLflow est un format permettant d’empaqueter le code de science des données de façon réutilisable et reproductible. Le composant Projets MLflow comprend une API et des outils de ligne de commande pour l’exécution des projets, qui s’intègrent également au composant Suivi pour enregistrer automatiquement les paramètres et la validation git de votre code source à des fins de reproductibilité.
Cet article décrit le format d’un projet MLflow et la manière d’exécuter un projet MLflow à distance sur des clusters Azure Databricks à l’aide de l’interface CLI MLflow, ce qui facilite la mise à l’échelle verticale de votre code de science des données.
Format de projet MLflow
Tout répertoire local ou référentiel Git peut être traité comme un projet MLflow. Les conventions suivantes définissent un projet :
- Le nom du projet est le nom du répertoire.
- L’environnement software est spécifié dans
python_env.yaml, le cas échéant. Si aucun fichierpython_env.yamln’est présent, MLflow utilise un environnement virtualenv contenant uniquement Python (plus particulièrement le dernier Python disponible pour virtualenv) lors de l’exécution du projet. - Tout fichier
.pyou.shdu projet peut être un point d’entrée, sans paramètres déclarés explicitement. Lorsque vous exécutez une telle commande avec un ensemble de paramètres, MLflow transmet chaque paramètre sur la ligne de commande en utilisant la syntaxe--key <value>.
Vous spécifiez plus d’options en ajoutant un fichier MLproject, qui est un fichier texte en syntaxe YAML. Voici un exemple de fichier MLproject :
name: My Project
python_env: python_env.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
Pour Databricks Runtime 13.0 ML et versions ultérieures, les projets MLflow ne peuvent pas s’exécuter correctement dans un cluster de type de travail Databricks. Pour migrer des projets MLflow existants vers Databricks Runtime 13.0 ML et versions ultérieures, consultez Format de projet de travail Spark MLflow Databricks.
Format de projet de travail Spark MLflow Databricks
Le projet de travail Spark MLflow Databricks est un type de projet MLflow introduit dans MLflow 2.14. Ce type de projet prend en charge l’exécution de projets MLflow à partir d’un cluster de travaux Spark, et ne peut être exécuté qu’à l’aide du back-end databricks.
Les projets de travail Databricks Spark doivent définir databricks_spark_job.python_file ou entry_points. Le fait de ne pas spécifier l’un ou l’autre paramètre ou de spécifier les deux paramètres déclenche une exception.
L’exemple suivant présente un fichier MLproject qui utilise le paramètre databricks_spark_job.python_file. Ce paramètre implique l’utilisation d’un chemin d’accès codé en dur pour le fichier d’exécution Python et ses arguments.
name: My Databricks Spark job project 1
databricks_spark_job:
python_file: "train.py" # the file which is the entry point file to execute
parameters: ["param1", "param2"] # a list of parameter strings
python_libraries: # dependencies required by this project
- mlflow==2.4.1 # MLflow dependency is required
- scikit-learn
L’exemple suivant présente un fichier MLproject qui utilise le paramètre entry_points :
name: My Databricks Spark job project 2
databricks_spark_job:
python_libraries: # dependencies to be installed as databricks cluster libraries
- mlflow==2.4.1
- scikit-learn
entry_points:
main:
parameters:
model_name: {type: string, default: model}
script_name: {type: string, default: train.py}
command: "python {script_name} {model_name}"
Le paramètre entry_points vous permet de transmettre des paramètres qui utilisent des paramètres de ligne de commande, comme :
mlflow run . -b databricks --backend-config cluster-spec.json \
-P script_name=train.py -P model_name=model123 \
--experiment-id <experiment-id>
Les limitations suivantes s’appliquent aux projets de travail Databricks Spark :
- Ce type de projet ne permet pas de spécifier les sections suivantes dans le fichier
MLproject:docker_env,python_envouconda_env. - Les dépendances de votre projet doivent être spécifiées dans le champ
python_librariesde la sectiondatabricks_spark_job. Les versions de Python ne peuvent pas être personnalisées avec ce type de projet. - L’environnement en cours d’exécution doit utiliser l’environnement d’exécution du pilote Spark principal pour s’exécuter dans des clusters de travaux qui utilisent Databricks Runtime 13.0 ou version ultérieure.
- De même, toutes les dépendances Python définies comme requises pour le projet doivent être installées en tant que dépendances de cluster Databricks. Ce comportement est différent des comportements d’exécution de projet précédents, où les bibliothèques devaient être installées dans un environnement distinct.
Exécuter un projet MLflow
Pour exécuter un projet MLflow sur un cluster Azure Databricks dans l’espace de travail par défaut, utilisez la commande suivante :
mlflow run <uri> -b databricks --backend-config <json-new-cluster-spec>
où <uri> est un URI de référentiel Git ou un dossier contenant un projet MLflow et <json-new-cluster-spec> est un document JSON contenant une structure new_cluster. L’URI Git doit se présenter sous la forme https://github.com/<repo>#<project-folder>.
Voici un exemple de spécification de cluster :
{
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
}
Si vous devez installer des bibliothèques sur le Worker, utilisez le format « spécification de cluster ». Notez que les fichiers Python Wheel doivent être chargés sur DBFS et spécifiés en tant que dépendances pypi. Par exemple :
{
"new_cluster": {
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
},
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
},
{
"pypi": {
"package": "/dbfs/path_to_my_lib.whl"
}
}
]
}
Important
- Les dépendances
.egget.jarne sont pas prises en charge pour les projets MLflow. - L’exécution de projets MLflow avec des environnements Docker n’est pas prise en charge.
- Vous devez utiliser une nouvelle spécification de cluster lorsque vous exécutez un projet MLflow sur Databricks. L’exécution de projets sur des clusters existants n’est pas prise en charge.
Utilisation de SparkR
Afin d’utiliser SparkR dans une exécution de projet MLflow, le code de votre projet doit d’abord installer et importer SparkR comme suit :
if (file.exists("/databricks/spark/R/pkg")) {
install.packages("/databricks/spark/R/pkg", repos = NULL)
} else {
install.packages("SparkR")
}
library(SparkR)
Votre projet peut alors initialiser une session SparkR et utiliser SparkR normalement :
sparkR.session()
...
Exemple
Cet exemple montre comment créer une expérience, exécuter le projet de tutoriel MLflow sur un cluster Azure Databricks, afficher la sortie de l’exécution du travail et visualiser l’exécution dans l’expérience.
Spécifications
- Installez MLflow en utilisant
pip install mlflow. - Installez et configurez l’interface CLI Databricks. Le mécanisme d’authentification de l’interface CLI Databricks est requis pour exécuter des travaux sur un cluster Azure Databricks.
Étape 1 : Créer une expérience
Dans l’espace de travail, sélectionnez Créer > Expérience MLflow.
Dans le champ Name (Nom), entrez
Tutorial.Cliquez sur Créer. Notez l’ID de l’expérience. Dans cet exemple, il s’agit de
14622565.
Étape 2 : Exécuter le projet de tutoriel MLflow
Les étapes suivantes configurent la variable d’environnement MLFLOW_TRACKING_URI et exécutent le projet, en enregistrant les paramètres de formation, les métriques et le modèle formé dans l’expérience notée à l’étape précédente :
Définissez la variable d’environnement
MLFLOW_TRACKING_URIsur l’espace de travail Azure Databricks.export MLFLOW_TRACKING_URI=databricksExécutez le projet de tutoriel MLflow, qui effectue l’apprentissage d’un modèle relatif au vin. Remplacez
<experiment-id>par l’ID d’expérience que vous avez noté à l’étape précédente.mlflow run https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine -b databricks --backend-config cluster-spec.json --experiment-id <experiment-id>=== Fetching project from https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine into /var/folders/kc/l20y4txd5w3_xrdhw6cnz1080000gp/T/tmpbct_5g8u === === Uploading project to DBFS path /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Finished uploading project to /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Running entry point main of project https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine on Databricks === === Launched MLflow run as Databricks job run with ID 8651121. Getting run status page URL... === === Check the run's status at https://<databricks-instance>#job/<job-id>/run/1 ===Copiez l’URL
https://<databricks-instance>#job/<job-id>/run/1dans la dernière ligne de la sortie de l’exécution MLflow.
Étape 3 : Afficher l’exécution du travail Azure Databricks
Ouvrez l’URL que vous avez copiée à l’étape précédente dans un navigateur pour afficher la sortie de l’exécution du travail Azure Databricks :
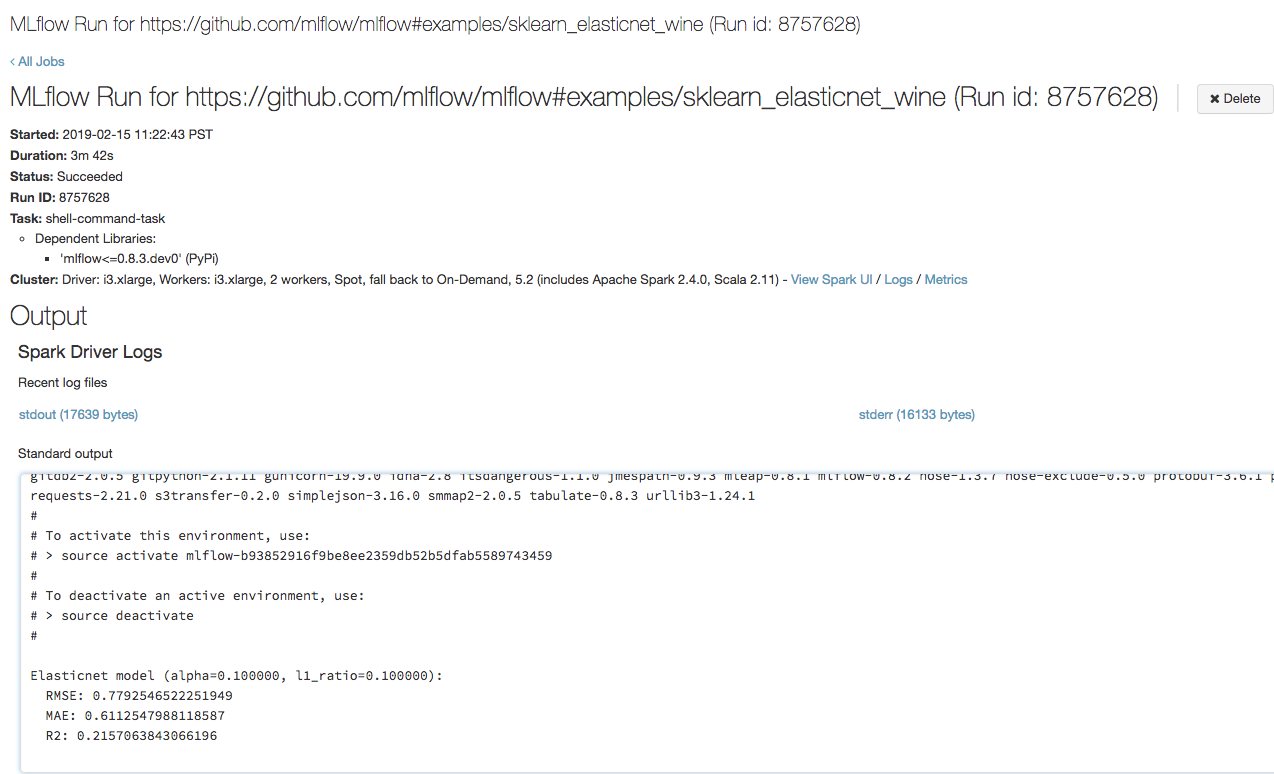
Étape 4 : Visualiser les détails de l’expérience et de l’exécution MLflow
Accédez à l’expérience dans votre espace de travail Azure Databricks.
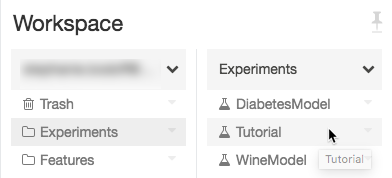
Cliquez sur l’expérience.
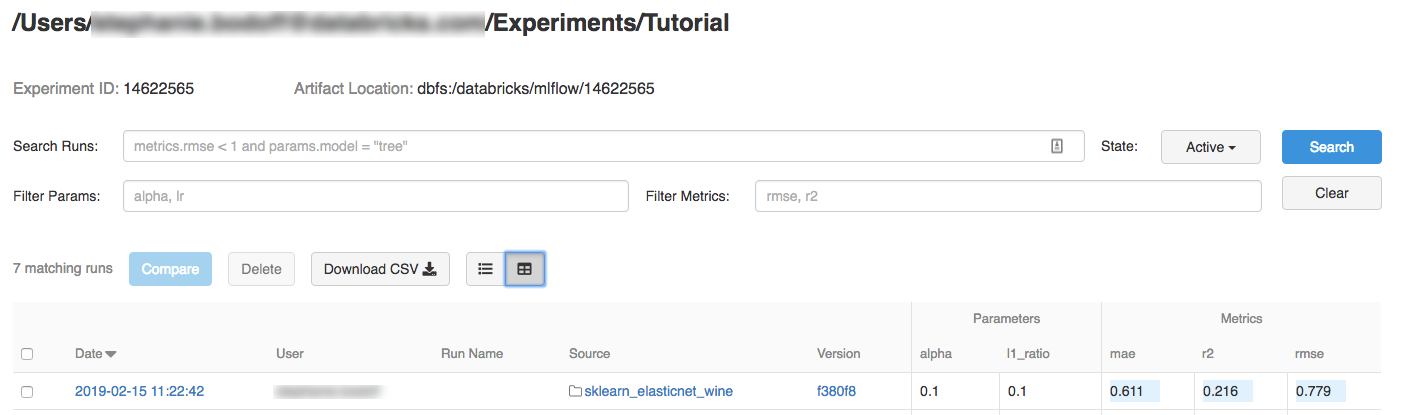
Pour afficher les détails de l’exécution, cliquez sur un lien dans la colonne Date.
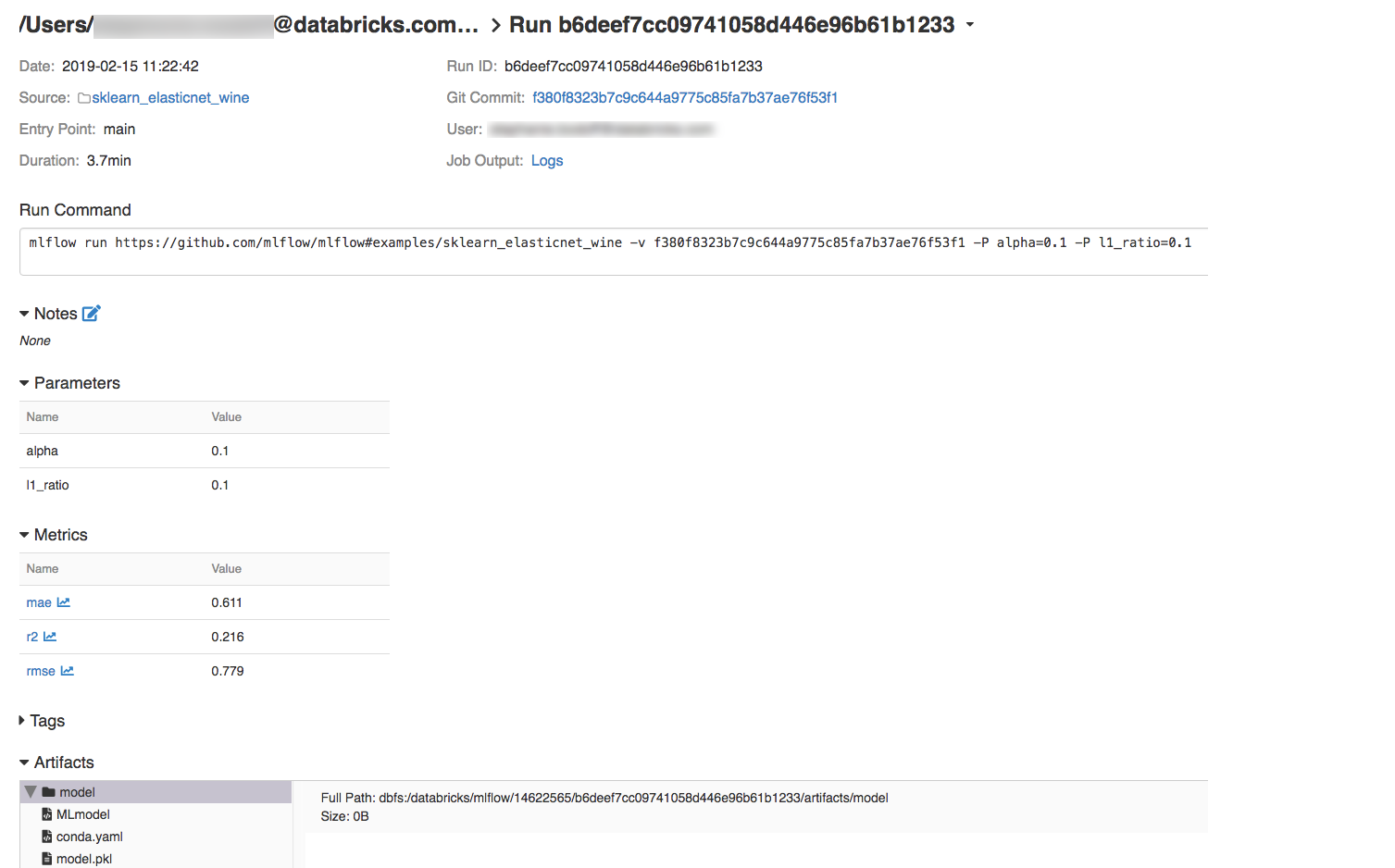
Vous pouvez afficher les journaux de votre exécution en cliquant sur le lien Journaux dans le champ Sortie du travail.
Ressources
Pour obtenir des exemples de projets MLflow, consultez la bibliothèque d’applications MLflow, qui contient un référentiel de projets prêts à l’emploi visant à faciliter l’inclusion de fonctionnalités ML dans votre code.