Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Aperçu
Les scoreurs personnalisés offrent la flexibilité ultime pour définir précisément la façon dont la qualité de votre application GenAI est mesurée. Les scoreurs personnalisés offrent une flexibilité pour définir des métriques d’évaluation adaptées à votre cas d’usage métier spécifique, qu’elles soient basées sur des heuristiques simples, une logique avancée ou des évaluations programmatiques.
Utilisez des scoreurs personnalisés pour les scénarios suivants :
- Définition d'une métrique d'évaluation personnalisée basée sur le code ou sur une heuristique.
- Personnalisation de la façon dont les données issues du tracé de votre application sont reliées aux juges LLM soutenus par la recherche de Databricks dans les scoreurs LLM prédéfinis
- Création d'un juge LLM avec un texte d'invite personnalisé en utilisant l'article sur les évaluateurs LLM basés sur les invites.
- Utilisation de votre propre modèle LLM (plutôt qu’un modèle de juge LLM hébergé par Databricks) pour l’évaluation
- Tous les autres cas d’usage où vous avez besoin de plus de flexibilité et de contrôle que fournis par les abstractions prédéfinies
Remarque
Reportez-vous à la page de concept du scoreur ou à la documentation de l’API pour obtenir une référence détaillée sur les interfaces de scoreur personnalisées.
Vue d’ensemble de l’utilisation
Les scoreurs personnalisés sont écrits en Python et vous donnent un contrôle total pour évaluer les données des traces de votre application. Un scoreur personnalisé unique fonctionne dans les deux evaluate(...) harnais pour l’évaluation hors connexion ou s’il est passé à create_monitor(...) pour la surveillance de la production.
Les types de sorties suivants sont pris en charge :
- Chaîne pass/fail :
"yes" or "no"les valeurs de chaîne s’affichent sous la forme « Pass » ou « Fail » dans l’interface utilisateur. - Valeur numérique : valeurs ordinales : entiers ou floats.
- Valeur booléenne :
TrueouFalse. - Objet de retour : Renvoyer un objet avec un score, une justification et des métadonnées supplémentaires.
En tant qu’entrée, les scoreurs personnalisés ont accès à :
- Trace MLflow complète, y compris les étendues, les attributs et les sorties. La trace est passée à l'évaluateur personnalisé en tant que classe instanciée
mlflow.entities.trace. - Dictionnaire
inputsdérivé du jeu de données d’entrée ou des post-traitements MLflow à partir de votre trace. - Valeur
outputsdérivée soit du jeu de données d’entrée, soit de la trace. Sipredict_fnest fournie, la valeuroutputssera le retour depredict_fn. - Le dictionnaire
expectations, dérivé du champexpectationsdans le jeu de données d’entrée ou des évaluations associées à la trace.
Le @scorer décorateur permet aux utilisateurs de définir des métriques d’évaluation personnalisées qui peuvent être transmises à mlflow.genai.evaluate() via l’argument scorers ou create_monitor(...).
La fonction scorer est appelée avec des arguments nommés en fonction de la signature ci-dessous. Tous les arguments nommés sont facultatifs afin de pouvoir utiliser n’importe quelle combinaison. Par exemple, vous pouvez définir un scoreur qui utilise uniquement inputs et trace comme arguments et omet outputs et expectations.
from mlflow.genai.scorers import scorer
from typing import Optional, Any
from mlflow.entities import Feedback
@scorer
def my_custom_scorer(
*, # evaluate(...) harness will always call your scorer with named arguments
inputs: Optional[dict[str, Any]], # The agent's raw input, parsed from the Trace or dataset, as a Python dict
outputs: Optional[Any], # The agent's raw output, parsed from the Trace or
expectations: Optional[dict[str, Any]], # The expectations passed to evaluate(data=...), as a Python dict
trace: Optional[mlflow.entities.Trace] # The app's resulting Trace containing spans and other metadata
) -> int | float | bool | str | Feedback | list[Feedback]
Approche de développement du scoreur personnalisé
Lorsque vous développez des métriques, vous devez effectuer rapidement une itération sur la métrique sans avoir à exécuter votre application chaque fois que vous apportez une modification au scoreur. Pour ce faire, nous vous recommandons les étapes suivantes :
Étape 1 : Définir vos données initiales de métrique, d’application et d’évaluation
import mlflow
from mlflow.entities import Trace
from mlflow.genai.scorers import scorer
from typing import Any
@mlflow.trace
def my_app(input_field_name: str):
return {'output': input_field_name+'_output'}
@scorer
def my_metric() -> int:
# placeholder return value
return 1
eval_set = [{'inputs': {'input_field_name': 'test'}}]
Étape 2 : Générer des traces à partir de votre application à l’aide de evaluate()
eval_results = mlflow.genai.evaluate(
data=eval_set,
predict_fn=my_app,
scorers=[dummy_metric]
)
Étape 3 : Interroger et stocker les traces obtenues
generated_traces = mlflow.search_traces(run_id=eval_results.run_id)
Étape 4 : Passer les traces obtenues en tant qu’entrée evaluate() à mesure que vous effectuez une itération sur votre métrique
La fonction search_traces retourne un DataFrame Pandas de traces, que vous pouvez transmettre directement à evaluate() en tant que jeu de données d’entrée. Cela vous permet d’itérer rapidement sur votre métrique sans avoir à réexécuter votre application.
@scorer
def my_metric(outputs: Any):
# Implement the actual metric logic here.
return outputs == "test_output"
# Note the lack of a predict_fn parameter
mlflow.genai.evaluate(
data=generated_traces,
scorers=[my_metric],
)
Exemples de scoreur personnalisé
Dans ce guide, nous allons vous montrer différentes approches pour créer des scoreurs personnalisés.

Prérequis : créer un exemple d’application et obtenir une copie locale des traces
Dans toutes les approches, nous utilisons l’exemple d’application ci-dessous et la copie des traces (extraites à l’aide de l’approche ci-dessus).
import mlflow
from openai import OpenAI
from typing import Any
from mlflow.entities import Trace
from mlflow.genai.scorers import scorer
# Enable auto logging for OpenAI
mlflow.openai.autolog()
# Connect to a Databricks LLM via OpenAI using the same credentials as MLflow
# Alternatively, you can use your own OpenAI credentials here
mlflow_creds = mlflow.utils.databricks_utils.get_databricks_host_creds()
client = OpenAI(
api_key=mlflow_creds.token,
base_url=f"{mlflow_creds.host}/serving-endpoints"
)
@mlflow.trace
def sample_app(messages: list[dict[str, str]]):
# 1. Prepare messages for the LLM
messages_for_llm = [
{"role": "system", "content": "You are a helpful assistant."},
*messages,
]
# 2. Call LLM to generate a response
response = client.chat.completions.create(
model="databricks-claude-3-7-sonnet", # This example uses Databricks hosted Claude. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc.
messages=messages_for_llm,
)
return response.choices[0].message.content
# Create a list of messages for the LLM to generate a response
eval_dataset = [
{
"inputs": {
"messages": [
{"role": "user", "content": "How much does a microwave cost?"},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "Can I return the microwave I bought 2 months ago?",
},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "I'm having trouble with my account. I can't log in.",
},
{
"role": "assistant",
"content": "I'm sorry to hear that you're having trouble with your account. Are you using our website or mobile app?",
},
{"role": "user", "content": "Website"},
]
},
},
]
@scorer
def dummy_metric():
# This scorer is just to help generate initial traces.
return 1
# Generate initial traces by running the sample_app.
# The results, including traces, are logged to the MLflow experiment defined above.
initial_eval_results = mlflow.genai.evaluate(
data=eval_dataset, predict_fn=sample_app, scorers=[dummy_metric]
)
generated_traces = mlflow.search_traces(run_id=initial_eval_results.run_id)
Après avoir exécuté le code ci-dessus, vous devez avoir trois traces dans votre expérience.
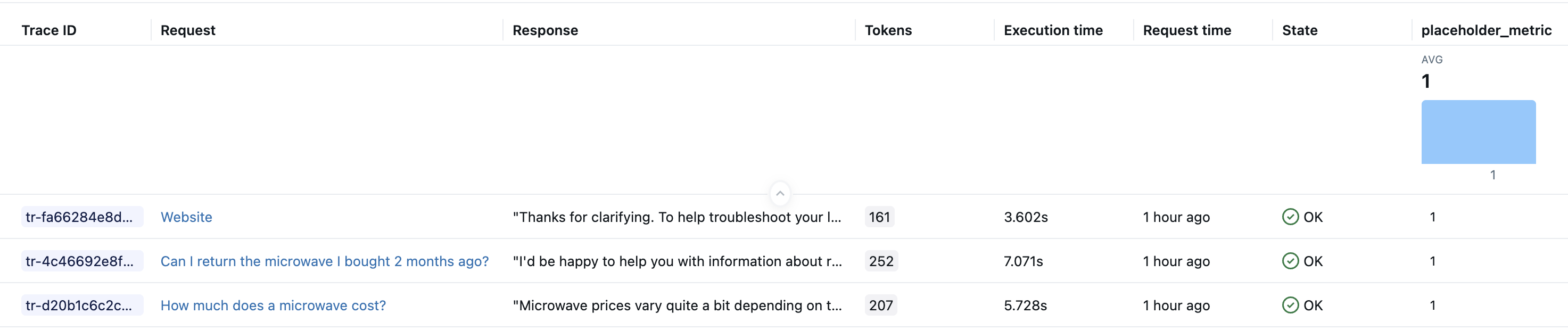
Exemple 1 : Accès aux données à partir de la trace
Accédez à l’objet MLflow Trace complet pour utiliser différents détails (étendues, entrées, sorties, attributs, minutage) pour le calcul précis des métriques.
Remarque
La section des prérequis generated_traces sera utilisée comme données d’entrée pour ces exemples.
Ce scoreur vérifie si le temps d’exécution total de la trace se trouve dans une plage acceptable.
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.entities import Trace, Feedback, SpanType
@scorer
def llm_response_time_good(trace: Trace) -> Feedback:
# Search particular span type from the trace
llm_span = trace.search_spans(span_type=SpanType.CHAT_MODEL)[0]
response_time = (llm_span.end_time_ns - llm_span.start_time_ns) / 1e9 # second
max_duration = 5.0
if response_time <= max_duration:
return Feedback(
value="yes",
rationale=f"LLM response time {response_time:.2f}s is within the {max_duration}s limit."
)
else:
return Feedback(
value="no",
rationale=f"LLM response time {response_time:.2f}s exceeds the {max_duration}s limit."
)
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
span_check_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[llm_response_time_good]
)
Exemple 2 : Encapsulation d’un juge LLM prédéfini
Créez un scoreur personnalisé qui encapsule les juges LLM prédéfinis de MLflow. Utilisez-le pour prétraiter les données de suivi du juge ou post-traiter ses commentaires.
Cet exemple montre comment encapsuler le is_context_relevant juge qui évalue si le contexte donné est pertinent pour la requête, pour déterminer si la réponse de l’assistant est pertinente pour la requête de l’utilisateur.
import mlflow
from mlflow.entities import Trace, Feedback
from mlflow.genai.judges import is_context_relevant
from mlflow.genai.scorers import scorer
from typing import Any
# Assume `generated_traces` is available from the prerequisite code block.
@scorer
def is_message_relevant(inputs: dict[str, Any], outputs: str) -> Feedback:
# The `inputs` field for `sample_app` is a dictionary like: {"messages": [{"role": ..., "content": ...}, ...]}
# We need to extract the content of the last user message to pass to the relevance judge.
last_user_message_content = None
if "messages" in inputs and isinstance(inputs["messages"], list):
for message in reversed(inputs["messages"]):
if message.get("role") == "user" and "content" in message:
last_user_message_content = message["content"]
break
if not last_user_message_content:
raise Exception("Could not extract the last user message from inputs to evaluate relevance.")
# Call the `relevance_to_query judge. It will return a Feedback object.
return is_context_relevant(
request=last_user_message_content,
context={"response": outputs},
)
# Evaluate the custom relevance scorer
custom_relevance_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[is_message_relevant]
)
Exemple 3 : Utilisation expectations
Lorsqu'mlflow.genai.evaluate() est appelé avec un argument data qui est une liste de dictionnaires ou d'un DataFrame Pandas, chaque ligne peut contenir une clé expectations. La valeur associée à cette clé est transmise directement à votre scorer personnalisé.
import mlflow
from mlflow.entities import Feedback
from mlflow.genai.scorers import scorer
from typing import Any, List, Optional, Union
expectations_eval_dataset_list = [
{
"inputs": {"messages": [{"role": "user", "content": "What is 2+2?"}]},
"expectations": {
"expected_response": "2+2 equals 4.",
"expected_keywords": ["4", "four", "equals"],
}
},
{
"inputs": {"messages": [{"role": "user", "content": "Describe MLflow in one sentence."}]},
"expectations": {
"expected_response": "MLflow is an open-source platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models.",
"expected_keywords": ["mlflow", "open-source", "platform", "machine learning"],
}
},
{
"inputs": {"messages": [{"role": "user", "content": "Say hello."}]},
"expectations": {
"expected_response": "Hello there!",
# No keywords needed for this one, but the field can be omitted or empty
}
}
]
Exemple 3.1 : Correspondance exacte avec la réponse attendue
Ce scoreur vérifie si la réponse de l’assistant correspond exactement à celle expected_response fournie dans le expectations.
@scorer
def exact_match(outputs: str, expectations: dict[str, Any]) -> bool:
# Scorer can return primitive value like bool, int, float, str, etc.
return outputs == expectations["expected_response"]
exact_match_eval_results = mlflow.genai.evaluate(
data=expectations_eval_dataset_list,
predict_fn=sample_app, # sample_app is from the prerequisite section
scorers=[exact_match]
)
Exemple 3.2 : Vérification de présence de mot clé à partir des attentes
Ce scoreur vérifie si tous les expected_keywords du expectations sont présents dans la réponse de l’assistant.
@scorer
def keyword_presence_scorer(outputs: str, expectations: dict[str, Any]) -> Feedback:
expected_keywords = expectations.get("expected_keywords")
print(expected_keywords)
if expected_keywords is None:
return Feedback(
score=None, # Undetermined, as no keywords were expected
rationale="No 'expected_keywords' provided in expectations."
)
missing_keywords = []
for keyword in expected_keywords:
if keyword.lower() not in outputs.lower():
missing_keywords.append(keyword)
if not missing_keywords:
return Feedback(value="yes", rationale="All expected keywords are present in the response.")
else:
return Feedback(value="no", rationale=f"Missing keywords: {', '.join(missing_keywords)}.")
keyword_presence_eval_results = mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=sample_app, # sample_app is from the prerequisite section
scorers=[keyword_presence_scorer]
)
Exemple 4 : Renvoi de plusieurs objets de commentaires
Un scoreur unique peut retourner une liste d’objets Feedback , ce qui permet à un scoreur d’évaluer simultanément plusieurs facettes de qualité (p. ex., PII, sentiment, concision). Chaque Feedback objet doit idéalement avoir un nom de métrique unique name (qui devient le nom de métrique dans les résultats) ; sinon, ils peuvent se remplacer si les noms sont générés automatiquement et entrent en collision. Si un nom n’est pas fourni, MLflow tente de générer un nom basé sur le nom de la fonction scorer et un index.
Cet exemple illustre un scoreur qui retourne deux éléments distincts de commentaires pour chaque trace :
-
is_not_empty_check: valeur booléenne indiquant si le contenu de la réponse n’est pas vide. -
response_char_length: valeur numérique pour la longueur du caractère de la réponse.
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.entities import Feedback, Trace # Ensure Feedback and Trace are imported
from typing import Any, Optional
# Assume `generated_traces` is available from the prerequisite code block.
@scorer
def comprehensive_response_checker(outputs: str) -> list[Feedback]:
feedbacks = []
# 1. Check if the response is not empty
feedbacks.append(
Feedback(name="is_not_empty_check", value="yes" if outputs != "" else "no")
)
# 2. Calculate response character length
char_length = len(outputs)
feedbacks.append(Feedback(name="response_char_length", value=char_length))
return feedbacks
multi_feedback_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[comprehensive_response_checker]
)
Le résultat aura deux colonnes : is_not_empty_check et response_char_length sous forme d’évaluations.
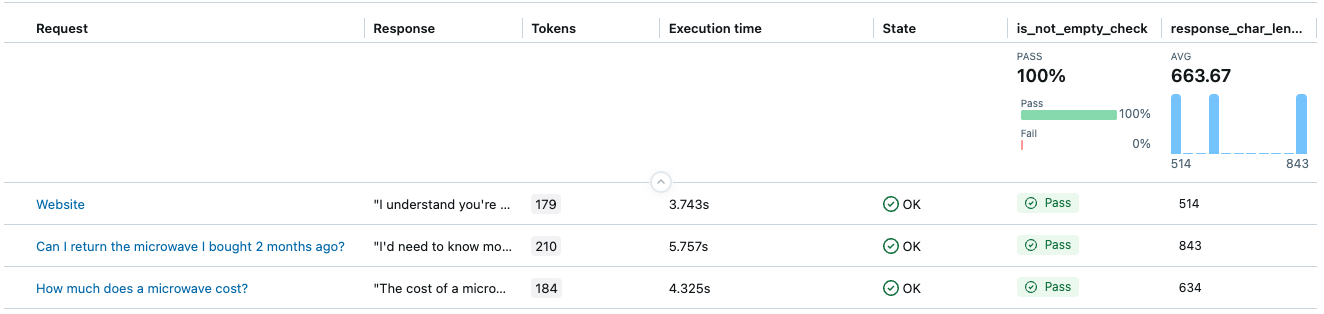
Exemple 5 : Utilisation de votre propre LLM pour un juge
Intégrez un LLM personnalisé ou hébergé en externe au sein d’un scoreur. Le scoreur gère les appels d’API, la mise en forme d’entrée/sortie et génère Feedback à partir de la réponse de votre LLM, ce qui donne un contrôle total sur le processus de jugement.
Vous pouvez également définir le source champ dans l’objet Feedback pour indiquer que la source de l’évaluation est un juge LLM.
import mlflow
import json
from mlflow.genai.scorers import scorer
from mlflow.entities import AssessmentSource, AssessmentSourceType, Feedback
from typing import Any, Optional
# Assume `generated_traces` is available from the prerequisite code block.
# Assume `client` (OpenAI SDK client configured for Databricks) is available from the prerequisite block.
# client = OpenAI(...)
# Define the prompts for the Judge LLM.
judge_system_prompt = """
You are an impartial AI assistant responsible for evaluating the quality of a response generated by another AI model.
Your evaluation should be based on the original user query and the AI's response.
Provide a quality score as an integer from 1 to 5 (1=Poor, 2=Fair, 3=Good, 4=Very Good, 5=Excellent).
Also, provide a brief rationale for your score.
Your output MUST be a single valid JSON object with two keys: "score" (an integer) and "rationale" (a string).
Example:
{"score": 4, "rationale": "The response was mostly accurate and helpful, addressing the user's query directly."}
"""
judge_user_prompt = """
Please evaluate the AI's Response below based on the Original User Query.
Original User Query:
```{user_query}```
AI's Response:
```{llm_response_from_app}```
Provide your evaluation strictly as a JSON object with "score" and "rationale" keys.
"""
@scorer
def answer_quality(inputs: dict[str, Any], outputs: str) -> Feedback:
user_query = inputs["messages"][-1]["content"]
# Call the Judge LLM using the OpenAI SDK client.
judge_llm_response_obj = client.chat.completions.create(
model="databricks-claude-3-7-sonnet", # This example uses Databricks hosted Claude. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o-mini, etc.
messages=[
{"role": "system", "content": judge_system_prompt},
{"role": "user", "content": judge_user_prompt.format(user_query=user_query, llm_response_from_app=outputs)},
],
max_tokens=200, # Max tokens for the judge's rationale
temperature=0.0, # For more deterministic judging
)
judge_llm_output_text = judge_llm_response_obj.choices[0].message.content
# Parse the Judge LLM's JSON output.
judge_eval_json = json.loads(judge_llm_output_text)
parsed_score = int(judge_eval_json["score"])
parsed_rationale = judge_eval_json["rationale"]
return Feedback(
value=parsed_score,
rationale=parsed_rationale,
# Set the source of the assessment to indicate the LLM judge used to generate the feedback
source=AssessmentSource(
source_type=AssessmentSourceType.LLM_JUDGE,
source_id="claude-3-7-sonnet",
)
)
# Evaluate the scorer using the pre-generated traces.
custom_llm_judge_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[answer_quality]
)
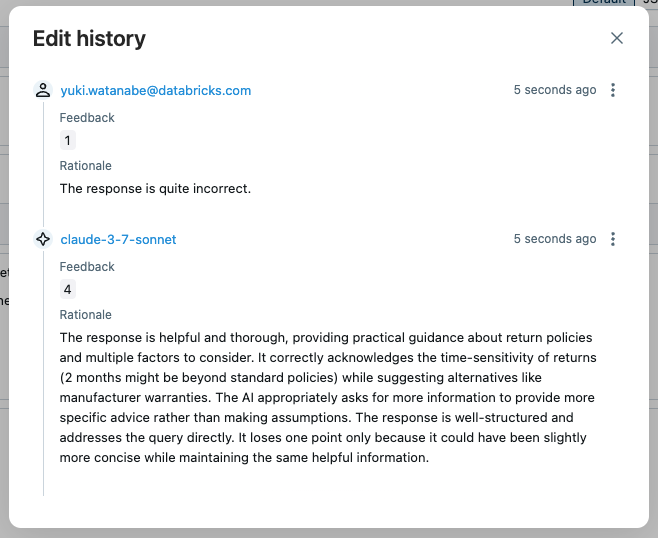
En ouvrant la trace dans l’interface utilisateur et en cliquant sur l’évaluation « answer_quality », vous pouvez voir les métadonnées du juge, telles que l'argumentation, l’horodatage, le nom du modèle de juge, etc. Si l’évaluation du juge n’est pas correcte, vous pouvez remplacer le score en cliquant sur le bouton Edit.
La nouvelle évaluation remplacera l’évaluation initiale du juge, mais l’historique des modifications sera conservé pour référence ultérieure.
Étapes suivantes
Poursuivez votre parcours avec ces actions et tutoriels recommandés.
- Évaluer avec des scoreurs LLM personnalisés - Créer une évaluation sémantique à l’aide de LLMs
- Exécuter des scoreurs en production - Déployer vos scoreurs pour la surveillance continue
- Créer des jeux de données d’évaluation - Créer des données de test pour vos scoreurs
Guides de référence
Explorez la documentation détaillée relative aux concepts et fonctionnalités mentionnés dans ce guide.
- Scorers - Présentation approfondie du fonctionnement des scoreurs et de leur architecture
-
Harnais d’évaluation - Comprendre comment
mlflow.genai.evaluate()utiliser vos scoreurs - Juges LLM - Découvrir la base de l’évaluation basée sur l’IA