Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Découvrez comment organiser les notebooks et modulariser du code dans des notebooks. Consultez des exemples et comprenez quand utiliser d’autres méthodes pour l’orchestration de notebooks.
Méthodes d’orchestration et de modularisation du code
Le tableau suivant compare les méthodes disponibles pour orchestrer des notebooks et modulariser le code dans les notebooks.
| Méthode | Cas d'utilisation | Remarques |
|---|---|---|
| Travaux Lakeflow | Orchestration du notebook (recommandé) | Méthode recommandée pour orchestrer des notebooks. Prend en charge les flux de travail complexes avec les dépendances de tâches, la planification et les déclencheurs. Fournit une approche robuste et évolutive pour les charges de travail de production, mais nécessite une installation et une configuration. |
| dbutils.notebook.run() | Orchestration du notebook | Utilisez dbutils.notebook.run() si les tâches ne peuvent pas prendre en charge votre cas d’usage, comme l'itération de notebooks sur un ensemble dynamique de paramètres.Démarre un nouveau travail éphémère pour chaque appel, ce qui peut augmenter la surcharge et manque de fonctionnalités de planification avancées. |
| fichiers d’espace de travail | Modularisation du code (recommandé) | Méthode recommandée pour la modularisation du code. Modularisez du code en fichiers de code réutilisables stockés dans l’espace de travail. Prend en charge le contrôle de version avec les dépôts et l’intégration avec les IDE pour un meilleur débogage et des tests unitaires. Nécessite une configuration supplémentaire pour gérer les chemins d’accès et les dépendances des fichiers. |
| %run | Modularisation du code | Utilisez %run si vous ne pouvez pas accéder aux fichiers d’espace de travail.Importez simplement des fonctions ou des variables à partir d’autres notebooks en les exécutant inline. Utile pour le prototypage, mais peut entraîner un code étroitement couplé qui est plus difficile à gérer. Ne prend pas en charge le passage de paramètres ou le contrôle de version. |
%run et dbutils.notebook.run()
La commande %run vous permet d’inclure un autre notebook dans un notebook. Vous pouvez utiliser %run pour modulariser votre code en plaçant des fonctions de prise en charge dans un bloc-notes distinct. Vous pouvez également l’utiliser pour concaténer les notebooks qui implémentent les étapes dans une analyse. Lorsque vous utilisez %run, le notebook appelé est immédiatement exécuté et les fonctions et les variables définies dans celui-ci sont disponibles dans le notebook appelant.
L’API dbutils.notebook complète %run, car elle vous permet de transmettre des paramètres à un notebook et de retourner des valeurs à partir d’un notebook. Cela vous permet de créer des flux de travail et des pipelines complexes avec des dépendances. Par exemple, vous pouvez obtenir une liste de fichiers dans un répertoire et passer les noms à un autre bloc-notes, ce qui est impossible avec %run. Vous pouvez également créer des flux de travail if-then-else en fonction des valeurs de retour.
Contrairement à %run, la méthode dbutils.notebook.run() démarre un nouveau travail pour exécuter le notebook.
Comme toutes les API dbutils, ces méthodes sont disponibles uniquement en Python et Scala. Toutefois, vous pouvez utiliser dbutils.notebook.run() pour appeler un notebook R.
Utiliser %run pour importer un notebook
Dans cet exemple, le premier notebook définit une fonction reverse, celle-ci est disponible dans le deuxième notebook après l’utilisation de la commande magic %run pour exécuter shared-code-notebook.

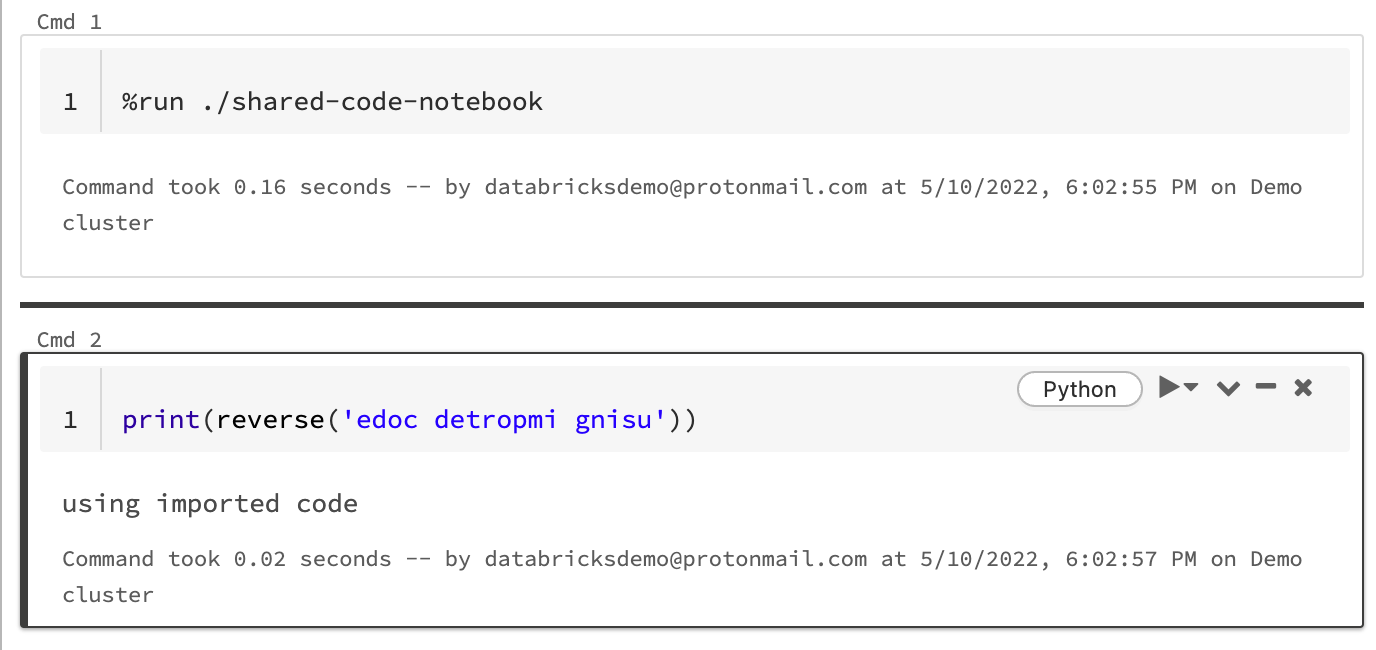
Étant donné que les deux blocs-notes se trouvent dans le même répertoire dans l’espace de travail, utilisez le préfixe ./ dans ./shared-code-notebook pour indiquer que le chemin d’accès doit être résolu par rapport au bloc-notes en cours d’exécution. Vous pouvez organiser les notebooks en répertoires, tels que %run ./dir/notebook, ou utiliser un chemin absolu comme %run /Users/username@organization.com/directory/notebook.
Notes
-
%rundoit se trouver dans une cellule par lui-même, car il exécute l’intégralité du notebook en ligne. - Vous ne pouvez pas utiliser
%runpour exécuter un fichier Python etimportles entités définies dans ce fichier dans un notebook-notes. Pour une importation depuis un fichier Python, consultez Modulariser votre code avec des fichiers. Ou empaquetez le fichier dans une bibliothèque Python, créez une bibliothèque Azure Databricks à partir de cette bibliothèque Python et installez la bibliothèque dans le cluster que vous utilisez pour exécuter votre notebook. - Lorsque vous utilisez
%runpour exécuter un bloc-notes qui contient des widgets, par défaut, le notebook spécifié s’exécute avec les valeurs par défaut du widget. Vous pouvez également transmettre des valeurs aux widgets ; consultez Utiliser des widgets Databricks avec %run.
Utiliser dbutils.notebook.run pour démarrer un nouveau travail
Exécutez un notebook et renvoyez sa valeur de sortie. La méthode démarre un travail éphémère qui s’exécute immédiatement.
Les méthodes disponibles dans l’API dbutils.notebook sont run et exit. Les paramètres et les valeurs renvoyées doivent être des chaînes.
run(path: String, timeout_seconds: int, arguments: Map): String
Le paramètre timeout_seconds contrôle le délai d’expiration de l’exécution (0 signifie qu’aucun délai d’attente n’est nécessaire). L’appel à run lance une exception s'il ne se termine pas dans le délai spécifié. Si Azure Databricks est en panne pendant plus de 10 minutes, l’exécution du notebook échoue, peu importe timeout_seconds.
Le paramètre arguments définit les valeurs des widgets du notebook cible. Plus précisément, si le notebook que vous exécutez possède un widget nommé A et que vous transmettez une paire clé-valeur ("A": "B") dans le paramètre arguments à l’appel run(), la récupération de la valeur du widget A retourne "B". Vous trouverez les instructions relatives à la création et à l’utilisation des widgets dans l’article Widgets Databricks.
Notes
- Le paramètre accepte uniquement les
argumentscaractères latins (jeu de caractères ASCII). L’utilisation de caractères non-ASCII retourne une erreur. - Les travaux créés avec l’API
dbutils.notebookdoivent être terminés dans un délai maximum de 30 jours.
run Utilisation
Python
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
Langage de programmation Scala
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
Passer des données structurées entre des notebooks
Cette section explique comment passer des données structurées entre des notebooks.
Python
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
Langage de programmation Scala
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
des erreurs
Cette section montre comment gérer les erreurs.
Python
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
Langage de programmation Scala
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here, we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
Exécuter simultanément plusieurs notebooks
Vous pouvez exécuter plusieurs notebooks en même temps à l’aide de constructions Scala et Python standard, telles que des Threads (Scala, Python) et Futures (Scala, Python). Les exemples de notebooks illustrent comment utiliser ces constructions.
- Téléchargez les quatre blocs-notes suivants. Les notebooks sont écrits en Scala.
- Importez les notebooks dans un dossier unique de l’espace de travail.
- Exécutez le notebook Exécuter simultanément.