Gérer des notebooks
Vous pouvez gérer des notebooks en tirant parti de l’interface utilisateur, de l’interface CLI et de l’API Espace de travail. Cet article analyse le fonctionnement des tâches de notebook avec l’interface utilisateur. Pour les autres méthodes, consultez Qu’est-ce que l’interface CLI Databricks et la référence de l’API d’espace de travail.
Créer un notebook
Utiliser le bouton Nouveau dans la barre latérale de l’espace de travail
Pour créer un bloc-notes dans votre dossier par défaut, cliquez ![]() Nouveau dans la barre latérale, puis sélectionnez bloc-notes dans le menu.
Nouveau dans la barre latérale, puis sélectionnez bloc-notes dans le menu.
Databricks crée et ouvre un notebook vide dans votre dossier par défaut. La langue par défaut est celle que vous avez utilisée en dernier et le notebook est automatiquement attaché à la ressource de calcul utilisée en dernier.
Créer un notebook dans n’importe quel dossier
Vous pouvez créer un nouveau notebook dans n’importe quel dossier (par exemple, dans le dossier Partagé) en procédant comme suit :
- Dans la barre latérale, cliquez sur
 Espace de travail.
Espace de travail. - Cliquez avec le bouton droit sur le nom d’un dossier et sélectionnez Créer > Notebook. Un notebook vide s’ouvre dans l’espace de travail.
Ouvrir un notebook
Dans votre espace de travail, cliquez sur ![]() . Le chemin d’accès au notebook s’affiche lorsque vous pointez votre souris sur le titre du notebook.
. Le chemin d’accès au notebook s’affiche lorsque vous pointez votre souris sur le titre du notebook.
Supprimer un bloc-notes
Pour plus d’informations sur l’accès au menu de l’espace de travail et sur la suppression d’un notebook ou d’autres éléments dans l’espace de travail, voir Dossiers et Opérations d’objet dans l’espace de travail.
Copier le chemin ou l’URL d’un notebook
Pour obtenir le chemin ou l’URL du fichier de notebook sans ouvrir le notebook, cliquez avec le bouton droit sur le nom du notebook, puis sélectionnez Copier > Chemin ou Copier > URL.
Renommer un notebook
Pour modifier le titre d’un notebook ouvert, cliquez sur son titre et modifiez-le en ligne ou cliquez sur Fichier > Renommer.
Contrôler l’accès à un notebook
Si votre compte Azure Databricks dispose du Plan Premium, vous pouvez utiliser le Contrôle d’accès aux espaces de travail pour contrôler les utilisateurs qui ont accès à un notebook.
Configurer les paramètres de l’éditeur
Pour configurer les paramètres de l’éditeur :
- Cliquez sur votre nom d’utilisateur en haut à droite de l’espace de travail, puis sélectionnez Paramètres dans la liste déroulante.
- Dans la barre latérale des Paramètres, sélectionnez Développeur.
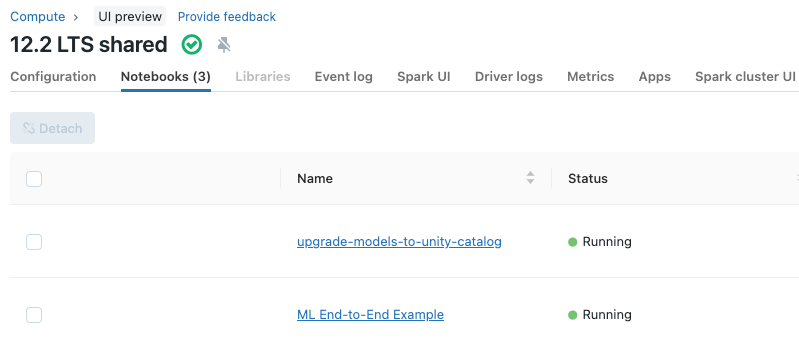
Afficher les notebooks attachés à un cluster
L’onglet Notebooks de la page de détails du cluster affiche les notebooks qui ont été récemment attachés à un cluster. L’onglet affiche également l’état du notebook ainsi que la dernière fois qu’une commande a été exécutée à partir du notebook.