Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Important
La mise à l’échelle automatique Lakebase est disponible dans les régions suivantes : eastus, eastus2, centralus, southcentralus, westus, westus2, canadacentral, brazilsouth, northeurope, uksouth, westeurope, australiaeast, centralindia, southeastasia
La version Lakebase Autoscaling est la dernière de Lakebase, avec l'évolutivité automatique, la mise à l’échelle jusqu'à zéro, la création de branches et la restauration instantanée. Si vous êtes un utilisateur Lakebase Provisionné, consultez Lakebase Provisioned.
La haute disponibilité associe un calcul en lecture/écriture principal avec une ou plusieurs instances de calcul secondaires réparties entre les zones de disponibilité. Lorsque le serveur principal devient indisponible, une instance de calcul secondaire est automatiquement promue et votre application continue à partir de la dernière transaction validée. Votre chaîne de connexion reste inchangée.
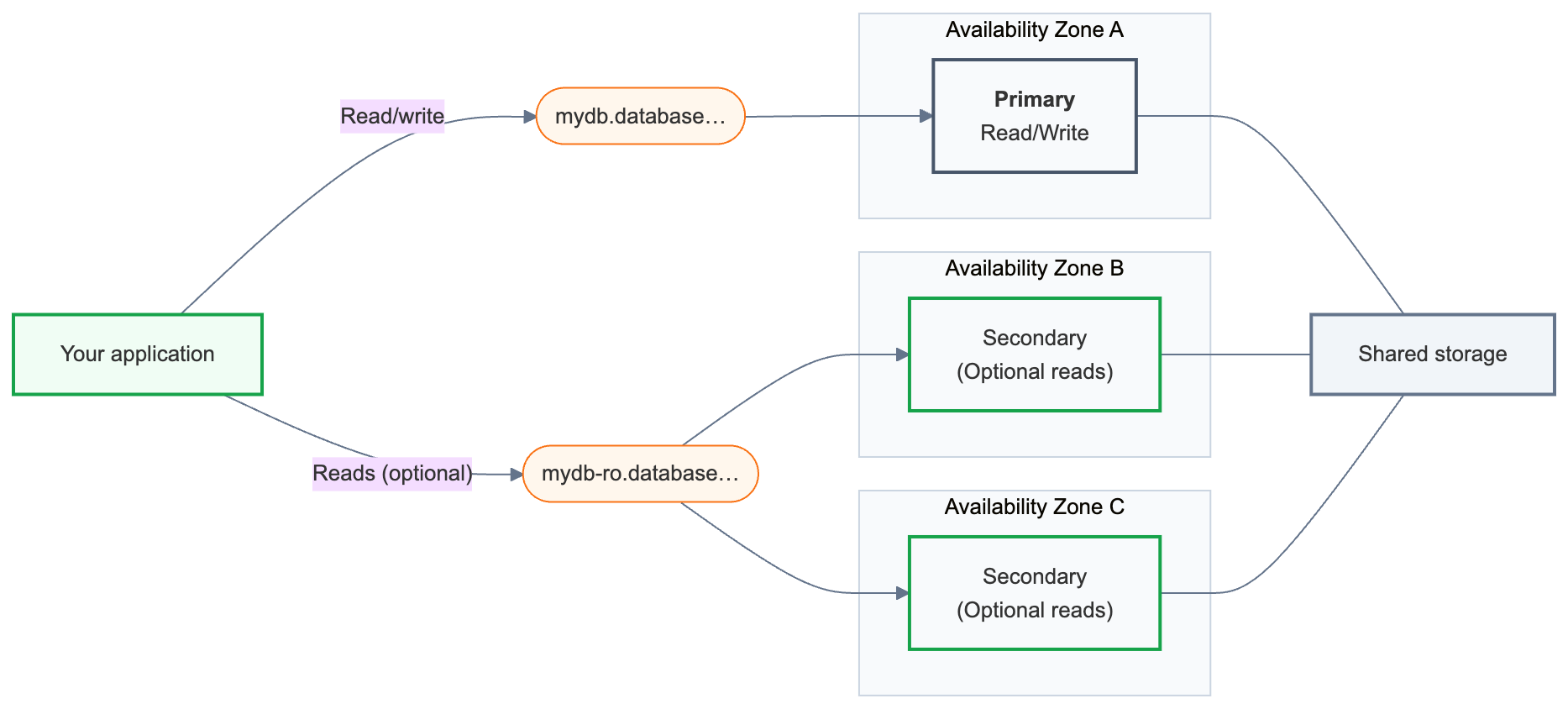
Fonctionnement de la haute disponibilité
Un point de terminaison Lakebase est l’adresse de base de données à qui votre application se connecte. Un point de terminaison à haute disponibilité expose deux chaînes de connexion :
-
Principal (
{endpoint-id}.database.{region}.databricks.com) : votre connexion principale en lecture/écriture. Utilisez-la dans chaque application qui se connecte à votre base de données. Après un basculement, il achemine automatiquement la tâche vers l'unité de calcul actuellement principale. -
Secondaire (
{endpoint-id}-ro.database.{region}.databricks.com) : disponible uniquement lorsque l’autorisation d’accès aux instances de calcul en lecture seule est activée. Les instances de calcul secondaires existent principalement comme secours en cas de basculement ; l’activation de l’accès en lecture vous permet également d’acheminer les requêtes de lecture à travers elles.
Les deux chaînes de connexion sont disponibles à partir de la boîte de dialogue Se connecter sur votre point de terminaison.
Derrière ces chaînes de connexion, un point de terminaison à haute disponibilité a toujours exactement une instance de calcul principale et une à trois instances de calcul secondaires . Le serveur principal gère tout le trafic en lecture/écriture. Les instances de calcul secondaires s’exécutent dans différentes zones de disponibilité et sont promues pour devenir le principal en cas d’échec.
Chaque instance de calcul secondaire a un paramètre Access qui détermine s’il sert également le trafic de lecture :
| Accès secondaire | Qu’est-ce que cela fait ? |
|---|---|
| Lecture seule | L'instance de calcul secondaire sert des lectures via la chaîne de connexion -ro et peut être promue comme primaire si nécessaire |
| Désactivé | L’instance de calcul secondaire est active et prête pour le remplacement, mais ne sert pas le trafic de lecture |
Vous contrôlez cela avec le paramètre Autoriser l’accès aux instances de calcul en lecture seule sur le point de terminaison, auquel vous pouvez accéder dans le tiroir de calcul Modifier . Lorsque l'option est activée, toutes les instances de calcul secondaires servent des lectures ; lorsque l'option est désactivée, elles ne sont en veille que pour le basculement. Dans les deux cas, le matériel de calcul est déjà alloué et en cours d’exécution : la promotion ne nécessite aucun nouvel approvisionnement. Par conséquent, votre capacité de basculement est réservée, quelle que soit la demande dans la zone de disponibilité.
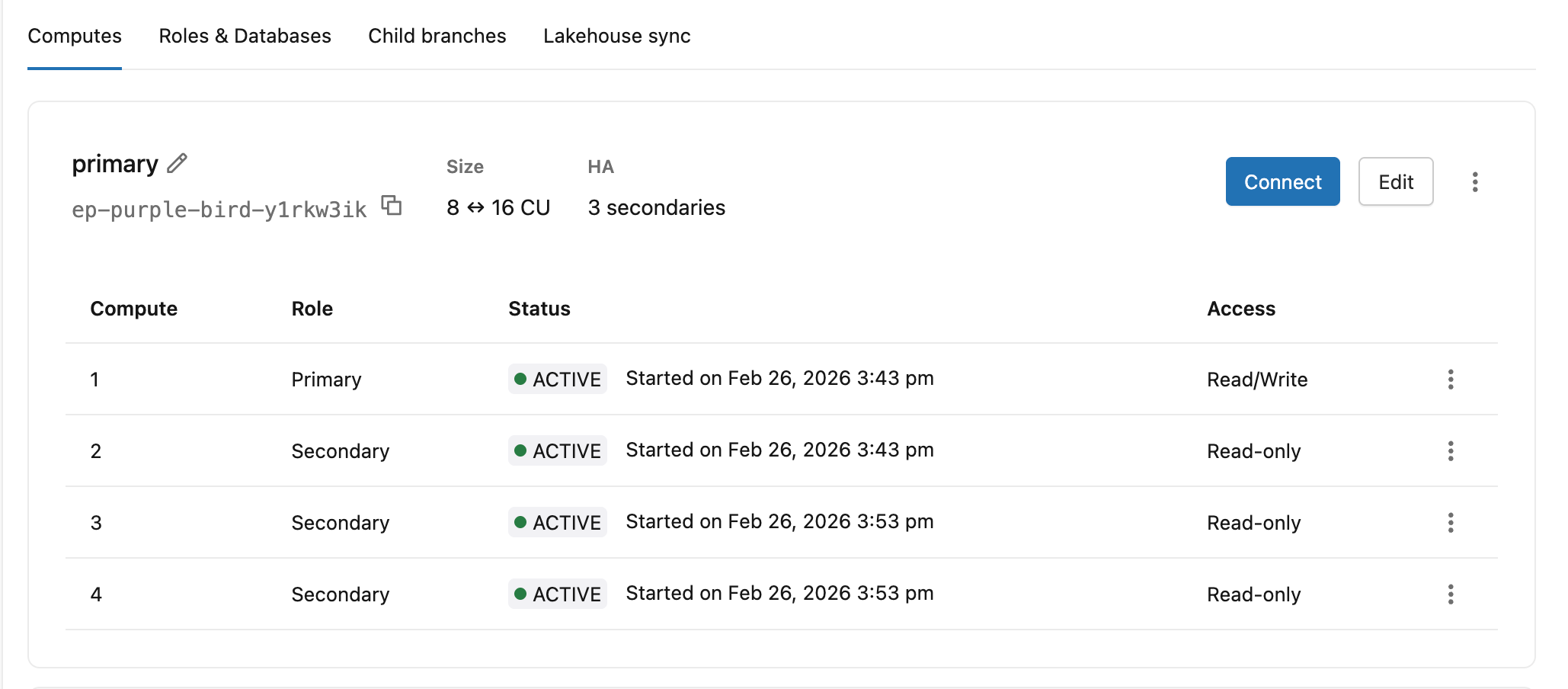
L’onglet Calculs affiche en un clin d’œil le rôle de chaque instance de calcul (principal ou secondaire), l’état et le niveau d’accès .
Distribution AZ
Lakebase distribue les instances de calcul primaire et secondaire entre les zones de disponibilité, ce qui réduit le risque d’une défaillance AZ unique affecte à la fois les instances de calcul primaire et secondaire.
Mise à l’échelle automatique dans un contexte de haute disponibilité
Toutes les instances de calcul d’une configuration à haute disponibilité partagent la même plage de mise à l’échelle automatique. La répartition maximale entre votre cu minimum et la cu maximale est de 8 CU, la même limite que les instances de calcul autonomes.
Les instances de calcul secondaires sont toujours mises à l’échelle vers au moins la même taille d'UC que le serveur principal, ce qui garantit que la capacité de votre base de données reste constante après un basculement.
La scalabilité à zéro n’est pas disponible pour les instances de calcul dans une configuration à haute disponibilité. Vous pouvez suspendre manuellement toutes les instances de calcul, mais votre point de terminaison n’est pas disponible en pause.
Instances de calcul secondaires vs réplicas en lecture autonomes
Les instances de calcul secondaires et les réplicas de lecture autonomes sont des fonctionnalités différentes qui peuvent coexister au sein de la même instance.
| Instances de calcul secondaires | Réplicas de lecture autonomes | |
|---|---|---|
| Objectif | Basculement + déchargement de lecture facultatif | Déchargement de lecture uniquement |
| Ajouté via | Configuration de la haute disponibilité | Ajouter un réplica en lecture |
| Participe au basculement | Oui | Non |
| Chaîne de connexion |
-ro sur le point de terminaison principal |
Propre point de terminaison distinct |
| Dimensionnement | Partagé avec le serveur principal (au niveau du point de terminaison) | Dimensionnée indépendamment |
Lorsque vous avez besoin d’une haute disponibilité et d’une capacité de lecture supplémentaire au-delà de ce que fournissent vos instances de calcul secondaires, vous pouvez combiner les deux fonctionnalités sur la même branche. Consultez réplicas en lecture.
Comportement du basculement
Basculement automatique
Lakebase surveille en permanence l’intégrité du calcul principal. Si le serveur principal devient indisponible, le basculement est déclenché automatiquement.
Le basculement conserve toutes les transactions validées.
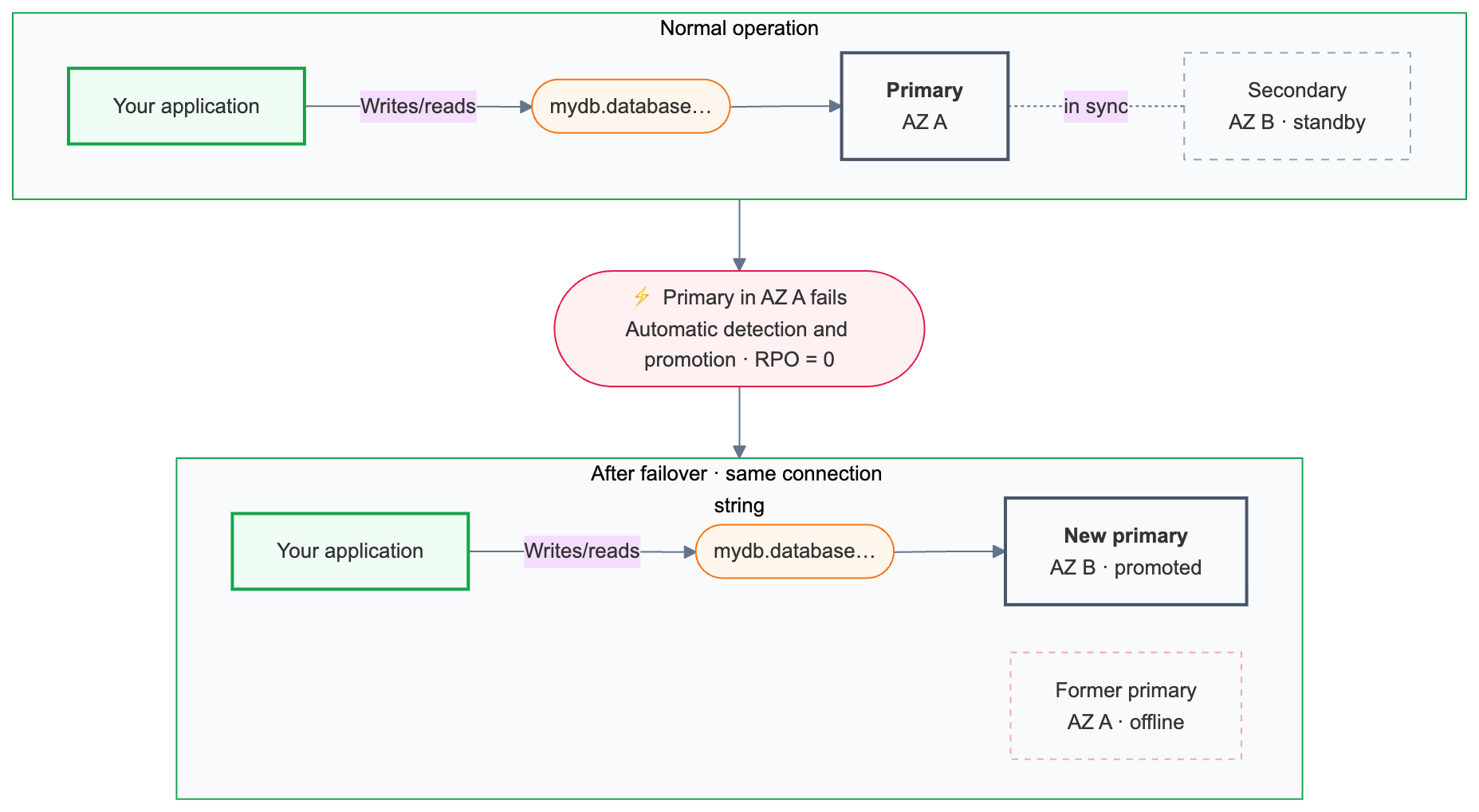
Après le basculement, la chaîne de connexion principale ({endpoint-id}.database.{region}.databricks.com) est automatiquement acheminée vers l’instance de calcul nouvellement promue. Les applications n’ont pas besoin de modifier leur configuration de connexion, mais les connexions existantes sont arrêtées pendant le basculement et doivent se reconnecter. Les applications avec une logique de nouvelle tentative gèrent cette opération automatiquement.
Basculement avec accès en lecture seule activé
Lorsque l’autorisation d’accès aux instances de calcul en lecture seule est activée et qu’un basculement se produit, le secondaire promu devient le nouveau serveur principal et cesse de traiter les lectures. Si vous avez deux ou plusieurs secondaires lisibles, le trafic en lecture sur la chaîne de connexion -ro continue à une capacité réduite jusqu’à ce qu’une instance de remplacement soit approvisionnée. Si vous n’en avez qu’une seule, les lectures sont entièrement interrompues jusqu’à ce que le remplacement soit prêt.
Chaînes de connexion
La boîte de dialogue Se connecter affiche les deux chaînes de connexion avec leur état de calcul actuel :
| Option de calcul dans le dialogue de connexion | Chaîne de connexion | Utilisé pour |
|---|---|---|
Primary (name) ● Active |
{endpoint-id}.database.{region}.databricks.com |
Toutes les écritures ; les lectures qui doivent atteindre le primaire actuel |
Secondary (name) ● Active RO |
{endpoint-id}-ro.database.{region}.databricks.com |
Déchargement en lecture vers des instances de calcul secondaires (disponible uniquement lorsque l’autorisation d’accès aux instances de calcul en lecture seule est activée) |
La chaîne de connexion principale est toujours acheminée vers le serveur principal actuel, même après un basculement.
Chaque instance de calcul a également sa propre chaîne de connexion directe, accessible à partir de l’onglet Calculs via le menu Actions (⋮) sur chaque ligne. Les connexions directes sont destinées à la résolution des problèmes d’instances de calcul individuelles, et non pour une utilisation de l’application. Les chaînes de connexion directes sont spécifiques à chaque unité de calcul et peuvent changer lorsque des instances secondaires sont ajoutées, supprimées ou promues.
Limites de haute disponibilité
| Limite | Valeur |
|---|---|
| Instances de calcul | 2, 3 ou 4 (1 instance de calcul primaire + 1 à 3 instances de calcul secondaires) |
| Plage de mise à l’échelle automatique (max − min) | ≤ 8 CU entre la valeur minimale et maximale |
| Mettre à l’échelle vers zéro | Non disponible pour les instances de calcul dans une configuration à haute disponibilité |
Bonnes pratiques
En suivant ces pratiques, votre application reste résiliente et disponible pendant les événements de basculement.
| Pratique | Détails |
|---|---|
| Implémenter la logique de nouvelle tentative de connexion | Les connexions actives sont arrêtées pendant le basculement. Les connexions au serveur principal défaillant peuvent se bloquer jusqu'à expiration du délai d'attente. Configurez un TCP keepalive ou définissez un délai d'attente de connexion dans votre pilote pour détecter rapidement une défaillance. Les connexions vers le secondaire en cours de promotion sont activement terminées, renvoyant immédiatement une erreur. Les applications avec une logique de nouvelle tentative se reconnectent automatiquement en quelques secondes. |
| Configurer le nombre secondaire pour votre cas d’usage | Chaque instance de calcul secondaire représente le matériel pré-alloué réservé au basculement. La réduction de votre nombre secondaire signifie moins de capacité de basculement et moins de zones de disponibilité couvertes. Une instance de calcul secondaire fournit une couverture de basculement. Si vous activez des fichiers secondaires lisibles, configurez deux ou plusieurs. Avec une seule, les lectures sont entièrement interrompues pendant un basculement jusqu’à ce qu’un remplacement soit provisionné. |
| Éviter la surcharge des instances de calcul secondaires | Le service peut redémarrer une instance de calcul secondaire surchargée ou en retard. Surveillez la charge des requêtes et les nombres de connexions, et augmentez la taille de la CU si vous observez une utilisation élevée soutenue. |
Étapes suivantes
- Gérer la haute disponibilité pour activer et configurer la haute disponibilité
- Mise à l’échelle automatique pour plus d’informations sur le dimensionnement des CU et les plages de mise à l’échelle automatique
- Chaînes de connexion pour référence complète de chaîne de connexion