Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
La mise à l’échelle automatique Lakebase prend en charge trois modèles principaux : servir les données lakehouse dans Postgres, exécuter un back-end d’application et alimenter les agents IA et ML. Chaque modèle utilise Postgres en même temps que le catalogue Unity pour donner à votre application une base de données à faible latence qui reste synchronisée avec le lakehouse.
Diffusez les données du lakehouse
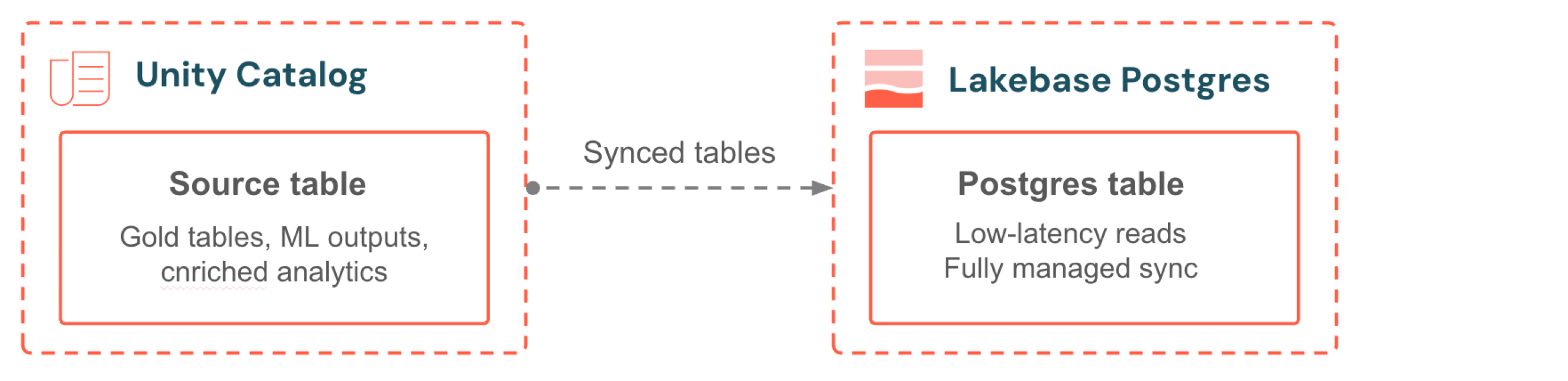
Les tables synchronisées apportent des données Unity Catalog dans votre base de données Lakebase pour les lectures transactionnelles à faible latence. Choisissez une table source, choisissez un mode de synchronisation et le pipeline est entièrement géré. Aucun script de synchronisation, aucune orchestration externe, aucun travail à surveiller. Le mode continu maintient les données à quelques secondes seulement de la source. Le mode déclenché offre un équilibre entre la fraîcheur des données et le coût grâce à des mises à jour incrémentielles planifiées. Votre application sert toujours les dernières analyses en même temps que ses propres données opérationnelles.
| Premières étapes | Parcours d’apprentissage |
|---|---|
|
Back-end d’application
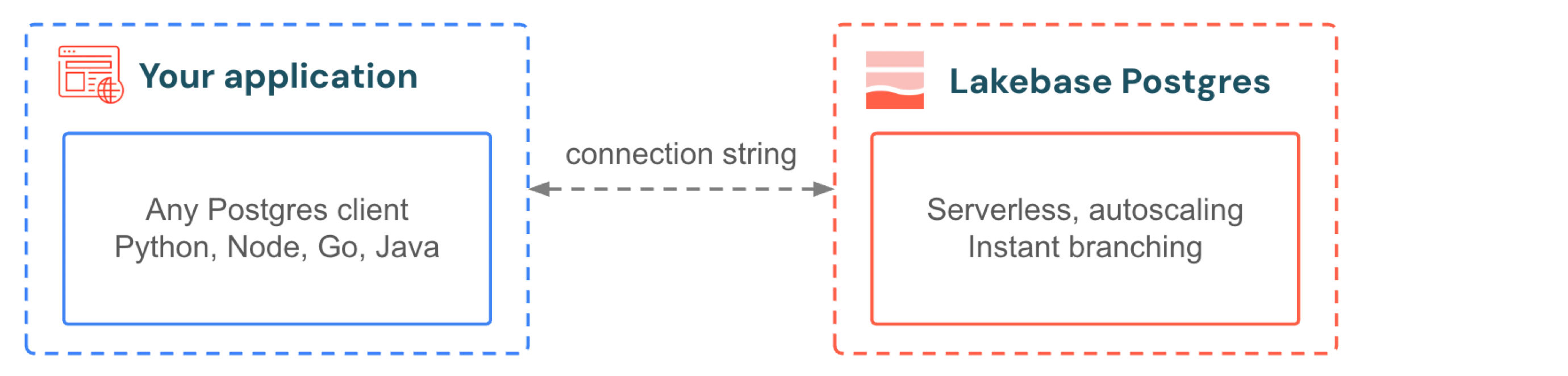
Votre application se connecte à Lakebase de la même façon qu’elle se connecte à n’importe quelle base de données Postgres. Utilisez les pilotes et les frameworks que vous connaissez déjà. Lorsque votre application obtient un pic de trafic, la mise à l’échelle automatique ajoute le calcul sans supprimer les connexions. Lorsque le trafic s’arrête, la mise à l’échelle à zéro suspend la base de données et se réactive en quelques centaines de millisecondes lors de la requête suivante. Vous ne provisionnez pas pour les pics et vous ne payez pas pour l’inactivité. Pour le développement, le branchement donne à chaque développeur une copie isolée de la base de données de production sans amorçage de données, aucune duplication de stockage et aucune attente.
| Premières étapes | Parcours d’apprentissage |
|---|---|
|
|
Agents d’IA et apprentissage automatique
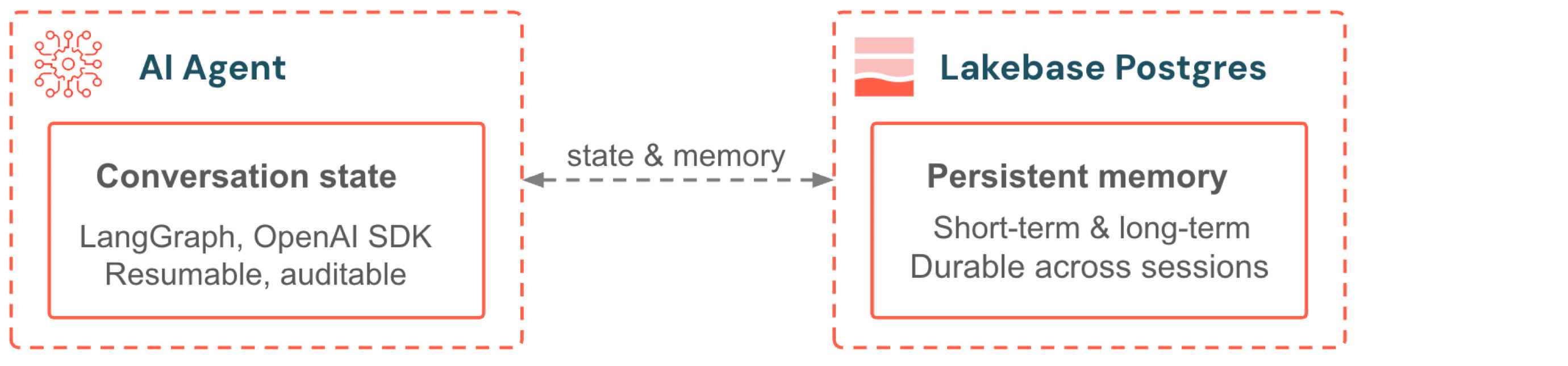
Lakebase sert de backend pour la mémoire des agents IA et le service de variables en temps réel. Les agents créés avec LangGraph ou le SDK OpenAI Agents stockent l’état des conversations et la mémoire à long terme dans Postgres. Les modèles déployés avec Mosaic AI accèdent aux données de caractéristiques via des Feature Stores en ligne alimentés par le dimensionnement automatique de Lakebase. Les deux bénéficient de la mise à l’échelle automatique, de la mise à l’échelle jusqu’à zéro et de la gouvernance d’Unity Catalog.
| Premières étapes | Parcours d’apprentissage |
|---|---|
|
|