Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Le Règlement général sur la protection des données (RGPD) et la California Consumer Privacy Act (CCPA) sont des réglementations en matière de confidentialité et de sécurité des données qui obligent les entreprises à supprimer définitivement et complètement toutes les informations d’identification personnelle (PII) collectées sur un client à leur demande explicite. Également appelée « droit d’oubli » (RTBF) ou « droit à l’effacement des données », les demandes de suppression doivent être exécutées pendant une période spécifiée (par exemple, dans un mois calendrier).
Cet article vous guide tout au long de l’implémentation de RTBF sur les données stockées dans Databricks. L’exemple inclus dans cet article modélise des jeux de données pour une entreprise de commerce électronique et vous montre comment supprimer des données dans des tables sources et propager ces modifications aux tables en aval.
Blueprint pour l’implémentation du « droit d’être oublié »
Le diagramme suivant montre comment implémenter le « droit d’être oublié ».
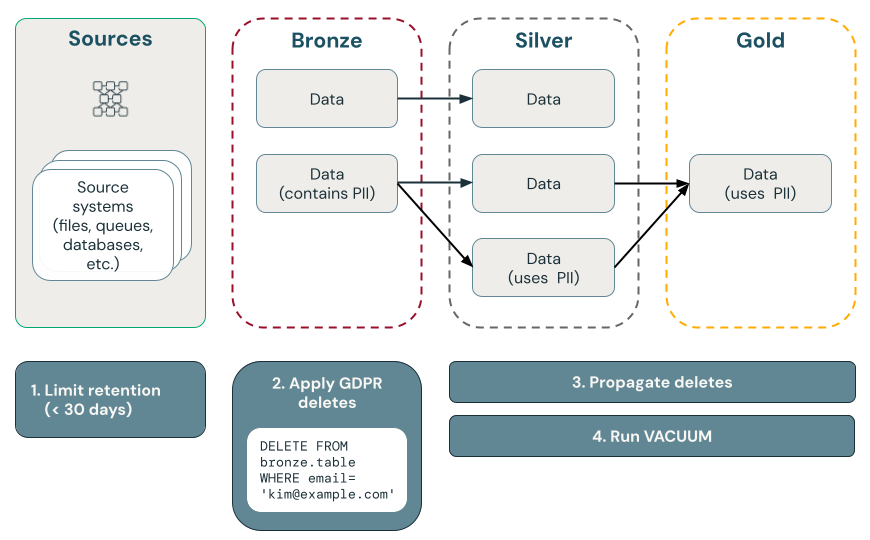
Suppressions de points avec Delta Lake
Delta Lake accélère les suppressions de points dans les grands lacs de données avec des transactions ACID, ce qui vous permet de localiser et de supprimer des informations personnelles identifiables (PII) en réponse aux demandes RGPD ou CCPA des consommateurs.
Delta Lake conserve l’historique d’une table et la rend disponible pour des requêtes et des restaurations jusqu’à une date et heure. La fonction VACUUM supprime les fichiers de données qui ne sont plus référencés par une table Delta et sont plus anciens qu’un seuil de rétention spécifié, supprimant définitivement les données. Pour en savoir plus sur les valeurs par défaut et les recommandations, consultez Utiliser l’historique des tables Delta Lake.
Vérifier que les données sont supprimées lors de l’utilisation de vecteurs de suppression
Pour les tables avec des vecteurs de suppression activés, après la suppression d’enregistrements, vous devez également exécuter REORG TABLE ... APPLY (PURGE) pour supprimer définitivement les enregistrements sous-jacents. Cela inclut les tables Delta Lake, les vues matérialisées et les tables de flux de données. Consultez Appliquer des modifications aux fichiers de données Parquet.
Supprimer des données dans des sources en amont
RGPD et CCPA s’appliquent à toutes les données, y compris les données dans des sources en dehors de Delta Lake, telles que Kafka, les fichiers et les bases de données. En plus de supprimer des données dans Databricks, vous devez également vous rappeler de supprimer des données dans des sources en amont, telles que les files d’attente et le stockage cloud.
La suppression complète est préférable à l’obfuscation
Vous devez choisir entre supprimer des données et l’obfusquer. L’obfuscation peut être implémentée à l’aide du pseudonyme, du masquage des données, etc. Toutefois, l’option la plus sûre est l’effacement complet, car, dans la pratique, l’élimination du risque de réidentification nécessite souvent une suppression complète des données d’identification personnelle.
Supprimer des données en couche bronze, puis propager les suppressions aux couches argent et or
Nous vous recommandons de commencer la conformité RGPD et CCPA en supprimant d’abord les données dans la couche bronze, pilotée par un travail planifié qui interroge une table de contrôle contenant des demandes de suppression. Une fois les données supprimées de la couche bronze, les modifications peuvent être propagées aux couches argent et or.
Gérer régulièrement des tables pour supprimer les données des fichiers historiques
Par défaut, Delta Lake conserve l’historique des tables, y compris les enregistrements supprimés, pendant 30 jours, et le rend disponible pour les déplacements temporels et les restaurations. Mais même si les versions précédentes des données sont supprimées, les données sont toujours conservées dans le stockage cloud. Par conséquent, vous devez régulièrement conserver des tables et des vues pour supprimer les versions précédentes des données. La méthode recommandée est l’optimisation prédictive pour les tables gérées par le catalogue Unity, qui gère intelligemment les tables de streaming et les vues matérialisées.
- Pour les tables gérées par l’optimisation prédictive, les pipelines déclaratifs Lakeflow gèrent intelligemment les tables de streaming et les vues matérialisées, en fonction des modèles d’utilisation.
- Pour les tables sans optimisation prédictive activée, les pipelines déclaratifs Lakeflow effectuent automatiquement des tâches de maintenance dans les 24 heures qui suivent la mise à jour des tables de streaming et des vues matérialisées.
Si vous n’utilisez pas d’optimisation prédictive ou de pipelines déclaratifs Lakeflow, vous devez exécuter une VACUUM commande sur des tables Delta pour supprimer définitivement les versions précédentes des données. Par défaut, cela réduit les fonctionnalités de voyage à 7 jours, qui est un paramètre configurable et supprime également les versions historiques des données en question du stockage cloud.
Supprimer des données d’identification personnelle de la couche bronze
En fonction de la conception de votre lakehouse, vous pouvez peut-être rompre le lien entre les données utilisateurs PII et non-PII. Par exemple, si vous utilisez une clé non naturelle telle que user_id au lieu d’une clé naturelle comme l’e-mail, vous pouvez supprimer des données d’identification personnelle, ce qui laisse des données non-PII en place.
Le reste de cet article traite du RTBF en supprimant intégralement les enregistrements utilisateur de toutes les tables bronze. Vous pouvez supprimer des données en exécutant une commande DELETE, comme indiqué dans le code suivant :
spark.sql("DELETE FROM bronze.users WHERE user_id = 5")
Lorsque vous supprimez un grand nombre d’enregistrements ensemble à la fois, nous vous recommandons d’utiliser la commande MERGE. Le code ci-dessous suppose que vous disposez d’une table de contrôle appelée gdpr_control_table qui contient une user_id colonne. Vous insérez un enregistrement dans cette table pour chaque utilisateur qui a demandé le « droit d’être oublié » dans cette table.
La commande MERGE spécifie la condition pour les lignes correspondantes. Dans cet exemple, il associe les enregistrements de target_table avec des enregistrements dans gdpr_control_table sur la base du user_id. S’il existe une correspondance (par exemple, une user_id dans la target_table et la gdpr_control_table), la ligne de l'target_table est supprimée. Une fois cette MERGE commande réussie, mettez à jour la table de contrôle pour vérifier que la demande a été traitée.
spark.sql("""
MERGE INTO target
USING (
SELECT user_id
FROM gdpr_control_table
) AS source
ON target.user_id = source.user_id
WHEN MATCHED THEN DELETE
""")
Propager les changements du bronze aux couches d’argent et d’or
Une fois les données supprimées dans la couche bronze, vous devez propager les modifications apportées aux tables des couches argent et or.
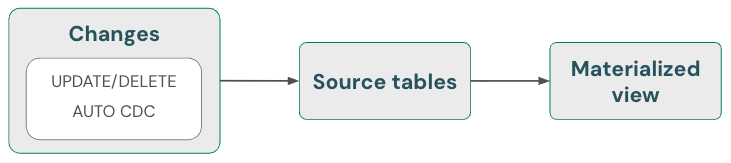
Vues matérialisées : gérer automatiquement les suppressions
Les vues matérialisées gèrent automatiquement les suppressions dans les sources. Par conséquent, vous n’avez rien de spécial à faire pour vous assurer qu’une vue matérialisée ne contient pas de données supprimées d’une source. Vous devez actualiser une vue matérialisée et exécuter la maintenance pour vous assurer que les suppressions sont entièrement traitées.
Une vue matérialisée retourne toujours le résultat correct, car il utilise un calcul incrémentiel s’il est moins cher que la recomputation complète, mais jamais au coût de la correction. En d’autres termes, la suppression de données d’une source peut entraîner un recalcul complet d’une vue matérialisée.
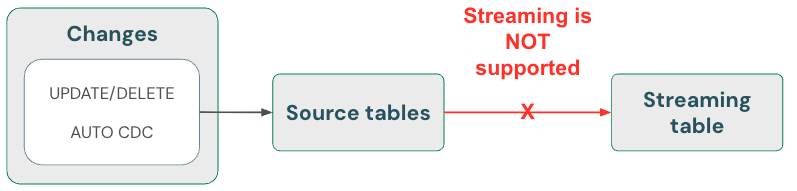
Tables de diffusion en continu : supprimer des données et lire la source de diffusion en continu à l’aide de skipChangeCommits
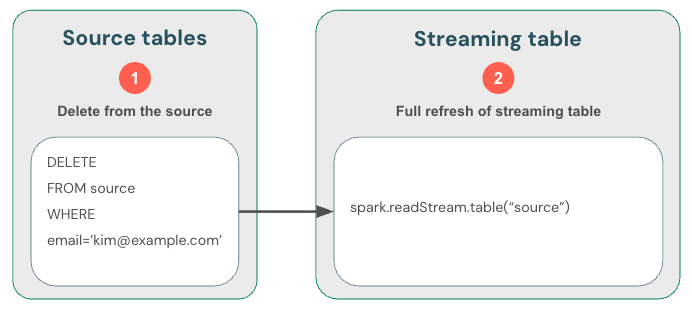
Les tables de diffusion en continu ne peuvent traiter que les données d’ajout uniquement. Autrement dit, les tables de streaming s'attendent à ce que seules les nouvelles lignes de données s'affichent dans la source de streaming. Toute autre opération, telle que la mise à jour ou la suppression d’un enregistrement d’une table source utilisée pour la diffusion en continu, n’est pas prise en charge et interrompt le flux.
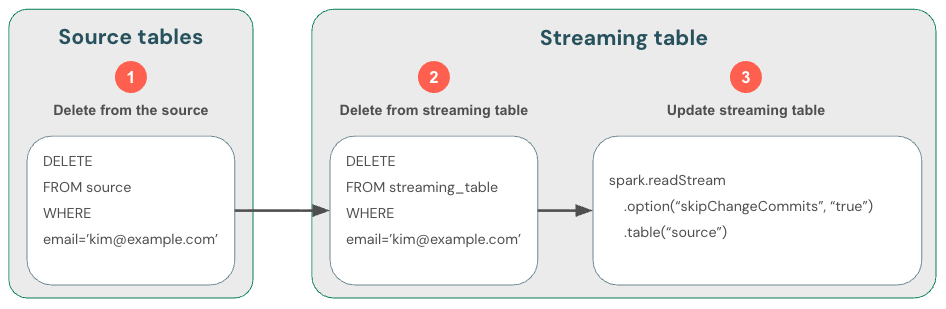
Étant donné que la diffusion en continu gère les nouvelles données uniquement, vous devez gérer vous-même les modifications apportées aux données. La méthode recommandée consiste à : (1) supprimer les données de la source de streaming, (2) supprimer les données de la table de streaming, puis (3) mettre à jour la lecture en continu pour utiliser skipChangeCommits. Cet indicateur indique à Databricks que la table de diffusion en continu doit ignorer tout autre élément que les insertions, telles que les mises à jour ou les suppressions.
Vous pouvez également supprimer (1) les données de la source, (2) la supprimer de la table de diffusion en continu, puis (3) actualiser complètement la table de diffusion en continu. Lorsque vous effectuez une actualisation complète d'une table de flux en continu, elle efface l'état de streaming de la table et traite toutes les données à nouveau. Toute source de données en amont qui dépasse sa période de rétention (par exemple, une rubrique Kafka qui vieillit les données après 7 jours) ne sera pas traitée à nouveau, ce qui peut entraîner une perte de données. Nous vous recommandons cette option pour les tables en streaming uniquement dans le scénario où les données historiques sont disponibles et que leur traitement de nouveau ne sera pas coûteux.
Tables delta : Gérer les suppressions à l’aide de readChangeFeed
Les tables Delta classiques n'ont aucune gestion spéciale des suppressions en amont. Au lieu de cela, vous devez écrire votre propre code pour leur propager les suppressions (par exemple, spark.readStream.option("readChangeFeed", true).table("source_table")).
Exemple : Conformité RGPD et CCPA pour une entreprise de commerce électronique
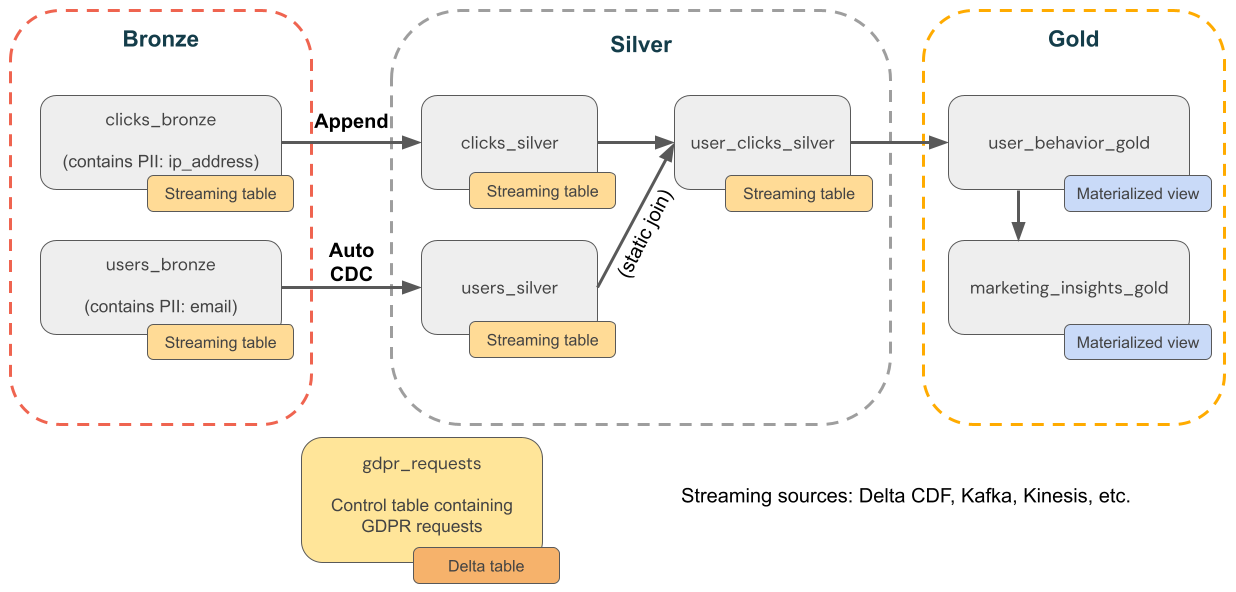
Le diagramme suivant montre une architecture de médaillon pour une entreprise de commerce électronique où la conformité RGPD &CCPA doit être implémentée. Même si les données d’un utilisateur sont supprimées, vous pouvez compter leurs activités dans les agrégations en aval.
-
couche bronze
-
users- Dimensions utilisateur. Contient des informations d’identification personnelles (par exemple, une adresse e-mail). -
clickstream- Cliquez sur des événements. Contient des informations d’identification personnelles (par exemple, une adresse IP). -
gdpr_requests- Table de contrôle contenant des ID d’utilisateur soumis à « droit d’être oublié ».
-
-
couche Argent
-
clicks_hourly- Nombre total de clics par heure. Si vous supprimez un utilisateur, vous souhaitez toujours compter leurs clics. -
clicks_by_user- Nombre total de clics par utilisateur. Si vous supprimez un utilisateur, vous ne souhaitez pas compter leurs clics.
-
-
couche Or
-
revenue_by_user- Total des dépenses par chaque utilisateur.
-
Étape 1 : Remplir des tables avec des exemples de données
Le code suivant crée ces deux tables :
-
source_userscontient des données dimensionnelles sur les utilisateurs. Cette table contient une colonne PII appeléeemail. -
source_clickscontient des données d’événement sur les activités effectuées par les utilisateurs. Il contient une colonne PII appeléeip_address.
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, MapType, DateType
catalog = "users"
schema = "name"
# Create table containing sample users
users_schema = StructType([
StructField('user_id', IntegerType(), False),
StructField('username', StringType(), True),
StructField('email', StringType(), True),
StructField('registration_date', StringType(), True),
StructField('user_preferences', MapType(StringType(), StringType()), True)
])
users_data = [
(1, 'alice', 'alice@example.com', '2021-01-01', {'theme': 'dark', 'language': 'en'}),
(2, 'bob', 'bob@example.com', '2021-02-15', {'theme': 'light', 'language': 'fr'}),
(3, 'charlie', 'charlie@example.com', '2021-03-10', {'theme': 'dark', 'language': 'es'}),
(4, 'david', 'david@example.com', '2021-04-20', {'theme': 'light', 'language': 'de'}),
(5, 'eve', 'eve@example.com', '2021-05-25', {'theme': 'dark', 'language': 'it'})
]
users_df = spark.createDataFrame(users_data, schema=users_schema)
users_df.write..mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_users")
# Create table containing clickstream (i.e. user activities)
from pyspark.sql.types import TimestampType
clicks_schema = StructType([
StructField('click_id', IntegerType(), False),
StructField('user_id', IntegerType(), True),
StructField('url_clicked', StringType(), True),
StructField('click_timestamp', StringType(), True),
StructField('device_type', StringType(), True),
StructField('ip_address', StringType(), True)
])
clicks_data = [
(1001, 1, 'https://example.com/home', '2021-06-01T12:00:00', 'mobile', '192.168.1.1'),
(1002, 1, 'https://example.com/about', '2021-06-01T12:05:00', 'desktop', '192.168.1.1'),
(1003, 2, 'https://example.com/contact', '2021-06-02T14:00:00', 'tablet', '192.168.1.2'),
(1004, 3, 'https://example.com/products', '2021-06-03T16:30:00', 'mobile', '192.168.1.3'),
(1005, 4, 'https://example.com/services', '2021-06-04T10:15:00', 'desktop', '192.168.1.4'),
(1006, 5, 'https://example.com/blog', '2021-06-05T09:45:00', 'tablet', '192.168.1.5')
]
clicks_df = spark.createDataFrame(clicks_data, schema=clicks_schema)
clicks_df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_clicks")
Étape 2 : Créer un pipeline qui traite les données d’identification personnelle
Le code suivant crée des couches bronze, argent et or de l’architecture de médaillon illustrée ci-dessus.
import dlt
from pyspark.sql.functions import col, concat_ws, count, countDistinct, avg, when, expr
catalog = "users"
schema = "name"
# ----------------------------
# Bronze Layer - Raw Data Ingestion
# ----------------------------
@dlt.table(
name=f"{catalog}.{schema}.users_bronze",
comment='Raw users data loaded from source'
)
def users_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_users")
)
@dlt.table(
name=f"{catalog}.{schema}.clicks_bronze",
comment='Raw clicks data loaded from source'
)
def clicks_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_clicks")
)
# ----------------------------
# Silver Layer - Data Cleaning and Enrichment
# ----------------------------
@dlt.table(
name=f"{catalog}.{schema}.users_silver",
comment='Cleaned and standardized users data'
)
@dlt.expect_or_drop('valid_email', "email IS NOT NULL")
def users_silver():
return (
spark.readStream
.table(f"{catalog}.{schema}.users_bronze")
.withColumn('registration_date', col('registration_date').cast('timestamp'))
.dropDuplicates(['user_id', 'registration_date'])
.select('user_id', 'username', 'email', 'registration_date', 'user_preferences')
)
@dlt.table(
name=f"{catalog}.{schema}.clicks_silver",
comment='Cleaned and standardized clicks data'
)
@dlt.expect_or_drop('valid_click_timestamp', "click_timestamp IS NOT NULL")
def clicks_silver():
return (
spark.readStream
.table(f"{catalog}.{schema}.clicks_bronze")
.withColumn('click_timestamp', col('click_timestamp').cast('timestamp'))
.withWatermark('click_timestamp', '10 minutes')
.dropDuplicates(['click_id'])
.select('click_id', 'user_id', 'url_clicked', 'click_timestamp', 'device_type', 'ip_address')
)
@dlt.table(
name=f"{catalog}.{schema}.user_clicks_silver",
comment='Joined users and clicks data on user_id'
)
def user_clicks_silver():
# Read users_silver as a static DataFrame
users = spark.read.table(f"{catalog}.{schema}.users_silver")
# Read clicks_silver as a streaming DataFrame
clicks = spark.readStream \
.table('clicks_silver')
# Perform the join
joined_df = clicks.join(users, on='user_id', how='inner')
return joined_df
# ----------------------------
# Gold Layer - Aggregated and Business-Level Data
# ----------------------------
@dlt.table(
name=f"{catalog}.{schema}.user_behavior_gold",
comment='Aggregated user behavior metrics'
)
def user_behavior_gold():
df = spark.read.table(f"{catalog}.{schema}.user_clicks_silver")
return (
df.groupBy('user_id')
.agg(
count('click_id').alias('total_clicks'),
countDistinct('url_clicked').alias('unique_urls')
)
)
@dlt.table(
name=f"{catalog}.{schema}.marketing_insights_gold",
comment='User segments for marketing insights'
)
def marketing_insights_gold():
df = spark.read.table(f"{catalog}.{schema}.user_behavior_gold")
return (
df.withColumn(
'engagement_segment',
when(col('total_clicks') >= 100, 'High Engagement')
.when((col('total_clicks') >= 50) & (col('total_clicks') < 100), 'Medium Engagement')
.otherwise('Low Engagement')
)
)
Étape 3 : Supprimer des données dans des tables sources
Dans cette étape, vous déletez des données dans toutes les tables où des informations d’identification personnelle sont trouvées.
catalog = "users"
schema = "name"
def apply_gdpr_delete(user_id):
tables_with_pii = ["clicks_bronze", "users_bronze", "clicks_silver", "users_silver", "user_clicks_silver"]
for table in tables_with_pii:
print(f"Deleting user_id {user_id} from table {table}")
spark.sql(f"""
DELETE FROM {catalog}.{schema}.{table}
WHERE user_id = {user_id}
""")
Étape 4 : Ajouter skipChangeCommits aux définitions des tables de diffusion en continu affectées
Dans cette étape, vous devez indiquer aux pipelines déclaratifs Lakeflow d’ignorer les lignes sans ajout. Ajoutez l’option skipChangeCommits aux méthodes suivantes. Vous n’avez pas besoin de mettre à jour les définitions des vues matérialisées, car elles gèrent automatiquement les mises à jour et les suppressions :
users_bronzeusers_silverclicks_bronzeclicks_silveruser_clicks_silver
Le code suivant montre comment mettre à jour la users_bronze méthode :
def users_bronze():
return (
spark.readStream.option('skipChangeCommits', 'true').table(f"{catalog}.{schema}.source_users")
)
Lorsque vous réexécutez le pipeline, la mise à jour sera effectuée avec succès.