Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Important
Cette fonctionnalité est disponible en préversion publique.
Les fonctions définies par l’utilisateur dans le catalogue Unity étendent les fonctionnalités SQL et Python dans Azure Databricks. Ils permettent aux fonctions personnalisées d’être définies, utilisées et partagées et régies en toute sécurité dans les environnements informatiques.
Les UDF Python enregistrées en tant que fonctions dans Unity Catalog diffèrent en termes de portée et de prise en charge des UDF PySpark étendues à un bloc-notes ou à SparkSession. Voir Fonctions scalaires définies par l'utilisateur – Python.
Consultez CREATE FUNCTION (SQL et Python) pour obtenir une référence complète du langage SQL.
Spécifications
Pour utiliser les UDF dans le catalogue Unity, vous devez remplir les conditions suivantes :
- Pour utiliser du code Python dans des fonctions définies par l'utilisateur inscrites dans Unity Catalog, vous devez utiliser un entrepôt SQL serverless ou pro ou un cluster exécutant Databricks Runtime 13.3 LTS ou une version ultérieure.
- Si une vue inclut une fonction UDF Python du catalogue Unity, elle échoue sur les entrepôts SQL classiques.
- La prise en charge des instances ARM pour les UDF Scala sur Unity Catalog est disponible dans Databricks Runtime 15.2 et versions ultérieures.
Création de fonctions définies par l’utilisateur dans Unity Catalog
Pour créer une fonction UDF dans le catalogue Unity, les utilisateurs ont besoin de l'autorisation « USAGE » et « CREATE » sur le schéma et de l'autorisation « USAGE » sur le catalogue. Pour plus d’informations, consultez le catalogue Unity.
Pour exécuter une fonction UDF, les utilisateurs ont besoin d’une autorisation EXECUTE sur la fonction UDF. Les utilisateurs ont également besoin d’une autorisation USAGE sur le schéma et le catalogue.
Pour créer et inscrire une fonction UDF dans un schéma de catalogue Unity, le nom de la fonction doit suivre le format catalog.schema.function_name. Vous pouvez également sélectionner le catalogue et le schéma appropriés dans l’Éditeur SQL.
Dans ce cas, votre nom de fonction ne doit pas être préfixé par catalog.schema.

L’exemple suivant inscrit une nouvelle fonction dans le my_schema schéma du my_catalog catalogue :
CREATE OR REPLACE FUNCTION my_catalog.my_schema.calculate_bmi(weight DOUBLE, height DOUBLE)
RETURNS DOUBLE
LANGUAGE SQL
RETURN
SELECT weight / (height * height);
Les fonctions UDF Python pour Unity Catalog utilisent des instructions décalées par des symboles de double dollar ($$). Vous devez spécifier un mappage de type de données. L’exemple suivant enregistre une fonction UDF qui calcule l’index de masse corporelle :
CREATE OR REPLACE FUNCTION my_catalog.my_schema.calculate_bmi(weight_kg DOUBLE, height_m DOUBLE)
RETURNS DOUBLE
LANGUAGE PYTHON
AS $$
return weight_kg / (height_m ** 2)
$$;
Vous pouvez maintenant utiliser cette fonction de catalogue Unity dans vos requêtes SQL ou code PySpark :
SELECT person_id, my_catalog.my_schema.calculate_bmi(weight_kg, height_m) AS bmi
FROM person_data;
Consultez les exemples de filtre de lignes et les exemples de masque de colonne pour obtenir d’autres exemples UDF.
Étendre les fonctions UDF à l’aide de dépendances personnalisées
Important
Cette fonctionnalité est disponible en préversion publique.
Étendez les fonctionnalités des UDF Python du Unity Catalog au-delà de l'environnement Databricks Runtime en définissant des dépendances personnalisées pour les bibliothèques externes.
Installez les dépendances à partir des sources suivantes :
- PyPI Packages
-
Fichiers stockés dans des volumes de catalogue Unity L’utilisateur appelant la fonction UDF doit disposer
READ VOLUMEd’autorisations sur le volume source. - Fichiers disponibles dans les URL publiques Les règles de sécurité réseau de votre espace de travail doivent autoriser l’accès aux URL publiques.
Remarque
Pour configurer des règles de sécurité réseau pour autoriser l’accès aux URL publiques à partir d’un entrepôt SQL serverless, consultez Valider avec Databricks SQL.
- Les entrepôts SQL serverless nécessitent que la fonctionnalité d’aperçu public Activer la mise en réseau pour les charges de travail isolées dans les Serverless SQL Warehouses soit activée dans la Page des Aperçus de votre espace de travail pour permettre l'accès à Internet pour les dépendances personnalisées.
Les dépendances personnalisées pour les fonctions UDF du catalogue Unity sont prises en charge sur les types de calcul suivants :
- Notebooks et travaux serverless
- Calcul à usage unique à l’aide de Databricks Runtime version 16.2 et ultérieure
- Entrepôt SQL pro ou serverless
Utilisez la ENVIRONMENT section de la définition UDF pour spécifier les dépendances :
CREATE OR REPLACE FUNCTION my_catalog.my_schema.mixed_process(data STRING)
RETURNS STRING
LANGUAGE PYTHON
ENVIRONMENT (
dependencies = '["simplejson==3.19.3", "/Volumes/my_catalog/my_schema/my_volume/packages/custom_package-1.0.0.whl", "https://my-bucket.s3.amazonaws.com/packages/special_package-2.0.0.whl?Expires=2043167927&Signature=abcd"]',
environment_version = 'None'
)
AS $$
import simplejson as json
import custom_package
return json.dumps(custom_package.process(data))
$$;
La ENVIRONMENT section contient les champs suivants :
| Champ | Descriptif | Catégorie | Exemple d’utilisation |
|---|---|---|---|
dependencies |
Liste des dépendances séparées par des virgules à installer. Chaque entrée est une chaîne qui est conforme au format de fichier de configuration requise pip. | STRING |
dependencies = '["simplejson==3.19.3", "/Volumes/catalog/schema/volume/packages/my_package-1.0.0.whl"]'dependencies = '["https://my-bucket.s3.amazonaws.com/packages/my_package-2.0.0.whl?Expires=2043167927&Signature=abcd"]' |
environment_version |
Spécifie la version de l’environnement serverless dans laquelle exécuter la fonction UDF. Actuellement, seule la valeur None est prise en charge. |
STRING |
environment_version = 'None' |
Utiliser les fonctions définies par l’utilisateur (UDF) du catalogue Unity dans PySpark
from pyspark.sql.functions import expr
result = df.withColumn("bmi", expr("my_catalog.my_schema.calculate_bmi(weight_kg, height_m)"))
display(result)
Mettre à niveau une fonction UDF délimitée à une session
Remarque
La syntaxe et la sémantique des UDF Python dans Unity Catalog diffèrent de celles des UDF Python enregistrées dans SparkSession. Consultez les fonctions scalaires définies par l’utilisateur - Python.
Compte tenu de la fonction UDF suivante basée sur une session dans un notebook Azure Databricks :
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
@udf(StringType())
def greet(name):
return f"Hello, {name}!"
# Using the session-based UDF
result = df.withColumn("greeting", greet("name"))
result.show()
Pour l’inscrire en tant que fonction de catalogue Unity, utilisez une instruction SQL CREATE FUNCTION , comme dans l’exemple suivant :
CREATE OR REPLACE FUNCTION my_catalog.my_schema.greet(name STRING)
RETURNS STRING
LANGUAGE PYTHON
AS $$
return f"Hello, {name}!"
$$
Partager les fonctions définies par l’utilisateur dans Unity Catalog
Les autorisations pour les fonctions définies par l'utilisateur sont gérées en fonction des contrôles d'accès appliqués aux catalogues, aux schémas, ou à la base de données où l’UDF est inscrite. Pour plus d’informations , consultez Gérer les privilèges dans le catalogue Unity .
Utilisez Azure Databricks SQL ou l’interface utilisateur de l’espace de travail Azure Databricks pour accorder des autorisations à un utilisateur ou un groupe (recommandé).
Autorisations dans l’interface utilisateur de l’espace de travail
- Trouvez le catalogue et le schéma où votre UDF est stocké, puis sélectionnez l'UDF.
- Recherchez une option Autorisations dans les paramètres UDF. Ajoutez des utilisateurs ou des groupes et spécifiez le type d’accès dont ils doivent disposer, tels que EXECUTE ou MANAGE.
autorisations 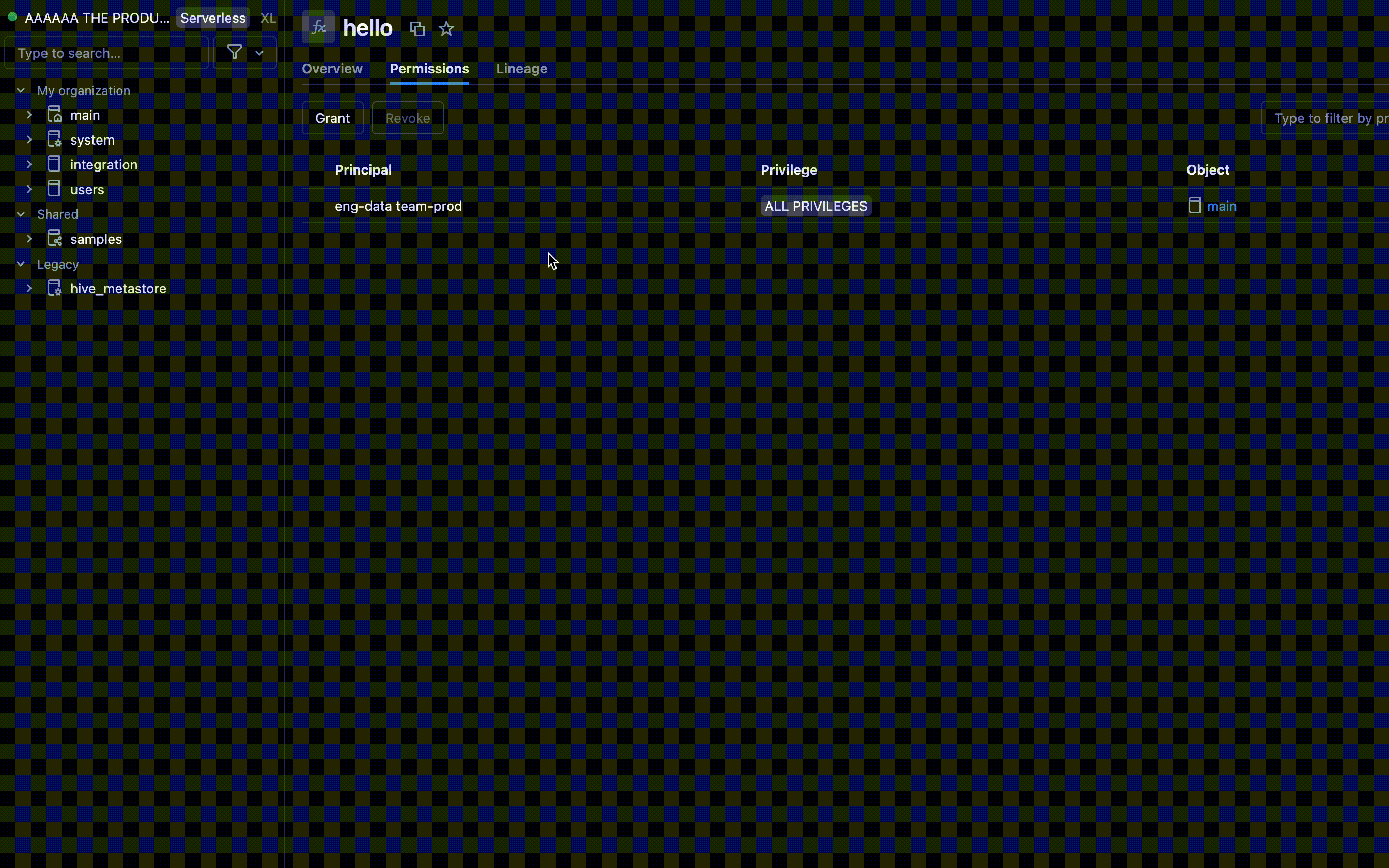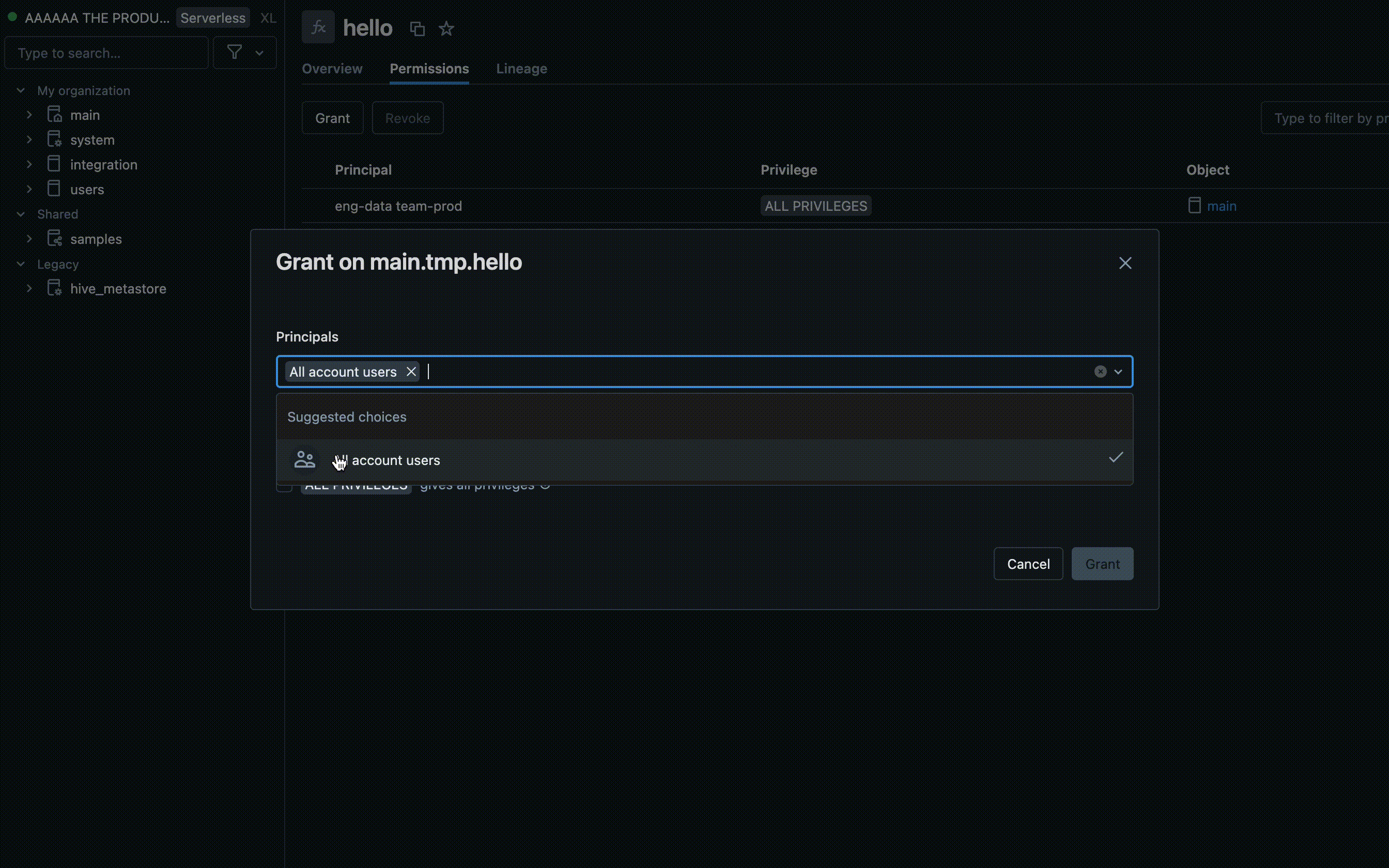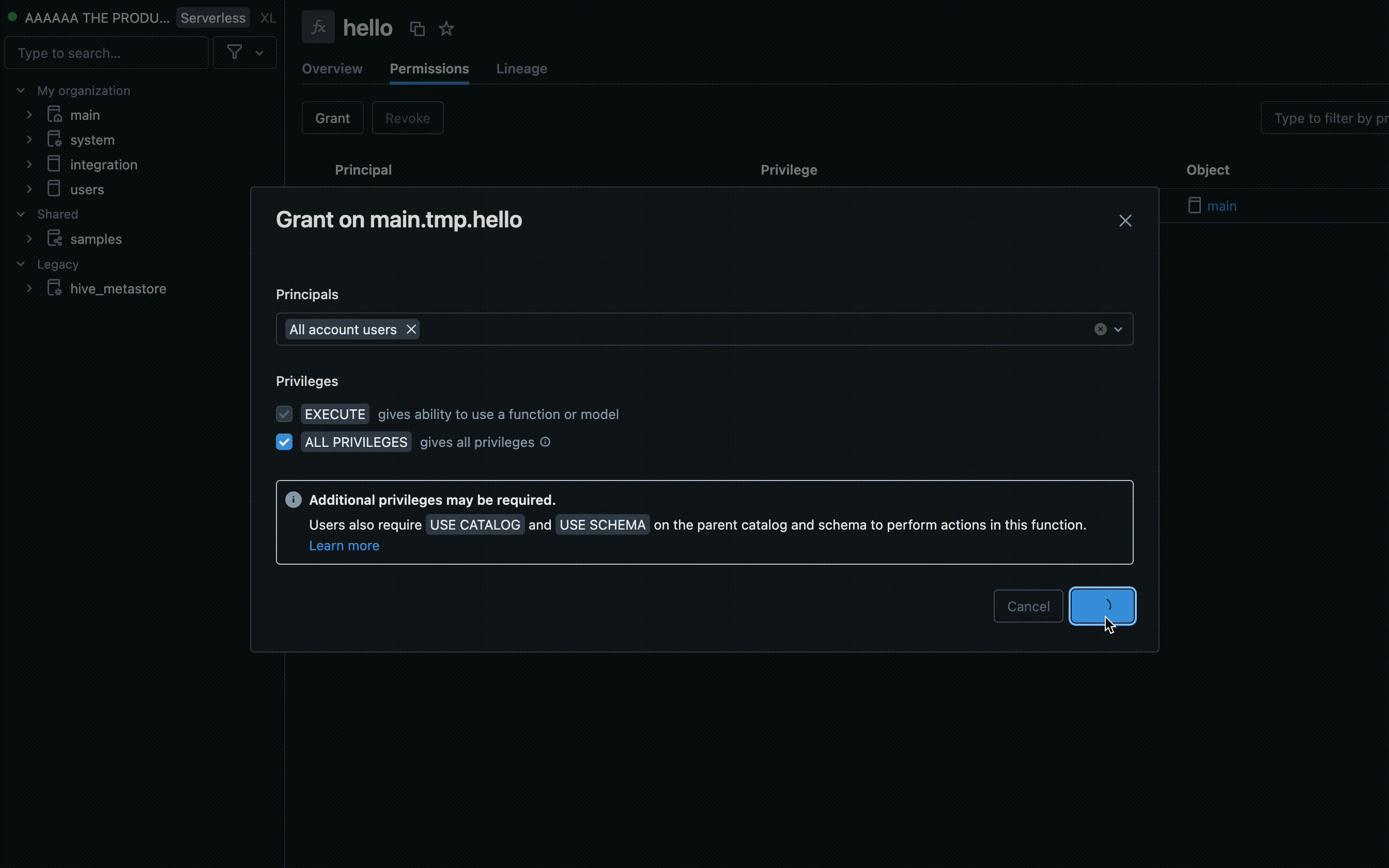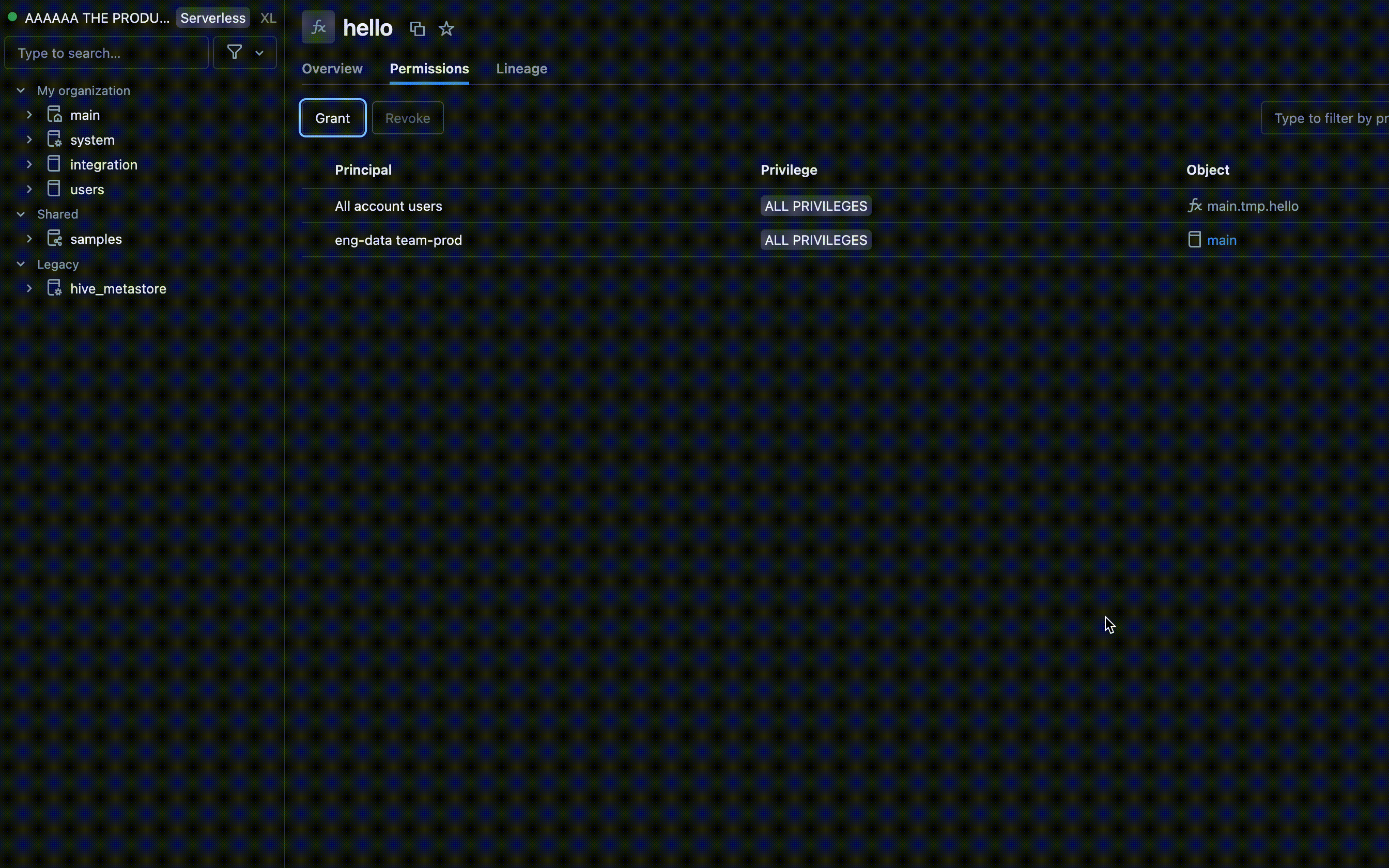
Autorisations à l’aide d’Azure Databricks SQL
L’exemple suivant accorde à un utilisateur l’autorisation EXECUTE sur une fonction :
GRANT EXECUTE ON FUNCTION my_catalog.my_schema.calculate_bmi TO `user@example.com`;
Pour supprimer des autorisations, utilisez la REVOKE commande comme dans l’exemple suivant :
REVOKE EXECUTE ON FUNCTION my_catalog.my_schema.calculate_bmi FROM `user@example.com`;
Isolation de l’environnement
Remarque
Les environnements d’isolation partagé nécessitent Databricks Runtime 18.0 et versions ultérieures. Dans les versions antérieures, toutes les fonctions définies par l’utilisateur Python du catalogue Unity s’exécutent en mode d’isolation strict.
Les UDF Python du catalogue Unity avec le même propriétaire et la même session peuvent partager un environnement d’isolation de manière par défaut. Cela améliore les performances et réduit l’utilisation de la mémoire en réduisant le nombre d’environnements distincts qui doivent être lancés.
Isolation stricte
Pour garantir qu’une fonction UDF s’exécute toujours dans son propre environnement entièrement isolé, ajoutez la STRICT ISOLATION clause caractéristique.
La plupart des fonctions définies par l’utilisateur n’ont pas besoin d’isolation stricte. Les UDFs de traitement de données standard bénéficient de l’environnement d’isolation partagé par défaut et s’exécutent plus rapidement avec une consommation de mémoire inférieure.
Ajoutez la clause caractéristique suivante STRICT ISOLATION aux fonctions définies par l’utilisateur qui :
- Exécutez l’entrée en tant que code à l’aide de
eval(),exec()ou de fonctions similaires. - Écrivez des fichiers dans le système de fichiers local.
- Modifiez les variables globales ou l’état système.
- Accéder ou modifier des variables d’environnement.
Le code suivant montre un exemple d’UDF qui doit être exécuté à l’aide de STRICT ISOLATION. Cette fonction UDF exécute du code Python arbitraire, ce qui peut modifier l’état du système, accéder aux variables d’environnement ou écrire dans le système de fichiers local. L’utilisation de la clause STRICT ISOLATION permet d’empêcher les interférences ou les fuites de données entre les fonctions définies par l’utilisateur.
CREATE OR REPLACE TEMPORARY FUNCTION run_python_snippet(python_code STRING)
RETURNS STRING
LANGUAGE PYTHON
STRICT ISOLATION
AS $$
import sys
from io import StringIO
# Capture standard output and error streams
captured_output = StringIO()
captured_errors = StringIO()
sys.stdout = captured_output
sys.stderr = captured_errors
try:
# Execute the user-provided Python code in an empty namespace
exec(python_code, {})
except SyntaxError:
# Retry with escaped characters decoded (for cases like "\n")
def decode_code(raw_code):
return raw_code.encode('utf-8').decode('unicode_escape')
python_code = decode_code(python_code)
exec(python_code, {})
# Return everything printed to stdout and stderr
return captured_output.getvalue() + captured_errors.getvalue()
$$
Définir DETERMINISTIC si votre fonction produit des résultats cohérents
Ajoutez DETERMINISTIC à votre définition de fonction s’il produit les mêmes sorties pour les mêmes entrées. Cela permet aux optimisations des requêtes d’améliorer les performances.
Par défaut, les UDFs Python du catalogue Batch Unity sont supposées être non déterministes, à moins d'être déclarées explicitement. Parmi les exemples de fonctions non déterministes, citons la génération de valeurs aléatoires, l’accès aux heures ou dates actuelles ou l’exécution d’appels d’API externes.
Voir CREATE FUNCTION (SQL et Python)
Fonctions définies par l'utilisateur (UDF) pour les outils d'agent IA
Les agents d'intelligence artificielle générative peuvent utiliser les fonctions définies par l'utilisateur du catalogue Unity afin d'effectuer des tâches et d'exécuter une logique personnalisée.
Consultez Créer des outils d’agent IA à l’aide des fonctions de catalogue Unity.
Fonctions définies par l'utilisateur (UDF) pour accéder aux API externes
Vous pouvez utiliser des fonctions définies par l’utilisateur pour accéder aux API externes à partir de SQL. L’exemple suivant utilise la bibliothèque Python requests pour effectuer une requête HTTP.
Remarque
Les fonctions définies par l'utilisateur (UDF) Python autorisent le trafic réseau TCP/UDP sur les ports 80, 443 et 53 en cas d'utilisation du calcul serverless ou du calcul configuré avec le mode d'accès standard.
CREATE FUNCTION my_catalog.my_schema.get_food_calories(food_name STRING)
RETURNS DOUBLE
LANGUAGE PYTHON
AS $$
import requests
api_url = f"https://example-food-api.com/nutrition?food={food_name}"
response = requests.get(api_url)
if response.status_code == 200:
data = response.json()
# Assume the API returns a JSON object with a 'calories' field
calories = data.get('calories', 0)
return calories
else:
return None # API request failed
$$;
UDF pour la sécurité et la conformité
Utilisez les fonctions UDF Python pour implémenter des mécanismes de tokenisation, de masquage des données, de suppression des données ou de chiffrement personnalisés.
L’exemple suivant masque l’identité d’une adresse e-mail tout en conservant la longueur et le domaine :
CREATE OR REPLACE FUNCTION my_catalog.my_schema.mask_email(email STRING)
RETURNS STRING
LANGUAGE PYTHON
DETERMINISTIC
AS $$
parts = email.split('@', 1)
if len(parts) == 2:
username, domain = parts
else:
return None
masked_username = username[0] + '*' * (len(username) - 2) + username[-1]
return f"{masked_username}@{domain}"
$$
L’exemple suivant applique cette fonction UDF dans une définition de vue dynamique :
-- First, create the view
CREATE OR REPLACE VIEW my_catalog.my_schema.masked_customer_view AS
SELECT
id,
name,
my_catalog.my_schema.mask_email(email) AS masked_email
FROM my_catalog.my_schema.customer_data;
-- Now you can query the view
SELECT * FROM my_catalog.my_schema.masked_customer_view;
+---+------------+------------------------+------------------------+
| id| name| email| masked_email |
+---+------------+------------------------+------------------------+
| 1| John Doe| john.doe@example.com | j*******e@example.com |
| 2| Alice Smith|alice.smith@company.com |a**********h@company.com|
| 3| Bob Jones| bob.jones@email.org | b********s@email.org |
+---+------------+------------------------+------------------------+
Meilleures pratiques
Pour que les fonctions définies par l’utilisateur soient accessibles à tous les utilisateurs, nous vous recommandons de créer un catalogue et un schéma dédiés avec des contrôles d’accès appropriés.
Pour les fonctions définies par l’équipe, utilisez un schéma dédié dans le catalogue d’équipes pour le stockage et la gestion.
Databricks vous recommande d’inclure les informations suivantes dans le docstring UDF :
- Numéro de version actuel
- Journal des modifications pour suivre les modifications entre les versions
- Objet UDF, paramètres et valeur de retour
- Exemple d’utilisation de la fonction UDF
Voici un exemple de bonnes pratiques concernant les fonctions UDF :
CREATE OR REPLACE FUNCTION my_catalog.my_schema.calculate_bmi(weight_kg DOUBLE, height_m DOUBLE)
RETURNS DOUBLE
COMMENT "Calculates Body Mass Index (BMI) from weight and height."
LANGUAGE PYTHON
DETERMINISTIC
AS $$
"""
Parameters:
calculate_bmi (version 1.2):
- weight_kg (float): Weight of the individual in kilograms.
- height_m (float): Height of the individual in meters.
Returns:
- float: The calculated BMI.
Example Usage:
SELECT calculate_bmi(weight, height) AS bmi FROM person_data;
Change Log:
- 1.0: Initial version.
- 1.1: Improved error handling for zero or negative height values.
- 1.2: Optimized calculation for performance.
Note: BMI is calculated as weight in kilograms divided by the square of height in meters.
"""
if height_m <= 0:
return None # Avoid division by zero and ensure height is positive
return weight_kg / (height_m ** 2)
$$;
Comportement du fuseau horaire timestamp pour les entrées
Dans Databricks Runtime 18.0 et versions ultérieures, lorsque les valeurs TIMESTAMP sont transmises aux fonctions Python définies par l'utilisateur, les valeurs restent au format UTC, mais les métadonnées de fuseau horaire (tzinfo attribut) ne sont pas incluses dans l'objet datetime.
Cette modification aligne les UDFs Python du catalogue Unity sur les UDFs Python optimisés par Arrow dans Apache Spark.
Par exemple, dans la requête qui suit :
CREATE FUNCTION timezone_udf(date TIMESTAMP)
RETURNS STRING
LANGUAGE PYTHON
AS $$
return f"{type(date)} {date} {date.tzinfo}"
$$;
SELECT timezone_udf(TIMESTAMP '2024-10-23 10:30:00');
Produit précédemment cette sortie dans les versions de Databricks Runtime avant la version 18.0 :
<class 'datetime.datetime'> 2024-10-23 10:30:00+00:00 Etc/UTC
Dans Databricks Runtime 18.0 et versions ultérieures, elle produit désormais cette sortie :
<class 'datetime.datetime'> 2024-10-23 10:30:00+00:00 None
Si votre fonction UDF s’appuie sur les informations de fuseau horaire, vous devez la restaurer explicitement :
from datetime import timezone
date = date.replace(tzinfo=timezone.utc)
Limites
- Vous pouvez définir n’importe quel nombre de fonctions Python au sein d’une fonction UDF Python, mais tous doivent retourner une valeur scalaire.
- Les fonctions Python doivent gérer les valeurs NULL indépendamment, et tous les mappages de types doivent suivre les mappages de langage SQL Azure Databricks.
- Si aucun catalogue ou schéma n'est spécifié, les UDF Python sont enregistrées dans le schéma actif actuel.
- Les UDF Python s'exécutent dans un environnement sécurisé et isolé et n'ont pas accès aux systèmes de fichiers ou aux services internes.
- Vous ne pouvez pas appeler plus de cinq fonctions UDF par requête.