Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les applications full-stack qui combinent des services front-end et back-end sont un modèle courant dans le développement web actuel. Azure Developer CLI (azd) prend en charge le déploiement d’applications complètes où le serveur frontal et le serveur principal sont hébergés en tant que services distincts. Cet article explique comment déployer des applications full-stack à l'aide de azd et met en évidence des stratégies et des avantages pour un déploiement efficace.
Qu’est-ce qu’un déploiement full-stack ?
Un déploiement full-stack avec azd se compose généralement des éléments suivants :
- Service frontal : application web orientée utilisateur, souvent créée avec des infrastructures telles que React, Angular, Vue ou Blazor. Le serveur frontal peut être hébergé en tant que site statique ou en tant qu’application conteneurisée.
- Service principal : une API ou une couche de service qui gère la logique métier, l’accès aux données et les intégrations. Le serveur principal est généralement hébergé dans des conteneurs ou en tant que fonctions sans serveur.
- Ressources partagées : bases de données, comptes de stockage, coffres de clés et autres ressources Azure que les deux services peuvent utiliser.
En utilisant azd, vous pouvez définir les deux services dans un fichier unique azure.yaml et les approvisionner ensemble à l’aide de l’infrastructure en tant que code (Bicep ou Terraform).
Cycle de vie de l’interface CLI pour développeurs Azure
Azure Developer CLI suit un workflow structuré avec des événements de cycle de vie distincts :
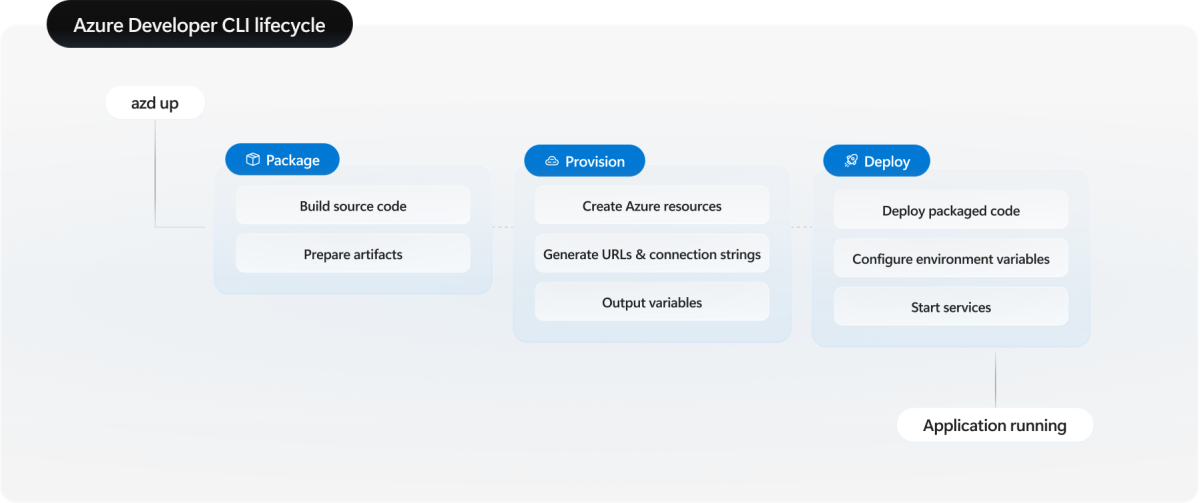
- Package : générez le code source de votre application et préparez les artefacts pour le déploiement.
- Provisionner : créez ou mettez à jour des ressources d’infrastructure Azure à l’aide de Bicep ou Terraform.
- Déployer : déployez le code de votre application empaquetée sur l’infrastructure provisionnée.
La azd up commande exécute les trois phases de manière séquentielle. Vous pouvez également exécuter chaque phase indépendamment en utilisant azd package, azd provisionet azd deploy pour un contrôle plus granulaire. Comprendre ce cycle de vie est essentiel pour gérer les dépendances entre les services, en particulier dans les déploiements de pile complète où le minutage et l’ordre importent.
Pour plus d’informations sur le cycle de vie et la azd personnalisation du flux de travail, consultez Explorer le flux de travail azd up.
Considérations relatives à la conception de l’infrastructure
Lors de la conception d'une application full-stack avec azd, choisissez les services d’hébergement Azure appropriés pour votre serveur frontal et serveur back-end :
| Type de service | Options d’hébergement | Cas d’utilisation |
|---|---|---|
| Interface utilisateur | Azure Static Web Apps, Azure App Service, Azure Container Apps | Sites statiques, spAs, applications rendues par serveur |
| Back-end | Azure Container Apps, Azure App Service, Azure Functions, Azure Kubernetes Service | Interfaces de programmation d'applications (API), microservices, fonctions sans serveur |
En savoir plus sur l’hébergement d’applications sur Azure.
Comprendre l’interdépendance entre les applications front-end et back-end
Les déploiements de pile complète rencontrent souvent des défis de dépendance circulaires où chaque service a besoin d’informations sur l’autre avant de pouvoir être entièrement configuré. La compréhension de ces interdépendances vous aide à concevoir des flux de travail de déploiement efficaces.
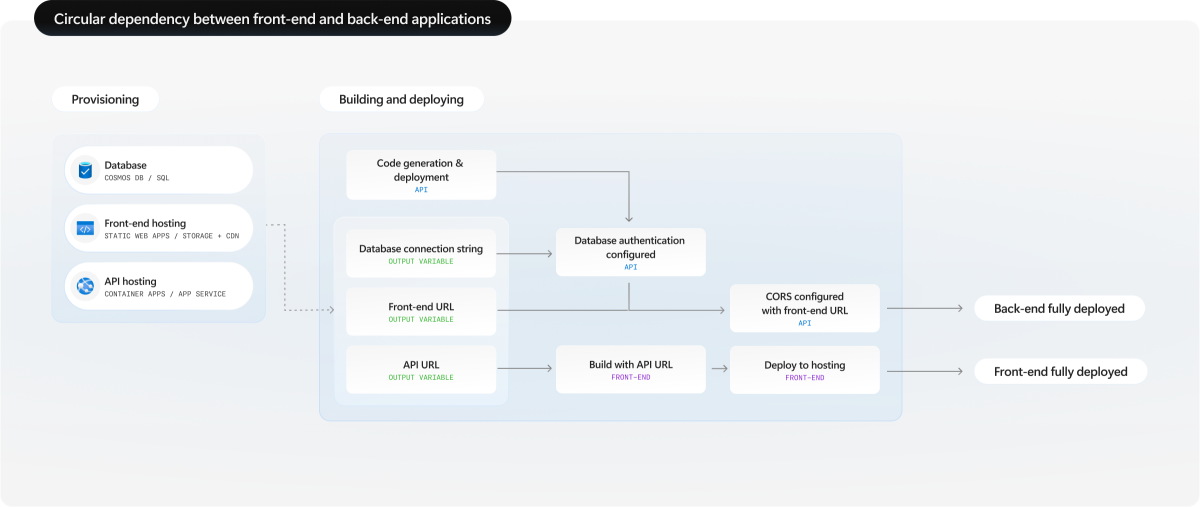
Le front-end a besoin de l'URL du back-end : votre application frontale doit généralement connaître l'URL du point d'accès de l'API back-end au moment de la génération ou au temps d'exécution. Toutefois, le service back-end n’a pas d’URL tant qu’il n’est pas déployé sur Azure.
Le serveur principal a besoin d’une URL frontale : votre service back-end peut avoir besoin de l’URL frontale pour configurer les stratégies CORS, mais le serveur frontal n’a pas d’URL tant qu’il n’est pas déployé.
Dépendances de ressources partagées : les deux services peuvent dépendre de ressources partagées telles que des bases de données, des coffres de clés ou des comptes de stockage. Ces ressources doivent être approvisionnées avant que l’un ou l’autre service puisse être configuré pour les utiliser.
Configuration spécifique à l’environnement : différents environnements (développement, préproduction, production) nécessitent différentes URL et configurations de point de terminaison, mais ces valeurs ne sont pas connues tant que l’approvisionnement n’est pas terminé.
Comprendre les stratégies de configuration
Azure Developer CLI gère ces interdépendances par le biais de deux approches :
- Configuration au moment du déploiement : résoudre les dépendances pendant l’approvisionnement et le déploiement
- Configuration du runtime : différer la configuration des dépendances au moment où l’application s’exécute
Ces approches représentent les décisions de conception que vous prenez lors de la création de votre application. Vous pouvez utiliser une stratégie exclusivement ou combiner les deux en fonction de votre architecture et de vos besoins.
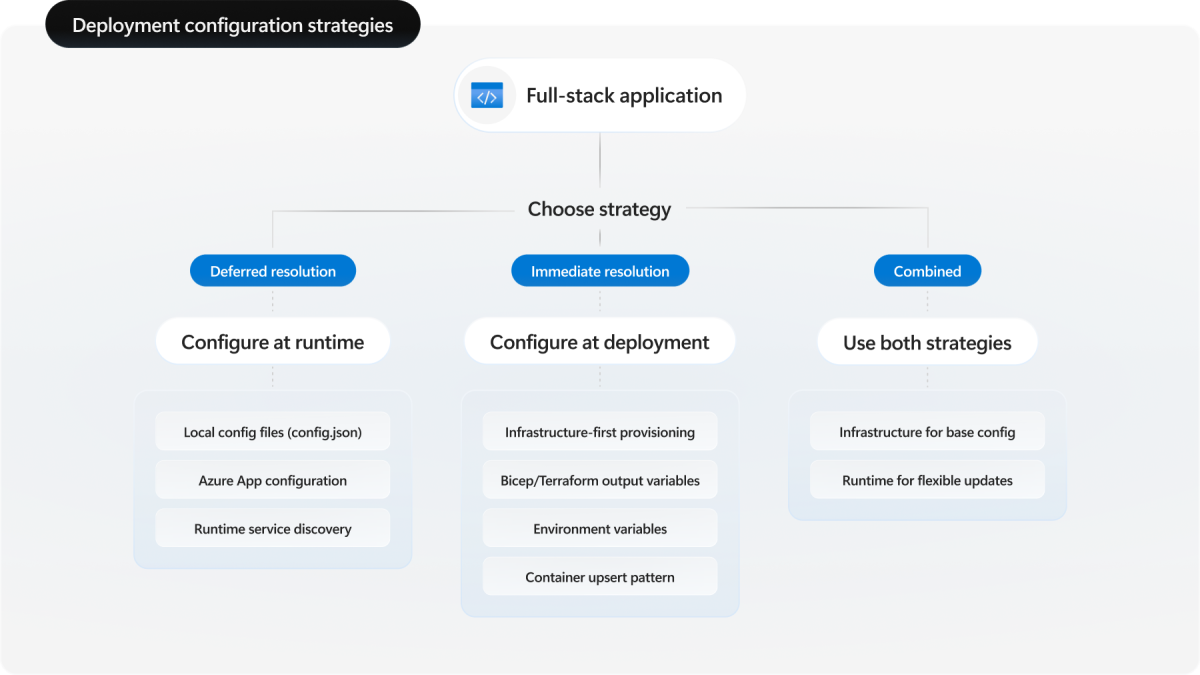
Configuration au moment du déploiement
La configuration au moment du déploiement signifie que les connexions de service et les configurations sont déterminées et verrouillées pendant les phases azd provision et azd deploy. À l’aide de cette approche, vous configurez des services avec des URL de point de terminaison spécifiques, des chaînes de connexion et d’autres informations de dépendance avant qu’ils ne commencent à s’exécuter. Cette configuration fait partie de l’environnement du service déployé, en tant que variables d’environnement ou dans les fichiers de configuration empaquetés avec le déploiement.
Approvisionnement de l'infrastructure d'abord: lorsque vous exécutez azd up ou azd provision, l’infrastructure est créée en premier. Cette étape génère les URL et les chaînes de connexion nécessaires avant le début du déploiement, ce qui garantit que les services dépendants ont les informations dont ils ont besoin.
Variables de sortie : Bicep et Terraform peuvent générer des valeurs, telles que des URL et des chaînes de connexion, après l’approvisionnement. Ces sorties deviennent disponibles en tant que variables d’environnement pendant la phase de déploiement. Vous pouvez donc configurer les services avec les points de terminaison appropriés avant de commencer.
Déploiement séquentiel : pour les scénarios complexes, vous devrez peut-être déployer des services dans un ordre spécifique. Utilisez azddes crochets pour contrôler la séquence de déploiement, assurant que les services préalables sont en cours d'exécution avant le déploiement des services dépendants.
Modèle d’upsert de conteneur : les modules vérifiés Azure (AVM) fournissent des modèles d’application conteneur, tels que container-app-upsert, qui fonctionnent de manière transparente avec le flux de travail en deux phases de azd. Pendant l’approvisionnement, l’infrastructure et le conteneur initial sont créés. Pendant le déploiement, azd upsert l’image conteneur avec des variables d’environnement mises à jour qui incluent des valeurs générées lors de l’approvisionnement, telles que des chaînes de connexion de base de données ou des URL de service. Ce modèle résout le problème de poulet et d’œuf en autorisant l’infrastructure à exister en premier, puis en mettant à jour la configuration du conteneur avec toutes les informations de dépendance requises.
Exemple de flux de travail pour un serveur frontal React avec un back-end d’API de conteneur :
- Exécutez
azd up, qui exécute des phases de package, d’approvisionnement et de déploiement séquentiellement. - Lors de l’approvisionnement, Bicep crée une infrastructure Azure Container Apps à l’aide de modules AVM
container-app-upsertet génère l’URL de l’API principale. - Pendant le déploiement,
azdmet à jour ou insère automatiquement les deux conteneurs avec les variables d’environnement appropriées, y compris l’URL de l’API pour l’interface utilisateur. - Les deux services commencent par la configuration correcte. Lors des futures exécutions de
azd upouazd deploy, les conteneurs sont mis à jour avec toutes les nouvelles valeurs de configuration.
Configuration du runtime
La configuration du runtime permet aux applications de charger la configuration lorsque l’application s’exécute au lieu du déploiement. Cette approche offre une flexibilité pour mettre à jour les points de terminaison de service, les chaînes de connexion et les stratégies sans redéployer votre application.
Sources de configuration : les applications peuvent charger la configuration du runtime à partir de deux sources principales :
Fichiers de configuration locaux : déployez un fichier de configuration, tel que , en même temps que
config.jsonvotre application. L’application charge ce fichier au démarrage pour obtenir les URL de point de terminaison actuelles, les paramètres d’authentification et d’autres valeurs de configuration. Cette approche fonctionne bien pour les frameworks côté client tels que React, Angular, Vue et Blazor WebAssembly qui peuvent récupérer la configuration lorsque l’application démarre dans le navigateur.Services de configuration cloud : utilisez Azure App Configuration ou des services similaires pour gérer de manière centralisée la configuration dans tous les environnements. Les applications interrogent le service de configuration au démarrage ou à la demande pour récupérer les valeurs actuelles. Cette approche est utile pour les architectures de microservices où plusieurs services ont besoin de mises à jour de configuration coordonnées.
Avantages : avec l’une ou l’autre approche, les modifications de configuration deviennent disponibles immédiatement sans redéploiement. Mettez à jour le fichier de configuration via votre pipeline de déploiement ou modifiez les valeurs dans Azure App Configuration via le portail Azure. Lorsque l’application redémarre ou actualise sa configuration, elle récupère les nouvelles valeurs. Ce modèle est particulièrement utile pour :
- Applications frontales qui doivent découvrir des URL d’API principales, des points de terminaison d’authentification et des emplacements de microservice
- Services principaux qui doivent mettre à jour les stratégies CORS à mesure que les URL frontales changent
- Services nécessitant une configuration différente entre les environnements de développement, de préproduction et de production
Exemple de flux de travail pour un serveur frontal React découvrant une API back-end :
- Exécutez
azd uppour approvisionner l’infrastructure et déployer les deux services. - Un hook post-déploiement génère un fichier
config.jsoncontenant l'URL du back-end et le charge à l'emplacement de stockage du front-end. - L’application React récupère
config.jsonau démarrage pour découvrir le point de terminaison de l’API. - Pour mettre à jour le point de terminaison ultérieurement, modifiez
config.jsonsans redéployer le serveur frontal.
Cette approche ne fonctionne pas pour les sites générés statiquement où tout le contenu est pré-rendu au moment de la génération.
Planifier votre flux de travail de déploiement
Tenez compte de ces facteurs lors de la configuration de votre déploiement full-stack :
- Identifier les dépendances : mapper quels services ont besoin d’informations d’autres services. Pour les dépendances unidirectionnelles (par exemple, une API en fonction d’une base de données), la plateforme d’approvisionnement (Bicep ou Terraform) gère automatiquement l’ordre. Pour les dépendances circulaires (telles que les services frontaux et principaux qui ont tous deux besoin des URL des uns des autres au démarrage), vous devez concevoir une coordination à l’aide de stratégies de configuration de déploiement ou d’exécution.
- Provisionner avant le déploiement : vérifiez que l’ensemble de l’infrastructure existe avant de déployer du code d’application.
- Utilisez des variables d’environnement : passez la configuration entre les couches d’infrastructure et d’application à l’aide de variables d’environnement azd.
- Conception de plusieurs environnements : planifiez la façon dont la configuration diffère entre les environnements de développement, de préproduction et de production.
- Envisagez l’ordre de déploiement : certains scénarios peuvent nécessiter le déploiement de services dans une séquence spécifique.
La azd up commande gère la plupart des scénarios de déploiement en exécutant automatiquement l’approvisionnement suivi du déploiement dans un seul workflow. Pour les applications uniques standard, cette approche fonctionne bien et nécessite une configuration minimale.
Pour les déploiements plus complexes, tels qu'un stack complet avec des dépendances circulaires :
Configurer l’ordre de service : dans votre
azure.yamlfichier, définissez les services dans l’ordre dans lequel vous souhaitez qu’ils soient déployés. Tandis queazddéploie les services en parallèle par défaut, vous pouvez utiliser des hooks pour imposer un déploiement séquentiel si nécessaire.Personnaliser les étapes du flux de travail : remplacez le flux de travail par défaut
azd upen définissant une propriété personnaliséeworkflowsdans votreazure.yamlfichier. Par exemple, vous pouvez modifier le comportement par défaut pour exécuter l’approvisionnement avant de générer le code source de votre application :name: todo-nodejs-mongo metadata: template: todo-nodejs-mongo@0.0.1-beta workflows: up: steps: - azd: provision - azd: package - azd: deployCe modèle est utile lorsque votre processus de génération a besoin de valeurs de configuration uniquement disponibles une fois l’approvisionnement terminé.
Provisionner et déployer séparément : au lieu d’utiliser
azd up, exécuterazd provisionetazd deploysous forme de commandes distinctes. Cette séparation est utile lorsque vous devez vérifier la configuration de l’infrastructure avant de déployer du code d’application ou lors de la résolution des problèmes de déploiement. Vous pouvez provisionner l’infrastructure une seule fois, puis déployer et redéployer le code d’application plusieurs fois sans reprovisionner.Personnaliser avec des hooks : ajoutez des crochets avant et post dans votre
azure.yamlfichier pour exécuter une logique personnalisée entre les phases d’approvisionnement et de déploiement. Utilisez des hooks pour remplir des fichiers de configuration, valider l’état de l’environnement ou coordonner des séquences de déploiement complexes.
Meilleures pratiques
Lors de la création d’applications complètes avec azd, suivez les bonnes pratiques suivantes :
- Mapper les dépendances au début : identifiez les services qui ont besoin d’informations d’autres services pendant votre phase de conception. Faites la distinction entre les dépendances unidirectionnelles que Bicep ou Terraform gère automatiquement et circulaires qui nécessitent des stratégies de configuration de déploiement ou d’exécution.
- Choisissez la stratégie de configuration appropriée : utilisez la configuration au moment du déploiement lorsque les services ont besoin d’une configuration verrouillée lors du déploiement. Utilisez la configuration du runtime lorsque vous avez besoin d’une flexibilité pour mettre à jour la configuration sans redéployer. Combinez les deux stratégies le cas échéant.
-
Utilisez des modules vérifiés Azure (AVM) : tirez parti des modules vérifiés Azure Bicep comme
container-app-upsertpour les applications conteneur. Ces modèles fonctionnent en toute transparence avecazdle flux de travail en deux phases pour résoudre les dépendances circulaires. -
Personnalisez les flux de travail si nécessaire : pour les déploiements simples, utilisez
azd uples paramètres par défaut. Pour les scénarios complexes avec des dépendances circulaires, personnalisez laworkflowspropriété dans votreazure.yamlfichier pour contrôler l’ordre de package, d’approvisionnement et de déploiement. - Tirez parti de la configuration du runtime : pour une flexibilité maximale entre les environnements, utilisez Azure App Configuration ou les fichiers de configuration locaux pour gérer les points de terminaison de service et les paramètres que vous pouvez mettre à jour sans redéploiement.
- Testez les environnements : vérifiez que votre stratégie de configuration fonctionne correctement dans les environnements de développement, de préproduction et de production où les URL et configurations de service diffèrent.