Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Azure DevOps Services | Azure DevOps Server | Azure DevOps Server 2022
Vous pouvez organiser votre pipeline en travaux. Chaque pipeline comprend au moins un travail. Un travail consiste en une série d’étapes qui s’exécutent de manière séquentielle comme un tout. En d’autres termes, il s’agit de la plus petite unité de travail dont on puisse planifier l’exécution.
Pour en savoir plus sur les concepts et composants clés qui composent un pipeline, consultez Les concepts clés pour les nouveaux utilisateurs d’Azure Pipelines.
Azure Pipelines ne prend pas en charge la priorité des travaux pour les pipelines YAML. Pour contrôler quand les travaux s’exécutent, vous pouvez spécifier des conditions et des dépendances.
Définition d’un seul travail
Dans le cas le plus simple, un pipeline comporte un seul travail. Il n’est alors pas nécessaire d’utiliser explicitement le mot clé job, à moins de recourir à un modèle. Vous pouvez spécifier directement les étapes dans votre fichier YAML.
Ce fichier YAML comprend un travail qui s’exécute sur un agent hébergé par Microsoft et génère Hello world.
pool:
vmImage: 'ubuntu-latest'
steps:
- bash: echo "Hello world"
Vous pouvez spécifier d’autres propriétés sur ce travail. Dans ce cas, utilisez le mot clé job.
jobs:
- job: myJob
timeoutInMinutes: 10
pool:
vmImage: 'ubuntu-latest'
steps:
- bash: echo "Hello world"
Votre pipeline peut comporter plusieurs travaux. Dans ce cas, utilisez le mot clé jobs.
jobs:
- job: A
steps:
- bash: echo "A"
- job: B
steps:
- bash: echo "B"
Votre pipeline peut comprendre plusieurs phases, chacune décomposée en plusieurs travaux. Dans ce cas, utilisez le mot clé stages.
stages:
- stage: A
jobs:
- job: A1
- job: A2
- stage: B
jobs:
- job: B1
- job: B2
La syntaxe complète pour spécifier un travail est la suivante :
- job: string # name of the job, A-Z, a-z, 0-9, and underscore
displayName: string # friendly name to display in the UI
dependsOn: string | [ string ]
condition: string
strategy:
parallel: # parallel strategy
matrix: # matrix strategy
maxParallel: number # maximum number simultaneous matrix legs to run
# note: `parallel` and `matrix` are mutually exclusive
# you may specify one or the other; including both is an error
# `maxParallel` is only valid with `matrix`
continueOnError: boolean # 'true' if future jobs should run even if this job fails; defaults to 'false'
pool: pool # agent pool
workspace:
clean: outputs | resources | all # what to clean up before the job runs
container: containerReference # container to run this job inside
timeoutInMinutes: number # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: number # how much time to give 'run always even if cancelled tasks' before killing them
variables: { string: string } | [ variable | variableReference ]
steps: [ script | bash | pwsh | powershell | checkout | task | templateReference ]
services: { string: string | container } # container resources to run as a service container
La syntaxe complète pour spécifier un travail est la suivante :
- job: string # name of the job, A-Z, a-z, 0-9, and underscore
displayName: string # friendly name to display in the UI
dependsOn: string | [ string ]
condition: string
strategy:
parallel: # parallel strategy
matrix: # matrix strategy
maxParallel: number # maximum number simultaneous matrix legs to run
# note: `parallel` and `matrix` are mutually exclusive
# you may specify one or the other; including both is an error
# `maxParallel` is only valid with `matrix`
continueOnError: boolean # 'true' if future jobs should run even if this job fails; defaults to 'false'
pool: pool # agent pool
workspace:
clean: outputs | resources | all # what to clean up before the job runs
container: containerReference # container to run this job inside
timeoutInMinutes: number # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: number # how much time to give 'run always even if cancelled tasks' before killing them
variables: { string: string } | [ variable | variableReference ]
steps: [ script | bash | pwsh | powershell | checkout | task | templateReference ]
services: { string: string | container } # container resources to run as a service container
uses: # Any resources (repos or pools) required by this job that are not already referenced
repositories: [ string ] # Repository references to Azure Git repositories
pools: [ string ] # Pool names, typically when using a matrix strategy for the job
Si l’objectif principal de votre travail consiste à déployer votre application (par opposition à générer ou tester votre application), vous pouvez utiliser un type de travail spécial appelé travail de déploiement.
La syntaxe d’un travail de déploiement est la suivante :
- deployment: string # instead of job keyword, use deployment keyword
pool:
name: string
demands: string | [ string ]
environment: string
strategy:
runOnce:
deploy:
steps:
- script: echo Hi!
Bien qu’il soit possible d’ajouter des étapes de tâches de déploiement dans un job, nous vous recommandons d’utiliser plutôt un travail de déploiement. Un travail de déploiement présente quelques avantages. Par exemple, vous pouvez déployer dans un environnement, ce qui inclut des avantages tels que la possibilité de voir l'historique de ce que vous avez déployé.

Types de travaux
Les travaux peuvent être de différents types selon l’endroit où ils s’exécutent.
- Les travaux de pool d’agents s’exécutent sur un agent dans un pool d’agents.
- Les travaux de serveur s’exécutent sur Azure DevOps Server.
- Les travaux de conteneur s’exécutent dans un conteneur sur un agent dans un pool d’agents. Pour plus d’informations sur le choix des conteneurs, consultez Définition de travaux de conteneur.
Travaux de pool d’agents
Les travaux de pool d’agents sont les travaux les plus courants. Ces travaux s'exécutent sur un agent dans un pool d'agents. Vous pouvez spécifier le pool sur lequel exécuter le travail, et vous pouvez également spécifier des exigences pour préciser les capacités qu'un agent doit avoir pour exécuter votre travail. Les agents peuvent être hébergés par Microsoft ou par eux-mêmes. Pour plus d’informations, consultez Agents Azure Pipelines.
- Lorsque vous utilisez des agents hébergés par Microsoft, chaque tâche dans un pipeline obtient un nouvel agent.
- Lorsque vous utilisez des agents auto-hébergés, vous pouvez utiliser exigences pour spécifier les fonctionnalités qu’un agent doit posséder pour exécuter votre tâche. Il peut arriver que vous obteniez le même agent pour des travaux consécutifs, selon qu’il existe dans votre pool d’agents plusieurs agents qui répondent aux demandes de votre pipeline. Si votre pool ne comprend qu’un seul agent adapté, le pipeline attend que ce dernier soit disponible.
Remarque
Les demandes et les fonctionnalités sont conçues pour être utilisées avec des agents autohébergés afin que les travaux puissent être mis en correspondance avec un agent qui répond à leurs demandes. Lorsque vous utilisez des agents hébergés par Microsoft, vous sélectionnez une image pour l'agent qui correspond aux exigences du travail. Bien qu'il soit possible d'ajouter des fonctionnalités à un agent hébergé par Microsoft, il n'est pas nécessaire d'utiliser des fonctionnalités avec les agents hébergés par Microsoft.
pool:
name: myPrivateAgents # your job runs on an agent in this pool
demands: agent.os -equals Windows_NT # the agent must have this capability to run the job
steps:
- script: echo hello world
Le code se présente ainsi dans le cas de demandes multiples :
pool:
name: myPrivateAgents
demands:
- agent.os -equals Darwin
- anotherCapability -equals somethingElse
steps:
- script: echo hello world
Découvrez les fonctionnalités de l’agent.
Travaux de serveur
Le serveur orchestre et exécute les tâches d'un travail de serveur. Un travail de serveur ne nécessite pas d’agent ni d’ordinateurs cibles. Seules quelques tâches sont actuellement prises en charge dans un travail de serveur. La durée maximale d’un travail de serveur est de 30 jours.
Tâches prises en charge par les travaux sans agent
Actuellement, seules les tâches suivantes sont prises en charge d’emblée pour les travaux sans agent :
- Tâche Retarder
- Tâche Appeler une fonction Azure
- Tâche Appeler l’API REST
- Tâche Validation manuelle
- Tâche Publier sur Azure Service Bus
- Tâche Interroger les alertes Azure Monitor
- Tâche Interroger les éléments de travail
Étant donné que les tâches sont extensibles, vous pouvez en ajouter d’autres sans agent à l’aide d’extensions. Le délai d’expiration par défaut des travaux sans agent est de 60 minutes.
La syntaxe complète pour spécifier un travail de serveur est la suivante :
jobs:
- job: string
timeoutInMinutes: number
cancelTimeoutInMinutes: number
strategy:
maxParallel: number
matrix: { string: { string: string } }
pool: server # note: the value 'server' is a reserved keyword which indicates this is an agentless job
Vous pouvez également utiliser la syntaxe simplifiée :
jobs:
- job: string
pool: server # note: the value 'server' is a reserved keyword which indicates this is an agentless job
Les dépendances
Lorsque vous définissez plusieurs travaux dans une seule phase, vous pouvez spécifier des dépendances entre eux. Les pipelines doivent contenir au moins un travail sans dépendance. Par défaut, les travaux de pipeline YAML Azure DevOps s’exécutent en parallèle, à moins que la valeur dependsOn ne soit définie.
Remarque
Un agent ne peut exécuter qu’un seul travail à la fois. Pour exécuter plusieurs travaux en parallèle, vous devez configurer plusieurs agents. Il vous faut également un nombre suffisant de travaux parallèles.
La syntaxe pour définir plusieurs travaux et leurs dépendances est la suivante :
jobs:
- job: string
dependsOn: string
condition: string
Voici quelques exemples de travaux générés séquentiellement :
jobs:
- job: Debug
steps:
- script: echo hello from the Debug build
- job: Release
dependsOn: Debug
steps:
- script: echo hello from the Release build
Voici quelques exemples de travaux générés en parallèle (sans dépendance) :
jobs:
- job: Windows
pool:
vmImage: 'windows-latest'
steps:
- script: echo hello from Windows
- job: macOS
pool:
vmImage: 'macOS-latest'
steps:
- script: echo hello from macOS
- job: Linux
pool:
vmImage: 'ubuntu-latest'
steps:
- script: echo hello from Linux
Exemple de fan-out :
jobs:
- job: InitialJob
steps:
- script: echo hello from initial job
- job: SubsequentA
dependsOn: InitialJob
steps:
- script: echo hello from subsequent A
- job: SubsequentB
dependsOn: InitialJob
steps:
- script: echo hello from subsequent B
Exemple de distribution non ramifiée :
jobs:
- job: InitialA
steps:
- script: echo hello from initial A
- job: InitialB
steps:
- script: echo hello from initial B
- job: Subsequent
dependsOn:
- InitialA
- InitialB
steps:
- script: echo hello from subsequent
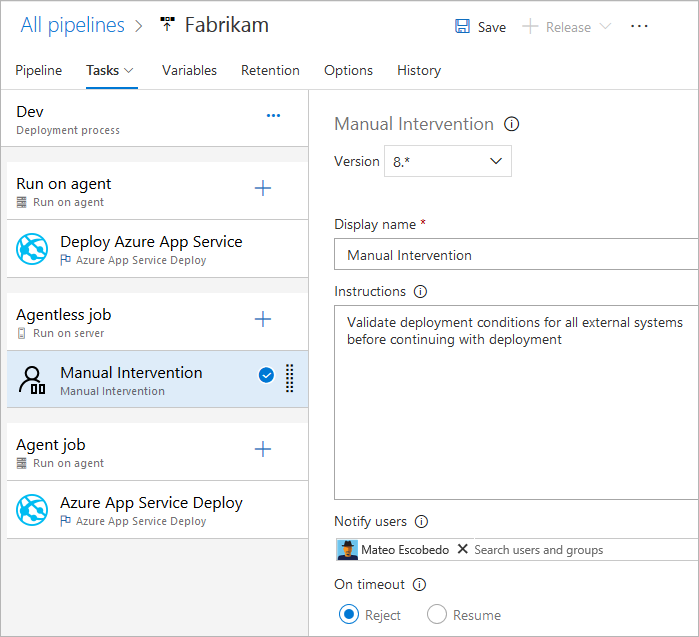
Conditions
Vous pouvez spécifier les conditions d’exécution de chaque travail. Par défaut, un travail s’exécute s’il ne dépend d’aucun autre travail, ou si tous les travaux dont il dépend ont été exécutés avec succès. Vous pouvez personnaliser ce comportement en forçant l’exécution d’un travail en cas d’échec d’un travail précédent ou en spécifiant une condition personnalisée.
Voici un exemple d’exécution d’un travail en fonction de l’état de l’exécution d’un travail précédent :
jobs:
- job: A
steps:
- script: exit 1
- job: B
dependsOn: A
condition: failed()
steps:
- script: echo this will run when A fails
- job: C
dependsOn:
- A
- B
condition: succeeded('B')
steps:
- script: echo this will run when B runs and succeeds
Voici un exemple d’utilisation d’une condition personnalisée :
jobs:
- job: A
steps:
- script: echo hello
- job: B
dependsOn: A
condition: and(succeeded(), eq(variables['build.sourceBranch'], 'refs/heads/main'))
steps:
- script: echo this only runs for master
Vous pouvez spécifier qu’un travail s’exécute en fonction de la valeur d’une variable de sortie définie dans un travail précédent. Dans ce cas, seules les variables définies dans des travaux directement dépendants peuvent être utilisées :
jobs:
- job: A
steps:
- script: "echo '##vso[task.setvariable variable=skipsubsequent;isOutput=true]false'"
name: printvar
- job: B
condition: and(succeeded(), ne(dependencies.A.outputs['printvar.skipsubsequent'], 'true'))
dependsOn: A
steps:
- script: echo hello from B
Délais d'attente
Pour éviter de consommer des ressources lorsque votre tâche ne répond pas ou est en attente trop longtemps, vous pouvez définir une limite sur la durée maximale d'exécution de votre tâche. Utilisez le paramètre de délai d’expiration du travail pour spécifier la limite d’exécution du travail en minutes. La valeur zéro signifie que le travail peut s’exécuter pendant les durées suivantes :
- Pour toujours sur les agents autohébergés
- Pendant 360 minutes (6 heures) sur les agents hébergés par Microsoft avec un projet public et un référentiel public
- Pendant 60 minutes sur les agents hébergés par Microsoft avec un projet privé ou un référentiel privé (sauf si une capacité supplémentaire est payée).
Le délai d’expiration commence au début de l’exécution du travail. Il n’inclut pas le temps de mise en file d’attente du travail ni le temps d’attente d’un agent.
timeoutInMinutes permet de fixer la limite du temps d’exécution du travail. Quand elle n’est pas spécifiée, la valeur par défaut est de 60 minutes. Lorsque 0 est spécifié, la limite maximale est utilisée.
cancelTimeoutInMinutes permet de fixer la limite du délai d’annulation du travail lorsque la tâche de déploiement est définie de façon à continuer à s’exécuter en cas d’échec d’une tâche précédente. Quand elle n’est pas spécifiée, la valeur par défaut est de 5 minutes. La valeur doit être comprise entre 1 et 35 790 minutes.
Remarque
La définition de timeoutInMinutes ou cancelTimeoutInMinutes à une valeur supérieure à la durée maximale d'un agent hébergé par Microsoft n’a aucun effet sur les pipelines des agents hébergés, car ces travaux expirent en fonction des limites fixées par l’agent hébergé. Pour plus d’informations, consultez la section Timeouts précédente.
jobs:
- job: Test
timeoutInMinutes: 10 # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: 2 # how much time to give 'run always even if cancelled tasks' before stopping them
Les délais d’expiration ont le niveau de précédence suivant.
- Sur les agents hébergés par Microsoft, les travaux sont limités dans la durée pendant laquelle ils peuvent s’exécuter en fonction du type de projet et s’ils sont exécutés à l’aide d’un travail parallèle payant. Lorsque l’intervalle de délai d’expiration du travail hébergé par Microsoft est écoulé, le travail est arrêté. Sur les agents hébergés par Microsoft, les travaux ne peuvent pas s’exécuter plus longtemps que cet intervalle, quel que soit le délai d’expiration du niveau du travail spécifié dans le travail.
- Le délai d’expiration configuré au niveau du travail spécifie la durée maximale de l’exécution du travail. Lorsque l’intervalle de délai d’expiration du niveau de travail est écoulé, le travail est arrêté. Lorsque le travail est exécuté sur un agent hébergé par Microsoft, la définition d'un délai d'attente au niveau du travail supérieur au délai d'attente intégré au niveau du travail hébergé par Microsoft n'a aucun effet.
- Vous pouvez également définir le délai d’expiration de chaque tâche individuellement : consultez les options de contrôle des tâches. Si l’intervalle de délai d’expiration du niveau du travail s’écoule avant la fin de la tâche, le travail en cours d’exécution est arrêté, même si la tâche est configurée avec un intervalle de délai d’expiration plus long.
Configuration à plusieurs travaux
À partir d’un seul travail créé, vous pouvez exécuter plusieurs travaux sur différents agents en parallèle. Voici quelques exemples :
Builds multiconfigurations : générez plusieurs configurations en parallèle. Par exemple, vous pouvez créer une application Visual C++ pour les configurations
debugetreleasesur les plateformesx86etx64. Pour plus d’informations, consultez Visual Studio Build : plusieurs configurations pour plusieurs plateformes.Déploiements multiconfigurations : exécutez plusieurs déploiements en parallèle, par exemple dans différentes régions géographiques.
Test multiconfiguration : exécutez plusieurs configurations de test en parallèle.
La multi-configuration génère toujours au moins une tâche, même si une variable de multi-configuration est vide.
La stratégie matrix permet de répartir un travail plusieurs fois, avec différents ensembles de variables. La balise maxParallel limite la quantité de parallélisme. Le travail suivant est réparti trois fois avec les valeurs Emplacement et Navigateur définies comme spécifié. Toutefois, seuls deux travaux s’exécutent en même temps.
jobs:
- job: Test
strategy:
maxParallel: 2
matrix:
US_IE:
Location: US
Browser: IE
US_Chrome:
Location: US
Browser: Chrome
Europe_Chrome:
Location: Europe
Browser: Chrome
Remarque
Les noms des configurations matricielles (comme US_IE dans l'exemple) ne doivent contenir que des lettres de l'alphabet latin de base (A - Z, a - z), des chiffres et des traits de soulignement (_).
Ils doivent commencer par une lettre.
Il doit également comporter 100 caractères maximum.
Il est également possible d’utiliser des variables de sortie pour générer une matrice. Cette méthode peut s'avérer pratique si vous devez générer la matrice à l'aide d'un script.
matrix accepte une expression runtime contenant un objet JSON stringifié.
Lorsqu’il est développé, cet objet JSON doit correspondre à la syntaxe de matrice.
Dans l’exemple suivant, nous avons codé en dur la chaîne JSON, mais vous pouvez la générer avec un langage de script ou un programme de ligne de commande.
jobs:
- job: generator
steps:
- bash: echo "##vso[task.setVariable variable=legs;isOutput=true]{'a':{'myvar':'A'}, 'b':{'myvar':'B'}}"
name: mtrx
# This expands to the matrix
# a:
# myvar: A
# b:
# myvar: B
- job: runner
dependsOn: generator
strategy:
matrix: $[ dependencies.generator.outputs['mtrx.legs'] ]
steps:
- script: echo $(myvar) # echos A or B depending on which leg is running
Découpage
Un travail d’agent peut être utilisé pour exécuter une suite de tests en parallèle. Par exemple, vous pouvez exécuter une grande série de 1000 tests sur un seul agent. Vous pouvez également vous servir de deux agents et lancer 500 tests sur chacun d’eux en parallèle.
Il est nécessaire, pour appliquer le découpage, que les tâches du travail soient suffisamment intelligentes pour savoir à quelle tranche elles appartiennent.
La tâche de test Visual Studio est une tâche de ce type qui prend en charge le découpage des tests. Si vous avez installé plusieurs agents, vous pouvez spécifier la façon dont la tâche Visual Studio Test s’exécute en parallèle sur ces agents.
La stratégie parallel permet de dupliquer un travail plusieurs fois.
Les variables System.JobPositionInPhase et System.TotalJobsInPhase sont ajoutées à chaque travail. Les variables peuvent ensuite être utilisées dans les scripts pour répartir la charge entre les travaux
(cf. Exécution parallèle et multiple à l’aide de travaux d’agent).
Le travail suivant est réparti cinq fois avec les valeurs de System.JobPositionInPhase et de System.TotalJobsInPhase correctement définies.
jobs:
- job: Test
strategy:
parallel: 5
Variables de travail
Si vous utilisez YAML, vous avez la possibilité de spécifier des variables sur le travail. Elles peuvent être passées aux entrées de tâche suivant la syntaxe de macro $(variableName) ou récupérées dans un script à l’aide de la variable de phase.
Voici un exemple de définition de variables dans un travail et d’utilisation dans des tâches.
variables:
mySimpleVar: simple var value
"my.dotted.var": dotted var value
"my var with spaces": var with spaces value
steps:
- script: echo Input macro = $(mySimpleVar). Env var = %MYSIMPLEVAR%
condition: eq(variables['agent.os'], 'Windows_NT')
- script: echo Input macro = $(mySimpleVar). Env var = $MYSIMPLEVAR
condition: in(variables['agent.os'], 'Darwin', 'Linux')
- bash: echo Input macro = $(my.dotted.var). Env var = $MY_DOTTED_VAR
- powershell: Write-Host "Input macro = $(my var with spaces). Env var = $env:MY_VAR_WITH_SPACES"
Pour plus d’informations sur l’utilisation d’une condition, consultez Spécification de conditions.
Espace de travail
Lorsqu’il s’exécute, un travail de pool d’agents crée un espace de travail sur l’agent. Cet espace de travail consiste en un répertoire dans lequel il télécharge la source, exécute les étapes et produit des sorties. Vous pouvez faire référence au répertoire de l’espace de travail dans votre travail à l’aide de la variable Pipeline.Workspace. Dans ce cadre, différents sous-répertoires sont créés :
-
Build.SourcesDirectory: l’endroit où les tâches téléchargent le code source de l’application. -
Build.ArtifactStagingDirectory: l’endroit où les tâches téléchargent les artefacts nécessaires au pipeline ou chargent les artefacts avant leur publication. -
Build.BinariesDirectory: l’endroit où les tâches écrivent leurs sorties. -
Common.TestResultsDirectory: l’endroit où les tâches chargent leurs résultats de test.
Les $(Build.ArtifactStagingDirectory) et $(Common.TestResultsDirectory) sont toujours supprimés et recréés avant chaque compilation.
Lorsque vous exécutez un pipeline sur un agent autohébergé, par défaut, aucun des sous-répertoires autres que $(Build.ArtifactStagingDirectory) et $(Common.TestResultsDirectory) n’est nettoyé entre deux exécutions consécutives. Par conséquent, vous pouvez effectuer des constructions et des déploiements incrémentiels, si des tâches sont mises en œuvre pour les utiliser. Il est possible de remplacer ce comportement en utilisant le paramètre workspace sur le travail.
Important
Les options clean de l’espace de travail ne s’appliquent qu’aux agents autohébergés. Les travaux sont toujours exécutés sur un nouvel agent avec des agents hébergés par Microsoft.
- job: myJob
workspace:
clean: outputs | resources | all # what to clean up before the job runs
Les options clean spécifiées sont interprétées comme suit :
-
outputs: supprimer le répertoireBuild.BinariesDirectoryavant d’exécuter un nouveau travail. -
resources: supprimer le répertoireBuild.SourcesDirectoryavant d’exécuter un nouveau travail. -
all: supprimez l’intégralité du répertoirePipeline.Workspaceavant d’exécuter un nouveau travail.
jobs:
- deployment: MyDeploy
pool:
vmImage: 'ubuntu-latest'
workspace:
clean: all
environment: staging
Remarque
En fonction des capacités de votre agent et des exigences du pipeline, chaque tâche peut être acheminée vers un agent différent dans votre pool auto-hébergé. Par conséquent, vous pouvez obtenir un nouvel agent pour les exécutions ultérieures du pipeline (ou les étapes ou les travaux du même pipeline). Le fait de ne pas nettoyer ne garantit donc pas que les exécutions, les travaux ou les étapes ultérieurs sont en mesure d'accéder aux résultats des exécutions, des travaux ou des étapes antérieurs. Vous pouvez configurer les capacités des agents et les demandes de pipeline pour spécifier quels agents sont utilisés pour exécuter une tâche de pipeline. Toutefois, à moins qu'un seul agent du pool ne réponde aux exigences, il n'est pas garanti que les tâches suivantes utilisent le même agent que les tâches précédentes. Pour plus d’informations, consultez Spécification des demandes.
En plus de l’option clean de l’espace de travail, vous pouvez également configurer le nettoyage en définissant le paramètre Nettoyer dans l’interface utilisateur des paramètres du pipeline. Lorsque le paramètre Nettoyer a la valeur true (qui constitue également sa valeur par défaut), il équivaut à spécifier clean: true pour chaque étape checkout du pipeline. Si vous spécifiez clean: true, vous exécutez git clean -ffdx suivi de git reset --hard HEAD avant la récupération (fetch) Git. Pour configurer le paramètre Nettoyer, procédez comme suit :
Modifiez votre pipeline, choisissez …, puis sélectionnez Déclencheurs.
Sélectionnez YAML et Obtenir des sources, puis configurez le paramètre Nettoyer souhaité. La valeur par défaut est true.
Téléchargement d’artefacts
Cet exemple de fichier YAML publie l’artefact Website, puis le télécharge dans $(Pipeline.Workspace). Le travail de déploiement ne s’exécute que si le travail de build réussit.
# test and upload my code as an artifact named Website
jobs:
- job: Build
pool:
vmImage: 'ubuntu-latest'
steps:
- script: npm test
- task: PublishPipelineArtifact@1
inputs:
artifactName: Website
targetPath: '$(System.DefaultWorkingDirectory)'
# download the artifact and deploy it only if the build job succeeded
- job: Deploy
pool:
vmImage: 'ubuntu-latest'
steps:
- checkout: none #skip checking out the default repository resource
- task: DownloadPipelineArtifact@2
displayName: 'Download Pipeline Artifact'
inputs:
artifactName: Website
targetPath: '$(Pipeline.Workspace)'
dependsOn: Build
condition: succeeded()
Pour plus d’informations sur l’utilisation de dependsOn et de condition, consultez Spécification de conditions.
Accès au jeton OAuth
Vous pouvez autoriser les scripts exécutés dans un travail à accéder au jeton de sécurité OAuth Azure Pipelines actuel. Le jeton peut être utilisé pour s’authentifier auprès de l’API REST Azure Pipelines.
Le jeton OAuth est toujours disponible pour les pipelines YAML.
Il doit être mappé explicitement à la tâche ou à l’étape à l’aide de env.
Voici un exemple :
steps:
- powershell: |
$url = "$($env:SYSTEM_TEAMFOUNDATIONCOLLECTIONURI)$env:SYSTEM_TEAMPROJECTID/_apis/build/definitions/$($env:SYSTEM_DEFINITIONID)?api-version=4.1-preview"
Write-Host "URL: $url"
$pipeline = Invoke-RestMethod -Uri $url -Headers @{
Authorization = "Bearer $env:SYSTEM_ACCESSTOKEN"
}
Write-Host "Pipeline = $($pipeline | ConvertTo-Json -Depth 100)"
env:
SYSTEM_ACCESSTOKEN: $(system.accesstoken)