Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans le domaine en évolution rapide de l’IA générative, les grands modèles de langage (LLMs) comme GPT ont transformé le traitement du langage naturel. Toutefois, une tendance émergente dans l’IA est l’utilisation de magasins de vecteurs, qui jouent un rôle essentiel dans l’amélioration des applications IA.
Ce tutoriel explique comment utiliser Azure DocumentDB, LangChain et OpenAI pour implémenter la génération augmentée par la récupération (RAG) pour des performances d'intelligence artificielle supérieures, et discute également des grands modèles de langage (LLMs) et de leurs limitations. Nous explorons le paradigme rapidement adopté de RAG et abordons brièvement le framework LangChain et les modèles Azure OpenAI. Enfin, nous intégrons ces concepts à une application réelle. À la fin de ce tutoriel, les lecteurs auront une bonne compréhension de ces concepts.
Comprendre les modules LLMs et leurs limitations
Les llMs sont des modèles de réseau neuronal profond avancés formés sur des jeux de données de texte étendus, ce qui leur permet de comprendre et de générer du texte de type humain. Bien que révolutionnaires dans le traitement du langage naturel, les LLM ont des limitations inhérentes :
- Hallucinations : les LLM génèrent parfois des informations factuellement incorrectes ou sans fondement, appelées « hallucinations ».
- Données obsolètes : les modules LLM sont formés sur des jeux de données statiques qui peuvent ne pas inclure les informations les plus récentes, ce qui limite leur pertinence actuelle.
- Aucun accès aux données locales de l’utilisateur : les modules LLM n’ont pas d’accès direct aux données personnelles ou localisées, ce qui limite leur capacité à fournir des réponses personnalisées.
- Limites de jeton : les modules LLM ont une limite de jeton maximale par interaction, limitant la quantité de texte qu’ils peuvent traiter simultanément. Par exemple, le gpt-3.5-turbo d’OpenAI a une limite de tokens de 4 096.
Utiliser la génération augmentée par rappel
RAG est une architecture conçue pour surmonter les limitations LLM. RAG utilise la recherche vectorielle pour récupérer des documents pertinents basés sur une requête d’entrée, en fournissant ces documents comme contexte au LLM pour générer des réponses plus précises. Au lieu de s’appuyer uniquement sur des modèles préformés, RAG améliore les réponses en incorporant des informations pertinentes à jour. Cette approche permet de :
- Réduire les hallucinations : ancrage des réponses dans des informations factuelles.
- Vérifiez les informations actuelles : récupération des données les plus récentes pour garantir des réponses actualisées.
- Utiliser des bases de données externes : bien qu’il n’accorde pas d’accès direct aux données personnelles, RAG autorise l’intégration avec des bases de connaissances externes spécifiques à l’utilisateur.
- Optimiser l’utilisation des jetons : en mettant l’accent sur les documents les plus pertinents, RAG rend l’utilisation des jetons plus efficace.
Ce tutoriel montre comment RAG peut être implémenté à l’aide d’Azure DocumentDB pour créer une application de réponse aux questions adaptée à vos données.
Présentation de l’architecture d’application
Le diagramme d’architecture suivant illustre les composants clés de notre implémentation RAG :

Composants clés et infrastructures
Nous allons maintenant aborder les différentes infrastructures, les modèles et les composants utilisés dans ce tutoriel, en mettant en évidence leurs rôles et nuances.
Azure DocumentDB
Azure DocumentDB prend en charge les recherches sémantiques de similarité, essentielles pour les applications basées sur l’IA. Il permet de représenter des données de différents formats sous forme d’incorporations vectorielles, qui peuvent être stockées avec les données sources et les métadonnées. À l’aide d’un algorithme d'approximation des plus proches voisins, comme un petit monde navigable hiérarchique (HNSW), ces embeddings peuvent être interrogés pour des recherches de similarité sémantique rapides.
Infrastructure LangChain
LangChain simplifie la création d’applications LLM en fournissant une interface standard pour les chaînes, plusieurs intégrations d’outils et des chaînes de bout en bout pour les tâches courantes. Il permet aux développeurs d’IA de créer des applications LLM qui utilisent des sources de données externes.
Aspects clés de LangChain :
- Chaînes : séquences de composants qui résolvent des tâches spécifiques.
- Composants : modules tels que les wrappers LLM, les wrappers de magasin de vecteurs, les modèles de prompts, les chargeurs de données, les séparateurs de texte et les récupérateurs.
- Modularité : simplifie le développement, le débogage et la maintenance.
- Popularité : un projet open source qui acquiert rapidement l’adoption et évolue pour répondre aux besoins des utilisateurs.
Interface Azure App Services
Les services d’application fournissent une plateforme robuste pour la création d’interfaces web conviviales pour les applications d’IA générative. Ce tutoriel utilise Azure App Services pour créer une interface web interactive pour l’application.
Modèles OpenAI
OpenAI est un leader dans la recherche IA, fournissant différents modèles pour la génération de langage, la vectorisation de texte, la création d’images et la conversion d’audio en texte. Pour ce tutoriel, nous allons utiliser les modèles d’incorporation et de langage d’OpenAI, essentiels à la compréhension et à la génération d’applications basées sur le langage.
Modèles d'incorporation contre modèles générateurs de langage
| Catégorie | Modèle d’incorporation de texte | Modèle de langage |
|---|---|---|
| Purpose | Convertit le texte en incorporations vectorielles. | Comprend et génère le langage naturel. |
| Fonction | Transforme les données textuelles en tableaux de nombres à haute dimension, en capturant la signification sémantique du texte. | Comprend et produit du texte de type humain en fonction de l’entrée donnée. |
| Output | Tableau de nombres (incorporations vectorielles). | Texte, réponses, traductions, code, etc. |
| Exemple de sortie | Chaque incorporation représente la signification sémantique du texte sous forme numérique, avec une dimensionnalité déterminée par le modèle. Par exemple, text-embedding-ada-002 génère des vecteurs avec 1 536 dimensions. |
Texte pertinent et cohérent avec le contexte, généré en fonction de l’entrée fournie. Par exemple, gpt-3.5-turbo peut générer des réponses aux questions, traduire du texte, écrire du code et davantage. |
| Cas d’usage classiques | – Recherche sémantique | – Chatbots |
| – Systèmes de recommandation | – Création de contenu automatisée | |
| – Clustering et classification des données texte | – Traduction de langage | |
| – Récupération d’informations | - Synthèse | |
| Représentation des données | Représentation numérique (incorporations) | Texte en langage naturel |
| Dimensionnalité | La longueur du tableau correspond au nombre de dimensions dans l’espace d’incorporation, par exemple, 1 536 dimensions. | Généralement représenté par une séquence de jetons, avec le contexte déterminant la longueur. |
Composants principaux de l’application
- Azure DocumentDB : Stockage et interrogation d’incorporations de vecteurs.
-
LangChain : construction du flux de travail LLM de l’application. Utilise des outils tels que :
- Chargeur de documents : pour le chargement et le traitement de documents à partir d’un répertoire.
- Intégration du magasin de vecteurs : pour stocker et interroger des représentations vectorielles dans Azure DocumentDB.
- AzureDocumentDBVectorSearch : Enveloppe de la recherche vectorielle de Azure DocumentDB
- Azure App Services : création de l’interface utilisateur pour l’application Cosmo Food.
-
Azure OpenAI : pour fournir des modèles LLM et d’incorporation, notamment :
- text-embedding-ada-002 : modèle d’incorporation de texte qui convertit le texte en incorporations vectorielles avec 1 536 dimensions.
- gpt-3.5-turbo : un modèle de langage permettant de comprendre et de générer le langage naturel.
Configurer l’environnement
Pour commencer à optimiser RAG à l’aide d’Azure DocumentDB, procédez comme suit :
-
Créez les ressources suivantes sur Microsoft Azure :
- Cluster Azure DocumentDB : Pour plus d’informations, consultez créer un cluster
-
Ressource Azure OpenAI avec :
-
Déploiement du modèle d’incorporation (par exemple,
text-embedding-ada-002). -
Déploiement du modèle de conversation (par exemple,
gpt-35-turbo).
-
Déploiement du modèle d’incorporation (par exemple,
Exemples de documents
Dans ce tutoriel, vous chargez un fichier texte unique à l’aide de chargeurs de documents. Le fichier doit être enregistré dans un répertoire nommé data dans le dossier src . Le contenu du fichier est le suivant :
food_items.json
{
"category": "Cold Dishes",
"name": "Hamachi Fig",
"description": "Hamachi sashimi lightly tossed in a fig sauce with rum raisins, and serrano peppers then topped with fried lotus root.",
"price": "16.0 USD"
},
Chargement de documents
Définissez la chaîne de connexion Azure DocumentDB, le nom de la base de données, le nom de la collection et l’index :
mongo_client = MongoClient(mongo_connection_string) database_name = "Contoso" db = mongo_client[database_name] collection_name = "ContosoCollection" index_name = "ContosoIndex" collection = db[collection_name]Initialisez le client d’incorporation.
from langchain_openai import AzureOpenAIEmbeddings openai_embeddings_model = os.getenv("AZURE_OPENAI_EMBEDDINGS_MODEL_NAME", "text-embedding-ada-002") openai_embeddings_deployment = os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME", "text-embedding") azure_openai_embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings( model=openai_embeddings_model, azure_deployment=openai_embeddings_deployment, )Créez des embeddings à partir des données, enregistrez-les dans la base de données et retournez une connexion vers votre magasin vectoriel, Azure DocumentDB.
vector_store: AzureDocumentDBVectorSearch = AzureDocumentDBVectorSearch.from_documents( json_data, azure_openai_embeddings, collection=collection, index_name=index_name, )Créez l’index vectoriel HNSW suivant sur la collection. (Notez que le nom de l’index est le même.)
num_lists = 100 dimensions = 1536 similarity_algorithm = DocumentDBSimilarityType.COS kind = DocumentDBVectorSearchType.VECTOR_HNSW m = 16 ef_construction = 64 vector_store.create_index( num_lists, dimensions, similarity_algorithm, kind, m, ef_construction )
Effectuer une recherche vectorielle à l’aide d’Azure DocumentDB
Connectez-vous à votre magasin de vecteurs.
vector_store: AzureDocumentDBVectorSearch = AzureDocumentDBVectorSearch.from_connection_string( connection_string=mongo_connection_string, namespace=f"{database_name}.{collection_name}", embedding=azure_openai_embeddings, )Définissez une fonction qui effectue une recherche de similarité sémantique à l’aide de la recherche vectorielle Azure DocumentDB sur une requête. (Notez que cet extrait de code n’est qu’une fonction de test.)
query = "beef dishes" docs = vector_store.similarity_search(query) print(docs[0].page_content)Initialisez le client de conversation pour implémenter une fonction RAG.
azure_openai_chat: AzureChatOpenAI = AzureChatOpenAI( model=openai_chat_model, azure_deployment=openai_chat_deployment, )Créez une fonction RAG.
history_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ( "user", """Given the above conversation, generate a search query to look up to get information relevant to the conversation""", ), ] ) context_prompt = ChatPromptTemplate.from_messages( [ ("system", "Answer the user's questions based on the below context:\n\n{context}"), MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ] )Convertissez le magasin de vecteurs en récupérateur, qui peut rechercher des documents pertinents en fonction des paramètres spécifiés.
vector_store_retriever = vector_store.as_retriever( search_type=search_type, search_kwargs={"k": limit, "score_threshold": score_threshold} )Créez une chaîne de récupérateur qui tient compte de l’historique des conversations, pour garantir une récupération de documents contextuellement pertinente à l’aide du modèle azure_openai_chat et du vector_store_retriever.
retriever_chain = create_history_aware_retriever(azure_openai_chat, vector_store_retriever, history_prompt)Créez une chaîne qui combine les documents récupérés dans une réponse cohérente à l’aide du modèle de langage (azure_openai_chat) et d’un prompt spécifié (context_prompt).
context_chain = create_stuff_documents_chain(llm=azure_openai_chat, prompt=context_prompt)Créez une chaîne qui gère l’ensemble du processus de récupération, en intégrant la chaîne de récupération prenant en charge l’historique et la chaîne de combinaison de documents. Cette chaîne RAG peut être exécutée pour récupérer et générer des réponses contextuellement précises.
rag_chain: Runnable = create_retrieval_chain( retriever=retriever_chain, combine_docs_chain=context_chain, )
Exemples de sortie
La capture d’écran suivante illustre les sorties pour différentes questions. Une recherche sémantique de similarité renvoie le texte brut des documents sources, tandis que l’application de réponse aux questions qui utilise l’architecture RAG génère des réponses précises et personnalisées en combinant le contenu du document récupéré avec le modèle de langage.
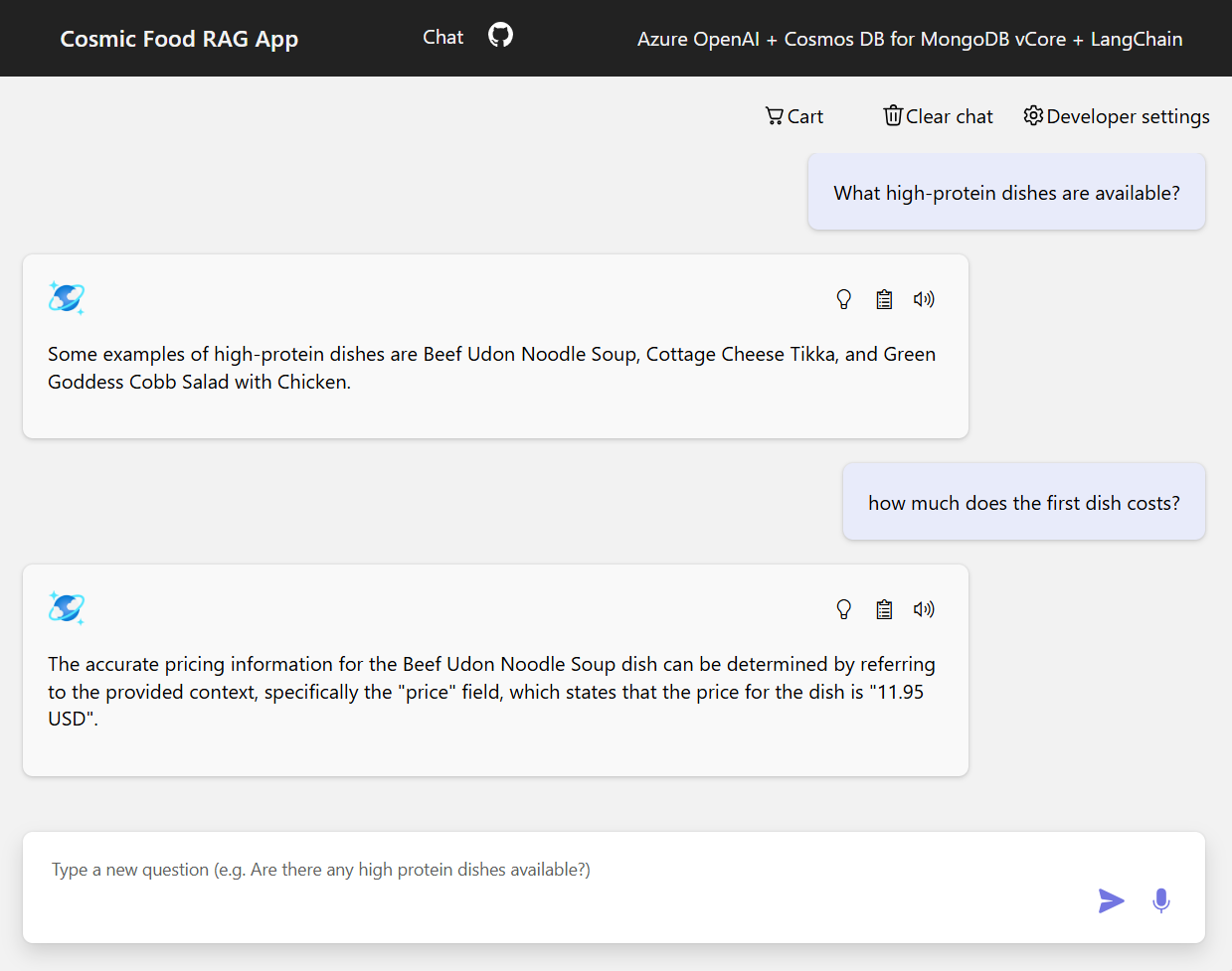
Conclusion
Dans ce tutoriel, nous avons découvert comment créer une application de réponse aux questions qui interagit avec vos données privées à l’aide d’Azure DocumentDB comme magasin de vecteurs. En utilisant l’architecture RAG avec LangChain et Azure OpenAI, nous avons démontré comment les magasins vectoriels sont essentiels pour les applications LLM.
RAG est un progrès important dans l’IA, en particulier dans le traitement du langage naturel, et la combinaison de ces technologies permet la création d’applications puissantes pilotées par l’IA pour différents cas d’usage.