Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans ce tutoriel, vous allez créer un générateur de publicité basé sur l’IA à l’aide d’Azure DocumentDB et d’OpenAI pour créer du contenu publicitaire dynamique et personnalisé. L’application utilise la recherche de similarité vectorielle pour faire correspondre les éléments d’inventaire avec des sujets publicitaires, puis utilise GPT-4 et DALL-E 3 pour générer une copie et des images publicitaires attrayantes via un assistant IA nommé Heelie.
L’application fonctionne en générant des incorporations vectorielles pour les descriptions d’inventaire à l’aide d’incorporations OpenAI, qui capturent la signification sémantique des descriptions de produits. Ces vecteurs sont stockés et indexés dans Azure DocumentDB, ce qui permet de puissantes recherches de similarité vectorielle. Lorsque vous devez générer une publicité, l'application vectorise le sujet de publicité pour trouver les éléments d'inventaire les mieux correspondants par le biais de la recherche vectorielle. Il utilise ensuite un processus de génération augmentée par récupération (RAG) pour envoyer les principales correspondances à OpenAI, qui élabore du contenu publicitaire attrayant, y compris des slogans accrocheurs et des images réalistes.
Dans ce tutoriel, vous allez :
- Configurer votre environnement Python avec les packages requis
- Configurer des clients Azure OpenAI et Azure DocumentDB
- Créer des incorporations vectorielles à partir de descriptions de produits
- Configurer une base de données Azure DocumentDB avec indexation vectorielle
- Implémenter la recherche de similarité vectorielle pour rechercher des produits pertinents
- Générer du contenu publicitaire à l’aide de GPT-4 et DALL-E 3
- Créer une interface web interactive avec Gradio
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prerequisites
Un abonnement Azure
- Si vous n’avez pas d’abonnement Azure, créez un compte gratuit
Un cluster Azure DocumentDB existant
- Si vous n’avez pas de cluster, créez un cluster
Pare-feu configuré pour autoriser l’accès à votre adresse IP cliente
-
text-embedding-ada-002Modèle d’incorporation déployégpt-4modèle de complétion déployé
Python 3.12 ou version ultérieure
Obtenir des exemples de données
Dans ce tutoriel, vous travaillez avec un jeu de données de produits de chaussures qui comprend des descriptions de produits et des incorporations de vecteurs précomputées. Les données d'exemple contiennent des informations d'inventaire que l'application utilise pour illustrer la recherche de similarité vectorielle et la génération de publicité.
Téléchargez l’exemple de fichier de données à partir du dépôt GitHub :
curl -o data/shoes_with_vectors.json https://raw.githubusercontent.com/jayanta-mondal/ignite-demo/main/data/shoes_with_vectors.jsonCréez un
datadossier dans votre répertoire de projet et enregistrez le fichier à l’intérieurshoes_with_vectors.jsonde celui-ci. Le fichier contient des informations sur le produit, notamment les noms, les descriptions, les prix et les incorporations vectorielles qui activent la fonctionnalité de recherche sémantique.
Configurer votre environnement Python
Configurez votre environnement Python avec les packages nécessaires et configurez vos clients Azure pour authentifier les demandes auprès de l’API OpenAI et des services Azure.
Ouvrez votre terminal et installez les packages Python requis :
pip install numpy pip install openai==1.2.3 pip install pymongo pip install python-dotenv pip install azure-core pip install azure-cosmos pip install tenacity pip install gradioVérifiez l’installation du package OpenAI :
pip show openaiCréez un fichier Python pour votre projet (par exemple).
ad_generator.pyAjoutez le code suivant pour importer les bibliothèques requises et configurer le client Azure OpenAI :
import json import time import openai from dotenv import dotenv_values from openai import AzureOpenAI # Configure the API to use Azure as the provider openai.api_type = "azure" openai.api_key = "<AZURE_OPENAI_API_KEY>" # Replace with your actual Azure OpenAI API key openai.api_base = "https://<OPENAI_ACCOUNT_NAME>.openai.azure.com/" # Replace with your OpenAI account name openai.api_version = "2023-06-01-preview" # Initialize the AzureOpenAI client with your API key, version, and endpoint client = AzureOpenAI( api_key=openai.api_key, api_version=openai.api_version, azure_endpoint=openai.api_base )Remplacez les valeurs de substitution par vos véritables informations d'identification Azure OpenAI :
-
<AZURE_OPENAI_API_KEY>: Votre clé API Azure OpenAI à partir des prérequis -
<OPENAI_ACCOUNT_NAME>: Nom de votre compte Azure OpenAI
-
Créer des incorporations vectorielles
Créez des incorporations vectorielles à partir de descriptions de produits pour capturer leur signification sémantique sous forme que les machines peuvent comprendre et traiter. Le diagramme suivant illustre l’architecture de la solution :
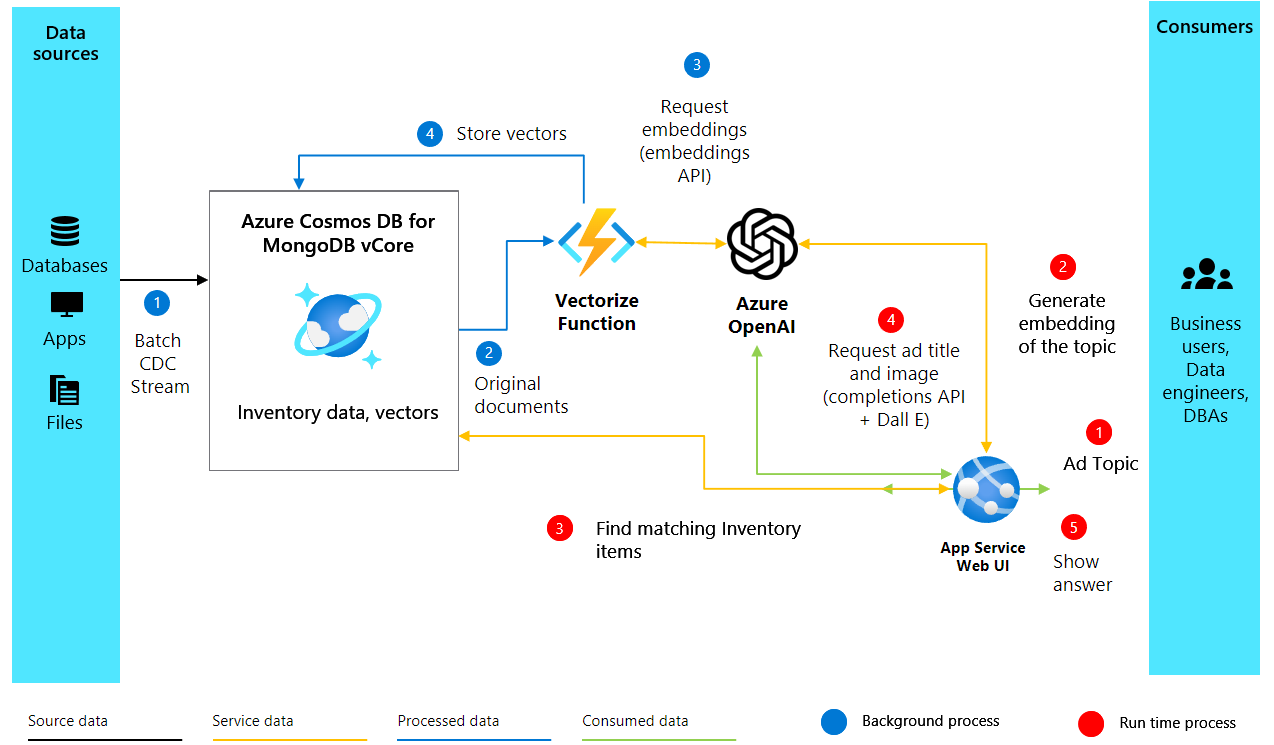
Créez des incorporations vectorielles à l’aide d’Azure OpenAI en ajoutant la fonction suivante à votre fichier Python :
import openai def generate_embeddings(text): try: response = client.embeddings.create( input=text, model="text-embedding-ada-002") embeddings = response.data[0].embedding return embeddings except Exception as e: print(f"An error occurred: {e}") return NoneCette fonction prend une entrée de texte et utilise la
client.embeddings.createméthode pour générer un incorporation vectorielle. Letext-embedding-ada-002modèle convertit le texte en vecteur haute dimension qui capture la signification sémantique.Testez votre fonction d’incorporation avec un exemple de description de produit :
embeddings = generate_embeddings("Shoes for San Francisco summer") if embeddings is not None: print(embeddings)Si elle réussit, la fonction imprime les incorporations générées ; sinon, il gère les exceptions en imprimant un message d’erreur.
Se connecter à Azure DocumentDB
Établissez une connexion à Azure DocumentDB pour stocker et indexer vos incorporations dans une base de données qui prend en charge la recherche de similarité vectorielle.
Ajoutez le code suivant pour établir une connexion avec votre cluster Azure DocumentDB :
import pymongo # Replace <username>, <password>, and <cluster-name> with your actual credentials mongo_conn = "mongodb+srv://<username>:<password>@<cluster-name>.mongocluster.cosmos.azure.com/?tls=true&authMechanism=SCRAM-SHA-256&retrywrites=false&maxIdleTimeMS=120000" mongo_client = pymongo.MongoClient(mongo_conn)Remplacez les valeurs d'espace réservé par vos véritables identifiants MongoDB figurant dans les prérequis :
-
<username>: nom d’utilisateur MongoDB -
<password>: mot de passe MongoDB -
<cluster-name>: Nom de votre cluster vCore
-
Créer une base de données et une collection
Stockez les données de publication et l’inventaire des produits en créant une base de données et une collection au sein de votre instance Azure DocumentDB.
Ajoutez le code suivant pour créer une base de données et une collection :
DATABASE_NAME = "AdgenDatabase" COLLECTION_NAME = "AdgenCollection" mongo_client.drop_database(DATABASE_NAME) db = mongo_client[DATABASE_NAME] collection = db[COLLECTION_NAME] if COLLECTION_NAME not in db.list_collection_names(): # Creates a unsharded collection that uses the database's shared throughput db.create_collection(COLLECTION_NAME) print("Created collection '{}'.\n".format(COLLECTION_NAME)) else: print("Using collection: '{}'.\n".format(COLLECTION_NAME))Ce code définit les noms de base de données et de collection, supprime toute base de données existante portant le même nom pour une configuration propre, crée une base de données et une collection et imprime les messages de confirmation.
Créer un index vectoriel
Créez un index vectoriel pour permettre des recherches efficaces de similarité vectorielle dans votre collection. Azure DocumentDB prend en charge différents types d’index vectoriels : Index de fichiers inversés (IVF) et HNSW (Hiérarchique Navigable Small World).
Choisissez votre algorithme d’indexation en fonction de votre niveau de cluster :
- IVF : Algorithme par défaut qui fonctionne sur tous les niveaux de cluster, utilise l’approche approximative des voisins les plus proches (ANN)
- HNSW : Structure basée sur graphe, plus rapide avec une plus grande précision, disponible uniquement sur les niveaux de cluster M40 et versions ultérieures
Pour créer un index IVF, exécutez la commande suivante :
db.runCommand({ 'createIndexes': 'AdgenCollection', 'indexes': [ { 'name': 'vectorSearchIndex', 'key': { "contentVector": "cosmosSearch" }, 'cosmosSearchOptions': { 'kind': 'vector-ivf', 'numLists': 1, 'similarity': 'COS', 'dimensions': 1536 } } ] });(Facultatif) Si vous utilisez un niveau de cluster M40 ou supérieur, vous pouvez créer un index HNSW à la place :
db.runCommand({ "createIndexes": "AdgenCollection", "indexes": [ { "name": "VectorSearchIndex", "key": { "contentVector": "cosmosSearch" }, "cosmosSearchOptions": { "kind": "vector-hnsw", "m": 16, "efConstruction": 64, "similarity": "COS", "dimensions": 1536 } } ] })
Important
Vous ne pouvez créer qu’un seul index par propriété vectorielle. Si vous souhaitez modifier le type d’index (par exemple, d’IVF à HNSW), vous devez d’abord supprimer l’index avant de créer un nouvel index.
Charger des données d’inventaire
Insérez les données d’inventaire, qui incluent des descriptions de produits et leurs incorporations vectorielles correspondantes, dans votre collection.
Ajoutez le code suivant pour charger et insérer les données dans votre collection :
data_file = open(file="./data/shoes_with_vectors.json", mode="r") data = json.load(data_file) data_file.close() result = collection.insert_many(data) print(f"Number of data points added: {len(result.inserted_ids)}")Ce code ouvre le fichier JSON, charge les données, insère tous les documents dans la collection en utilisant
insert_many()et imprime le nombre de documents ajoutés.
Implémenter la recherche vectorielle
Utilisez la recherche vectorielle pour rechercher les éléments les plus pertinents en fonction d’une requête. L’index vectoriel que vous avez créé active les recherches sémantiques dans le jeu de données.
Ajoutez la fonction suivante pour effectuer des recherches de similarité vectorielle :
def vector_search(query, num_results=3): query_vector = generate_embeddings(query) embeddings_list = [] pipeline = [ { '$search': { "cosmosSearch": { "vector": query_vector, "numLists": 1, "path": "contentVector", "k": num_results }, "returnStoredSource": True }}, {'$project': { 'similarityScore': { '$meta': 'searchScore' }, 'document' : '$$ROOT' } } ] results = collection.aggregate(pipeline) return resultsCette fonction génère un vecteur d'embedding pour la requête de recherche, crée un pipeline d'agrégation qui utilise la
$searchfonctionnalité d'Azure DocumentDB, recherche les éléments correspondants les plus proches en fonction de la similarité vectorielle et retourne des résultats avec des scores de similarité.Testez votre fonction de recherche vectorielle avec un exemple de requête :
query = "Shoes for Seattle sweater weather" results = vector_search(query, 3) print("\nResults:\n") for result in results: print(f"Similarity Score: {result['similarityScore']}") print(f"Title: {result['document']['name']}") print(f"Price: {result['document']['price']}") print(f"Material: {result['document']['material']}") print(f"Image: {result['document']['img_url']}") print(f"Purchase: {result['document']['purchase_url']}\n")Ce code exécute une recherche vectorielle et affiche les trois principaux produits correspondants avec leurs scores et détails de similarité.
Générer du contenu publicitaire
Combinez tous les composants pour créer des publicités attrayantes à l’aide du GPT-4 d’OpenAI pour le texte et DALL-E 3 pour les images.
Ajoutez la fonction suivante pour générer des titres de publicité catchy à l’aide de GPT-4 :
from openai import OpenAI def generate_ad_title(ad_topic): system_prompt = ''' You are Heelie, an intelligent assistant for generating witty and captivating taglines for online advertisements. - The ad campaign taglines that you generate are short and typically under 100 characters. ''' user_prompt = f'''Generate a catchy, witty, and short sentence (less than 100 characters) for an advertisement for selling shoes for {ad_topic}''' messages=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": user_prompt}, ] response = client.chat.completions.create( model="gpt-4", messages=messages ) return response.choices[0].message.contentAjoutez la fonction suivante pour générer des images de publicité à l’aide de DALL-E 3 :
def generate_ad_image(ad_topic): daliClient = OpenAI( api_key="<DALI_API_KEY>" ) image_prompt = f''' Generate a photorealistic image of an ad campaign for selling {ad_topic}. The image should be clean, with the item being sold in the foreground with an easily identifiable landmark of the city in the background. The image should also try to depict the weather of the location for the time of the year mentioned. The image should not have any generated text overlay. ''' response = daliClient.images.generate( model="dall-e-3", prompt= image_prompt, size="1024x1024", quality="standard", n=1, ) return response.data[0].urlRemplacez
<DALI_API_KEY>par votre clé API OpenAI.Ajoutez la fonction suivante pour combiner tous les éléments dans une publication HTML complète :
def render_html_page(ad_topic): # Find the matching shoes from the inventory results = vector_search(ad_topic, 4) ad_header = generate_ad_title(ad_topic) ad_image_url = generate_ad_image(ad_topic) with open('./data/ad-start.html', 'r', encoding='utf-8') as html_file: html_content = html_file.read() html_content += f'''<header> <h1>{ad_header}</h1> </header>''' html_content += f''' <section class="ad"> <img src="{ad_image_url}" alt="Base Ad Image" class="ad-image"> </section>''' for result in results: html_content += f''' <section class="product"> <img src="{result['document']['img_url']}" alt="{result['document']['name']}" class="product-image"> <div class="product-details"> <h3 class="product-title" color="gray">{result['document']['name']}</h2> <p class="product-price">{"$"+str(result['document']['price'])}</p> <p class="product-description">{result['document']['description']}</p> <a href="{result['document']['purchase_url']}" class="buy-now-button">Buy Now</a> </div> </section> ''' html_content += '''</article> </body> </html>''' return html_contentCette fonction effectue une recherche vectorielle pour rechercher des produits correspondants, génère un titre de publication à l’aide de GPT-4, génère une image de publication à l’aide de DALL-E 3 et combine tout dans une page HTML avec des descriptions de produits.
Créer une interface interactive
Créez une interface web interactive qui permet aux utilisateurs d’entrer des sujets de publication et génère et affiche dynamiquement les publicités résultantes.
Ajoutez le code suivant pour créer l’interface web :
import gradio as gr css = """ button { background-color: purple; color: red; } <style> </style> """ with gr.Blocks(css=css, theme=gr.themes.Default(spacing_size=gr.themes.sizes.spacing_sm, radius_size="none")) as demo: subject = gr.Textbox(placeholder="Ad Keywords", label="Prompt for Heelie!!") btn = gr.Button("Generate Ad") output_html = gr.HTML(label="Generated Ad HTML") btn.click(render_html_page, [subject], output_html) btn = gr.Button("Copy HTML") if __name__ == "__main__": demo.launch()Enregistrez votre fichier Python (par exemple,
ad_generator.py).Exécutez l’application à partir de votre terminal :
python ad_generator.pyOuvrez votre navigateur web et accédez à l’URL affichée dans le terminal (généralement
http://localhost:7860).Entrez des mots clés de publicité et sélectionnez Générer une publicité pour afficher votre publicité générée par l’IA.
Observez la publicité générée. La publication générée combine les résultats de recherche vectorielle avec du contenu généré par l’IA pour créer une publicité attrayante et personnalisée. L'application crée divers éléments pour vous. Tout d’abord, il crée un slogan accrocheur à l’aide de l’IA. Ensuite, il crée une image publicitaire réaliste avec DALL-E 3. Il trouve également des produits qui correspondent à votre sujet à l’aide de la recherche vectorielle. Enfin, il vous montre les détails complets du produit avec des images, des descriptions et des liens pour les acheter.
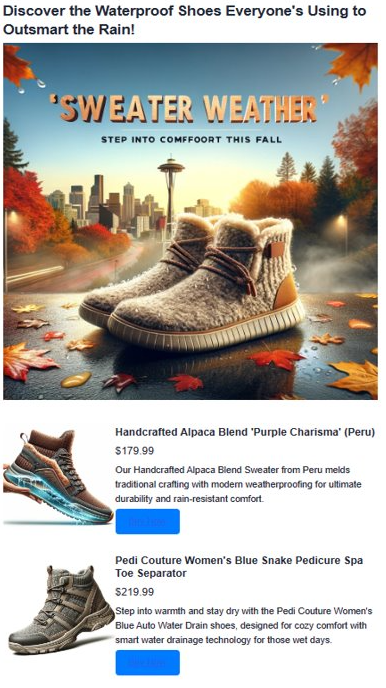
Nettoyer les ressources
Si vous avez créé des ressources spécifiquement pour ce didacticiel et que vous n’en avez plus besoin, supprimez-les pour éviter les frais.
Supprimez la base de données Azure DocumentDB en accédant à votre ressource Azure DocumentDB dans le portail Azure, en sélectionnant Explorateur de données, en cliquant avec le bouton droit sur la
AdgenDatabasebase de données et en sélectionnant Supprimer la base de données.(Facultatif) Supprimez les déploiements Azure OpenAI en accédant à votre ressource Azure OpenAI dans le portail Azure, en sélectionnant Déploiements de modèles et en supprimant les déploiements GPT-4 et text-embedding-ada-002 si vous les avez créés uniquement pour ce didacticiel.
(Facultatif) Si vous avez créé un groupe de ressources dédié pour ce didacticiel, supprimez l’ensemble du groupe de ressources pour supprimer toutes les ressources associées.