Concepts en lien avec l’ingestion basée sur un manifeste
L’ingestion de fichiers basée sur un manifeste fournit aux utilisateurs finaux et aux systèmes un mécanisme robuste pour charger des métadonnées dans une instance Azure Data Manager for Energy. Ces métadonnées sont indexées par le système et permettent à l’utilisateur final d’effectuer des recherches dans les jeux de données.
L’ingestion de fichiers basée sur un manifeste est une ingestion opaque, c’est-à-dire qu’elle n’analyse pas et ne comprend pas le contenu du fichier. Elle crée un enregistrement de métadonnées basé sur le manifeste et permet à l’enregistrement de faire l’objet d’une recherche.
Qu’est-ce qu’un manifeste ?
Un manifeste est un document JSON qui repose sur une structure prédéterminée pour capturer des entités définies avec un « genre » (kind), c’est-à-dire inscrites en tant que schémas auprès du service de schémas selon les définitions WKS (Well-Known Schema).
Vous trouverez un exemple de document de manifeste au format JSON ici.
Le schéma de manifeste contient des conteneurs pour les types de groupes OSDU® suivants :
- ReferenceData (zéro ou plus) : ensemble de valeurs autorisées pouvant être utilisées par d’autres champs de données (principal ou de transaction). Il s’agit par exemple de l’unité de mesure (pied), de la devise, etc.
- MasterData (zéro ou plus) : source unique de données métier de base utilisées sur plusieurs systèmes, applications et/ou processus. Les exemples incluent Wells et Wellbores.
- WorkProduct (WP) (un seul - doit être présent en cas de chargement de WorkProductComponents) : une limite de session ou une collection (projet, étude) englobe un ensemble d’entités qui doivent être traitées ensemble. Par exemple, vous pouvez prendre l’ingestion d’une ou plusieurs collectes de journaux.
- WorkProductComponents (WPC) (zéro ou plus - doit être présent en cas de chargement de jeux de données) : unité de contenu de données métier typée, la plus petite et utilisable indépendamment, transférée dans le cadre d’un produit de travail (une collection d’éléments ingérés ensemble). Chaque composant de produit de travail (WPC) utilise généralement des données de référence, appartient à certaines données de référence et conserve une référence aux jeux de données. Exemple : Journaux d’activité, erreurs, documents
- Jeux de données (zéro ou plus - doivent être présents si vous chargez des enregistrements WorkProduct et WorkProductComponent) : chaque composant de produit de travail (WPC) se compose d’un ou plusieurs conteneurs de données appelés jeux de données.
Les données du manifeste sont chargées dans une séquence particulière :
- Le tableau « ReferenceData » (s’il est rempli).
- Le tableau « MasterData » (s’il est rempli).
- La structure « Data » est traitée en dernier (si elle est remplie). Dans la propriété « Data », le traitement est effectué dans l’ordre suivant :
- Tableau « Datasets »
- Tableau « WorkProductComponents »
- « WorkProduct »
Tous les tableaux sont classés. En cas d’interdépendances, les éléments dépendants doivent être placés derrière leurs cibles de relation. Par exemple, un enregistrement master-data Well doit être placé dans le tableau « MasterData » avant ses Wellbores.
Workflow d’ingestion de fichiers basée sur un manifeste
L’instance Azure Data Manager for Energy intègre la prise en charge du workflow d’ingestion de fichiers basée sur un manifeste. Osdu_ingest Airflow DAG est préconfiguré dans votre instance.
Composants du workflow d’ingestion de fichiers basée sur un manifeste
Le workflow d’ingestion de fichiers basée sur un manifeste comprend les composants suivants :
- Service de workflows : service wrapper qui s’exécute sur le moteur de workflow Airflow.
- Moteur Airflow : moteur d’orchestration de workflows qui exécute des workflows inscrits en tant que graphes orientés acycliques (DAG). Airflow est le moteur de workflow choisi par la communauté OSDU® pour orchestrer et exécuter des workflows d’ingestion. Airflow n’est pas directement exposé, mais ses fonctionnalités sont accessibles via le service de workflows.
- Service de stockage : service utilisé pour enregistrer les enregistrements de métadonnées du manifeste dans la plateforme de données.
- Service de schémas : service qui gère les schémas définis par OSDU® dans la plateforme de données. Les schémas sont référencés pendant l’ingestion de fichier basée sur le manifeste.
- Service de droits : service qui gère les groupes d’accès. Ce service est utilisé pendant l’ingestion pour la vérification des autorisations d’ingestion. Ce service est également utilisé lors de la récupération des enregistrements de métadonnées pour la validation des écritures en lecture.
- Service juridique : service qui valide la conformité par le biais d’étiquettes légales.
- Le service de recherche est utilisé pour effectuer une vérification de l’intégrité référentielle pendant le processus d’ingestion du manifeste.
Conditions préalables
Avant d’exécuter le workflow d’ingestion de fichiers basée sur un manifeste, les clients doivent s’assurer que les comptes d’utilisateur exécutant le workflow ont accès aux services principaux (recherche, stockage, schémas, droits et juridique) et au service de workflows (pour plus de détails, consultez les rôles de droits). Dans le cadre de l’approvisionnement de l’instance Azure Data Manager for Energy, les schémas standard OSDU® et les données de référence associées sont préchargés. Les clients doivent s’assurer que le compte d’utilisateur utilisé pour l’ingestion des manifestes est inclus dans les listes de contrôle d’accès de propriétaires et de viewers appropriées. Les clients doivent s’assurer que les manifestes sont configurés avec les bonnes étiquettes légales, listes de contrôle d’accès de propriétaires et de viewers, données de référence, etc.
Séquence du workflow
L’illustration suivante présente le workflow d’ingestion de fichiers basée sur un manifeste : 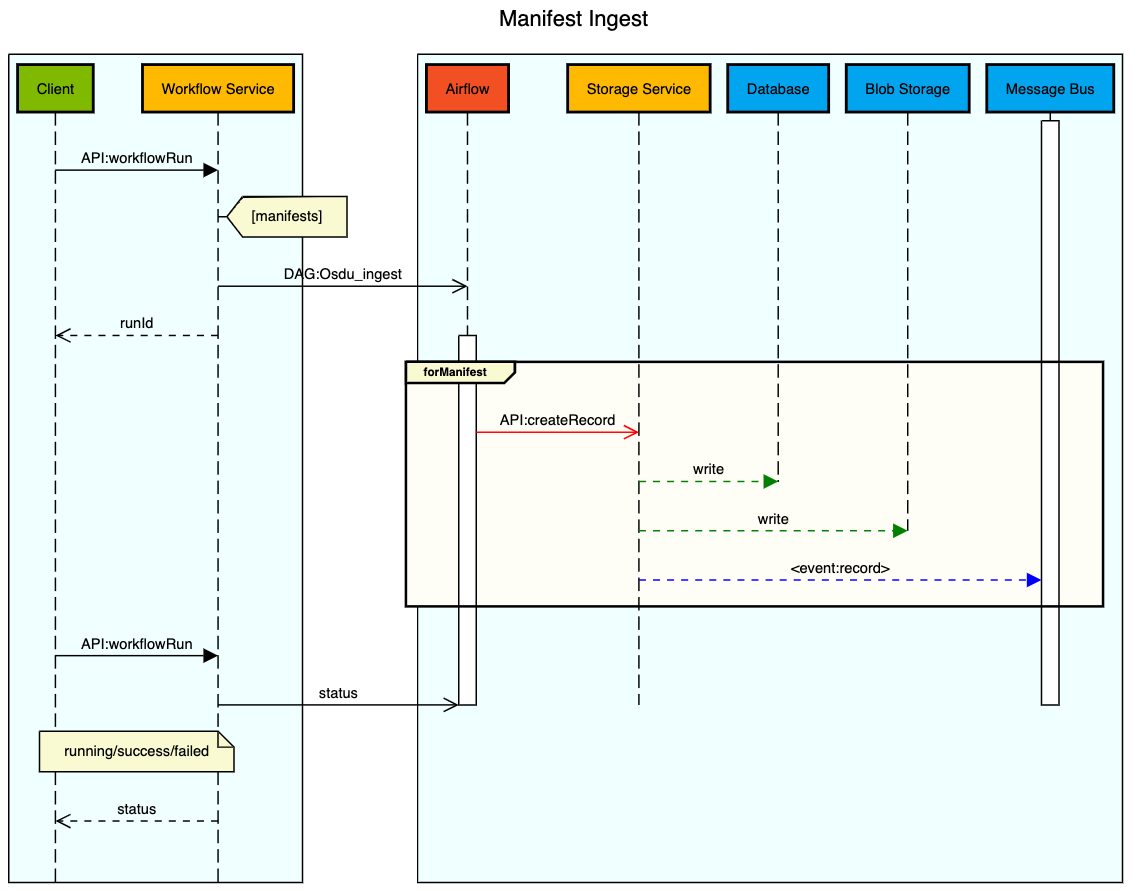
Un utilisateur soumet un manifeste à Workflow Service en utilisant le nom du workflow d’ingestion de manifeste (« Osdu_ingest »). Si la requête est correcte et que l’utilisateur est autorisé à exécuter le workflow, le service de workflows charge le manifeste et lance le workflow d’ingestion de manifeste.
Le service de workflows exécute une série d’opérations syntax validation sur le manifeste, comme la validation de la structure du manifeste, la validation des attributs selon le schéma défini et la vérification des attributs de schéma obligatoires. Le système effectue ensuite une opération referential integrity validation entre les composants et les jeux de données du produit de travail. Il s’agit par exemple de déterminer si les données parentes référencées existent.
Une fois les validations réussies, le système traite le contenu dans le stockage en écrivant chaque entité valide dans la plateforme de données à l’aide de l’API du service de stockage.
OSDU® est une marque déposée de The Open Group.