Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier les répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer de répertoire.
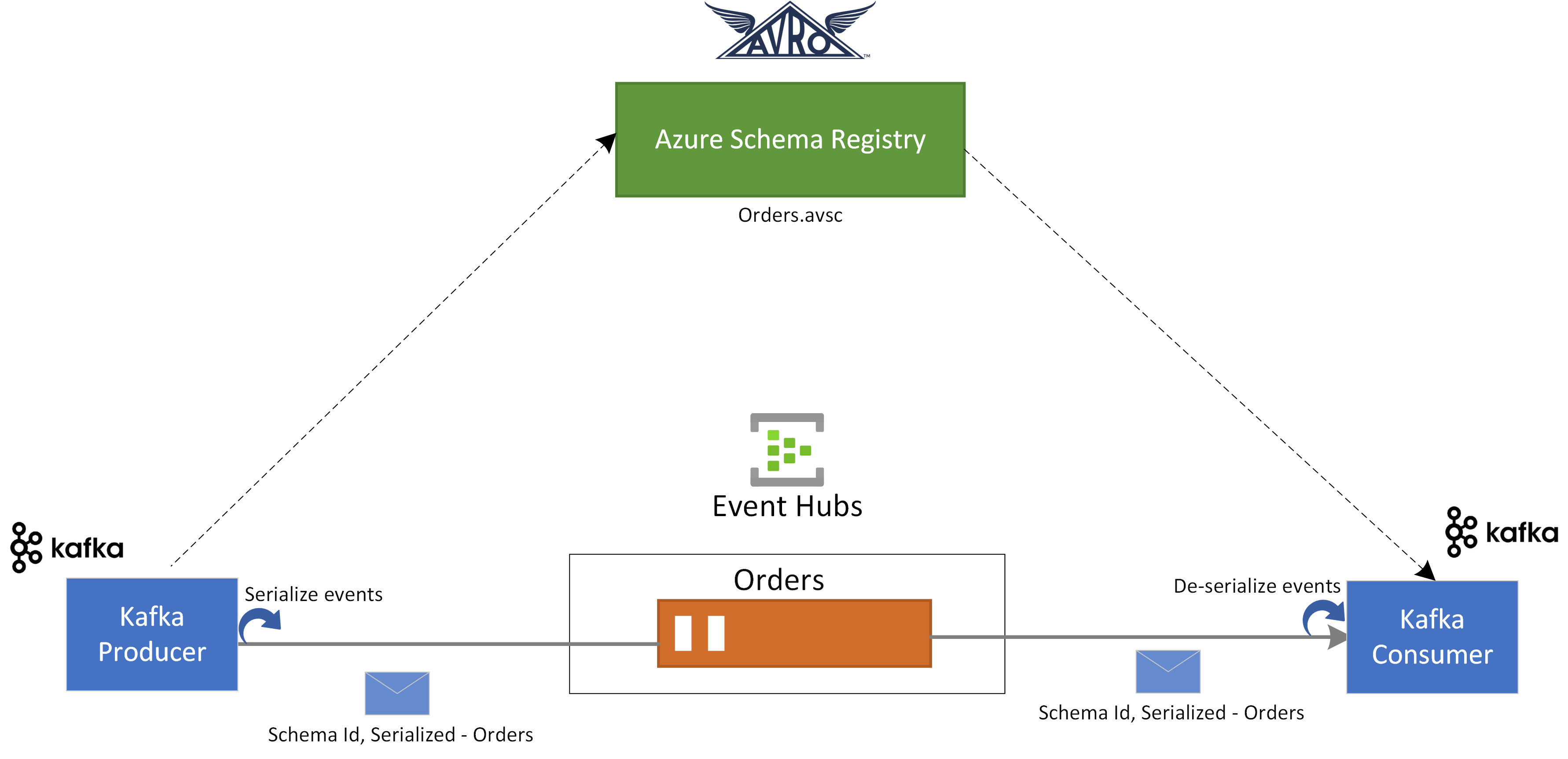
Dans ce guide de démarrage rapide, nous allons découvrir comment valider des événements à partir d’applications Apache Kafka à l’aide d’Azure Schema Registry pour Event Hubs.
Dans ce cas d’usage, une application de producteur Kafka utilise le schéma Avro stocké dans Azure Schema Registry pour sérialiser l’événement et les publier dans une rubrique/hub d’événements Kafka dans Azure Event Hubs. Le consommateur Kafka désérialise les événements qu’il consomme à partir d’Event Hubs. Pour cela, il utilise l’ID de schéma de l’événement et le schéma Avro, qui est stocké dans Azure Schema Registry.
Prerequisites
Si vous débutez avec Azure Event Hubs, consultez la vue d’ensemble d’Event Hubs avant de suivre ce guide de démarrage rapide.
Pour effectuer ce démarrage rapide, vous avez besoin de ce qui suit :
- Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
- Dans votre environnement de développement, installez les composants suivants :
- Kit de développement Java (JDK) 1.7+.
- Téléchargez et installez une archive binaire Maven.
- Git
- Clonez le référentiel Azure Schema Registry for Kafka.
Créer un concentrateur d’événements
Suivez les instructions du guide de démarrage rapide : Créez un espace de noms Event Hubs et un hub d’événements pour créer un espace de noms Event Hubs et un hub d’événements. Ensuite, suivez les instructions de Obtenir la chaîne de connexion pour obtenir une chaîne de connexion vers votre espace de noms Event Hubs.
Notez les paramètres suivants que vous utilisez dans le guide de démarrage rapide actuel :
- Chaîne de connexion pour l’espace de noms Event Hubs
- Nom du hub d’événements
Créer un schéma
Suivez les instructions de créer des schémas à l’aide du Registre de schémas pour créer un groupe de schémas et un schéma.
Créez un groupe de schémas nommé contoso-sg à l’aide du portail du Registre de schémas. Utilisez Avro comme type de sérialisation et None pour le mode de compatibilité.
Dans ce groupe de schémas, créez un schéma Avro avec le nom de schéma :
Microsoft.Azure.Data.SchemaRegistry.example.Orderà l’aide du contenu de schéma suivant.{ "namespace": "Microsoft.Azure.Data.SchemaRegistry.example", "type": "record", "name": "Order", "fields": [ { "name": "id", "type": "string" }, { "name": "amount", "type": "double" }, { "name": "description", "type": "string" } ] }
Inscrire une application pour accéder au Registre de schémas
Vous pouvez utiliser l’ID Microsoft Entra pour autoriser votre producteur Kafka et votre application consommateur à accéder aux ressources Azure Schema Registry en inscrivant votre application cliente auprès d’un locataire Microsoft Entra à partir du portail Azure.
Pour inscrire une application Microsoft Entra nommée example-app , consultez Inscrire votre application auprès d’un locataire Microsoft Entra.
- tenant.id : définit l’ID de locataire de l’application
- client.id : définit l’ID client de l’application
- client.secret : définit la clé secrète client pour l’authentification
Et si vous utilisez une identité managée, vous avez besoin des éléments suivants :
- use.managed.identity.credential : indique que les informations d’identification MSI doivent être utilisées pour une machine virtuelle avec MSI
- managed.identity.clientId : s’il est spécifié, il génère des informations d’identification MSI avec l’ID client donné
- managed.identity.resourceId : s’il est spécifié, il génère des informations d’identification MSI avec un ID de ressource donné
Ajouter un utilisateur au rôle Lecteur du Registre de schémas
Ajoutez votre compte d’utilisateur au rôle Lecteur du Registre de schémas au niveau de l’espace de noms. Vous pouvez également utiliser le rôle Contributeur du Registre de schémas , mais ce n’est pas nécessaire pour ce guide de démarrage rapide.
- Dans la page de l’espace de noms Event Hubs , sélectionnez Contrôle d’accès (IAM) dans le menu de gauche.
- Dans la page Contrôle d’accès (IAM), sélectionnez + Ajouter une>attribution de rôle dans le menu.
- Dans la page Type d’affectation , sélectionnez Suivant.
- Dans la page Rôles , sélectionnez Lecteur du Registre de schémas (préversion), puis sélectionnez Suivant en bas de la page.
- Utilisez le lien + Sélectionner des membres pour ajouter l’application
example-appque vous avez créée à l’étape précédente au rôle, puis sélectionnez Suivant. - Sur la page Vérifier + attribuer, sélectionnez Vérifier + attribuer.
Mettre à jour la configuration de l’application cliente des applications Kafka
Vous devez mettre à jour la configuration des clients des applications de producteur et de consommateur Kafka avec la configuration associée à l'application Microsoft Entra que nous avons créée, ainsi que les informations du registre de schémas.
Pour mettre à jour la configuration du producteur Kafka, accédez à azure-schema-registry-for-kafka/tree/master/java/avro/samples/kafka-producer.
Mettez à jour la configuration de l’application Kafka dans src/main/resources/app.properties en suivant le guide de démarrage rapide Kafka pour Event Hubs.
Mettez à jour les détails de configuration du producteur dans src/main/resources/app.properties à l’aide de la configuration associée au registre de schémas et de l’application Microsoft Entra que vous avez créée ci-dessus comme suit :
schema.group=contoso-sg schema.registry.url=https://<NAMESPACENAME>.servicebus.windows.net tenant.id=<> client.id=<> client.secret=<>Suivez les mêmes instructions et mettez à jour la configuration azure-schema-registry-for-kafka/tree/master/java/avro/samples/kafka-consumer.
Pour les applications producteurs et consommateurs Kafka, le schéma Avro suivant est utilisé :
{ "namespace": "com.azure.schemaregistry.samples", "type": "record", "name": "Order", "fields": [ { "name": "id", "type": "string" }, { "name": "amount", "type": "double" }, { "name": "description", "type": "string" } ] }
Utilisation du producteur Kafka avec validation de schéma Avro
Pour exécuter l’application de producteur Kafka, accédez à azure-schema-registry-for-kafka/tree/master/java/avro/samples/kafka-producer.
Vous pouvez exécuter l’application de producteur afin qu’elle puisse produire des enregistrements spécifiques Avro ou des enregistrements génériques. Pour un mode d’enregistrement spécifique, vous devez d’abord générer les classes sur l’un des schémas du producteur à l’aide de la commande maven suivante :
mvn generate-sourcesVous pouvez ensuite exécuter l’application de producteur à l’aide des commandes suivantes.
mvn clean package mvn -e clean compile exec:java -Dexec.mainClass="com.azure.schemaregistry.samples.producer.App"Lors de l’exécution réussie de l’application de producteur, il vous invite à choisir le scénario de producteur. Pour ce guide de démarrage rapide, vous pouvez choisir l’option 1 : produire des Avro SpecificRecords.
Enter case number: 1 - produce Avro SpecificRecords 2 - produce Avro GenericRecordsUne fois la sérialisation et la publication des données réussies, vous devriez voir les logs de console suivants dans votre application de producteur :
INFO com.azure.schemaregistry.samples.producer.KafkaAvroSpecificRecord - Sent Order {"id": "ID-0", "amount": 10.0, "description": "Sample order 0"} INFO com.azure.schemaregistry.samples.producer.KafkaAvroSpecificRecord - Sent Order {"id": "ID-1", "amount": 11.0, "description": "Sample order 1"} INFO com.azure.schemaregistry.samples.producer.KafkaAvroSpecificRecord - Sent Order {"id": "ID-2", "amount": 12.0, "description": "Sample order 2"}
Utilisation du consumer Kafka avec la validation du schéma Avro
Pour exécuter l’application consommateur Kafka, accédez à azure-schema-registry-for-kafka/tree/master/java/avro/samples/kafka-consumer.
Vous pouvez exécuter l’application consommateur afin qu’elle puisse consommer des enregistrements spécifiques Avro ou des enregistrements génériques. Pour un mode d’enregistrement spécifique, vous devez d’abord générer les classes sur l’un des schémas du producteur à l’aide de la commande maven suivante :
mvn generate-sourcesVous pouvez ensuite exécuter l’application consommateur à l’aide de la commande suivante.
mvn clean package mvn -e clean compile exec:java -Dexec.mainClass="com.azure.schemaregistry.samples.consumer.App"Lors de l’exécution réussie de l’application consommateur, il vous invite à choisir le scénario de producteur. Pour ce guide de démarrage rapide, vous pouvez choisir l’option 1 : utiliser Avro SpecificRecords.
Enter case number: 1 - consume Avro SpecificRecords 2 - consume Avro GenericRecordsUne fois réussies la consommation et la désérialisation des données, vous devez voir les journaux de console suivants dans votre application producteur :
INFO com.azure.schemaregistry.samples.consumer.KafkaAvroSpecificRecord - Order received: {"id": "ID-0", "amount": 10.0, "description": "Sample order 0"} INFO com.azure.schemaregistry.samples.consumer.KafkaAvroSpecificRecord - Order received: {"id": "ID-1", "amount": 11.0, "description": "Sample order 1"} INFO com.azure.schemaregistry.samples.consumer.KafkaAvroSpecificRecord - Order received: {"id": "ID-2", "amount": 12.0, "description": "Sample order 2"}
Nettoyer les ressources
Supprimez l’espace de noms Event Hubs ou supprimez le groupe de ressources qui contient l’espace de noms.